Data Schema
What is the schema?
Linkurious Enterprise uses a data schema to deliver some of its features. However, most graph databases are schema-less. As a consequence, Linkurious Enterprise automatically detects the data schema from each data-source. The automatically detected schema is:
- Implicit: it is inferred based on the data stored in the database.
- Incomplete: it is detected by sampling a subset of the graph data. As a consequence, some information might be missing.
- Limited in its expressiveness: property types are limited to either String or Numbers. Other types such as Enumerations or Dates cannot be detected since they cannot be automatically be told apart from Strings or Numbers.
The schema can be extended manually. An administrator can:
- Add missing properties
- Declare properties' types.
- Switch search/visibility options for node-categories, edge-types or properties.
The schema has two modes:
- Partial mode (default). The schema is the combination of what is detected automatically by Linkurious Enterprise and explicit declaration from the administrator.
- Strict mode, based only on the declarations of the administrators.
The Partial mode is flexible and incremental, whereas the Strict schema is stable and normative. Therefore the Partial mode is a better fit in early projects when the data schema is poised to change. The Strict mode is a better fit for production-ready projects that require a more controlled environment.
IMPORTANT
Statements made in the schema DO NOT alter the data in the database:
- Setting a property type in Linkurious Enterprise will not change the type of the corresponding values in the graph database (see section about the property types).
- Switching search/visibility options for a node-category, edge-type or property in Linkurious Enterprise will not remove or change the data stored in the graph database.
- Switching to strict mode in Linkurious Enterprise will not remove or change the data stored in the graph database.
Accessing the schema
The schema can be reached through the Admin menu.
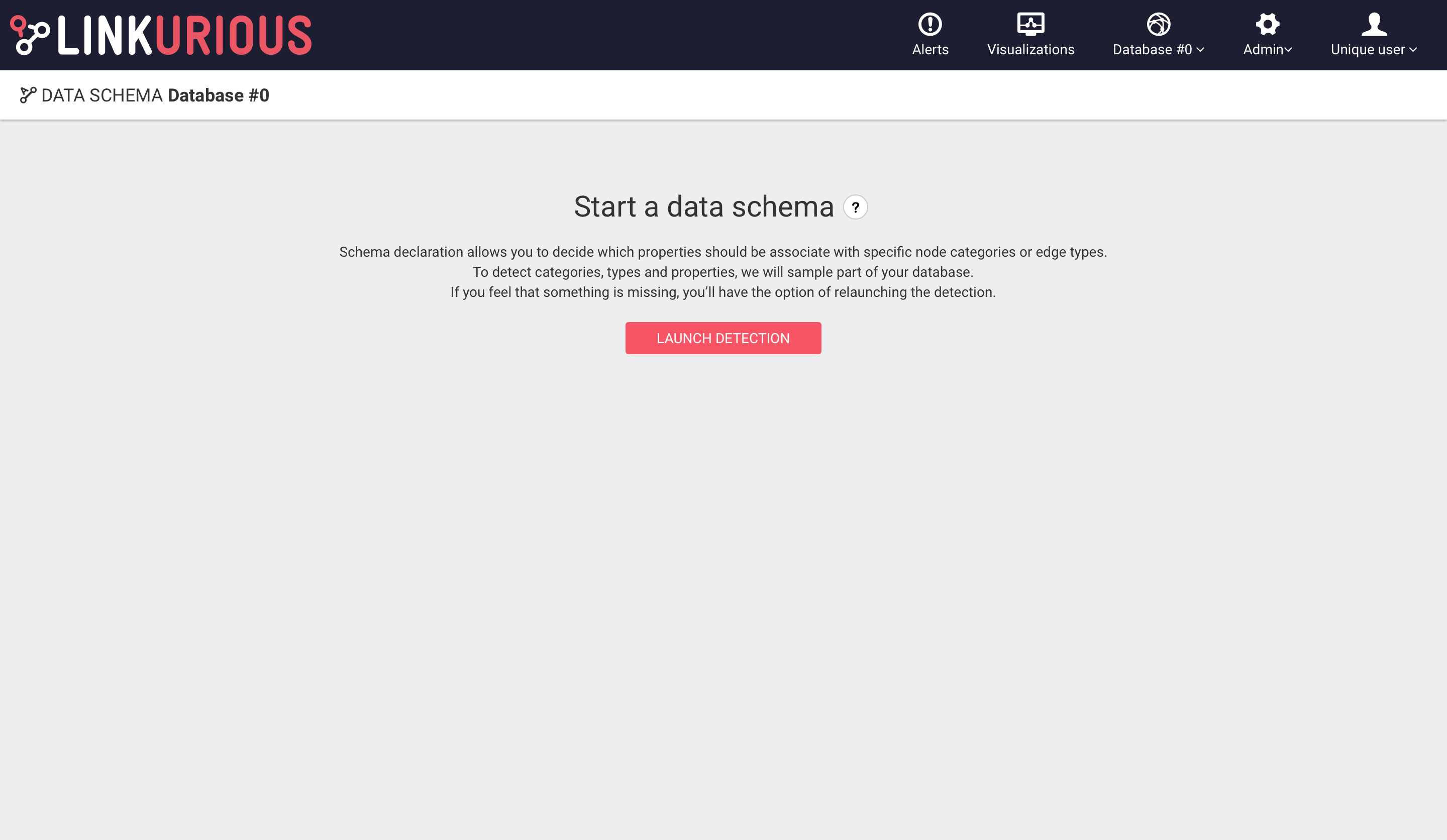
If this is the first time you access the feature, you will be prompted to "sample" the database. Linkurious Enterprise will take a few seconds / minutes to go through a sample of the database and build a more complete schema.
Overview
Structure
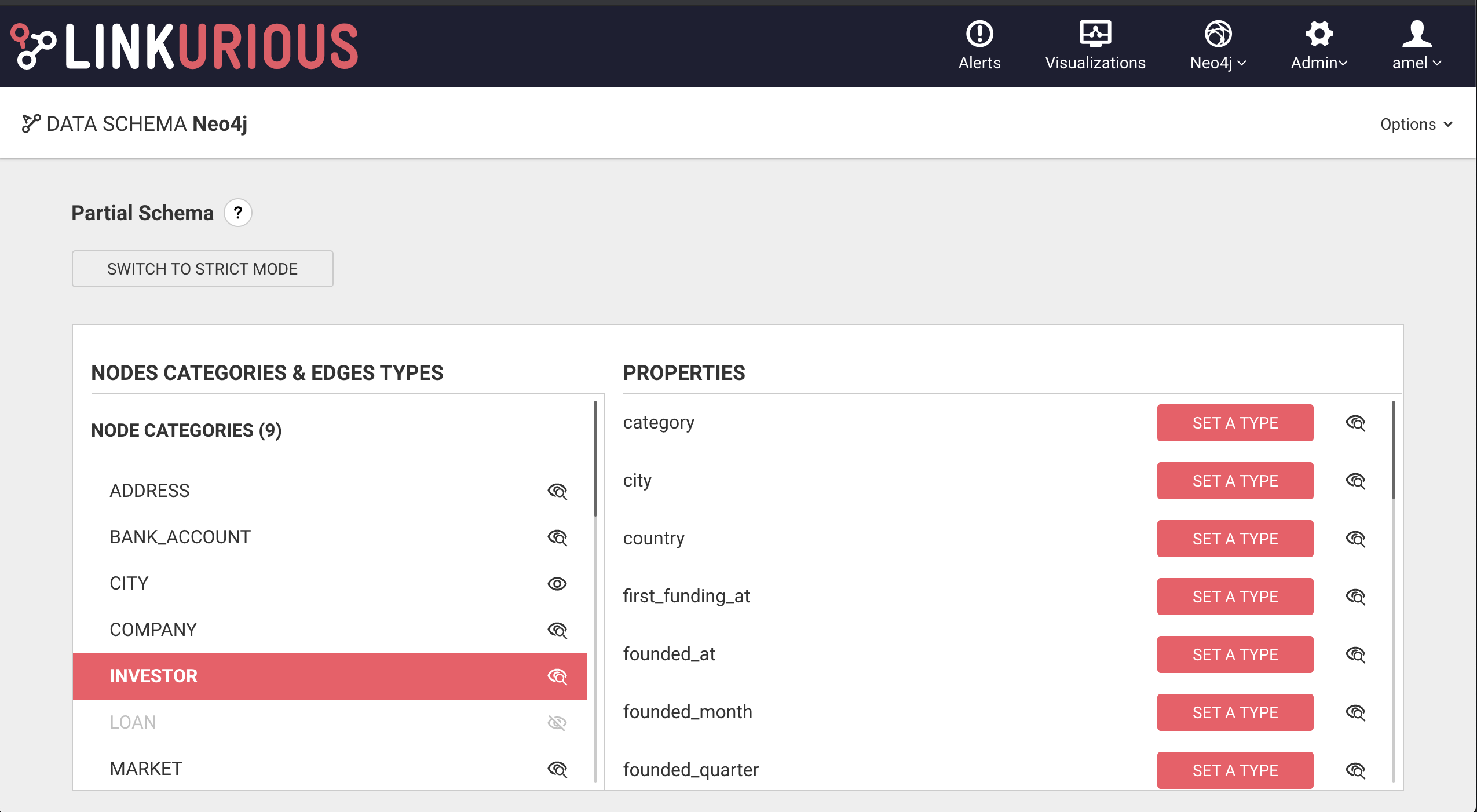
The schema is presented as two columns:
- On the left the node-categories and edge-types
- On the right the properties attached to the selected node-category or edge-type
Switch search/visibility for categories, types and properties
The "eye" icon next to node categories, edge types and properties allows to switch the visibility to View & Search, Only view or No access. See the dedicated section for more details.
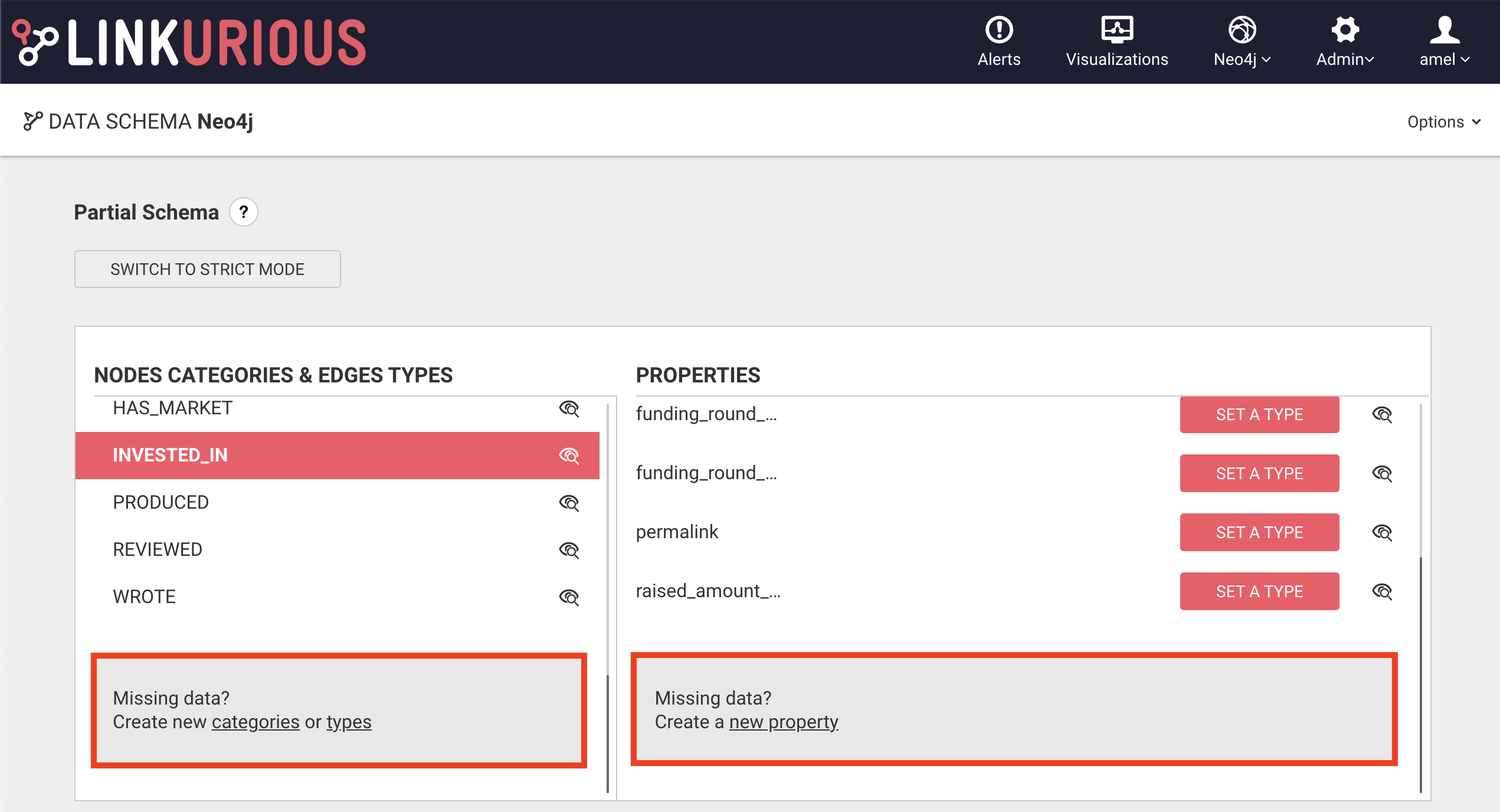
Create node-categories, edge-types and properties manually
The schema may be incomplete. Or you may want to add a category, type or property that is not yet in the data. You can create them manually through action links available at the bottom the list.
Remove nodes or edges from search results
Some node-categories or edge-types are unlikely to be searched for. As a consequence they pollute the search results.
You can disable the search by clicking on the "eye" icon and select Only view option. The nodes or the edges will then be not searchable but stay visible.
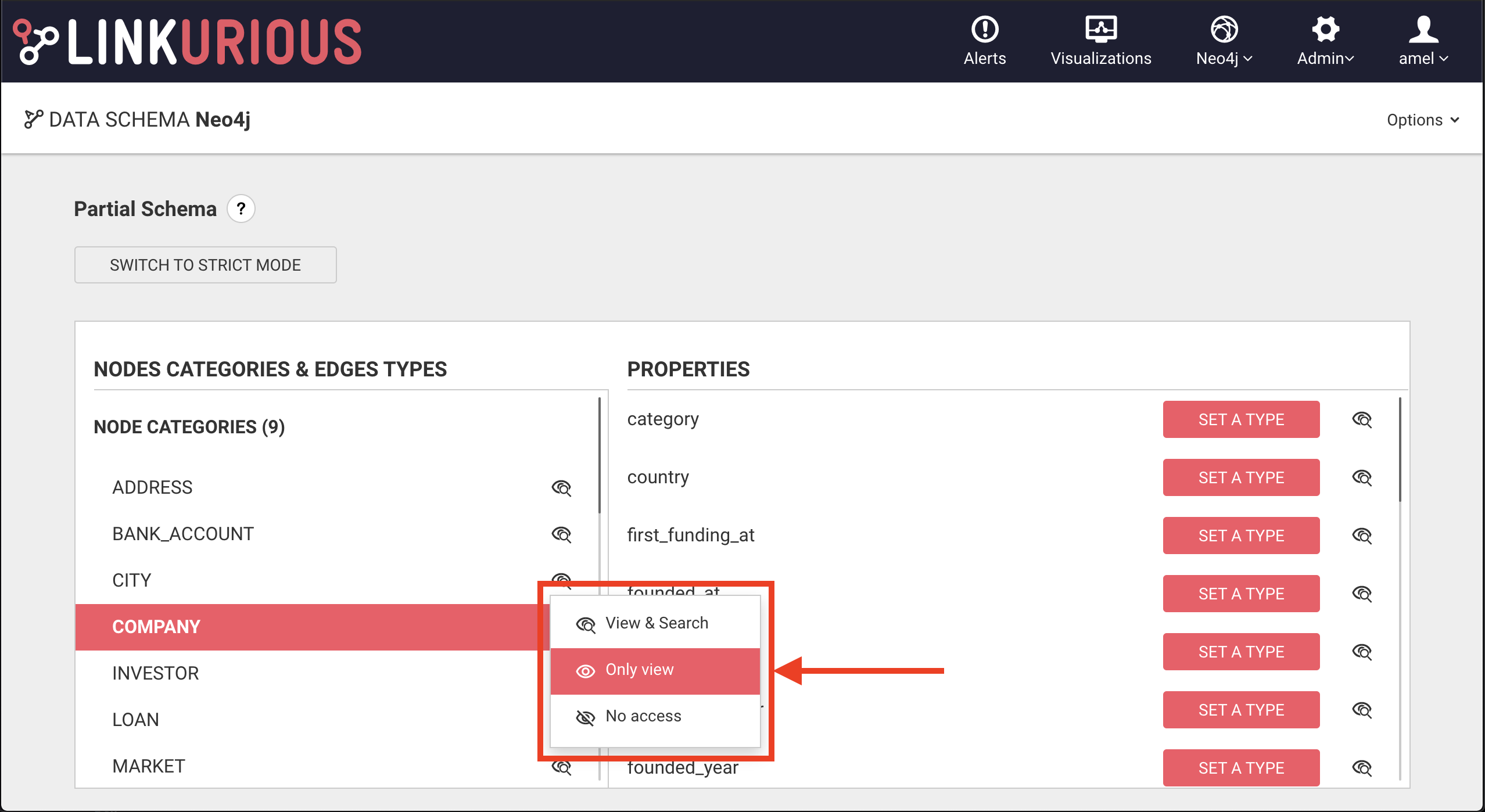
You can also remove them from the search by selecting No access option. The nodes or the edges will then be not searchable and not visible.
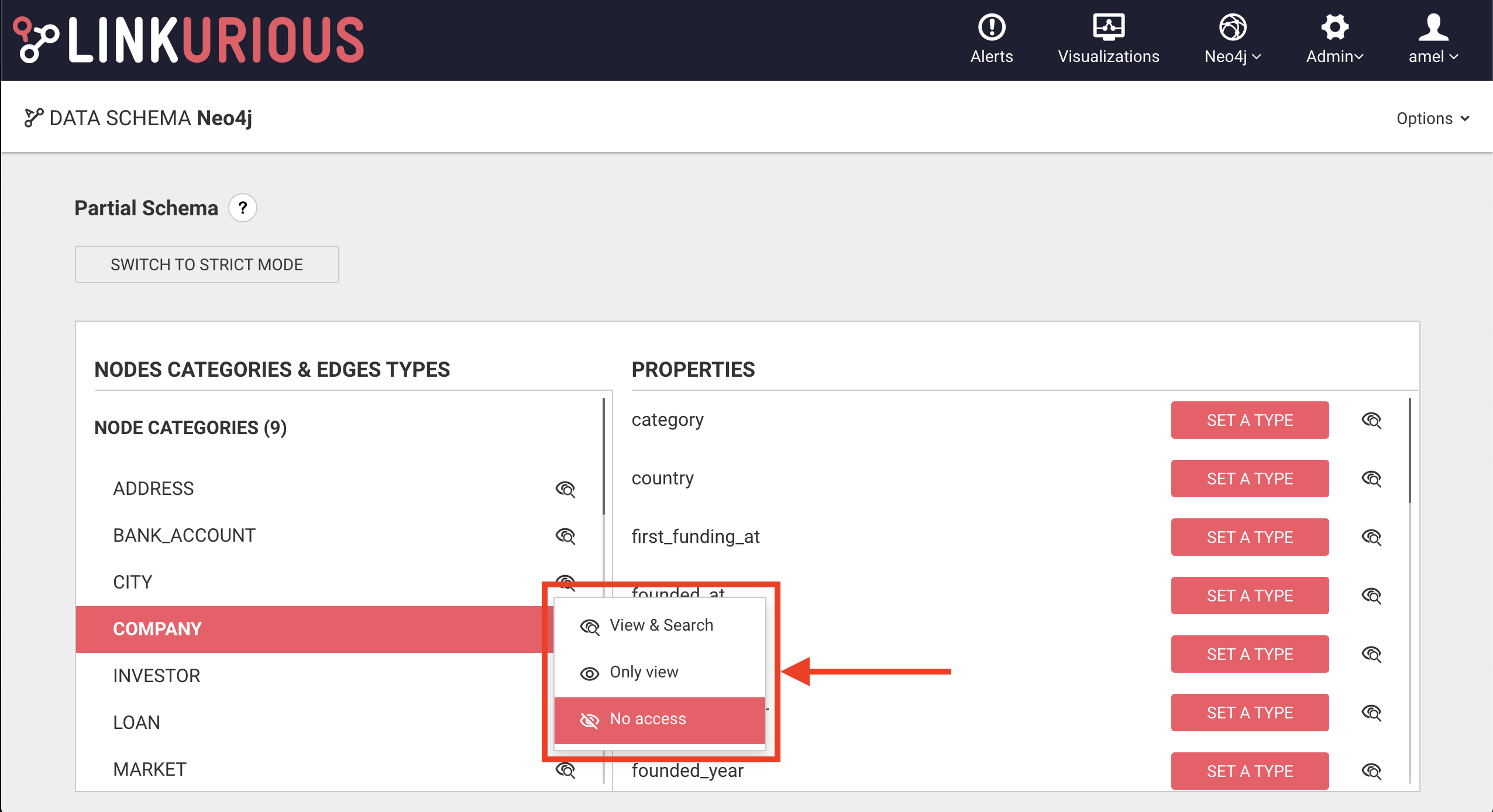
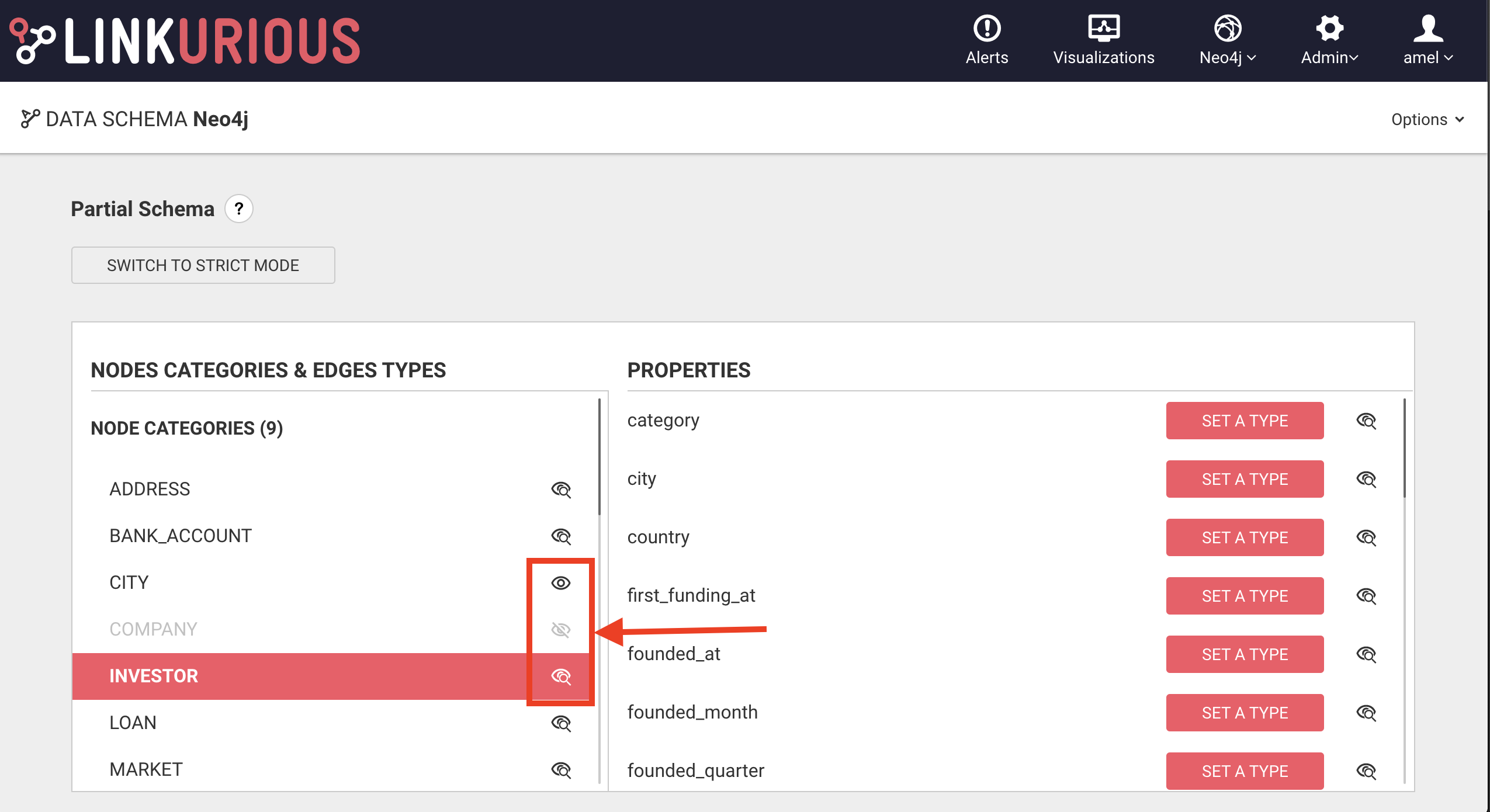
The "eye" icon will be updated by the selected search/visibility option
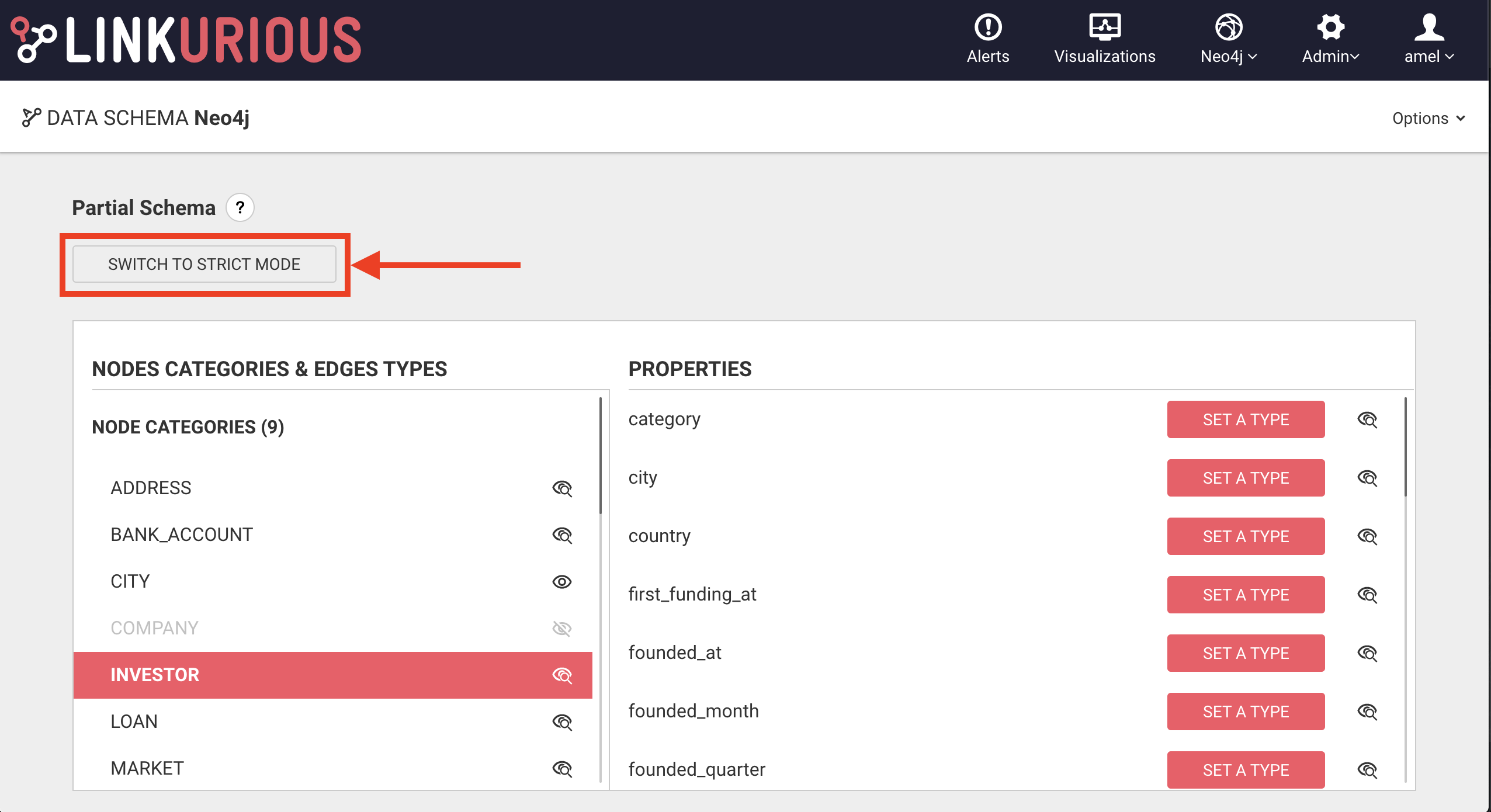
Switch to Strict mode
The button "Switch to strict mode" allows you to switch to a strict mode. See the dedicated section for more information.
Reset the schema
If the schema has changed a lot and you want to start fresh, it is possible to "Reset the schema": this will remove any schema declaration, and trigger a new sampling of the database.
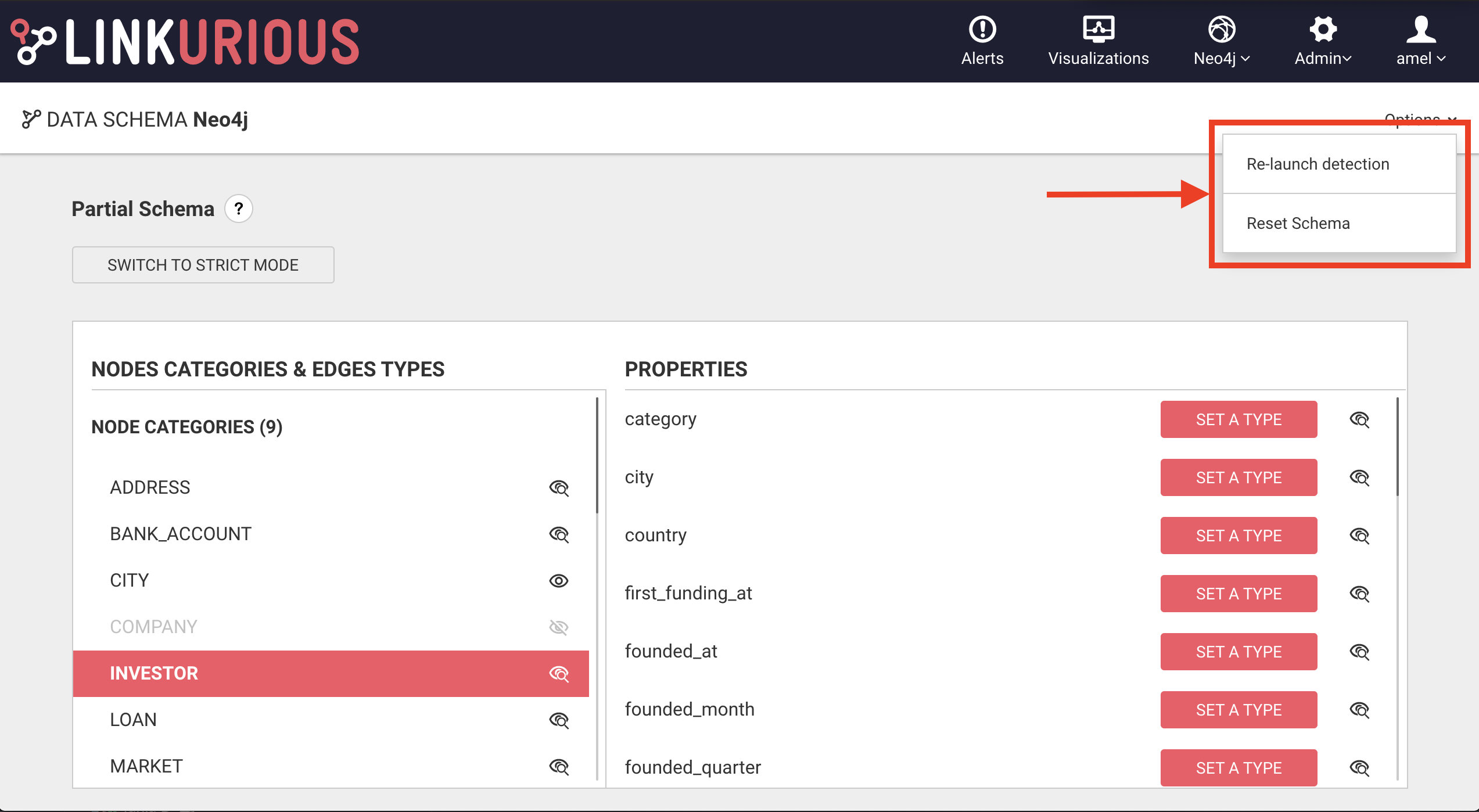
Add more sampling
If the schema is too incomplete (due for example to a recent import in the graph database with lots of new node categories / edge types / properties) it's possible to launch manually another sampling round to detect the missing categories / types / properties, using the Re-launch detection option in the Options menu.
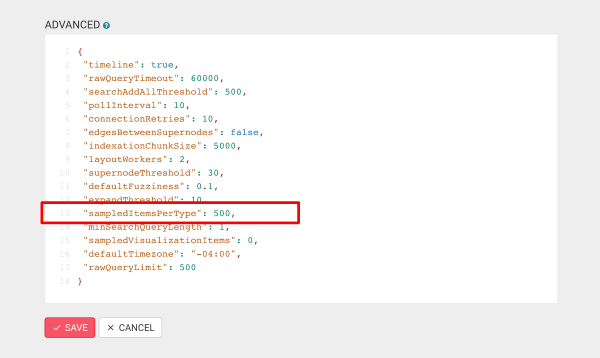
Sample size
The sampling of the database will scan only part of the database. The larger the sample, the more accurate but the longer the detection.
The default setting for the sampling size is 500 nodes per node category, 500 edges per edge type.
You can change this by editing the value of sampledItemsPerType in the Advanced section of the configuration (via Admin > Global configuration).
Fix search inconsistencies
When Linkurious indexes your data, it will only index nodes and edges whose categories and properties are marked as searchable.
On the Linkurious interface to set a category/ property to be searchable, you need to select the (view & search) option, However if you want a category/ property to be non-searchable you need to select the (view-only) option.
If for example in the schema I declare:
- category "PERSON" marked as searchable (view & search)
- property "last_name" marked as searchable (view & search)
- property "first_name" marked as visible (view only)
In search, I will be able to search by "last_name" but not by "first_name". In case, I want to enable search also by "first_name", I will need to mark this property as searchable, however if I do this after the indexation has occurred, I will see a warning in the schema configuration page telling me that there are inconsistencies I will need to solve in order to search for some properties. In order to fix the issue, a full indexation is required.
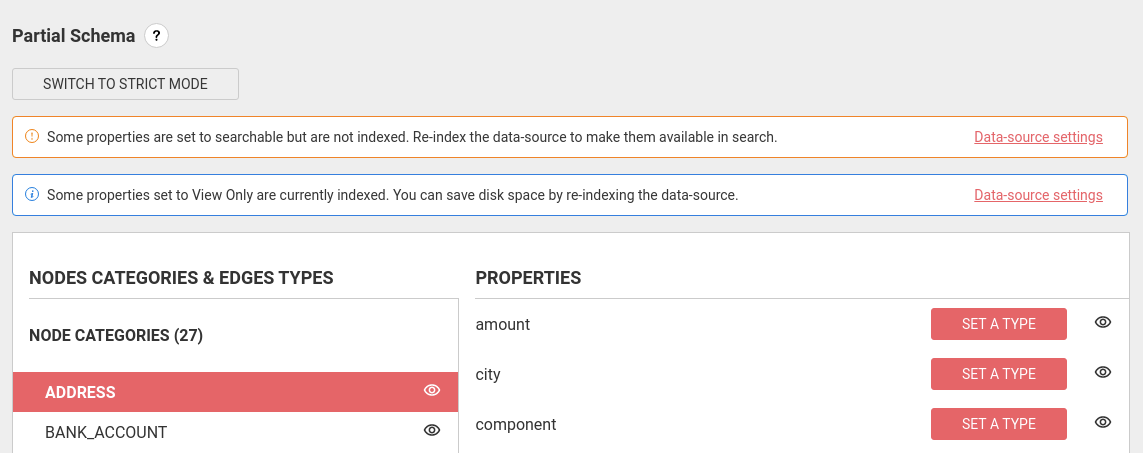
In case a property has been changed from searchable to visible, another information is shown, telling us that, the current search index is not optimized, which means there are more properties indexed than what are really needed to search. Running a full indexation should optimize the search index.