Welcome to the Linkurious Enterprise administrator documentation. This documentation will help you install, run and customize Linkurious Enterprise.
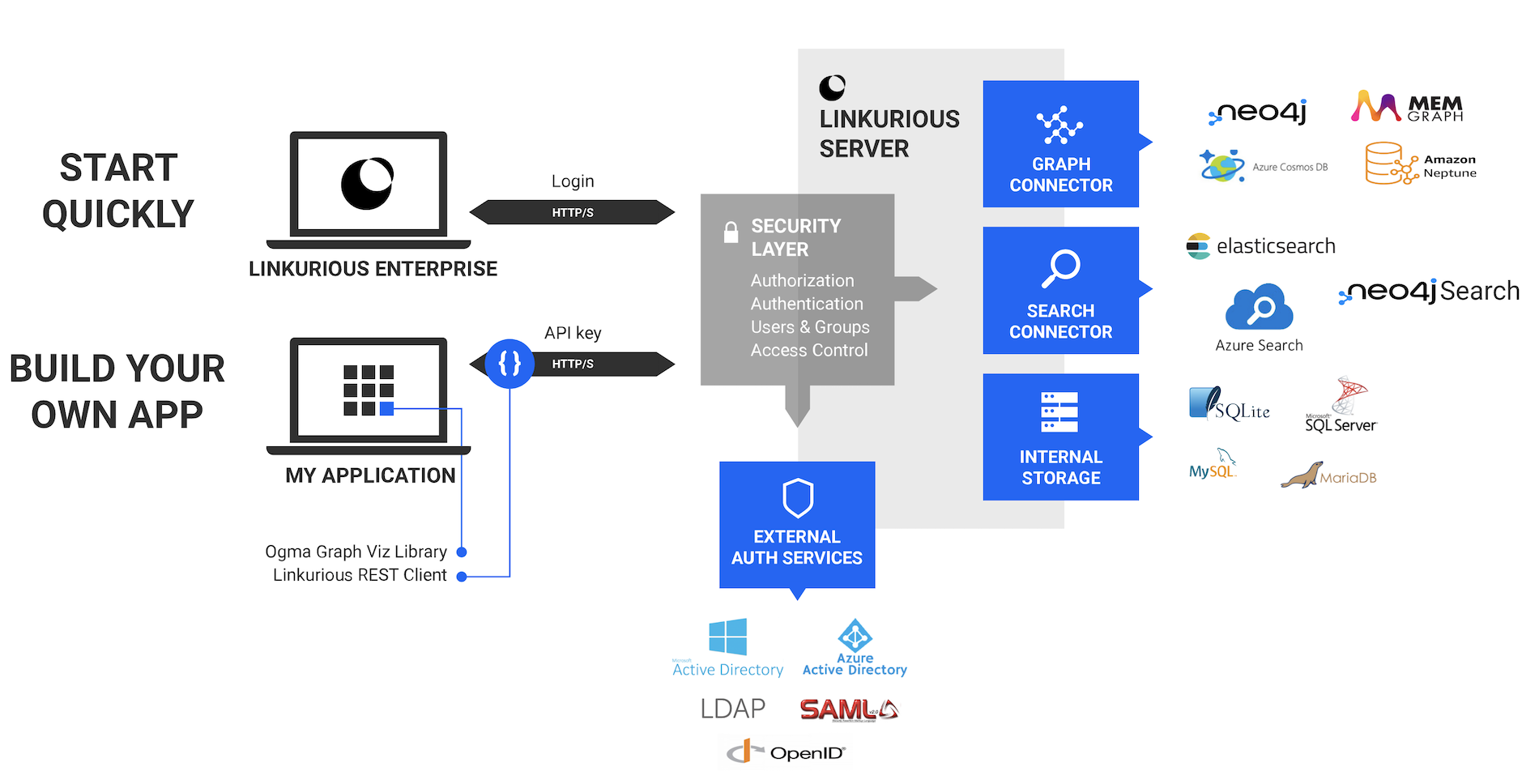
Linkurious Enterprise is a three-tier application.
The presentation layer is a Web application. It uses our graph visualization library, Ogma, to allow rich interactions with the graph. It also provides a user interface to enable data administration and collaboration among end users.
The presentation layer communicates with the logic layer via a JSON-based REST API. Custom presentation layer application can be developed on top of the logic layer.
The logic layer is a NodeJS-based server. It provides a unified REST API to read, write and search into graph databases from multiple vendors (Neo4j and Cosmos DB). It implements also a security layer with modular authentication that enables role-based access control policies. It can be connected to multiple graph databases at the same time and offers high-level APIs for collaborative exploration of graphs: users can create, share and publish graph visualizations, and multiple users can edit graph data.
Administrators can control it from its REST API for easy automation and deployment.
Multiple external authentication providers are supported (LDAP, Microsoft Active Directory, Microsoft Azure Active Directory, Google Suite, OpenID Connect, SAML2 / ADFS).
The data layer supports several graph databases, as well as indexing engines.
Depending on your license and your deployment model, you will have access to different features. A complete comparison of the features available in Linkurious Enterprise Cloud and the Linkurious Enterprise on Premise can be found on our pricing page, which provides an overview of the features available in Linkurious Enterprise depending on your deployment model.
Custom license information are available on the License Management Page.
Consult with your vendor to make sure that your graph database is installed on appropriate hardware and configured for better performances:
Make sure that your graph database is secure:
Keep in mind that Linkurious Enterprise can be used without Elasticsearch, see search options.
If you are using Linkurious Enterprise with Elasticsearch
By default, SQLite is used for the user-data store. SQLite is not recommended for production environment: switch to MySQL/MariaDB/MSSQL instead.
Schedule regular backups of the user-data store:
Make sure your user-data-store database is secure
If you need high-availability, set up replication
linkurious/data directoryforceHttps: true in Web Server configuration)See Cluster mode
The user-data store database (containing visualizations, saved queries, user, groups, etc) is stored in a SQL database.
By default, this database is an SQLite database (located at linkurious/data/database.sqlite).
In production, the use of a MySQL/MariaDB/MSSQL database is recommended.
These databases can be located on a remote server.
The default user-data store (SQLite) is not encrypted.
Encryption is available with the following vendors:
Yes, when using an external user-data store (e.g. MariaDB, MySQL or MSSQL), the SQLite files can be deleted.
The configuration file contains all configurable options, as well as the configuration options of all configured data sources (e.g. User-Data Store host/port/username/encrypted password; Graph Database URL/username/encrypted password; Index Search URL/username/encrypted password, etc). All passwords/secrets in the configuration file are encrypted before storage.
The configuration file, like the rest of the data folder, should be considered private and not be readable by anyone other than the Linkurious Enterprise service account.
All application secrets stored by Linkurious Enterprise (Graph Database credentials, User-Data Store credentials, Index Search credentials, SSL certificate passphrase, etc.) are encrypted using the AES-256-CTR algorithm.
User passwords are strongly hashed before being stored in the database. Passwords for LDAP and other external authentication solutions are not stored at all.
The audit trail files are generated in linkurious/data/audit-trail by default.
This path can be set in the audit trail configuration.
The audit trail contains sensitive information and should be secured. It should be owned and readable only by the Linkurious Enterprise service account.
The data directory contains logs, configuration files, and, if enabled, audit trails. This information is sensitive, and the directory should be owned and readable only by the Linkurious Enterprise service account
A service account is an operating system user account with restricted privileges that is used only to run a specific service and own it data related to this service. Service accounts are not intended to be used by people, except for performing administrative operations. Access to service accounts is usually tightly controlled using privileged access management solutions.
Service accounts prevent other users and services from reading or writing to sensitive files in the directories that they own, and are themselves prevented from reading and writing to other parts of the file system where they are not owners.
We do not support Kerberos as of now (but we support many other third-party authentication services).
Linkurious Enterprise creates three types of logs:
data/logs/analytics.log): Usage telemetry (GDPR safe, not sensitive information)data/logs/linkurious.log and linkurious.exceptions.log): Server debugging logs (may contain graph queries).data/audit-trail/audit-trail.log): See audit trail log format details.If your LDAP server supports secure LDAP, use the "ldaps://" protocol in your LDAP configuration.
If you need authentication and transport layer security for Elasticsearch:
To customize supported TLS ciphers, in the general configuration, set tlsCipherList in the server section.
Here is an example, based on Mozilla's recommended cipher list:
{
"tlsCipherList": "TLS_AES_128_GCM_SHA256:TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256:ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384:!eNULL:!aNULL"
}
We are trying to keep the Linkurious Enterprise update process as simple as possible. However, sometimes configuration can require specific manual activities.
Before you upgrade to a new version of Linkurious Enterprise, consider browsing our public resources to verify whether there are specific instructions that applies to your configuration or activities you are planning.
If you have issues configuring a secure connection, temporarily tweaking the TLS settings may help troubleshooting the issue.
TLS certificate validation can be disabled by setting the NODE_TLS_REJECT_UNAUTHORIZED
environment variable to 0.
Note that this should only be done for troubleshooting purposes, as it makes TLS inherently insecure.
Some useful Node options can also be set:
--trace-tls: Prints TLS packet trace information in the manager logs.--openssl-legacy-provider: Enable OpenSSL 3.0 legacy provider.--tls-cipher-list=list: Specify an alternative default TLS cipher list (this can also be set in Linkurious Enterprise configuration file).These settings can be set in the /data/manager/manager.json configuration file, in the env section of the Linkurious Server service.
For instance, it may look like this:
{
"env": {
"NODE_TLS_REJECT_UNAUTHORIZED": 0,
"NODE_OPTIONS": "--max-old-space-size=4096 --trace-tls --openssl-legacy-provider --tls-cipher-list=DEFAULT@SECLEVEL=0"
}
}
For Neo4j connections, certificate validation can be disabled by changing the URL scheme:
neo4j+s:// can be replaced by neo4j+ssc:// (where ssc means "self signed certificate", it disables certificate validation).bolt+s:// can be replaced by bolt+ssc://.For Active Directory, TLS debug settings can be set directly in the Linkurious Enterprise configuration file, see Active Directory configuration.
PEM (for Privacy-Enhanced Mail) is a file format for storing and sending cryptographic keys and certificates.
To verify if a certificate is PEM-encoded, open it with a text-editor, it should look something like this:
-----BEGIN CERTIFICATE-----
MIICLDCCAdKgAwIBAgIBADAKBggqhkjOPQQDAjB9MQswCQYDVQQGEwJCRTEPMA0G
A1UEChMGR251VExTMSUwIwYDVQQLExxHbnVUTFMgY2VydGlmaWNhdGUgYXV0aG9y
DwEB/wQFAwMHBgAwHQYDVR0OBBYEFPC0gf6YEr+1KLlkQAPLzB9mTigDMAoGCCqG
SM49BAMCA0gAMEUCIDGuwD1KPyG+hRf88MeyMQcqOFZD0TbVleF+UsAGQ4enAiEA
l4wOuDwKQa+upc8GftXE2C//4mKANBC6It01gUaTIpo=
-----END CERTIFICATE-----
If you have a DER-encoded certificate (binary), it can be converted to PEM:
openssl x509 -inform der -in certificate.cer -out certificate.pemCrypto Shell Extensions)details tabCopy to file...NextBase-64 encoded X.509 (.CER) and click NextNextFinishMost graph vendors support search strategies other than Elasticsearch. See details on our search options page.
Yes. See the geospatial configuration options for further details.
Yes, you can configure ArcGIS as the tile-server for geospatial mode. The ArcGIS documentation describes the API endpoints that is compatible with Linkurious Enterprise:
https://<MapServer-url>/tile/{z}/{y}/{x}For example:
./linkurious/start.sh: start the server./linkurious/stop.sh: stop the server./linkurious/menu.sh: open the management console./linkurious/menu.sh status: print the current status of the server./linkurious/menu.sh install: install as a system-wide service (requires root)./linkurious/menu.sh uninstall: remove from system-wide services (requires root)./linkurious/menu.sh help: show advanced optionsDepending on the configuration options specified, enabling the audit trail can have an impact on performance. See the audit trail documentation for details.
Linkurious Enterprise supports different options to integrate with third party tools. This is particularly helpful to add graph capabilities to other tools or to extend Linkurious Enterprise capabilities.
For example, clients have integrated Linkurious Enterprise with reporting and business intelligence tools such as Microsoft PowerBi, Tableau, Looker or NeoDash.
There are 4 main options to integrate Linkurious Enterprise with a third party application:
The easiest integration is via Custom Action. It allows to add a menu entry in Linkurious Enterprise that opens a third party application. These menu entries open a parameterizable link.
For example, you can right-click on a "Person" node in a visualization and run a Custom Action to open a new tab with the details of that person displayed by an internal back-office tool.
In order for Custom Actions to function correctly, the target third party application should support deep links (i.e. the possibility to accept URL parameters). Most reporting tools offer the possibility to filter data based on variables and allow setting these variables via URL parameters.
This can allow users to open a pre-filtered report hosted by a third party tool.
It is also possible to access Linkurious Enterprise from a third party application, via deep links (note: please check if your license package includes Deep Links). From a third party application, it is possible to generate a URL to open an existing or new visualization in Linkurious Enterprise, with options to display the result of a graph query, or search query, etc.
For example, if you have a page in a back-office application displaying data about a specific company, you can add a link in this page to view the context of this company in Linkurious Enterprise.
In order to take advantage of deep links, the third party application should support user interactions (e.g. via links, clickable buttons, etc.) that open a URL, with the possibility to add parameters to the opened URL.
It is possible to embed Linkurious Enterprise in another Web application using an iframe HTML element.
Note that when performing this integration, you need to have enough seats in your license to
cover all the users of your third party application.
To create an iframe integration, you will need:
iframe element to an existing Web applications.iframes and set the appropriate security parameters (see details).It is possible for Linkurious Enterprise to notify third party applications about certain events, so that these applications can react to these events. This can be done by setting up a Webhook in Linkurious Enterprise.
For example, to use a third party case management tool to handle alert cases created by Linkurious Enterprise,
you need to set up a Webhook for the newCase event, and set up the Webhook to call
the API of your case management system and create a new case there.
Linkurious Enterprise uses version codes with 3 numbers separated by dots (e.g. 2.9.14).
The numbers are interpreted as MAJOR.MINOR.PATCH.
For example, Linkurious Enterprise 2.9.11 is a patch version that is part of the Linkurious Enterprise 2.9
minor version, which is itself part of the Linkurious Enterprise 2 major version.
When updating Linkurious Enterprise from one version to another (for any version in the “stable” or “maintenance” stage), the following is guaranteed:
A breaking change is a change that either removes a feature, or changes an existing feature in a way that makes adopting this change require either:
Examples:
A non-breaking improvement is a change that either adds a new feature, or extends the capacities of an existing features without removing any existing functional behavior.
Examples:
A minor version of Linkurious Enterprise (e.g. 2.9) is always in one of the following stages:
This is an example version life-cycle to illustrate how minor and patch version are released.

Release Date: 2026-07-10
maxMatchesLimit is reached while an alert is runningaccess.loginTimeoutcategoriesOrType parameteraccess.loginTimeout configuration is not set, the default value is now 10800 seconds. The previous behavior was to never expire sessions when this configuration was not set.HTTP_PROXY, HTTPS_PROXY or NO_PROXY to enable proxying of outgoing HTTP traffic, you must now set NODE_USE_ENV_PROXY=1 for these environment variables to be taken into account.
If you were using the "proxy" option for a Neo4j data-source, this option is now ignored and you must now use the aforementioned environment variables.agent of the RestClient constructor has been removed. This parameter was normally not meant to be used, besides a few advanced specific use-cases.Technical requirements for users that access Linkurious Enterprise with their Web browser:
Hardware requirements of the Linkurious Enterprise Web client vary with the size of the visualized graphs. For up to 500 nodes and edges in a single visualization, we recommend to use a machine with 8 GB RAM, and 2 CPU cores @ 1.6 Ghz.
End-users will access Linkurious Enterprise through a Web browser. The following browsers are officially supported:
| Feature \ Vendor | Neo4j | Amazon Neptune | Memgraph | Cosmos DB | Google Spanner | Google BigQuery |
|---|---|---|---|---|---|---|
| Full-text search | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Graph styles customization | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Graph filtering | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Graph editing | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| CSV Import | ✅ | ❌ | ✅ | ❌ | ❌ | ❌ |
| Access-rights management | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Custom graph queries | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Custom query templates | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Predefined queries | ✅ | ❌ | ❌ | ❌ | ✅ | ✅ |
| Alerts | ✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
| No-code query builder | ✅ | ✅ | ❌ | ❌ | ✅ | ✅ |
| Entity resolution | ✅ | ❌ | ❌ | ❌ | ❌ | ❌ |
Linkurious Enterprise is a Web-application server. It needs to be installed on a server and can then be accessed by multiple users using their Web browser.
Technical requirements for the machine used to install the Linkurious Enterprise Web-application server:
Linkurious Enterprise hardware requirements change according to your needs and setup. Here are some scenarios with their suggested minimum hardware configurations.
Project up to 20 users and few alerts.
Using the embedded Elasticsearch1:
Not using the embedded Elasticsearch:
Project up to 100 users and tenth of alerts.
Using the embedded Elasticsearch1:
Not using the embedded Elasticsearch:
Project with more than 100 users and several alerts.
To maintain stable performance, it is necessary to move heavily loaded components to well-dimensioned dedicated servers/clusters:
Hardware requirements only for the Linkurious Enterprise server:
Linkurious Enterprise requires a 64-bit system to run.
1The embedded Elasticsearch is not recommended when dealing with large amounts of data, see Elasticsearch documentation.
2Some extra space is required for the Elasticsearch full-text index. This space is proportional to the size of your graph database. A (very) rough estimate could be 50% of your graph database (it also depends on the actual data density).
3It is possible to configure Elasticsearch for higher memory usage, please contact us.
4It is possible to configure Linkurious Enterprise for higher memory usage more, please contact us.
Please keep in mind that these technical requirements are for Linkurious Enterprise server only. For hardware requirements regarding your graph database, please refer to these guides:
Linkurious Enterprise includes an embedded Elasticsearch instance for search capabilities. Please keep in mind that this embedded instance will only work for smaller graphs (less than 50M nodes + edges). For larger graphs, you will need to deploy an Elasticsearch cluster. Please refer to Elasticsearch's hardware requirements guide for details.
Linkurious Enterprise server can be deployed on the following platforms:
Linkurious Enterprise depends on Node.js that requires a Linux kernel >= 4.18 and a GLIBC >= 2.28.
You can check the Linux kernel and the GLIBC version available on your system on http://distrowatch.com.
The latest version of Linkurious Enterprise can be downloaded from the Linkurious Customer Center.
Log in with the username and password created during the purchase process and then go to the download section for the specific license (in case of multiple one), it will be possible to download the package for the correct platform.

The ZIP file contains:
Please see the Linkurious Enterprise version compatibility matrix and our documentation on how to update Linkurious Enterprise.
To work properly, Linkurious Enterprise only need permissions (including write access) to the whole application directory, no administrative rights are needed.
The only exception may be related to Operating Systems' security policies preventing any standard user to bind applications on the first 1024 port numbers, see web server configuration to learn more on the issue and how prevent to grant administrative rights.
As best practice, it is advised to create a dedicated service account (e.g. linkurious)
with the minimum level of permissions.
unzip linkurious-linux-v4.3.10.zip
useradd -r linkurious
chown -R linkurious:linkurious /linkurious-linux
cd linkurious-linux
linkurious-linux/data/config/production.json (see how to configure a data-source)See how to start Linkurious Enterprise on Linux.
linkurious-windows folderlinkurious-windows/data/config/production.json (see how to configure a data-source)See how to start Linkurious Enterprise on Windows.
> unzip linkurious-osx-v4.3.10.zip> cd linkurious-osxlinkurious-osx/data/config/production.json (see how to configure a data-source)See how to start Linkurious Enterprise on macOS.
> docker load -i linkurious-docker-v4.3.10.tar.gz3000 and 3443 for http and https connections respectively./data stores Linkurious Enterprise configuration, logs and application data./elasticsearch stores the Embedded Elasticsearch data.docker volume create lke-data
docker volume create lke-elasticsearch
NODE_EXTRA_CA_CERTS
environment variable (see details.)See how to start Linkurious Enterprise with docker.
⚠️ Linkurious Enterprise and it's additional components are only available for
x86_64architectures. If you are deploying a testing environment with Apple Silicon chip that offers transparent support forx86_64binaries you may need to add the--platform linux/x86_64docker parameter to force downloading the existing image.
If you wish to download Linkurious Enterprise directly using the docker command line, use:
docker login -u 'YOUR_EMAIL' -p 'YOUR_DOWNLOAD_KEY' LINKURIOUS_PRIVATE_REGISTRYdocker pull LINKURIOUS_PRIVATE_REGISTRY/linkurious/linkurious-enterprise:4.3.10ℹ️ To get a version of Linkurious Enterprise that includes the embedded Elasticsearch instance, use
linkurious-enterprise-esinstead oflinkurious-enterprisein the command above.
You will find the value for YOUR_DOWNLOAD_KEY in the Linkurious Customer Center, using the Copy Download Key button.
You will find the value for LINKURIOUS_PRIVATE_REGISTRY in the Linkurious Customer Center, under the Download menu.
Please refrain from using Linkurious's private Docker registry directly in your deployment scripts, because its high-availability is not guaranteed. Instead, please download the image once and load it into your organization's private Docker registry.
Example command line to upload Linkurious Enterprise to your organization's private Docker registry:
docker login MY_PRIVATE_REGISTRYdocker tag LINKURIOUS_PRIVATE_REGISTRY/linkurious/linkurious-enterprise:4.3.10 MY_PRIVATE_REGISTRY/linkurious-enterprisedocker push MY_PRIVATE_REGISTRY/linkurious-enterprise:4.3.10To run Linkurious Enterprise automatically when the operating system starts, it is possible to install it as a system service on Linux, macOS and Windows.
Open the administration menu by running menu.sh, menu.bat or menu.sh.command in the Linkurious Enterprise folder.
Click on Install Linkurious as a system service (administrative rights may be needed to successfully complete the task).
Linkurious Enterprise automatically detects the owner of the folder and will use that user as the
Process owner.It is possible to use a different user by running the
menuscript with the option--user=USER(whereUSERis the desiredProcess ownerwith adequate permissions).
When Linkurious Enterprise is installed as a service, the administration menu (by running menu.sh,
menu.bat or menu.sh.command in the Linkurious Enterprise folder) will show the current status
of the service as well as a new entry to Uninstall Linkurious from system services.
To start Linkurious Enterprise, run the start.sh script in the linkurious-linux directory.
Alternatively, run the menu.sh script and click Start Linkurious.
By default, Linkurious Enterprise server will listen for connection on port 3000.
However, some firewalls block network traffic ports other than 80 (HTTP).
See the Web server configuration documentation to learn how to make Linkurious Enterprise listen on
port 80.
To start Linkurious Enterprise, run the start.bat script in the linkurious-windows directory.
Alternatively, run the menu.bat script and click Start Linkurious.
The firewall of Windows might ask you to authorize connections to Linkurious Enterprise. If so, click on Authorize access.
Content of the linkurious-windows directory:
Linkurious Enterprise starting up on Windows:
macOS prevents you from running applications downloaded from the internet.
To solve this problem, please follow these steps before starting Linkurious Enterprise.
It will allow macOS to run "untrusted" applications:
xattr -rc <Linkurious_home_directory>
Once you have followed the steps above (depending on your macOS version), you can start Linkurious Enterprise:
start.sh.command script in the linkurious-osx directory.menu.sh.command script and click Start Linkurious.Note: Embedded Elasticsearch is not available on macOS systems
To start a Linkurious Enterprise docker image, please use the docker run command.
Here is an example:
docker run -d --rm \
-p 3000:3000 \
--mount type=volume,src=lke-data,dst=/data \
--mount type=volume,src=lke-elasticsearch,dst=/elasticsearch \
linkurious:4.3.10
If you choose to mount a host machine folder as a volume, please make sure that the user within the container has read and write access to the volume folders. By default, Linkurious Enterprise runs as the
linkurioususer (uid:2013). You can do that by adding a--useroption to the docker run command. The folders that you want to mount must exist before starting Docker, otherwise Linkurious Enterprise will fail to start due to permissions errors. Please read the docker documentation to learn more.
Here is an example:
docker run -d --rm \
-p 3000:3000 \
--mount type=bind,src=/path/to/my/data/folder,dst=/data \
--mount type=bind,src=/path/to/my/elasticsearch/folder,dst=/elasticsearch \
--user "$(id -u):$(id -g)" \
linkurious:4.3.10
If no user is set, the Linkurious Enterprise container will check for appropriate file permissions and change file permissions if necessary.
By default, Linkurious Enterprise runs as the user linkurious who only exists in the container, not on the
host. As a consequence, it is not trivial to set up mount folders on the host which this new
user has write permissions for.
To make this process easier, file permissions will be set automatically if you run the
container as root, and a helpful error message will be printed if file permissions cannot be
fixed automatically.
If you are setting memory limits on the running container, using the argument --memory 1024m
you will possibly need to adapt the quantity of memory used by the Linkurious Enterprise instance.
When setting --max-old-space-size, please take into account the full Node.js process memory,
subtracting roughly 50MB to the allocated memory of the container.
Considering you are not using the embedded Elasticsearch instance:
docker run -d --rm \
-p 3000:3000 \
--mount type=bind,src=/path/to/my/data/folder,dst=/data \
--memory 1024m \
-e NODE_OPTIONS='--max-old-space-size=984' \
linkurious:4.3.10
We do not recommend using the embedded Elasticsearch in a memory-limited container.
You may also pass in environment variables that can be expanded in the configuration
Please read the previous section on starting a Linkurious Enterprise instance using docker, and the section on fault tolerance.
A simple way to test out Linkurious Enterprise using Kubernetes is to create a simple deployment, using only
one replica, and allocate a PersistentVolume for both of the volumes (lke-data,
lke-elasticsearch) described above.
In production, however, you would want to follow the fault tolerance guide and use a StatefulSet, with a main/failover strategy, and the appropriate strategy configured for your load-balancer or ingress.
You can start quickly with our public helm chart.
Run the stop.sh script in the linkurious-linux directory.
Alternately, run menu.sh and click Stop Linkurious.
Run the stop.bat script in the linkurious-windows directory.
Alternately, run menu.bat and click Stop Linkurious.
Run the stop.sh.command script in the linkurious-osx directory.
Alternately, run menu.sh.command and click Stop Linkurious.
Linkurious Enterprise supports a cluster deployment mode which allows horizontal scaling and high availability. In cluster mode, one server instance is the "primary" and one or more instances are "secondary".
When a primary instance fails, its users are redirected (by a load balancer) to secondary instances, with a limited impact (see "limitations" for details).
When a secondary instance fails, its users are redirected (by a load balancer) to other instances in the cluster, where they can find their working objects (i.e., visualizations, queries, alerts, cases, etc.) as they last saved on the instance they were working on.
cluster configuration:"cluster": {
"enabled": boolean,
"mode": "primary" | "secondary",
"maxDriftMs": number
}
enabled: Whether cluster mode is enabled or disabled.mode: Whether the instance is a primary or a secondary one.maxDriftMs(default: 900000, i.e., 15 minutes): Time taken by the primary instance to schedule/unschedule alerts created/updated by secondary instances, send email notifications and webhooks generated by the secondary instances and for the caches on different instances in the cluster to be cleared.1 Synchronization of servers must be done in a way that guarantees minimal state
drifts (i.e., lower than the configured maxDriftMs), and automatic resolution of data
conflicts.
When Linkurious Enterprise is deployed in cluster mode, the following limitations apply:
linkurious/data/config/production.json.manager.json and logger.json configuration files)
must not be modified in ways that will make the
configuration of different instances inconsistent (i.e., if you want to change a value in the
global configuration, you must set the same value on all instances manually).Cluster mode is designed to be used with a load-balancer (e.g. HAProxy or nginx). The load-balancer is responsible for redirecting queries from end-users to currently available servers in the cluster.
In a typical load-balancer configuration, you would expose the cluster as cluster.my-domain.org and have several servers in the cluster (e.g. primary.my-domain.org, secondary-1.my-domain.org and secondary-2.my-domain.org) handle the traffic.
When the server at secondary-1.my-domain.org becomes unavailable, the load-balancer redirects users working on this server to one of the available servers.
You must use a load-balancer that supports session persistence to make sure that end-users are consistently redirected to the same server during their work (see this example using nginx or this example using HAProxy).
Example nginx configuration (see details in the nginx documentation):
# Define the upstream group for your Linkurious Enterprise instances
upstream linkurious_backend {
# Selects a server randomly for each request (respecting sticky session)
random;
# --- Sticky Sessions via Cookies ---
# srv_id: name of the cookie
# expires=2h: cookie lifetime
# domain: scope of the cookie
# path=/: cookie applies to the whole site
# httponly: prevents client-side script access
sticky cookie srv_id expires=2h domain=cluster.my-domain.org path=/ httponly ;
# --- Backend Servers ---
# max_fails=3: Consider server down after 3 consecutive failed attempts.
# fail_timeout=30s: Mark the server down for 30 seconds before retrying.
server primary.my-domain.org:80 max_fails=3 fail_timeout=30s;
server secondary-1.my-domain.org:80 max_fails=3 fail_timeout=30s;
server secondary-2.my-domain.org:80 max_fails=3 fail_timeout=30s;
}
server {
listen 80;
server_name cluster.linkurious.org;
# --- Location Block for Proxying ---
location / {
# Pass requests to the upstream group defined above
proxy_pass http://linkurious_backend;
}
}
dataSource.* configuration entry).cluster.mode must be set to "secondary".db can be set to a different SQL server (if sync is guaranteed, see "How it works" section).dataSources.*.graph.url/username/password can be set to a different server (if sync is guaranteed, see "How it works" section).access.saml2/oauth2 can be set to a different server if the backing directory contains the same accounts (see "How it works" section).When updating the Linkurious Enterprise cluster:
To edit the Linkurious Enterprise configuration, you can either edit the configuration file located at linkurious/data/config/production.json
or use the Web user-interface:
Using an administrator account, access the Admin > Global configuration menu to edit the Linkurious Enterprise configuration:
Some configuration changes will require restarting the server to be applied. Linkurious Enterprise will notify you and offer you to restart from the Web UI only if you made the changes from the Web UI. If you modified the production.json file manually, changes will not be applied immediately, and you will need to restart Linkurious Enterprise.
Configuration sections are organized by category.
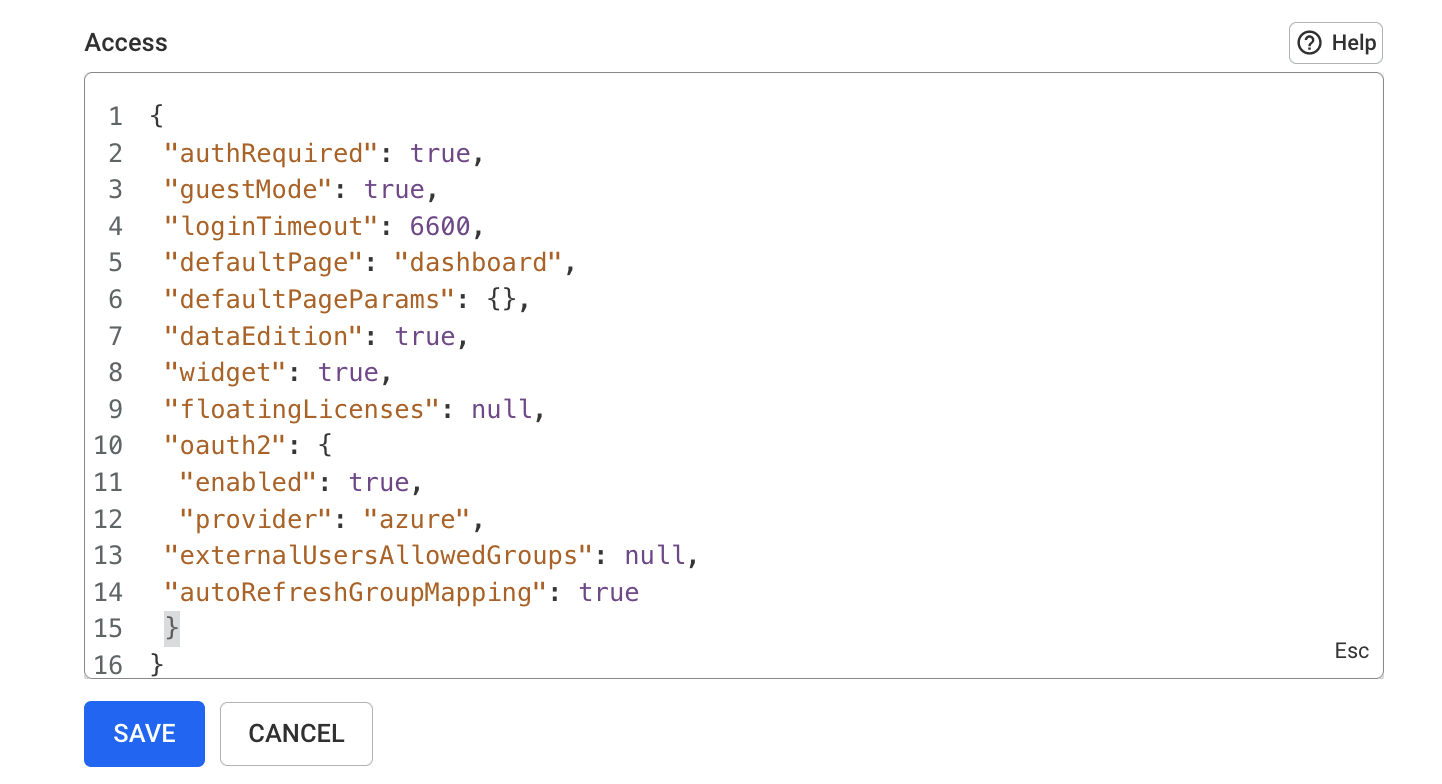
ℹ️ Password fields are obfuscated in the Web UI, but can be edited.
You can also use dynamic variables in the configuration: these variables will be replaced by values read from environment variables or files at runtime.
For example, if you set {"myKey": "$ENV:NEO4J_PASSWORD"} in the configuration, the value of
myKey will take the value of the NEO4j_PASSWORD environment variable at runtime.
The following variable expressions are supported:
$ENV:VAR1: replaced with the value of the VAR1 environment variable;$ENV-NUMBER:VAR2: replaced with the value of the VAR2 environment variable, interpreted as a number;$ENV-JSON:VAR3: replaced with the value of the VAR3 environment variable, interpreted as JSON;$FILE:/path/to/file: replaced with the content of the file at /path/to/file, parsed as UTF-8 text.In the configuration object, you can use the following syntax:
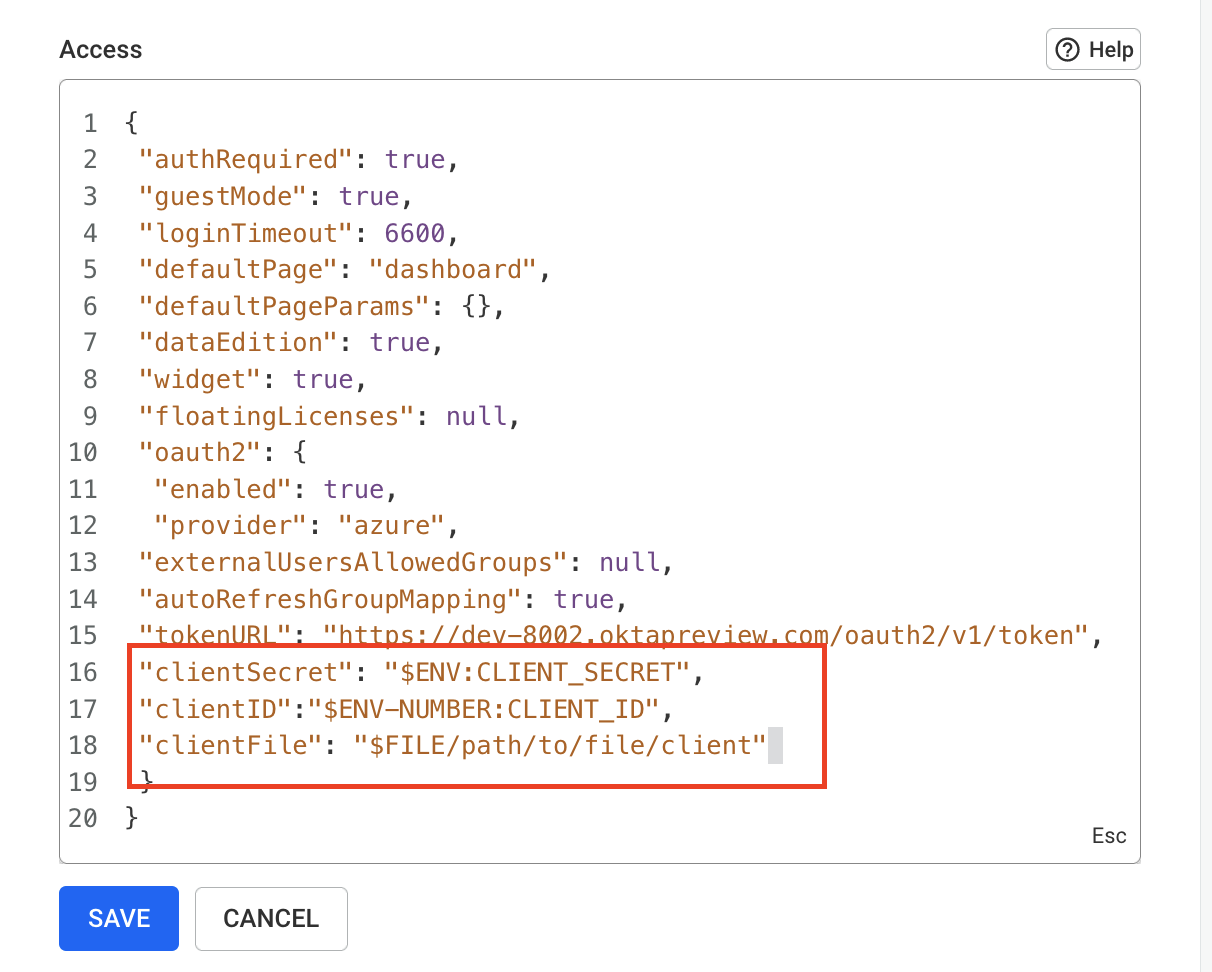
When you are finished changing, click Save.
ℹ️ Limitations with the
$ENV-JSONexpansion:
$ENV-JSONdoes not work when used at the root level or at the first level of the configuration (for example for the wholeserver.*configuration key).$ENV-JSONdoes not work when used at any level within thedataSource.*configuration key.
🛡 Security considerations for configuration variable expansion:
$FILEexpansion is limited to files of 1MB or less$FILEexpansion can be constrained to only resolve files under a certain folder, for example, setting theLKE_CONFIG_INJECTABLE_FILE_ROOTenvironment variable to./my-filesonly allows files under thelinkurious/data/my-filesfolder to be injected in the configuration.- Variable expansion can be switched to read-only mode by setting the
LKE_CONFIG_EXPANSION_READ_ONLYenvironment variable to "true".
In addition to the configuration file, the following environment variables can be used to change the behavior of Linkurious Enterprise:
LKE_PLUGINSLKE_PLUGINS='["query-ai"]'["config-migration", "plugin-manager", "query-ai", "third-party-data", "webhook-manager"];./data/plugins-available to ./data/plugins) at startup.LKE_PLUGINS_ENABLE_UPLOADLKE_PLUGINS_ENABLE_UPLOAD=truefalseLKE_STD_LOG_FORMATLKE_STD_LOG_FORMAT=jsontexttext) or JSON (json).
This is mainly used to make the Docker version of Linkurious Enterprise generate JSON logs.LKE_CONFIG_INJECTABLE_FILE_ROOTLKE_CONFIG_INJECTABLE_FILE_ROOT=./my-config-files/$FILE variables to be resolved in this folder. Relative paths are
resolved from the data-folder (see details).LKE_CONFIG_EXPANSION_READ_ONLYLKE_CONFIG_EXPANSION_READ_ONLY=truefalseLKE_DATA_PATHLKE_DATA_PATH=/var/lib/linkurious-data../datasystem folder.NODE_EXTRA_CA_CERTSNODE_EXTRA_CA_CERTS=./customCA.pemNODE_TLS_REJECT_UNAUTHORIZEDNODE_TLS_REJECT_UNAUTHORIZED=01NODE_USE_ENV_PROXYNODE_USE_ENV_PROXY=101, will honor the HTTP_PROXY, HTTPS_PROXY and NO_PROXY environment variable to
proxy outgoing HTTP(S) traffic.HTTP_PROXY or HTTPS_PROXYHTTPS_PROXY=http://my-proxy.my-company.com:8080HTTPS_PROXY=http://username:password@my-proxy.my-company.com:8080NODE_USE_ENV_PROXY=1, will use the proxy at the given URL to proxy
outgoing HTTP traffic (when using HTTP_PROXY) or HTTPS traffic (when using HTTPS_PROXY)NO_PROXYNO_PROXY=localhost,127.0.0.1,.my-company.com (see details)NODE_USE_ENV_PROXY=1, will not use the proxy defined by HTTPS_PROXY
(or HTTP_PROXY) for the matching IPs or domains.On Docker:
When Linkurious Enterprise is installed as a service:
"env" section of server in the
./manager/manager.json file, under the data-folder.A configuration overlay is a mechanism that allows to maintain a subset of configurations in a separate file
(called product-overlay.json), which is automatically merged with the main configuration.
This mechanism enables:
For example, if you want to change the server.listenPort configuration from 3000 to 8080 and prevent users from
changing it back, you can use the overlay mechanism as follows:
production.json):{
// [...]
"server": {
"listenPort": 3000,
"listenPortHttps": 8443,
"clientFolder": "server/public",
"basePath": "my-folder"
}
// [...]
}
production-overlay.json):{
"version": "4.3.10",
"server": {
"listenPort": 8080,
"basePath": "$UNSET"
}
}
The values of the overlay file will be merged field-by-field with the configuration file, resulting in the following final configuration:
{
// [...]
"server": {
"listenPort": 8080, // "listenPort" has be overwritten by the overlay
"listenPortHttps": 3443,
"clientFolder": "server/public",
// "basePath" has been removed by the overlay
}
// [...]
}
To set up an overlay configuration file:
production-overlay.json, stored in data directory, along the main configuration file
(production.json);version property, with a value lower or equal to the current version of Linkurious Enterprise
(e.g., 4.3.10) (see how the overlay version property works);Overlay-specific behaviors to keep in mind:
"$UNSET" value in the overlay file.The overlay mechanism allows automatic deployment tools to push and freeze a subset of configurations.
A typical example is the need to preconfigure authentication and the external user-data store connection in a
Kubernetes deployment. We use this mechanism in our Kubernetes deployment via the config
value of our Helm chart.
💡 The same mechanism is relevant for standard deployments performed via automation scripts.
Over different Linkurious Enterprise versions, configuration fields may be added, removed, or migrated. The version property
indicates for which version of Linkurious Enterprise a configuration file was written.
The version of the main configuration file and the version of the overlay file may be different.
When the application starts, the following steps are performed:
version is lower than the current version of Linkurious Enterprise, it is migrated
and the migrated configuration is written back to the configuration file.version is lower than the current version of Linkurious Enterprise, it is migrated (the migrated
overlay is not written back to the overlay file, but only used for the merge process).When loading the configuration, the application reads both the main configuration file and the overlay file, and merges them together to get the final configuration used at runtime.
When the configuration is updated at runtime (e.g. via the Web UI of the API), the new configuration is merged with the overlay before being written back to the main configuration file.
The merge process is a field-by-field merge between the main configuration and the overlay file:
overlay, the value from the overlay is used;A typical example involving an array in the configuration is the data-source field.
If the overlay has a single data-source configured and a user manually adds a second data-source, the final
configuration will have an array of two data-sources, where the first one matches the one defined in the overlay.
If a second data-source is added later to the overlay, it will be merged with the second existing data-source in the
main configuration, potentially creating an invalid configuration.
To remove an existing property from the configuration file, you should define the desired property
with the special value "$UNSET".
A typical example, is when configuring an external user-data store.
A robust overlay configuration for defining a MySQL database will use the
"storage": "$UNSET" as follows:
{
"version": "4.3.10",
"db": {
"name": "linkurious",
"username": "MYSQL_USER_NAME",
"password": "MYSQL_PASSWORD",
"options": {
"storage": "$UNSET",
"dialect": "mysql",
"host": "MYSQL_HOST",
"port": 3306
}
}
}
The necessity of using $UNSET for the db.options.storage field requires to unroll the merge process:
db field in the main configuration is the following (see SQLite configuration):{
// [...]
"db": {
"name": "linkurious",
"options": {
"dialect": "sqlite",
"storage": "server/database.sqlite"
},
},
// [...]
}
overlay without using $UNSET, using the following overlay:{
"version": "4.3.10",
"db": {
"name": "linkurious",
"username": "MYSQL_USER_NAME",
"password": "MYSQL_PASSWORD",
"options": {
"dialect": "mysql",
"host": "MYSQL_HOST",
"port": 3306
}
}
}
db.options.storage field, which is not valid for MySQL. This would
be detected as an invalid configuration and prevent the application from starting.{
// [...]
"db": {
"name": "linkurious",
"username": "MYSQL_USER_NAME",
"password": "MYSQL_PASSWORD",
"options": {
"dialect": "mysql",
"storage": "server/database.sqlite", // unexpected "storage" field was kept because "$UNSET" was not used
"host": "MYSQL_HOST",
"port": 3306
}
}
// [...]
}
Linkurious Enterprise starts 3 separate processes when launched:
node (or node.exe): The internal process managernode (or node.exe): The Linkurious Enterprise Server processjava (or java.exe): The embedded Elasticsearch full-text search server (if enabled).Check if these processes are alive by opening the menu from the Linkurious Enterprise directory (see how to open it on each operating system below):
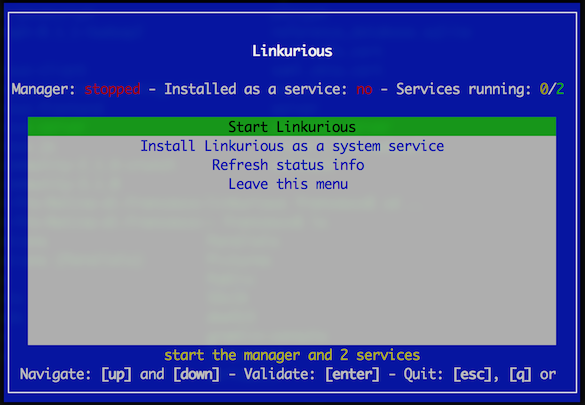
Run menu.sh. Alternately, run menu.sh status.
Run menu.bat. Alternately, run menu.bat status.
Run menu.sh.command. Alternately, run menu.sh.command status.
The status of the API can be retrieved using a browser or a command line HTTP client like cURL.
To retrieve the API status, send a GET request to http://127.0.0.1:3000/api/status
(replace 127.0.0.1 and 3000 with the actual host and port of your server).
// example response
{
"status": {
"code": 200,
"name": "initialized",
"message": "Linkurious ready to go :)",
"uptime": 8633
}
}
To retrieve the API status, send a GET request to http://127.0.0.1:3000/api/version
(replace 127.0.0.1 and 3000 with the actual host and port of your server).
// example response
{
"tag_name": "4.3.10",
"name": "Brilliant Burrito",
"prerelease": false,
"enterprise": true
}
The logs of the application are located in linkurious/data/manager/logs folder:
linkurious-server.log: Linkurious Enterprise server outputembedded-elasticsearch.log: embedded Elasticsearch outputFor a structured version of the Linkurious Enterprise server logs in JSONL format, see the linkurious/data/logs folder:
linkurious.log: Linkurious Enterprise server general log, with timestampslinkurious.exceptions.log: Linkurious Enterprise server exceptions log, with timestampsAs part of your license, you have access to a customer service, which will help you resolve issues discovered while using our products.
If you are a commercial partner, you also have access to the support service, and can submit demands on behalf of customers too.
Unless your organization has a premium support agreement, the support service team will provide a first answer within 2 working days (timezone: France, 9 hours per day, 5 days per week, excluding French public holidays).
If you face issues while working with Linkurious Enterprise or require assistance using our product, you can submit your request as described below.
For the best experience, it is suggested to open a new request via our online support portal. In this way you can benefit from:
As an alternative, you can still submit a new request by sending an email to support@linkurio.us, however you will not benefit from the above-mentioned features.
You can access your online support portal at https://support.linkurious.com.
To authenticate, use your Linkurious Customer Center credentials (if you do not have access, you can ask your team to invite you).
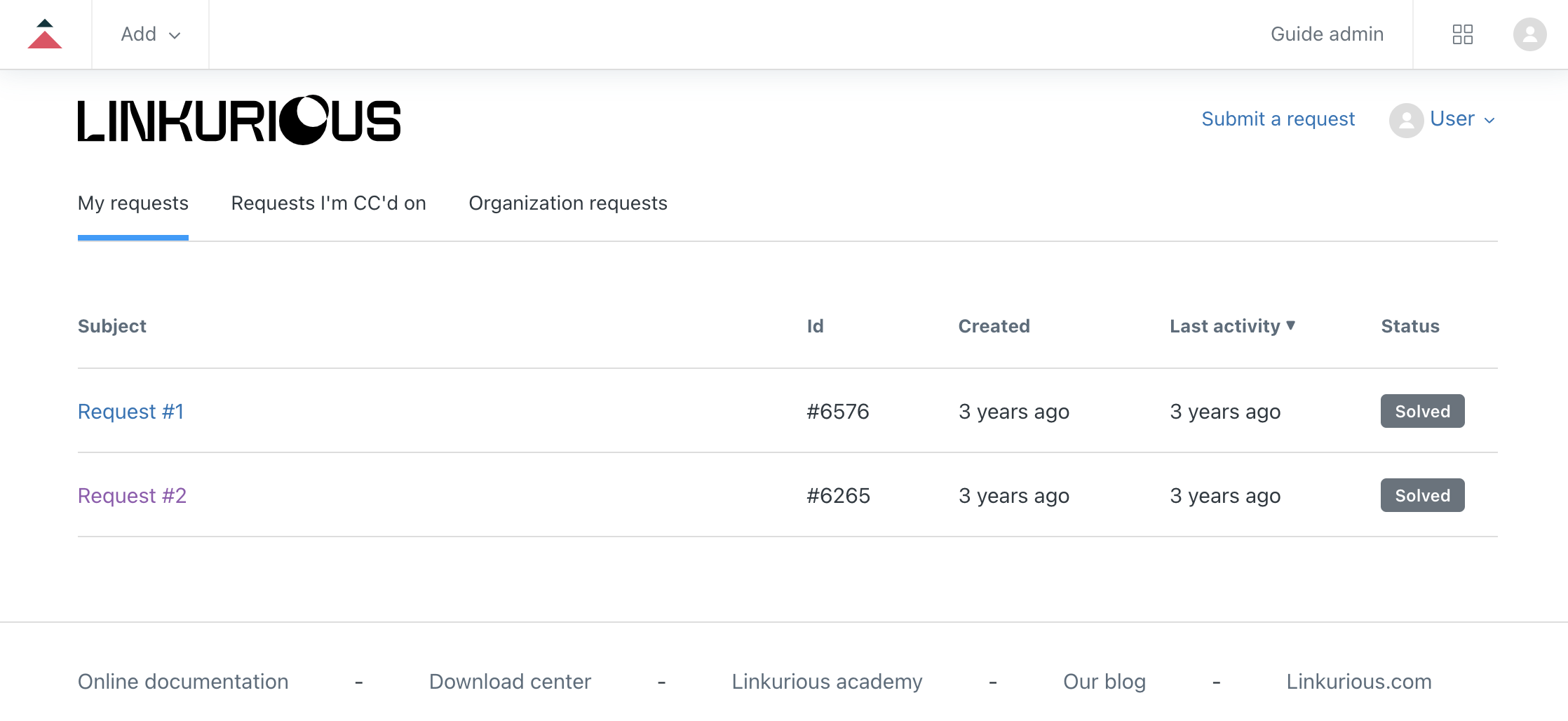
After logging into the online support portal, you will see your dashboard from where you can:
By clicking on the request's subject, you can access the full history and interact with the support team as needed.
After logging into the online support portal, you will be able to submit a new request.
When submitting a new request, it is suggested to follow a few best practices to minimize the resolution time:
Subject that describes your problem;Subject any useful information to determine the correct SLA
(e.g. usually it is based on the criticality classification of the problem: Blocking, Critical, Major, etc.);Here is an example of a suitable request (you can either embed images in the description or attach additional files separately).
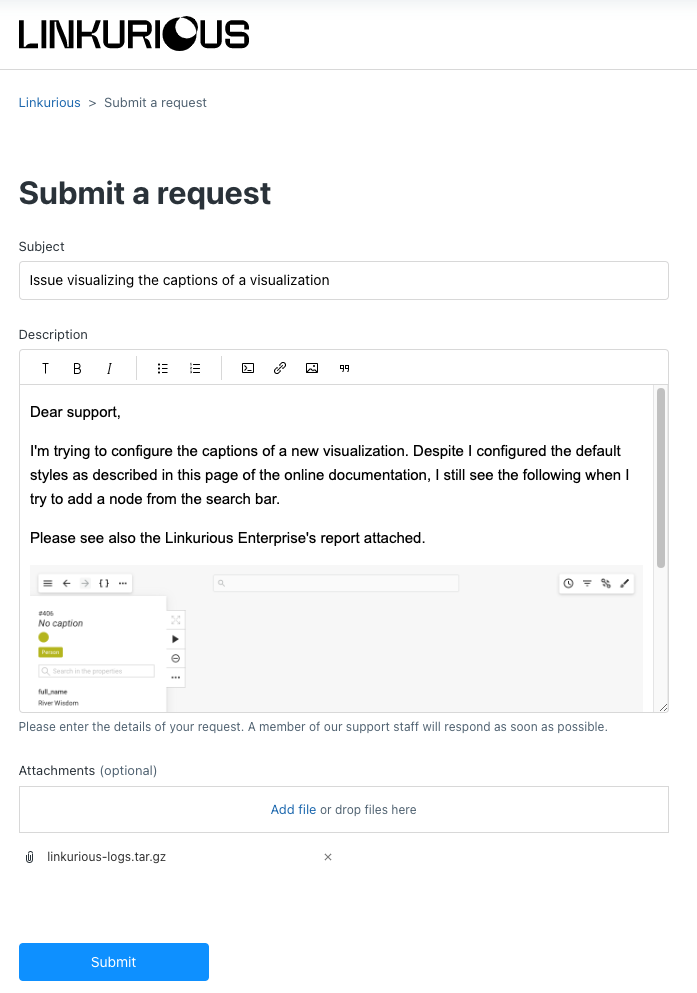
After pressing Submit, you will receive an automatic confirmation email. You can reply to it to
add more contents or follow up with the support team.
The Linkurious Enterprise report is an archive that contains all the information needed to enable our support team to provide a resolution as quickly as possible.
The archive contains system logs, Linkurious Enterprise configurations, and does not contain any sensitive data related to your graph database.
There are two possible ways of collecting the report:
You can download an automatically generated report from the Web user interface via the Admin > Global configuration menu:
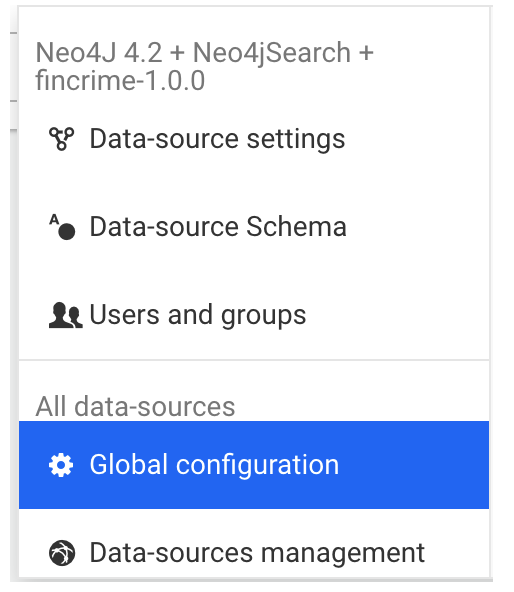
At the end of the page, click Download Report:

It can happen that the system fails to start due to an error. In that case, the following files should be added manually to a compressed archive:
The application logs: the manager and logs folders stored in <linkurious-installation>/data
The application configuration (optional): the production.json file stored in <linkurious-installation>/data/config
Depending on your situation, the configuration file (
production.json) may sometimes contain clear-text passwords. Consider redacting such passwords before sharing your configuration with the support team.
In some cases the support team may need some extra logs or data only accessible from your browser, please follow the below steps to collect them.
Option + ⌘ + J (on macOS); Shift + CTRL + J (on Windows/Linux).
Option + ⌘ + J (on macOS); Shift + CTRL + J (on Windows/Linux).
This file may contain sensitive data, this is usually not asked if not for specific complex issues. Always be careful when sharing this file. In case of doubts on those steps we suggest involving your internal IT / security team.
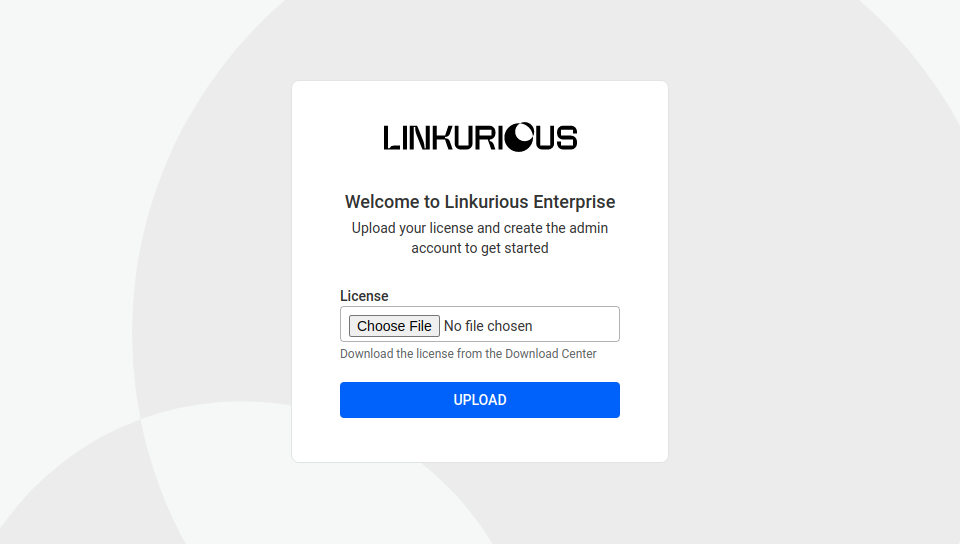
When running Linkurious Enterprise for the first time, you are asked to provide a valid license. You can download your license file from our Customer center.
Once you have provided a valid license, we ask you to create your Admin account.
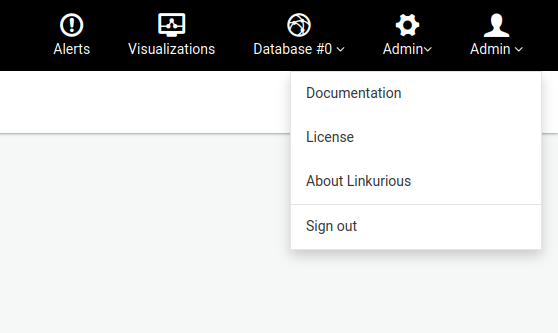
Click on the top right hand Admin & Settings menu and select Licenses management to access the license dashboard.
From here, you can have a look at:
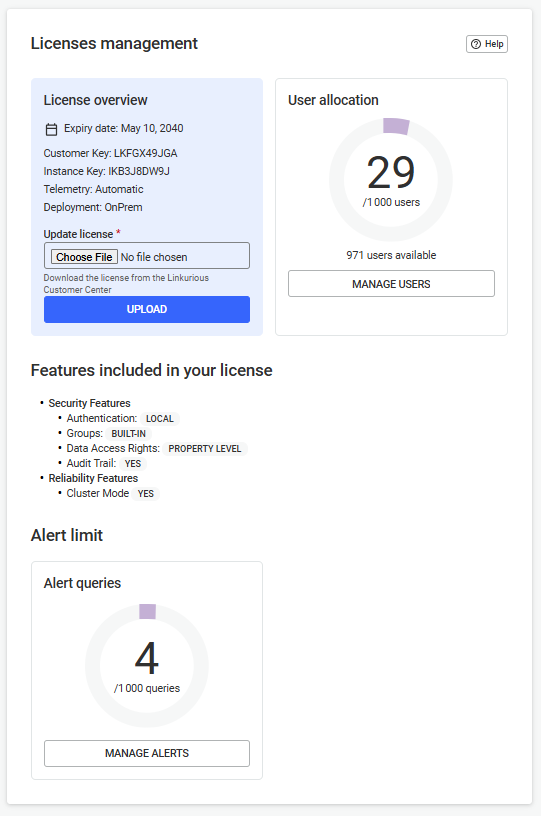
When your license expires, you are notified within the Linkurious Enterprise interface and asked to upload a new one.

If your license with Linkurious has expired, please contact our sales team. In case your license has already been renewed, you can update the license. To achieve this:
From the license dashboard, click on Choose file in the Update license section, then click Upload.
Linkurious Enterprise is scanned continuously for vulnerabilities both in the application code and in third-party dependencies using static code analysis tools and dependency scanning tools.
While doing that, we regularly have Linkurious Enterprise tested by independent third-party security specialists to test it for exploitable vulnerabilities (a.k.a. pentesting).
When a security vulnerability is discovered in Linkurious Enterprise:
Our vulnerability reports include a severity level. This severity level is based on our self-calculated CVSS score (Common Vulnerability Scoring System) for each specific vulnerability. CVSS is an industry standard vulnerability metric (learn more about CVSS).
For CVSS v3, we use the following severity rating system:
| CVSS v3 score range | Report severity level |
|---|---|
| 0.1 - 3.9 | Low |
| 4.0 - 6.9 | Medium |
| 7.0 - 8.9 | High |
| 9.0 - 10.0 | Critical |
Below are a few examples of vulnerabilities which may result in a given severity level. Please keep in mind that this rating does not take into account details of your installation and are to be used as a guide only.
Critical severity vulnerabilities usually have most of the following characteristics:
For critical vulnerabilities, it is advised that customers patch or upgrade as soon as possible, unless you have other mitigating measures in place. For example, a mitigating factor could be if your installation is not accessible from the Internet.
High severity vulnerabilities usually have some of the following characteristics:
Medium severity vulnerabilities usually have some of the following characteristics:
Low severity vulnerabilities typically have very little impact on an organization's business. Exploitation of such vulnerabilities usually requires local or physical system access. Vulnerabilities in third party code that are unreachable from Linkurious Enterprise's code may be downgraded to low severity.
If you have discovered an unknown security vulnerability in Linkurious Enterprise (or in an associated product or service), please get in touch with us via email: security@linkurious.com
Before starting to explore the content of your graph database using Linkurious Enterprise, you need to import data in your graph database.
The following sections will help you import data into your graph:
If you already have data in your graph database or you don't need to import anything, see how to configure your graph database with Linkurious Enterprise.
To import data into Neo4j, you have a number of solutions depending on your needs.
If your data is static:
If you are streaming data, you can use Neo4j Streams Kafka Integration to ingest any kind of Kafka event into your graph.
For simple CSV files, to get you quickly up and running, you can use the official Linkurious CSV importer plugin to import data directly through Linkurious Enterprise. The plugin provides a simple user interface to upload CSV files and easily define relationships.
If you are using spreadsheets, you can easily transform the data within to Cypher queries with this tutorial.
Finally, If your data is in JSON format, you could use the
load JSON functionality from APOC
By default, a pre-loaded movie database is available in Neo4j Desktop.
You can also get started with Neo4j Sandbox and launch a free Neo4j online instance with an example dataset
If you are still not sure, or your data import needs are more complex, or if you need to get help from professionals, contact us and we will be happy to answer your questions.
To import data into Memgraph, you have a several options depending on your needs.
Memgraph has features to:
CSV data from filesJSON data from filesCYPHERL files with Cypher queries Please refer to the Memgraph documentation about data import for details.
To import data into Amazon Neptune, you have a several options depending on your needs.
Neptune supports importing data using:
INSERT statements addV and addE stepsNeptune supports migrating data from another source using Amazon DMS. Please refer to the list of supported sources for data migration.
If you are migrating data from Neo4j to Neptune, the steps are:
CALL apoc.export.csv.all("neo4j-export.csv", {d:','})git clone git@github.com:awslabs/amazon-neptune-tools.gitmvn package in ./amazon-neptune-tools/neo4j-to-neptune/java -jar ./amazon-neptune-tools/neo4j-to-neptune/target/neo4j-to-neptune.jar convert-csv -i ./neo4j-export.csv -d output --infer-typesPlease refer to the Cosmos db online documentation for details on how to load data into Cosmos db.
For detailed information, please refer to the following page: https://cloud.google.com/spanner/docs/import-export-overview. If you have any further questions or require additional assistance, do not hesitate to contact our support team.
For detailed information, please refer to the BigQuery documentation about data import.
If you have any further questions or require additional assistance, do not hesitate to contact our support team.
Importing data into Linkurious using a CSV file is simple and efficient. To use the CSV import feature, you must have a connected graph database.
Administrators can create reusable import templates, allowing themselves and other users to quickly and consistently import data into Linkurious.
You can start creating a template from either:

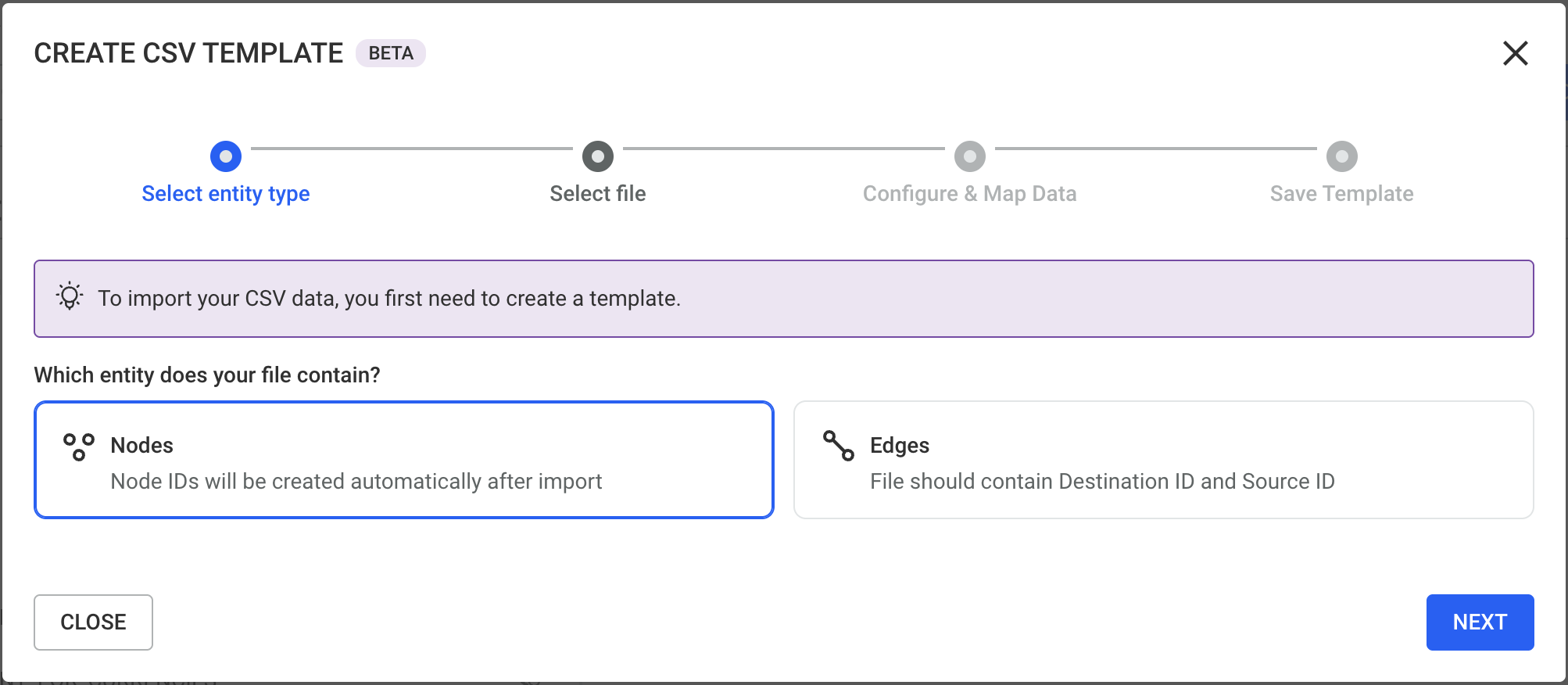
First, choose the entity type for the data you want to import. Select whether your CSV file contains:
Your selection determines how the data will be structured and mapped during import.
Note: When importing edges, your CSV file must include information about the nodes the edges connect (e.g., source and target identifiers).
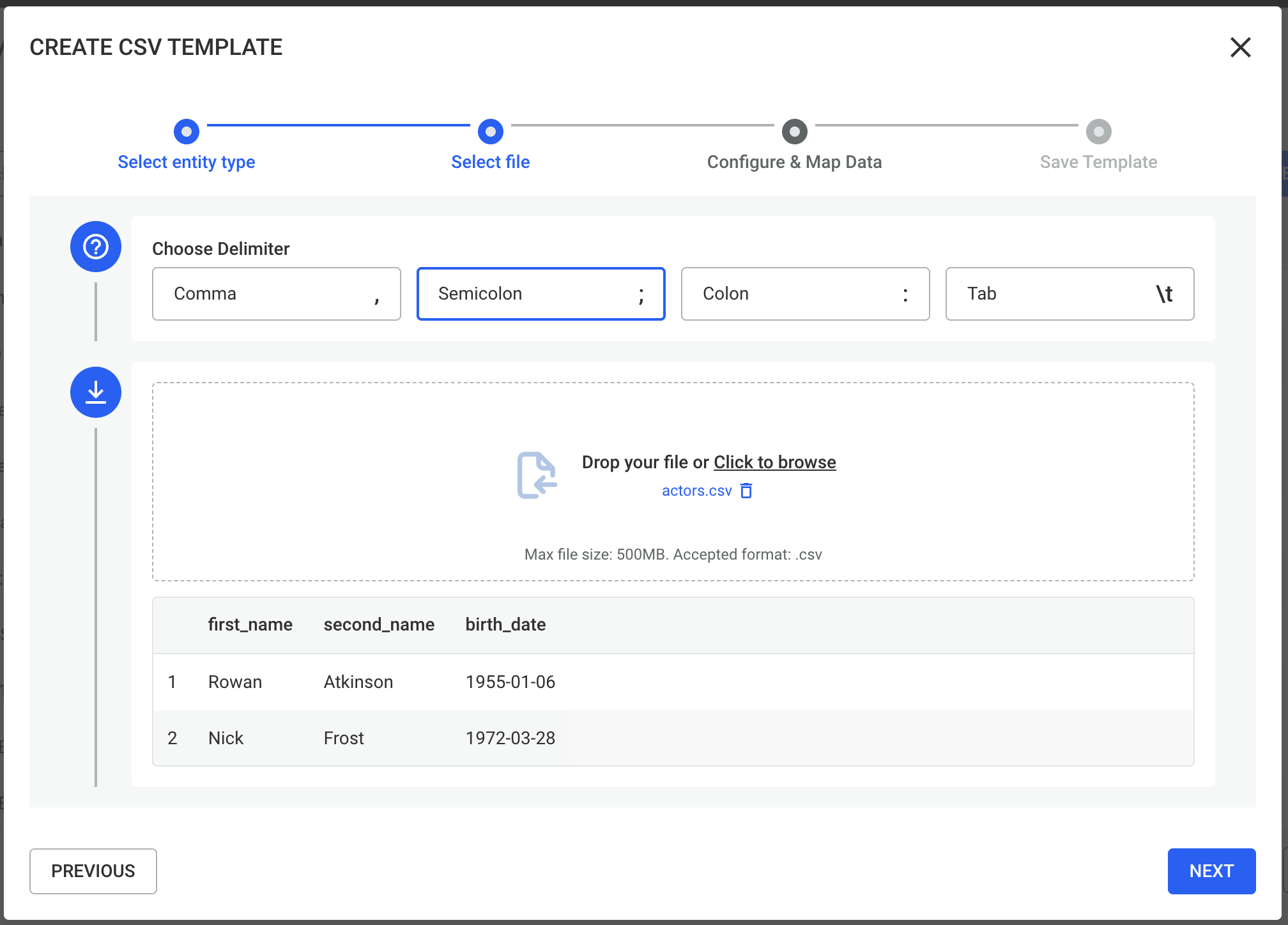
Next, upload your CSV file and select the delimiter used in the file (for example, comma, semicolon, etc.).
Once uploaded, the file will be displayed in a table preview so you can verify that the data has been correctly parsed.
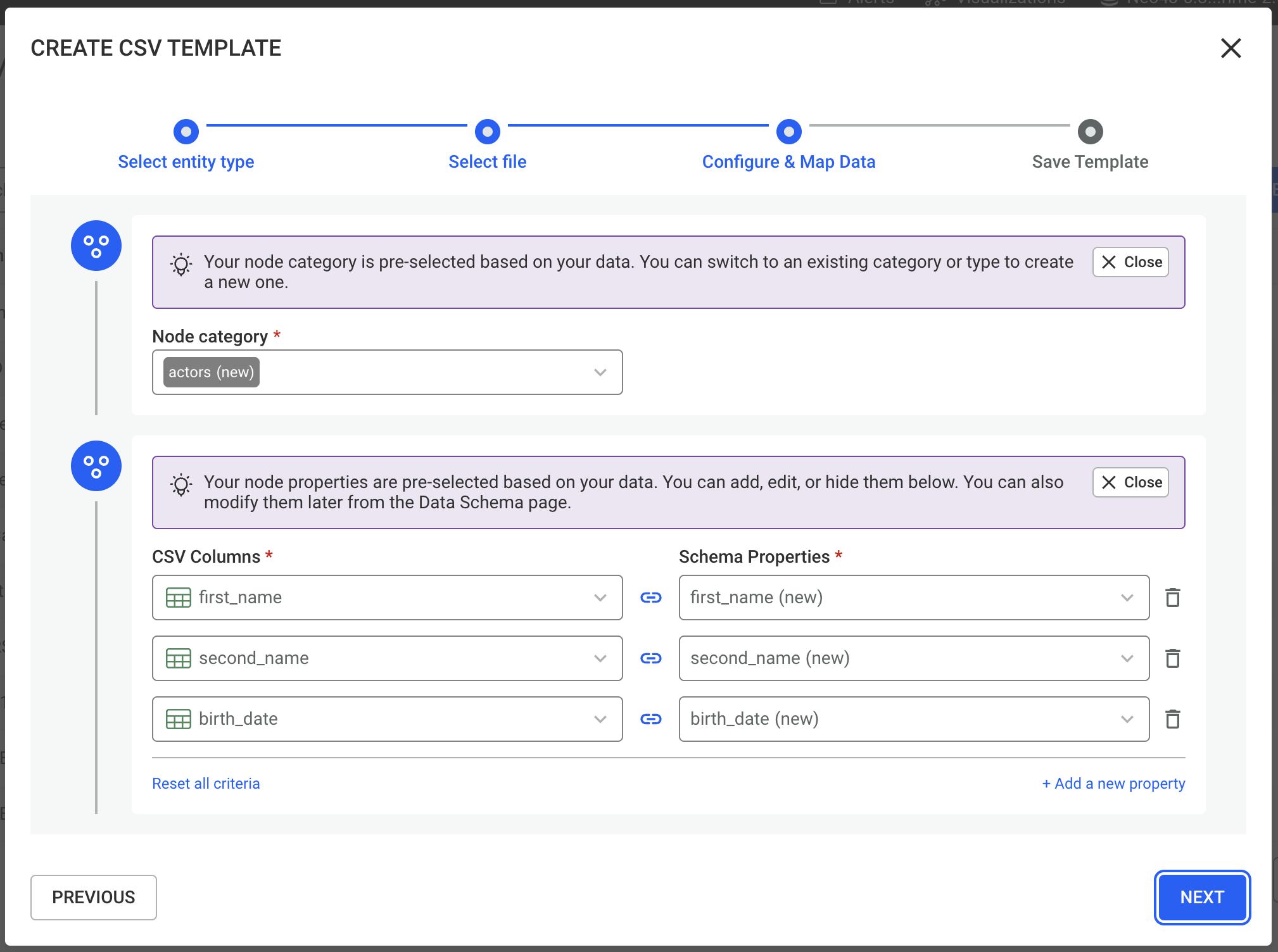
In this step, you map the columns of your CSV file to the structure of your connected datasource.
Linkurious will automatically suggest:
You can accept these suggestions or manually select:
Additional details for edge mapping:
When importing edges, you must define how the source and target nodes are identified. This typically involves mapping CSV columns to existing node identifiers (such as ID properties) so Linkurious can correctly create the relationships.
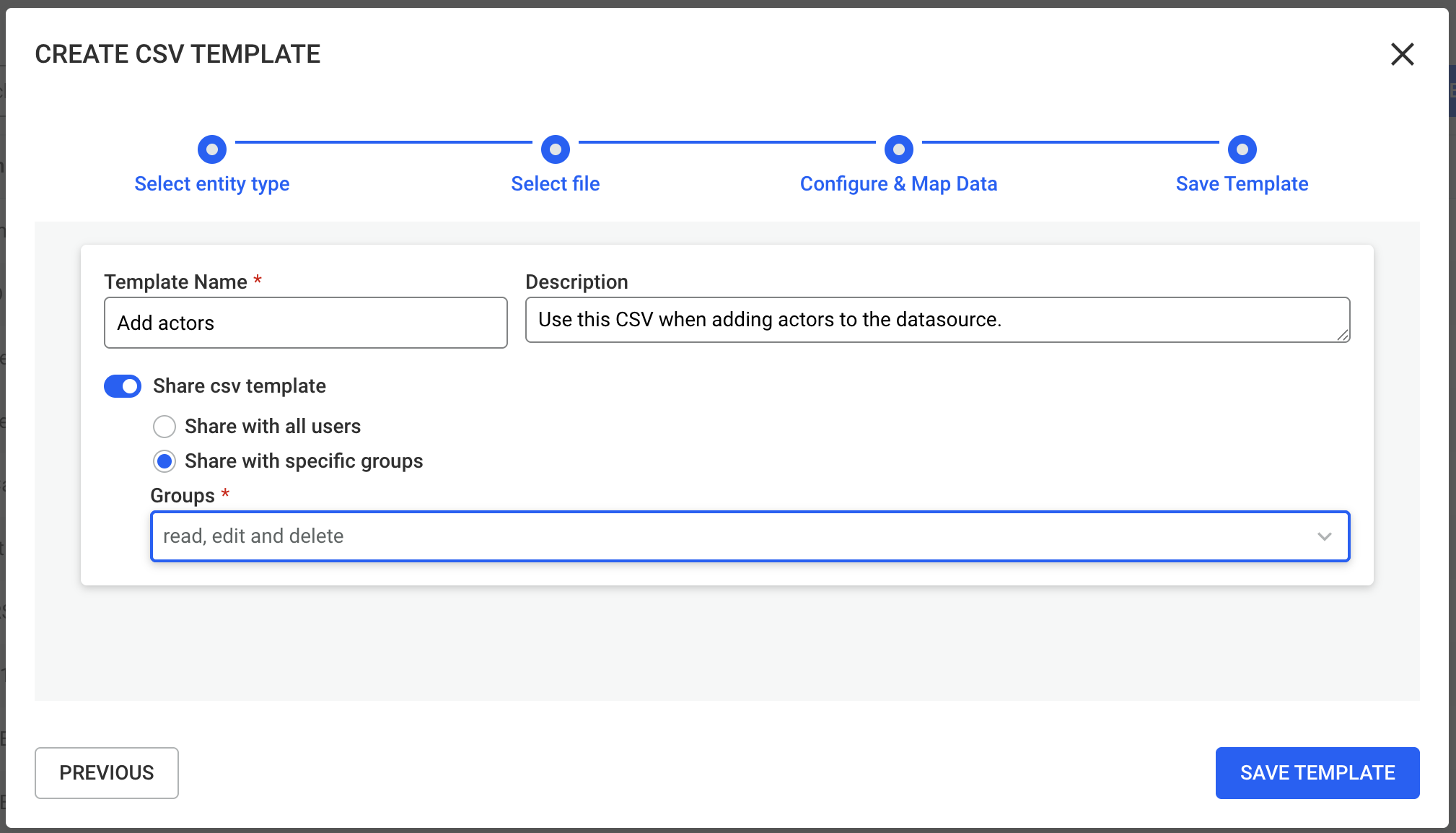
In the final step, provide:
This allows you to control who can use the template.
All CSV templates are available under:
Resources Management → CSV Templates
From this tab, administrators can:
All completed CSV imports can be viewed under:
Resources Management → CSV Imports
From this tab, administrators can:
When saving a visualization or a case, Linkurious Enterprise only stores the ID references to the nodes
and edges stored in your graph database.
When updating your graph data you need to make sure your graph engine preserves those
references to avoid any data loss.
There are 2 different strategies for updating your graph data. Each strategy has its own advantages and risks.
This strategy consists in adding, removing or updating the nodes and edges within an existing
database.
You can use this strategy when you know exactly the nodes and edges that have changed since
your last database update.
After performing this update the following changes will be reflected in Linkurious Enterprise:
When you remove nodes and edges from Neo4j, the IDs of the deleted nodes and edges are
recycled when you later create new nodes and edges.
The consequence is that your existing visualizations in Linkurious Enterprise may contain references to
new nodes and edges unrelated to the existing context.
If you plan to incrementally remove data from Neo4j, we recommend you use
alternative identifiers before creating your visualizations.
This strategy consists in recreating your graph database from an external source.
You consider the current graph database stale, and you create a new graph database with fresh
data.
This strategy is useful when your current infrastructure does not allow you to keep track of
which nodes and edges are updated.
When you rebuild your graph database, new IDs will be assigned to all your nodes and edges, consequently breaking the references stored by Linkurious Enterprise. If you are planning to use this strategy, it is very important you configure alternative identifiers before creating your visualizations (only available with Neo4j).
In the unfortunate scenario that you have performed a database rebuild without configuring the alternative identifiers, Linkurious Enterprise will prevent access to your visualizations in an effort to prevent any data loss.
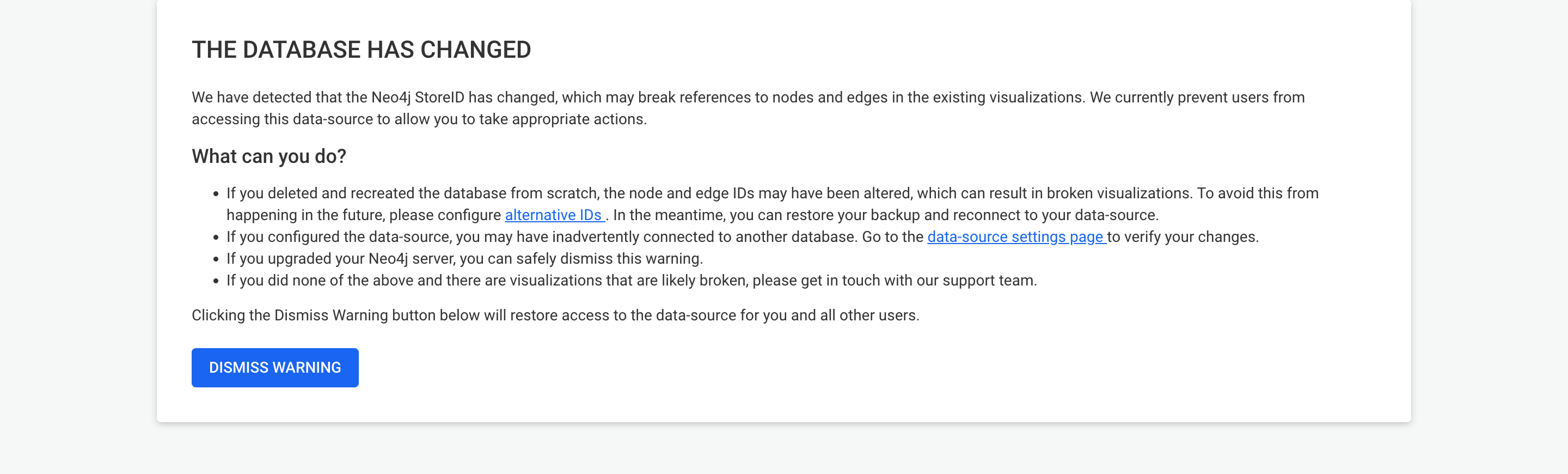
As an administrator, you can perform the following actions:
We release new versions of Linkurious Enterprise frequently with fixes and improvements.
The following pages will help you check for updates, back-up Linkurious Enterprise before updating, and update Linkurious Enterprise.
Using an administrator account, access the Your Username > About menu to open the Linkurious Enterprise info:
Click Check for updates to see if you are using the latest version.
Alternatively, you can check at http://linkurious.com/version/linkurious-enterprise.json
// example response
{
"tag_name": "v4.3.10", // latest version of Linkurious Enterprise
"message": null,
"url": "https://get.linkurio.us/" // where to download the latest version from
}
Follow these steps to perform a backup of your Linkurious Enterprise data:
linkurious/data folderPlease note that this procedure does not back-up your graph data, but only your Linkurious Enterprise configuration and user-data (visualizations, users, etc.).
If you are backing up your data before a system update through a standard installer
(i.e. Linux, Windows, Mac OS), make also a copy of the whole linkurious directory
to be able to perform an easy rollback in case of problems.
If you follow this procedure, you will be able to update Linkurious Enterprise to a newer version without loosing your configuration and user-data store. Your data will be automatically migrated to the newer version.
Before updating, make sure that you have backed-up your data in case something unexpected happens.
Even though this procedure is the standard one for a general update, some version (especially major releases) can introduce changes requiring extra attention. Please browse our public resources to verify whether there is something applicable to your specific configuration before proceeding with the update.
During the update procedure, if Linkurious Enterprise is running, it will be stopped. You will need to re-start Linkurious Enterprise after the update procedure.
linkurious-xxx-v4.3.10.zip into the root folder of your working Linkurious Enterprise directory (along the start stop and update scripts)update.sh, Mac OS: update.sh.command, Windows: update.bat).
In case of failures, run it again to revert the changes.If the update script fails, please check the update log located
at linkurious/data/logs/update.log for details.
If you use the Linkurious Enterprise Docker image, the only step to update Linkurious Enterprise is to use the new Docker image with the existing Linkurious Enterprise data volume.
This procedure only allows to undo an update and restore the version of Linkurious Enterprise that was installed just before the update, without loss of data.
This procedure requires that you have performed a full backup of Linkurious Enterprise before the update (see details in our backup guide).
If you are working on Linux, Windows or Mac OS:
linkurious folder to linkurious_previous (it is needed if you will reach to support for investigation)linkurious folder from your backupIf you use the Linkurious Enterprise Docker image:
A data-source is a conceptual representation of a graph database within Linkurious Enterprise. Visualizations and other user data created within Linkurious Enterprise will be associated their respective data-source.
Linkurious Enterprise can connect to some of the most popular graph databases:
For more details about supported versions for each vendor, please check our compatibility matrix.
Linkurious Enterprise is able to connect to several graph databases at the same time and lets you switch from one database to another seamlessly.
You can configure your data-sources via the Web user interface
or directly on the linkurious/data/config/production.json file.
Using an administrator account, access the Admin > Data menu to edit the current data-source configuration:
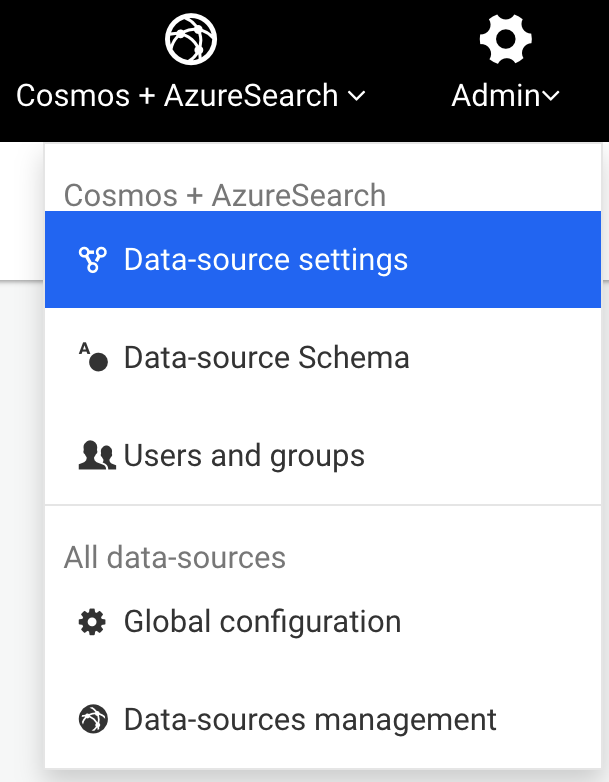
Edit the data-source configuration to connect to your graph database:
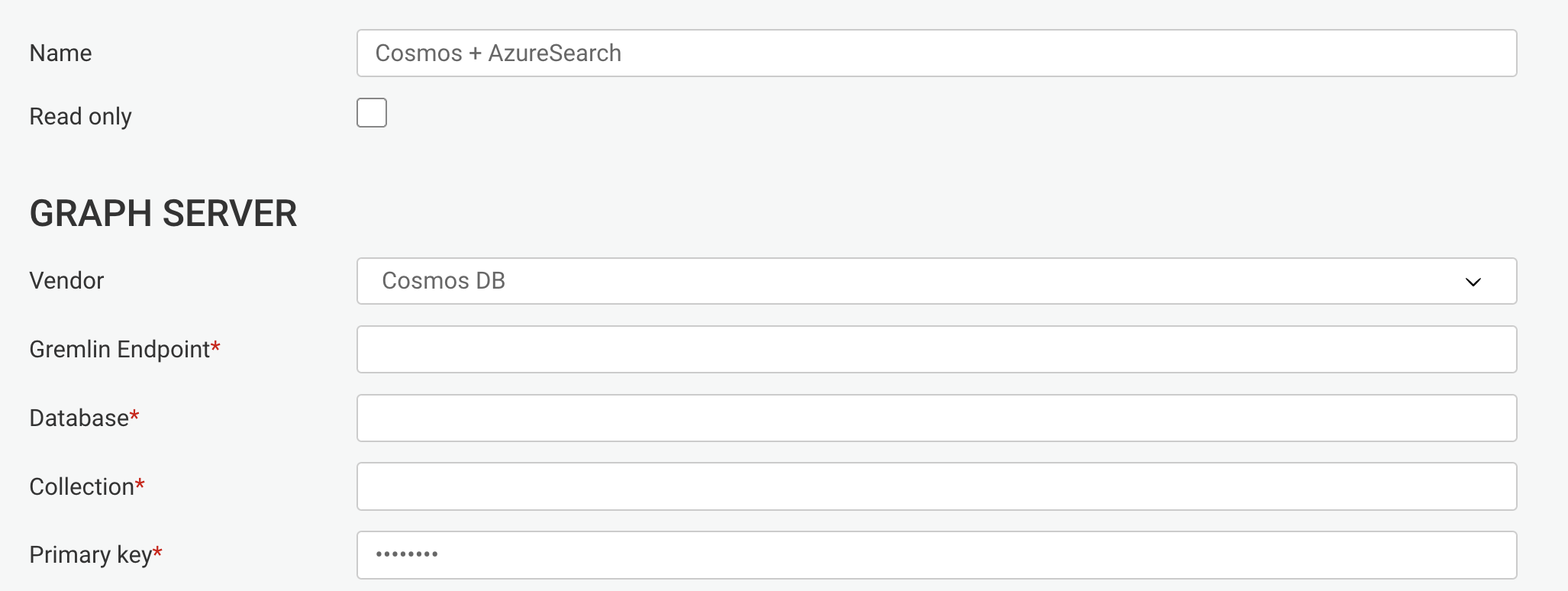
Submit the changes by hitting the Save configuration button.

Edit the configuration file located at linkurious/data/config/production.json.
See details for each supported graph database vendor:
Every data-source is uniquely identified with a sourceKey, a string computed
when Linkurious Enterprise connects to the database for the first time, based on internal information
from the data-source and saved in the configuration file.
Editing or removing the sourceKey of an existing configuration is strongly discouraged and may lead to unexpected behaviours.
Please check for supported Neo4j versions in our compatibility matrix.
To edit the Neo4j data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "neo4j",
"url": "neo4j://127.0.0.1:7687/",
"user": "myNeo4jUser",
"password": "myNeo4jPassword"
},
"index": {
"vendor": "neo4jSearch"
}
}
]
}
Example configuration using TLS:
{
"dataSources": [
{
"graphdb": {
"vendor": "neo4j",
"url": "neo4j+s://127.0.0.1:7687/",
"user": "myNeo4jUser",
"password": "myNeo4jPassword"
},
"index": {
"vendor": "neo4jSearch"
}
}
]
}
Learn more on how to configure SSL from the Neo4j documentation.
Linkurious connects to Neo4j via the
Boltprotocol. To do so, you need to enable the protocol in your Neo4j configuration file. If an HTTP/S URL is configured, Linkurious will automatically upgrade the connection to Bolt.
Supported graphdb options with Neo4j:
url (required): URL of the Neo4j server (http, https, bolt, bolt+s, bolt+ssc, neo4j, neo4j+s, neo4j+ssc)user (optional): Neo4j user (if credentials are enabled, see Neo4j credentials)password (optional): Neo4j password (if credentials are enabled)alternativeNodeId (optional): Name of the node property to use as reference in visualizations (see alternative IDs)alternativeEdgeId (optional): Name of the edge property to use as reference in visualizationslatitudeProperty (optional): Name of the node property to use for latitude (used in geo mode)longitudeProperty (optional): Name of the node property to use for longitude (used in geo mode)allowSelfSigned (optional, default false): Whether to allow self-signed certificatesdatabaseName (optional): Name of the database to be connectedallowVirtualEntities (optional, default true): Whether to allow virtual nodes and virtual edgesalternativeURLs (optional): Linkurious accepts a string array consisting of alternative Neo4j Bolt URLs for high availabilityignoredEdgeTypePrefixes (optional): List of edge type prefixes to be excluded in the schema samplingLinkurious Enterprise allows using Neo4j instances running on Neo4j Aura as data-sources.
Neo4j Aura is only supported for the Neo4j Aura instances running Neo4j engine v4.0 and later.
In order to have full-text search, you can choose among the following options:
If you just installed Neo4j, these steps will help you create credentials:
Alternatively, you can disable credentials in Neo4j by editing the Neo4j configuration at neo4j/conf/neo4j.conf
by uncommenting the following line:
dbms.security.auth_enabled=false
Note that configuring access rights is unnecessary on the Neo4j Community edition or if Neo4j credentials are disabled.
In Neo4j, access rights are managed using role-based access control. You can either:
Required privileges for graph exploration
In order to connect to a data-source, Linkurious requires a Neo4j user with the ACCESS,
EXECUTE PROCEDURE and EXECUTE FUNCTION privileges.
These privileges only allow Linkurious to connect to the data-source.
Additional privileges must be granted in order to interact with the graph database.
The Neo4j built-in PUBLIC role has these privileges on the default database.
These privileges can be granted on a database $name to a custom role $role by running the following Cypher commands:
GRANT ACCESS ON DATABASE $name TO $role;
GRANT EXECUTE FUNCTION * ON DBMS TO $role;
GRANT EXECUTE PROCEDURE * ON DBMS TO $role;
If the data-source is read-only, the MATCH privilege must be granted on part or all of the graph,
so that Linkurious can fetch nodes and edges.
The Neo4j built-in reader role has this privilege on all databases, except the system one.
This privilege can be granted by running the following Cypher commands:
GRANT MATCH {*} ON GRAPH $name TO $role;
If the data-source is read-write and the schema is in strict mode, the WRITE privilege must also be granted on the graph,
so that linkurious can create nodes and edges. This corresponds to the Neo4j built-in editor role.
GRANT WRITE ON GRAPH $name TO $role;
Additionally, if the schema is not in strict mode, the NAME MANAGEMENT privilege must also be granted on the graph,
so that linkurious can alter the schema. This corresponds to the Neo4j built-in publisher role.
GRANT NAME MANAGEMENT ON DATABASE $name TO $role;
Additional privileges required for full-text search
Neo4j search requires the INDEX MANAGEMENT privilege. This corresponds to the Neo4j built-in architect role.
GRANT INDEX MANAGEMENT ON DATABASE $name TO $role;
Elasticsearch doesn't require any specific privilege if incremental indexing is not used.
However, enabling incremental indexing on Elasticsearch requires the INDEX MANAGEMENT privilege.
On Neo4j 5.0 and onward, the EXECUTE ADMIN PROCEDURE privilege is also needed in order to manage Neo4j triggers.
And between Neo4j 5.0 and 5.3, the SHOW SERVER privilege is needed in check if the Neo4j server is a standalone instance or a cluster.
These privileges correspond to the Neo4j built-in admin role.
GRANT INDEX MANAGEMENT ON DATABASE $name TO $role;
GRANT EXECUTE ADMIN PROCEDURES ON DBMS TO $role; // Only on Neo4j 5.0 and onward
GRANT SHOW SERVER ON DBMS TO $role; // Only between Neo4j 5.0 and 5.3
Configuring alternative IDs indices is recommended.
The first step is to:
myAlternativeNodeIdIndex for nodes and myAlternativeEdgeIdIndex for relationships.Company, Person and City are the node categories while WORKS_FOR and LIVES_IN are the relationship types.myUniqueNodeId for nodes and myUniqueEdgeId for relationships.Once we have this information we can create the indices with the following Cypher queries:
CREATE FULLTEXT INDEX `myAlternativeNodeIdIndex` FOR (n:`Company`|`Person`|`City`) ON EACH [n.`myUniqueNodeId`] OPTIONS { indexConfig: { `fulltext.analyzer`: 'keyword' } }
CREATE FULLTEXT INDEX `myAlternativeEdgeIdIndex` FOR ()-[r:`WORKS_FOR`|`LIVES_IN`]-() ON EACH [r.`myUniqueEdgeId`] OPTIONS { indexConfig: { `fulltext.analyzer`: 'keyword' } }
If you are running a version of Neo4j older than v4.3 you may need to use the old syntax:
call db.index.fulltext.createNodeIndex('myAlternativeNodeIdIndex', ['Company', 'Person', 'City'], ['myUniqueNodeId'], {analyzer: 'keyword'})
call db.index.fulltext.createRelationshipIndex('myAlternativeEdgeIdIndex', ['WORKS_FOR', 'LIVES_IN'], ['myUniqueEdgeId'], {analyzer: 'keyword'})
If new node labels or edge types are added to Neo4j, it's necessary to recreate these indices with the full list of categories.
Once the indices are created, we can configure them:
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "neo4j",
"url": "neo4j://127.0.0.1:7687/",
"user": "myNeo4jUser",
"password": "nyNeo4jPassword",
"alternativeNodeId": "myUniqueNodeId",
"alternativeNodeIdIndex": "myAlternativeNodeIdIndex",
"alternativeEdgeId": "myUniqueEdgeId",
"alternativeEdgeIdIndex": "myAlternativeEdgeIdIndex"
},
"index": {
"vendor": "neo4jSearch"
}
}
]
}
It is possible to map user-groups in Linkurious Enterprise to users in Neo4j.
For example, if an administrator wants to make sure that all graph queries executed by members of the "investigators" user-group in Linkurious Enterprise are executed in Neo4j using the "invest-user" user, then the follopwing data-sources configuration should be used:
{
"dataSource": [
{
"name": "my neo4j database",
"graphdb": {
"vendor": "neo4j",
"user": "my-default-user",
"password": "mySecret1",
// omitted
"credentialsMappings": [
// the "investigators" group has the ID #12 (see group-management page)
{"groupIds": [12], "neo4jUser": "invest-user", "neo4jPassword": "mySecret2"}
]
},
"index": {
"vendor": "neo4jSearch"
}
}
]
}
ℹ️ The
credentialsMappingsfield cannot be edited via the Web interface and can only be edited by editing the configuration file with a file editor.
The rules to map a user-group in Linkurious Enterprise to a user in Neo4j are the following:
Input credential mapping:
"user": "my-default-user",
"password": "mySecretPassword1",
"credentialsMappings": [
{"groupIds": [1], "neo4jUser": "user1", "neo4jPassword": "password1"},
{"groupIds": [1, 2], "neo4jUser": "user2", "neo4jPassword": "password2"},
{"groupIds": [1, 2, 3], "neo4jUser": "user3", "neo4jPassword": "password3"},
]
Resulting mapping:
[1] => User "user1", because it is the first mapping that contains all the groups.[1, 2] => User "user2", because it is the first mapping that contains all the groups.[1, 2, 3] => User "user3", because it is the first mapping that contains all the groups.[1, 2, 3, 4] => User "user3", because it is the mapping with most groups in common.[2] => User "user3", because it is the first mapping with most groups in common. [4] => User "my-default-user" because no mapping has any groups in common.Neo4j introduced a new "block" storage format. This new storage format was introduced in Neo4j 5.14 and is the default since Neo4j 5.17. Migrating the storage format of a Neo4j database will change the nodes and edges IDs, and thus break references in Linkurious Enterprise's user-data store. As a consequence, migrating to block format without following the proper steps will cause all existing visualizations and alert cases to become either empty or filled with the wrong nodes and edges.
ℹ️ If you don't have any saved visualization or case, you can safely skip this section as your system does not store any reference yet.
ℹ️ If you already have alternative identifiers properly configured, you can safely skip this section as your system is already not relying on the internal IDs of Neo4j.
⚠️ If you decide to activate alternative identifiers at this stage of the migration, you are not covered by the mentioned risks and you will still need to take actions. Please get in touch in case of doubts.
To migrate to block format without breaking references in Linkurious Enterprise, the neo4jBlockFormatMigration script is available to migrate the content of Linkurious Enterprise's user-data store.
The neo4jBlockFormatMigration script has two commands:
prepare, that must be executed before migrating Neo4j to block storage format⚠️ This step will store some extra data on your neo4j database (even on the order of GBs for databases with billions of elements), please make sure to have enough free space on your server.
complete, that must be executed after migrating Neo4j to block storage format.ℹ️ This step will clear the extra data created at the previous step.
You should be able to see the documentation of the neo4jBlockFormatMigration script by running it without any argument:
On Docker
docker run --rm --mount type=bind,src=/path/to/my/data/folder,dst=/data linkurious:4.3.10 node /usr/src/linkurious/system/scripts/neo4jBlockFormatMigration` (don't forget to replace `/path/to/my/data/folder` to your data folder, or you can use any other volume configuration that mounts the data folder)
On Linux
./neo4jBlockFormatMigration.shOn macOS
./neo4jBlockFormatMigration.sh.commandOn Windows
./neo4jBlockFormatMigration.batYou should see: "Usage: neo4jBlockFormatMigration [command] [options] (...)" and more documentation about the script.
⚠️ Since for big databases the execution time of the scripts could be very long, be sure to run the different commands in a proper way to prevent the operating system to automatically kill the scripts.
Please follow these steps to perform a migration to block format (the database is called my-database here):
Make sure the Neo4j database is not already using a "block" storage format by running SHOW DATABASES YIELD name, store in the Neo4j console.
record-aligned, it means that the database is not yet migrated to block formatblock-block, it means that the database was already migrated to block formatStop Linkurious Enterprise
Run the neo4jBlockFormatMigration script with the prepare command (add prepare as the end of the neo4jBlockFormatMigration script documented above).
Migrate Neo4j to block storage:
STOP DATABASE my-database WAIT;neo4j-admin database migrate --to-format="block" my-databaseSTART DATABASE my-database WAIT;Run the neo4jBlockFormatMigration script with the complete command (add complete as the end of the neo4jBlockFormatMigration script documented above).
Start Linkurious Enterprise
After the first connection you may see a warning message that the database has changed. Since this is expected as part of the migration step in neo4j, you can safely dismiss the warning to complete the process.
Please check for supported Amazon Neptune versions in our compatibility matrix.
By default, Amazon Neptune is not accessible from outside your AWS Virtual Private Cloud (VPC). To allow Linkurious Enterprise to access Neptune, you have several options:
Linkurious Enterprise requires the Neptune Graph Summary API to be enabled in order to retrieve metadata from an Amazon Neptune instance. This metadata is essential for constructing the graph schema during the schema sampling process (see schema sampling).
To ensure reliable schema sampling with Amazon Neptune, all of the following conditions must be met:
4.1.8 or later is installed.T3 and T4g instances: you must use a larger instance type to enable the API)IMPORTANT
If these prerequisites are not met, Linkurious Enterprise will attempt a best-effort schema sampling approach. However, this may fail for large datasets, potentially leading to incomplete schema detection.
To edit a Neptune data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"name": "neptune",
"graphdb": {
"vendor": "neptune",
"url": "https://neptune-instance-name.c2to76ungguf.us-east-1.neptune.amazonaws.com:8182",
"accessKeyId": "AKIATWJHFKUGHEKH665AN",
"secretAccessKey": "O5m1mTcReZ46zesZ/Zty27rfa58/5/SEG"
},
"index": {
"vendor": "neptuneSearch",
"url": "https://opensearch-instance-name.us-east-1.es.amazonaws.com"
}
}
]
}
Supported graphdb options with Neptune:
url (required): URL of the Neptune server's Gremlin endpoint.accessKeyId (required unless assumedRoleArn is used): Access Key ID for the AIM role used to access Neptune.secretAccessKey (required unless assumedRoleArn is used): Secret Access Key for the AIM role used to access Neptune.assumedRoleArn (optional): To authenticate via AssumeRole, this must be the Amazon Resource Name (ARN) of the role to assume.assumedRoleTokenRefreshSeconds (default: 1800): When assumedRoleArn is used, number of seconds before the temporary access token is refreshed.latitudeProperty (optional): Name of the node property to use for latitude (used in geo mode).longitudeProperty (optional): Name of the node property to use for longitude (used in geo mode).ignoredEdgeTypePrefixes (optional): List of edge type prefixes to be excluded in the schema sampling.See options to enable full-text search with Amazon Neptune.
Please check for supported Memgraph versions in our compatibility matrix.
To edit the Memgraph data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "memgraph",
"url": "bolt+s://18.150.10.214",
"user": "my-memgraph-user",
"password": "my-memgraph-password"
},
"index": {
"vendor": "elasticsearch",
"host": "127.0.0.1",
"port": 9201
}
}
]
}
Supported graphdb options with Memgraph:
url (required): URL of the Memgraph server (Bolt: bolt:// or bolt+s://)databaseName (optional): Name of the database to be connecteduser (optional): Memgraph user (if credentials are enabled)password (optional): Memgraph password (if credentials are enabled)latitudeProperty (optional): Name of the node property to use for latitude (used in geo mode)longitudeProperty (optional): Name of the node property to use for longitude (used in geo mode)ignoredEdgeTypePrefixes (optional): List of edge type prefixes to be excluded in the schema samplinguseSchemaCacheAndAutoIndexes (optional): When enabled, Linkurious Enterprise will use the schema metadata cache,
node categories and edge types indexes to speed up the schema sampling.
This option is recommended for large graph databases in production and requires Memgraph 2.16+.ℹ️ IMPORTANT: When the
useSchemaCacheAndAutoIndexes, Memgraph 2.16+ is required and the following options must be set.For Memgraph 2.16 to 2.20:
--storage-enable-schema-metadata=true--storage-mode=IN_MEMORY_TRANSACTIONAL--storage-automatic-label-index-creation-enabled=true--storage-automatic-edge-type-index-creation-enabled=trueFor Memgraph 2.21+:
--schema-info-enabled=true--storage-mode=IN_MEMORY_TRANSACTIONAL--storage-automatic-label-index-creation-enabled=true--storage-automatic-edge-type-index-creation-enabled=true
We strongly recommend you to also enable the following Memgraph options:
--storage-enable-edges-metadata=true: Necessary to make getting edges by ID scalable.Linkurious Enterprise allows using Memgraph instances running on Memgraph cloud.
See options to enable full-text search with Memgraph.
![]()
If you have data in Google Cloud Spanner, you can explore this data as a graph using Linkurious Enterprise.
To achieve this, you must first define a property graph schema in Spanner, which defines a projection of the data in your tables as a graph.
This section defines the technical requirements to use Spanner with Linkurious Enterprise.
Make sure that your graph schema defines at least one KEY property for each node and edge in
the graph schema. Make sure all KEY columns are part of the graph node/edge properties. The
Supported key types are: INT32, INT64 and STRING.
Nodes with multiple labels are not supported, please assign a single label for each table. Each label must unambiguously reference a single table, make sure a given label does not correspond to two different SQL tables.
For edges, we recommend using:
Person (1) -OWNS_BIKE-> (*) Bike, a good key for the OWNS_BIKE edge is the key property of the Bike node-table);Account (*) <-TRANSACTION-> (*) Account a good key for the TRANSACTION edge is the key of the TRANSACTION edge-table);Person (*) <-KNOWS-> (*) Person, a good key for the KNOWS edge is (sourcePersonId, targetPersonId))To use this feature, you must have at least one node property in your graph that is tokenized, and at least one index that contains that tokenized property.
For more details, see how to configure Google Spanner Search.
To edit the Spanner data-source configuration, you can either use the Web user-interface or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"databaseName": "spanner-dev-db",
"graphName": "spanner_dev_graph",
"vendor": "spanner",
"url": "https://cloud.google.com",
"projectId": "dev-test-spanner",
"instanceId": "spanner-test-instance",
"keyFileContent": "<secret>"
},
"index": {
"vendor": "spannerSearch"
}
}
]
}
Supported graphdb options with Spanner:
vendor (required): must be spanner;projectId (required): Your Google Cloud project ID;instanceId (required): Your Google Spanner instance ID;databaseName (required): Your Google Spanner database name;graphName (required): Your property graph's name;keyFileContent: If you are not running Linkurious Enterprise on GCP, you can create a service account key file
and copy the full content of the file in this field;keyFile (used only if keyFileContent is not set): If you are running Linkurious Enterprise on GCP, you can
set up application credentials and set this field to
$ENV:GOOGLE_APPLICATION_CREDENTIALS (this will read the value of this environment variable);url (required): must be https://cloud.google.com;queryHint (optional): A query hint that will be added to all queries (e.g. OPTIMIZER_VERSION=8).Supported index options with Spanner:
vendor (required): must be spannerSearch;retrievalLimit (optional, default: 10000): Limit how many results to fetch and rank in each
table when executing a search. See Google Spanner documentation about retrieval depth.There are 3 ways to authenticate to Google Spanner.
Using keyFileContent:
keyFileContentkeyFile unset.Using a keyFile:
keyFile field to $ENV:GOOGLE_APPLICATION_CREDENTIALS (this will read the value of this environment variable)keyFileContent unset.Using a Service Account:
keyFile and keyFileContent unsetscope includes cloud-platform)roles/spanner.databaseReader)See Google Spanner's documentation about importing data.
![]()
If you have data in Google BigQuery, you can explore this data as a graph using Linkurious Enterprise.
To achieve this, you must first define a property graph schema in BigQuery, which defines a projection of the data in your tables as a graph.
This section defines the technical requirements to use BigQuery with Linkurious Enterprise.
Make sure that your graph schema defines at least one KEY property for each node and edge in
the graph schema. Make sure all KEY columns are part of the graph node/edge properties. The
Supported key types are INT64 and STRING.
Nodes with multiple labels are not supported, please assign a single label for each table. Each label must unambiguously reference a single table, make sure a given label does not correspond to two different SQL tables.
For edges, we recommend using:
Person (1) -OWNS_BIKE-> (*) Bike, a good key for the OWNS_BIKE edge is the key property of the Bike node-table).Account (*) <-TRANSACTION-> (*) Account a good key for the TRANSACTION edge is the key of the TRANSACTION edge-table).Person (*) <-KNOWS-> (*) Person, a good key for the KNOWS edge is (sourcePersonId, targetPersonId)).To use this feature, you must have at least one node property in your graph that is indexed.
For more details, see how to configure Google BigQuery Search.
To edit the BigQuery data-source configuration, you can either use the Web user-interface or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "bigQuery",
"url": "https://cloud.google.com/bigquery",
"projectId": "dev-big-query",
"datasetId": "big_query_dev_dataset",
"graphName": "big_query_dev_graph",
"keyFileContent": "<secret>"
},
"index": {
"vendor": "bigQuerySearch"
}
}
]
}
Supported graphdb options with BigQuery:
vendor (required): must be bigQuery;url (required): must be https://cloud.google.com/bigquery.projectId (required): Your Google Cloud project ID.datasetId (required): Your Google BigQuery dataset ID.graphName (required): Your property graph's name.keyFileContent: If you are not running Linkurious Enterprise on GCP, you can create a service account key file
and copy the full content of the file in this field;keyFile (used only if keyFileContent is not set): If you are running Linkurious Enterprise on GCP, you can
set up application credentials and set this field to
$ENV:GOOGLE_APPLICATION_CREDENTIALS (this will read the value of this environment variable);Supported index options with BigQuery:
vendor (required): must be bigQuerySearch;retrievalLimit (optional, default: 10000): Limit how many results to fetch and rank in each
table when executing a search.For details, see BigQuery's documentation about full-text search.
There are 3 ways to authenticate to Google Spanner.
Using keyFileContent:
keyFileContentkeyFile unset.Using a keyFile:
keyFile field to $ENV:GOOGLE_APPLICATION_CREDENTIALS (this will read the value of this environment variable)keyFileContent unset.Using a Service Account:
keyFile and keyFileContent unsetscope includes cloud-platform)See Google BigQuery's documentation about importing data.
Cosmos DB is supported by Linkurious Enterprise.
To edit the Cosmos DB data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "cosmosDb",
"url": "https://your-service.gremlin.cosmosdb.azure.com:443/",
".NET SDK URI": "https://your-service.documents.azure.com:443/",
"database": "your-graph-database",
"collection": "your-collection",
"primaryKey": "your-account-primary-key",
"partitionKey": "your-collection-partition-key"
},
"index": {
"vendor": "azureSearch",
"url": "https://your-search-service.search.windows.net",
"apiKey": "your-search-service-admin-api-key",
"nodeIndexName": "your-node-index",
"edgeIndexName": "your-edge-index"
}
}
]
}
Supported graphdb options for Cosmos DB:
url (required): This is the full Gremlin Endpoint of your Cosmos DB. Should not to be confused with the .NET SDK URI.NET SDK URI (required): The .NET SDK URI of your Cosmos DBdatabase (required): Cosmos DB databasecollection (required): Cosmos DB collectionprimaryKey (required): Cosmos DB account primary keypartitionKey (required): The partition key of your Cosmos DB collectionlatitudeProperty (optional): Name of the node property to use for latitude (used in geo mode)longitudeProperty (optional): Name of the node property to use for longitude (used in geo mode)allowSelfSigned (optional, default false): Whether to allow self-signed certificatesIn order to have full-text search, you can choose among the following options:
Note: alternative IDs are only supported with Neo4j
When you save a visualization in Linkurious Enterprise, only the node and edge identifier are persisted in the user-data store, along with position and style information. When a visualization is loaded, the node and edge identifiers are used to reload the actual node and edge data from the graph database.
If you need to re-generate your graph database from scratch, the graph database will probably generate new identifiers for all nodes and edges, breaking all references to nodes and edges in existing visualizations.
You can configure Linkurious Enterprise to use a node or edge property as stable identifiers. Once set-up, Linkurious Enterprise will use the given property as identifier instead of using the identifiers generated by the database.
Thanks to this strategy, visualizations will be robust to graph re-generation.
Notice that the properties used as identifier should be indexed by the database to allow for a fast lookup by value.
To use alternative node and edge identifiers,
edit your data-source database configuration in the configuration file (linkurious/data/config/production.json):
Example of alternative identifier configuration with Neo4j:
{
"dataSources": [
{
"graphdb": {
"vendor": "neo4j",
"url": "http://127.0.0.1:7474/",
"alternativeNodeId": "STABLE_NODE_PROPERTY_NAME",
"alternativeEdgeId": "STABLE_EDGE_PROPERTY_NAME"
}
// [...]
}
]
}
If you plan on using a compatible Neo4J version and alternative IDs, we recommend configuring alternative IDs indices.
To achieve better performance with alternative IDs is recommended to configure indices for alternative node and edge IDs.
Please note that the node or edge property used as an alternative ID must have string values. Other types (typically integers) are not supported. This is needed because the alternative IDs indices are FULLTEXT ones and can thus only index string values.
Refer to the documentation specific to Neo4j on how to configure these indices.
Enabling or disabling alternative IDs will change the nodes and edges IDs, and thus break references in Linkurious Enterprise's user-data store. As a consequence, enabling or disabling alternative IDs without following the proper steps will cause all existing visualizations and alert cases to become either empty or filled with the wrong nodes and edges.
ℹ️ If you don't have any saved visualization or case, you can safely skip this section as your system does not store any reference yet.
To enable or disable alternative IDs without breaking references in Linkurious Enterprise, the alternativeIdsMigration script is available to migrate the content of Linkurious Enterprise's user-data store.
The alternativeIdsMigration script has two commands:
enable, to enable alternative IDs and migrate the content of Linkurious Enterprise's user-data store to use the alternative IDs instead of the internal Neo4j IDs.
This command expect the name of the alternative ID node and edge properties in its command line arguments.
If alternative IDs are configured before running the enable command, it's going to print a warning and abort.disable, to disable alternative IDs and migrate the content of Linkurious Enterprise's user-data store to use the internal Neo4j IDs.
The disable command can always be run, no matter if alternative IDs are configured or not. This can be handy to clean-up the Linkurious user-data-store if the migration goes wrong.You should be able to see the documentation of the alternativeIdsMigration script by running it without any argument:
On Docker
docker run --rm --mount type=bind,src=/path/to/my/data/folder,dst=/data linkurious:4.3.10 node /usr/src/linkurious/system/scripts/alternativeIdsMigration` (don't forget to replace `/path/to/my/data/folder` to your data folder, or you can use any other volume configuration that mounts the data folder)
On Linux
./alternativeIdsMigration.shOn macOS
./alternativeIdsMigration.sh.commandOn Windows
./alternativeIdsMigration.batYou should see: "Usage: alternativeIdsMigration [command] [options] (...)" and more documentation about the script.
You can get more help with a command by running ./alternativeIdsMigration.sh [command] --help (e.g. ./alternativeIdsMigration.sh enable --help)
⚠️ For big databases, the execution time of the scripts could be very long.
Please follow these steps to enable alternative IDs:
Stop Linkurious Enterprise
Run the alternativeIdsMigration script with the enable command and the right arguments:
./alternativeIdsMigration.sh enable --help to understand which arguments to set./alternativeIdsMigration.sh enable --alternative-node-id myAlternativeNodeId --alternative-edge-id myAlternativeEdgeIdStart Linkurious Enterprise
Please follow these steps to disable alternative IDs:
Stop Linkurious Enterprise
Run the alternativeIdsMigration script with the disable command (add disable as the end of the alternativeIdsMigration script documented above).
Start Linkurious Enterprise
You have the possibility to merge data-sources from the data-source management page with the following steps:
From the dashboard, go to the Admin > Data-sources management menu
The data-source to be merged should be the old data-source now marked as offline because it has been replaced with the freshly generated data-source.

On the resulting modal, select the new data-source then click on the merge button.

The user can choose to perform a normal merge, or an overwrite merge.
As a result, the following objects from the old data-source will be merged in the new data-source:
The Data-Source won't be deleted in case the user decides to do an overwrite merge at a later stage.
To perform an overwrite merge, simply select the "overwrite" check box in the merge modal.
As a result, the objects from the old data-source mentioned above will be merged in the new data-source. Additionally, the following objects will be replaced in the new data-source with the ones from the old data-source:
This action will irreversibly remove any data associated with the old data-source, and the data-source will be deleted.
The following advanced settings apply to all data-sources.
To change them, see how to configure Linkurious Enterprise.
dataSourceConnectionTimeout (default: 30): The maximum number of seconds before the connection attempt to a data-source times out.dataSourceAutoReconnectInterval (default: 300): Number of seconds after which Linkurious will try to reconnect automatically to all offline data-sources.
This value is internally converted into minutes; if it is not a multiple of 60, it will be rounded to the nearest number of minutes.
Explicitly setting this parameter to 0 will disable the offline data-sources auto-reconnection feature.pollInterval (default: 10): Check if the data-sources and search engine are connected at each interval (in seconds).indexingChunkSize (default: 5000): The number of nodes and edges retrieved at each batch when indexing the graph database.searchAddAllThreshold (default: 500): The maximum number of search results that the user can add to a Visualization at once.minSearchQueryLength (default: 3): The number of characters needed to trigger a search query. Set 1 to provide live results from the first character typed by the user.searchPrefixExpansion (default: true): Whether Linkurious should return nodes and edges that contain the search query as a prefix, e.g.: Searching Link will return node Linkurious.searchRetryMultiplier (default: 5): During search, if some search results are missing from the graph, will re-run the search query with a page size searchRetryMultiplier times larger than the originally requested size (larger values can make search slower).defaultFuzziness (default: 0.1): Default value to search fuzziness between 0 and 1. A value of 0 means exact matching of the search query.supernodeThreshold (default: 10000): Number of adjacent edges after which a node is considered a supernode.edgesBetweenSupernodes (default: false): Whether Linkurious should retrieve edges between 2 supernodes. Note: Linkurious always return edges between a supernode and a regular node.rawQueryTimeout (default: 60000): Milliseconds after which a query to the database will time out.rawQueryLimit (default: 500): The maximum number of results returned by Linkurious Enterprise when executing a query or query template.expandThreshold (default: 50): When the user expands a node with too many neighbors, Linkurious Enterprise will ask to refine the query so that fewer neighbors are returned.showBuiltinQueries (default: true): Whether built-in queries like Shortest Path should appear in the list of graph queries.slowQueryThreshold (default: 500): Milliseconds after which a query is logged in the log file as a slow query.defaultLayout (default: { "algorithm": "force", "mode": "best" }): The default layout to be applied to visualizations.defaultLayout.algorithm (default: force): Can be force or hierarchical. defaultLayout.mode (default: best): (best|fast) for force algorithm and (LR | RL | TB | BT) for hierarchical algorithm. See the layout section in the user manual for more information.sampledItemsPerType (default: 1000): The number of nodes/edges per category/type to read from the graph for the schema samplingsampledVisualizationItems (default: 1000): Number of nodes/edges to read from existing visualizations for the schema samplingThe worker pool is an internal thread pool used to offload computational tasks from the main thread of the Linkurious Enterprise process. It is used to run alerts, custom queries and compute server-side visualization layouts, so that these do not affect the application responsiveness.
workerPool (default: { "enabled": true, "size": 1, "memoryLimitMb": 1024, "exclusiveWorker": false}):workerPool.enabled (default: true): Whether to enable this feature. When disabled,
any task that would have been executed by the worker pool is executed directly by the main thread.workerPool.size (default: 1): The fixed number of threads to spawn in the worker pool.
We recommend this setting to be at least 2 if alerts are enabled.
The maximum value for this setting should be the number of available CPU cores on the server running Linkurious Enterprise, minus one.workerPool.memoryLimitMb (default: 512): The maximum size of the main heap in megabytes, for each thread in the worker pool.workerPool.exclusiveWorker (default: false): When set to true, each worker can only execute one task at a time.
When all workers are busy, additional tasks will wait in a queue until a worker becomes available.
This ensures task isolation, preventing timeouts in one task from affecting other tasks.
However, this may increase latency. Consider increasing workerPool.size when enabling this flag to maintain throughput.ℹ️ If the worker pool is disabled, all the tasks will be executed by the main thread of the Linkurious Enterprise process.
⚠️ When using
exclusiveWorker: true, carefully consider yourworkerPool.sizeconfiguration. With exclusive workers, fewer concurrent tasks can be executed, potentially causing tasks to queue. If the worker pool size is insufficient compared to the average number of concurrent operations, the queue can grow indefinitely, leading to increased memory usage and task delays.
extraCertificateAuthorities: The relative or absolute path to a single PEM file. When set, the well known "root" CAs
(like LetsEncrypt) will be extended with the extra certificates in the
file. The file should consist of one trusted certificate or multiple ones concatenated one after the other in the PEM format. If in your chain of certificates you have some Intermediate certificates, adding the Root CA will be enough to trust the whole chain.
If the path is relative, the file should be located within the linkurious/data folder.If Linkurious Enterprise is installed as a service, the service needs to be uninstalled and re-installed for the change to be taken into account.
If Linkurious Enterprise is installed using Docker, then
extraCertificateAuthoritieswill not work and theNODE_EXTRA_CA_CERTSenvironment variable should be used instead. The variable must contain the absolute path to a PEM file (see details on the Node.js documentation).
obfuscation (default: false): Set to true if you want all the passwords in the configuration to be obfuscated at the next restart of Linkurious Enterprise.Resource management is where resources, such as (Spaces), are managed in Linkurious Enterprise.
You can go to this page by clicking Admin, Resource management.
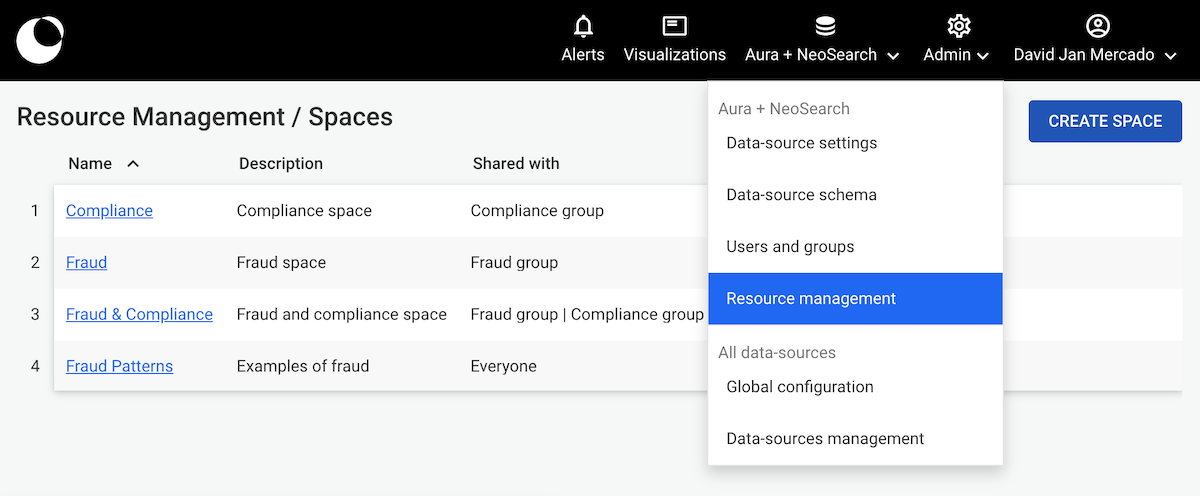
Spaces are containers of visualizations shared with user groups. By default, the admin and source manager has this right enabled. To provide a user group the right to manage a space, you can enable it in the custom group creation, as shown below.
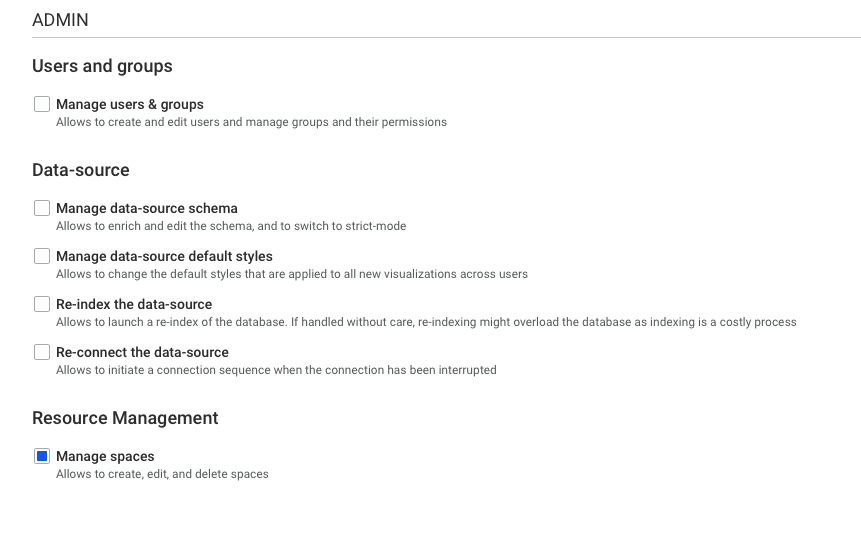
IMPORTANT
User groups that have the Manage access right can create and delete a space. This does not, however, automatically grant them access to all spaces. The spaces have to be shared explicitly to a user group.
You can create a space by clicking the Create Space button on the upper right part of the page. The Name and Share with input fields are required. You can share it with as many built-in groups and custom groups as necessary.
The space appears in the table once it’s created. Clicking on the name displays a panel that appears on the right (see image below) with the space’s information as well as the buttons to edit and delete.
To delete a space, you click the name then click the delete button on the right drawer. This operation is irreversible, hence, the popin asks for further confirmation by asking you to type “delete”.
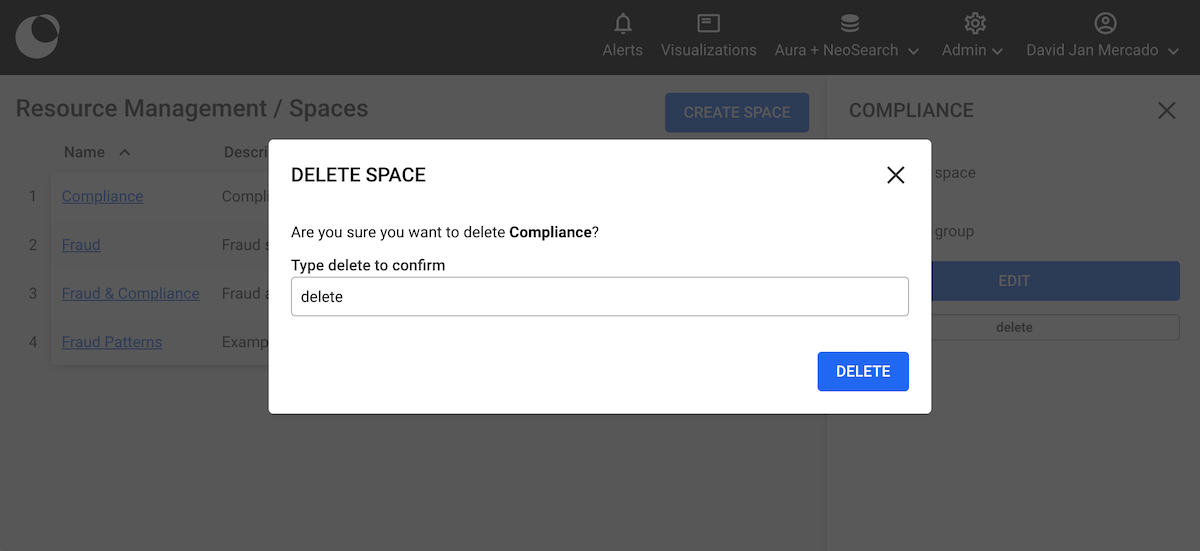
Warning To delete a space having visualizations, you have to delete all visualizations within it before you can delete it. If you attempt to delete such a space, the popin informs you that you cannot do it.
Tags tab of the Resource Management page allows you to view and manage Query Tags.
You can find the extensive list of distinct query tags in Resources Management > Tags.
Clicking on a tag's name displays a panel that appears on the right. Tag's panel displays tags creation date and lists all the queries associated with the selected tag.
You can delete a tag by clicking on the "Delete" button at the bottom of the tag's right panel. Confirmation will be asked to prevent accidental clicks.
Warning To delete a tag you either need to be the tag's creator OR to have "Can manage, create read/write queries and run queries" access rights.
Linkurious Enterprise allows you to search your graph using natural full-text search.
In order to offer the search feature out-of-the-box, Linkurious Enterprise ships with an embedded Elasticsearch server. This option allows for zero-configuration deployment in many cases.
By default, Linkurious Enterprise uses Elasticsearch for search. This options requires Linkurious Enterprise to index your graph database, which technically means that Linkurious Enterprise will feed the whole content of the graph database to Elasticsearch to make it searchable. The time required to index the graph database increases with the size of the graph and this solution has limits in its scalability.
Indexing typically happens at speeds between 2000 and 20000 nodes or edges per second, depending on the number of properties for nodes and edges, and hardware performances.
By default, Linkurious Enterprise ships with an embedded Elasticsearch server (version 9.2.0).
This server only listens for local connections on a non-default port (it binds to 127.0.0.1:9201),
for security reasons and to avoid collisions with existing servers.
Note: Embedded Elasticsearch is not available on macOS systems
It is possible to use your own Elasticsearch cluster for performance reasons. Linkurious Enterprise supports Elasticsearch v1.x and v2.x. See details about Elasticsearch configuration options.
Using Elasticsearch is convenient but may not fit cases where the graph database is large (more than a couple million nodes and edges) and is regularly modified from outside Linkurious Enterprise, which requires to re-index the whole database.
In order to offer a scalable search feature on big graphs, Linkurious Enterprise offers alternative search solutions. See details about the different options.
You can configure your search engines via the Web user interface
or directly on the linkurious/data/config/production.json file.
Using an administrator account, access the Admin > Data menu to edit the current data-source configuration:
Edit the search engine configuration to connect to your graph database:
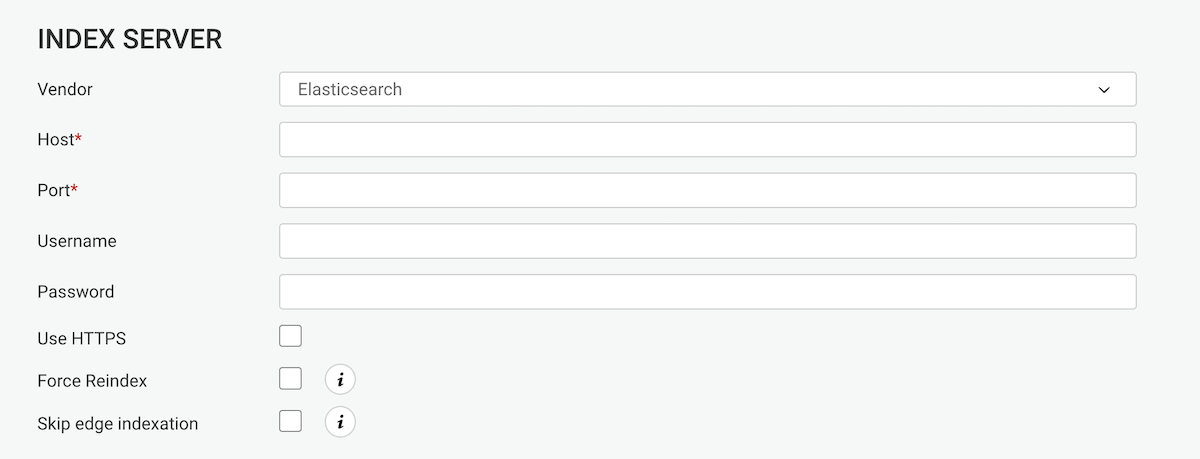
Submit the changes by hitting the Save configuration button.

Edit the configuration file located at linkurious/data/config/production.json.
See details for each supported search connector.
Choosing which full-text search engine to use for a specific graph vendor is not always obvious.
For each graph vendor, this page will help you list your options and compare their pros and cons.
Note: Embedded Elasticsearch is not available on macOS systems
| Feature | Definition |
|---|---|
| Onboarding | Does this search option require additional configuration, or can it be used out-of-the-box with the associated graph database? |
| Fast indexing | How fast is indexing? Note that this is a relative metric; while some search options may be faster than others, speed will depend on the complexity of your data model and your hardware limitations. |
| Automatic index sync | Are changes made to the graph DB propagated to the index automatically? |
| Search scalability | How well search queries perform for large graph databases? The actual upper limit on the performance of a given option will vary from vendor to vendor. |
| Advanced search | If advanced search features are available, such as numerical and date range search operators. |
| Search option | Onboarding | Fast indexing | Automatic index sync | Search scalability | Advanced search |
|---|---|---|---|---|---|
| Embedded Elasticsearch | Plug-and-play | No | No | Will not scale beyond ~100M nodes | Yes (requires configuration) |
| External Elasticsearch (v7+) | Requires Elasticsearch installation and configuration | No | No | Yes (by adding hardware to Elasticsearch cluster) | Yes (requires configuration) |
| Neo4j Search (v4.0.2+) | Plug-and-play | Yes | Yes | Limited | No |
| Elasticsearch Incremental Indexing | Requires External Elasticsearch (versions compatible with Linkurious Enterprise) and Neo4j v4.0.2 and above | Yes (except the first full indexing) | Yes (requires configuration) | Yes (by adding hardware to Elasticsearch cluster) | Yes (requires configuration) |
| Search option | Onboarding | Fast indexing | Automatic index sync | Search scalability | Advanced search |
|---|---|---|---|---|---|
| Embedded Elasticsearch | Plug-and-play | No | No | Will not scale beyond ~100M nodes | Yes (requires configuration) |
| External Elasticsearch (v7+) | Requires Elasticsearch installation and configuration | No | No | Yes (by adding hardware to Elasticsearch cluster) | Yes (requires configuration) |
| OpenSearch for Amazon Neptune | Requires configuration in Amazon Neptune & OpenSearch | Yes | Yes | Yes (by adding resources in OpenSearch) | No |
| Search option | Onboarding | Fast indexing | Automatic index sync | Search scalability | Advanced search |
|---|---|---|---|---|---|
| Embedded Elasticsearch | Plug-and-play | No | No | Will not scale beyond ~100M nodes | Yes (requires configuration) |
| External Elasticsearch (v7+) | Requires Elasticsearch installation and configuration | No | No | Yes (by adding hardware to Elasticsearch cluster) | Yes (requires configuration) |
| Search option | Onboarding | Fast indexing | Automatic index sync | Search scalability | Advanced search |
|---|---|---|---|---|---|
| Google Spanner Search | Requires manually creating the search indexes in the Spanner SQL database | Yes | Yes | Yes | No |
| Search option | Onboarding | Fast indexing | Automatic index sync | Search scalability | Advanced search |
|---|---|---|---|---|---|
| AzureSearch | Requires AzureSearch setup (easy) | Yes | Yes | Yes | No |
| Embedded Elasticsearch | Plug-and-play | No | No | Will not scale beyond ~1M nodes (missing backpressure) | Yes (requires configuration) |
| External Elasticsearch (v7+) | Requires Elasticsearch installation and configuration | No | No | Will not scale beyond ~1M nodes (missing backpressure) | Yes (requires configuration) |
The neo4jSearch connector is a solution for full-text search with Neo4j.
neo4jSearch is supported since version 3.5.1 of Neo4j.
Linkurious can use the builtin search indices managed by Neo4j itself.
You can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json to set the index.vendor property to the value neo4jSearch.
To edit the Neo4j data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "neo4j",
"url": "neo4j://127.0.0.1:7687",
"user": "my-neo4j-user",
"password": "my-neo4j-password"
},
"index": {
"vendor": "neo4jSearch",
"indexEdges": true
}
}
]
}
Supported index options with Neo4jSearch:
indexEdges (boolean, default: false): Whether to create or use an edge indexanalyzer (string, default: "standard-no-stop-words"): Optional custom analyzer (see details on the Neo4j documentation)Note that, in Neo4jSearch, only fields stored in Neo4j as string will be searchable. Numerical and date properties won't be searchable if stored in Neo4j as numbers or native dates.
Please check for supported Elasticsearch versions in our compatibility matrix.
Linkurious Enterprise ships with an embedded Elasticsearch server (version 9.2.0).
ATTENTION: The internal Elasticsearch is not intended to be used for graph databases > 50,000,000 nodes. Though indexing and search performance are ultimately dependent on hardware limitations, it has been configured to prevent horizontal scaling and so is not an efficient choice for large DBs. It is meant instead as a quick indexing strategy for POCs or small deployments.
Embedded Elasticsearch is not available on macOS systems
To use the Linkurious Enterprise embedded Elasticsearch instance, set the following index configurations keys:
vendor must be elasticSearchhost must be "127.0.0.1"port must be 9201Example configuration:
{
"dataSources": [
{
"graph": {
"vendor": "neo4j",
"url": "http://127.0.0.1:7474"
},
"index": {
"vendor": "elasticSearch",
"host": "127.0.0.1",
"port": 9201
}
}
]
}
Search connector elasticSearch supports the following options:
host (required): Elasticsearch server hostport (required): Elasticsearch server port (standard is 9200)https: true to connect to Elasticsearch via HTTPSuser: Elasticsearch username (if you are using X-Pack Security, a.k.a ElasticShield)password: Elasticsearch passwordforceReindex: true to re-index the data-source each time Linkurious Enterprise startsskipEdgeIndexing: true to skip edges indexing (edges won't be searchable)analyzer (default: "standard"): The custom analyzer aimed at analyzing a specific language text. (see available language analysers)numberOfShards (default: 1): The number of shards each index has. This parameter must be set before the graph database is indexed for the first time.numberOfReplicas (default: 1): The number of replica each shard has. This parameter must be set before the graph database is indexed for the first time.mappingTotalFieldsLimit (default: 1000): The maximum number of fields per index. This
parameter must be set before the graph database is indexed for the first time. Linkurious Enterprise creates
a single index for nodes and another one for edges, so this limit must be greater than the total
number of searchable properties among all node categories / edge types. Increasing this limit can
lead to performance degradations and memory issues, consider making properties non-searchable
instead.Example configuration:
{
"dataSources": [
{
"graph": {
"vendor": "neo4j",
"url": "http://127.0.0.1:7474"
},
"index": {
"vendor": "elasticSearch",
"host": "192.168.1.122",
"port": 9200,
"skipEdgeIndexing": true
}
}
]
}
Please check here how to configure search on numerical and date properties.
The Neptune Search integration is the preferred option for providing full-text search with Amazon Neptune.
This integration uses Amazon OpenSearch in combination with Neptune-to-OpenSearch replication to provide an always-up-to-date search index in Linkurious Enterprise.
We recommend using the Neptune Search integration because the standard "Elasticsearch" integration has the following limitations with Amazon Neptune:
Versions 1.3+ and 2.x of OpenSearch have been tested to work for this integration
(see details about supported versions).
When configuring Neptune Search the following options are available:
vendor: must be neptuneSearch.url: the OpenSearch domain endpoint URLExample configuration:
{
"dataSources": [
{
"name": "neptune",
"graphdb": {
"vendor": "neptune",
"url": "https://neptune-instance-name.c2to76ungguf.us-east-1.neptune.amazonaws.com:8182",
"accessKeyId": "AKIATWJHFKUGHEKH665AN",
"secretAccessKey": "xxxxxxxxxxxxxxxxxxxxx"
},
"index": {
"vendor": "neptuneSearch",
"url": "https://opensearch-instance-name.us-east-1.es.amazonaws.com"
}
}
]
}
⚠️ Be aware that you should set up the Neptune-to-OpenSearch integration on an empty Neptune graph. If you set up the integration after you already added data to Neptune, existing data will not be automatically synchronized to OpenSearch.
If you already have data in your graph, check out how to export Neptune to OpenSearch
See the AWS documentation for how to set up the Neptune to OpenSearch integration
A simplified guide is provided here as a quick start guide:
neptune_streams to 1Google Spanner Search is the built-in integration providing full-text search for Google Spanner.
It leverages the full-text search capabilities provided by Google Spanner.
Search is only supported on nodes, and on properties that correspond to a STRING column.
In Google Spanner, for each SQL table that corresponds to a searchable node label:
Create a TOKENLIST column for each searchable column, using the TOKENIZE_FULLTEXT function.
Here is an example of how to create a tokenized property:
CREATE TABLE Album (
id STRING(MAX) NOT NULL,
title STRING(MAX),
title_tokens TOKENLIST AS (TOKENIZE_FULLTEXT(title)) HIDDEN
) PRIMARY KEY(id);
Create a single SEARCH INDEX for the table, containing all the TOKENLIST columns. Here is
an example of how to create a search index:
CREATE SEARCH INDEX AlbumIndex
ON Album(title_tokens);
And this it it. Linkurious Enterprise will automatically find the created search indexes, there is no need for additional configuration.
Google BigQuery Search is the built-in integration providing full-text search for Google BigQuery.
It leverages the full-text search capabilities provided by Google BigQuery.
Search is only supported on nodes, and on properties that correspond to a STRING column.
In Google BigQuery, for each SQL table that corresponds to a searchable node label,
create a single SEARCH INDEX for the table, containing all the searchable columns.
Here is an example of how to create a search index:
CREATE SEARCH INDEX album_index
ON dataset.album(title, summary, category);
Linkurious Enterprise will automatically find the created search indexes, there is no need for additional configuration.
Azure search is the recommended full-text search solution for Cosmos DB.
Linkurious Enterprise requires an index on nodes to enable full-text search. If you do not have a configured index yet, you can create one via the Azure portal.
The following conditions must be met on the index, for Linkurious Enterprise to be able to use it for search:
label field must be marked as filterable;graphdb.primaryKey must be marked as retrievable;retrievable.⚠️ Any data transformation (e.g. base64 encoding) during the indexing process is not supported as this will cause the retrieval of unexpected data and might break the search feature.
Additionally, you can create an index on edges if you want search them as well with Linkurious Enterprise.
To edit the AzureSearch data-source configuration,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"dataSources": [
{
"graphdb": {
"vendor": "cosmosDb",
"url": "https://your-service.gremlin.cosmosdb.azure.com:443/",
"database": "your-graph-database",
"collection": "your-collection",
"primaryKey": "your-account-primary-key"
},
"index": {
"vendor": "azureSearch",
"url": "https://your-search-service.search.windows.net",
"apiKey": "your-search-service-admin-api-key",
"nodeIndexName": "your-node-index-name",
"edgeIndexName": "your-edge-index-name"
}
}
]
}
Supported index options with Azure search:
url (required): URL of the search serviceapiKey (required): Primary Admin Key of the search servicenodeIndexName (required): Name of the node index of your graph databaseedgeIndexName (optional): Name of the edge index of your graph databasePlease refer to the Azure search online documentation for details on how to load data into Azure search.
Note that today, in Azure Search, it's not possible to search on numbers or dates. If you are interested in this feature, please get in touch.
Incremental indexing allows you to keep in sync your Elasticsearch index and your Neo4j graph database.
Linkurious Enterprise will index at a regular interval new and updated items from your database. This way, you avoid a complete reindex every time you update your data.
This is achieved by keeping track of a timestamp on every node and edge in the database, hereby allowing the indexer to only consider the nodes with newer timestamps and consequently reducing the indexing time.
You should consider this option if your database holds a significant number of items and needs to be updated frequently.
Here some important considerations when choosing incremental indexing:
Linkurious Enterprise relies on APOC triggers to ensure that every node and edge created or updated has a timestamp.
You need to make sure that you have installed APOC correctly and enabled APOC triggers. You can find all the information you need to install APOC from Neo4j documentation.
You can quickly verify that you have installed everything correctly by executing the following command from your Neo4j browser:
CALL apoc.trigger.list()
After you have installed and configured APOC, you can enable incremental indexing by ticking the checkbox in the data-source configuration page (or by witching this option to true while editing the configuration file)
Incremental indexing adds an internal timestamp property linkuriousTimestamp on all nodes and edges. Any information stored on that property will be overwritten.
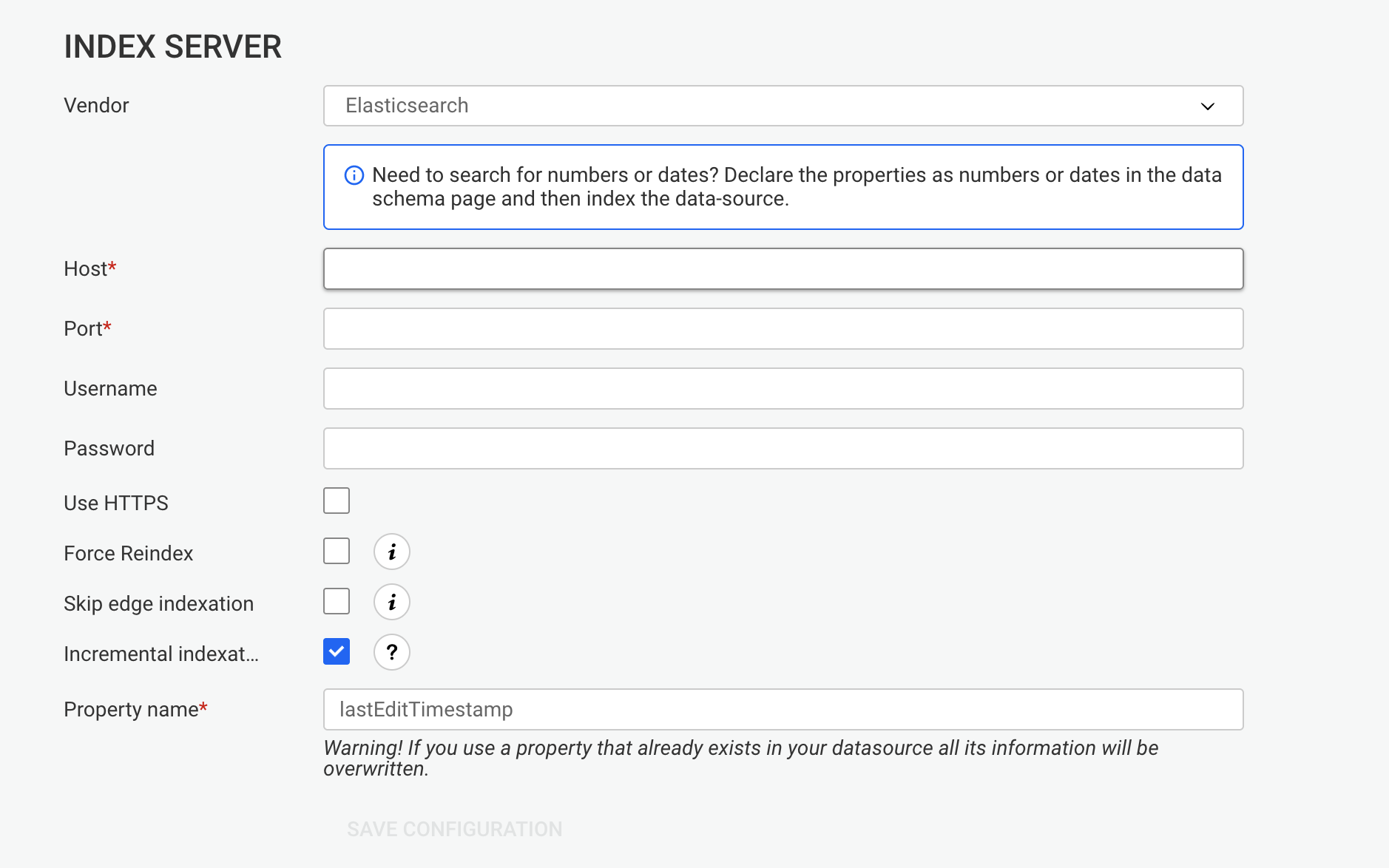
After you have enabled incremental indexing for the first time, Linkurious Enterprise requires to perform a complete re-indexing of the data-source to ensure that every item has been indexed. You simply need to click on the "Start indexing" button to complete the configuration.
Linkurious Enterprise will index your data-source incrementally from that point forward using the timestamps generated by the APOC triggers.
Once you have set up the incremental indexing, you can configure the frequency at which it will be triggered. You can customize this schedule by adding a cron expression to your Elasticsearch configuration.
You can make this change from the configuration file located at linkurious/data/config/production.json under datasources.index for each dataSource.
By default, we have set all incremental indexing to be launched every Sunday at 12PM, but you can change it to the frequency that most suits your needs. We advise that you schedule your increments to run after you have updated your database with new information. Here are some examples of cron expressions:
"incrementalIndexingCron": "*/5 * * * *""incrementalIndexingCron": "*/30 * * * *""incrementalIndexingCron": "0 * * * *""incrementalIndexingCron": "00 15 * * *""incrementalIndexingCron": "00 00 1,15 * *""incrementalIndexingCron": "00 00 1 * *"If you need to index your data-source at non-regular intervals:
Indexing by clicking the "Update index" button (or using the equivalent update index API endpoint) only performs an incremental update of the index. Note that you can also rebuild your index from scratch by clicking the "Re-create index" button. It might be useful if the index is inconsistent with the data-source schema (because the latter has changed).
You can disable automatic indexing with the following configuration: "incrementalIndexingCron": "none"
Elasticsearch is required to be able to perform numerical and date search.
To properly configure Elasticsearch for number and date search please follow these steps:
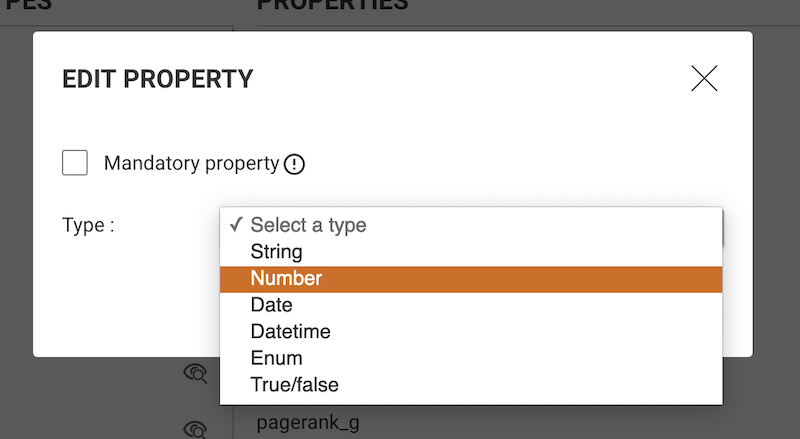
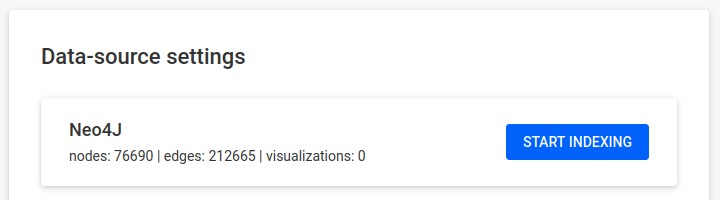
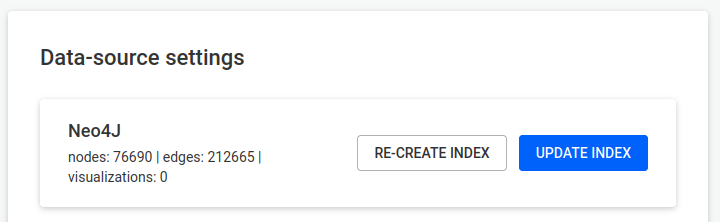
Note that if you change the types after the indexing, you will need to re-index for the changes to apply.
Linkurious Enterprise uses an SQL database to store user-data. The database contains:
This database doesn't store the business data stored in the graph database (except for the widget) which makes it a lightweight database that doesn't need a lot of resources.
By default, the user-data store is a SQLite file-based database. This makes Linkurious Enterprise easy to deploy.
For deployment at scale (more than a couple users), we recommend switching to one of the supported server-based databases:
To see the exact list of supported vendors and versions, please review our compatibility matrix.
Typical database server requirements for a moderate usage of the system with less than 100 users are:
You may need to allocate more resources in the following scenarios:
If you need to get help from professionals, contact us and we will be happy to answer your questions.
In order to get started with Linkurious Enterprise, there are few requirements for user-data store to function properly.
In order to create a new linkurious database and an associated user, refer to your team of database experts to comply with possible internal policies. Below is an example of typical queries you can use (replace SQL_USER_NAME, SQL_PASSWORD, and LKE_HOST by actual values).
CREATE USER 'SQL_USER_NAME'@'LKE_HOST' IDENTIFIED BY 'SQL_PASSWORD';
CREATE DATABASE linkurious;
GRANT ALL PRIVILEGES ON linkurious.* TO 'SQL_USER_NAME'@'LKE_HOST';
Please note that custom
sql_modein MariaDB and MySQL is not supported. Linkurious Enterprise only supports the default value forsql_mode.
CREATE DATABASE linkurious;
CREATE LOGIN SQL_USER_NAME WITH PASSWORD = 'SQL_PASSWORD', DEFAULT_DATABASE = linkurious;
USE linkurious;
CREATE USER SQL_USER_NAME FOR LOGIN SQL_USER_NAME;
EXEC sp_addrolemember 'db_owner', SQL_USER_NAME;
Linkurious Enterprise provides many options which can be used to configure user-data store connection. Below, you can find the configuration documentation and configuration examples for popular DBMS solutions.
In the Linkurious Enterprise configuration file, it is possible to configure the database connection under db key.
name (default: "linkurious"): Database name for Linkurious Enterprise to use.username (optional): Username for the database userpassword (optional): Password for the database usertransactionTimeout(optional, default:60000, only for "mssql"): The maximum time in milliseconds before a database transaction timeoutoptions: Child object that contains connection optionsdialect (default: "sqlite"): The database dialect to be used. Supports: "sqlite", "mysql", "mariadb", "mssql" host: Host address of the databaseport: Port address of the databasestorage (only for "sqlite"): Storage location for the database filepool (optional, not available for "sqlite"): Child object that contains connection pool optionsmin (optional): Minimum number of connections in the poolmax (optional): Maximum number of connections in the pooldialectOptions (optional): Child object that contains dialect specific additional options ssl (optional): Child object that contains dialect specific options for sslencrypt (default: false, boolean): Whether to enable encryption (useful for cloud instances with encryption enabled by default)multiSubnetFailover (default: false, boolean): Whether the driver attempts parallel connections to the failover IP addresses during a multi-subnet failover for higher availability.SQLite if the default user-data store of Linkurious Enterprise.
"db": {
"name": "linkurious",
"options": {
"dialect": "sqlite",
"storage": "server/database.sqlite"
}
}
"db": {
"name": "linkurious",
"username": "MYSQL_USER_NAME",
"password": "MYSQL_PASSWORD",
"options": {
"dialect": "mysql",
"host": "MYSQL_HOST",
"port": 3306
}
}
"db": {
"name": "linkurious",
"username": "MYSQL_USER_NAME",
"password": "MYSQL_PASSWORD",
"options": {
"dialect": "mysql",
"dialectOptions": {
"ssl": {
"require": true
}
}
"host": "MYSQL_HOST",
"port": 3306
}
}
"db": {
"name": "linkurious",
"username": "MSSQL_USER_NAME",
"password": "MSSQL_PASSWORD",
"options": {
"dialect": "mssql",
"host": "MSSQL_HOST",
"port": 1433
}
}
"db": {
"name": "linkurious",
"username": "MARIADB_USER_NAME",
"password": "MARIADB_PASSWORD",
"options": {
"dialect": "mariadb",
"host": "MARIADB_HOST",
"port": 3306
}
}
The default storage system for Linkurious Enterprise is SQLite.
Configuring Linkurious Enterprise to work with MySQL is a really easy procedure if you don't need to migrate data from SQLite.
Migrating data from SQLite to an external database is possible but it is a procedure we would recommend only if restarting from scratch with the new configuration is not a viable option.
Our public resources contain a specific tool needed to perform the migration from SQLite to one of the supported databases, as well as the detailed list of steps to use and eventually configure the tool.
If you need help with the procedure please contact us.
If you are using the SQLite database (by default), you only need to follow the standard Linkurious Enterprise backup procedure.
If you are using another database to store the Linkurious Enterprise user-data, please refer to one of the following guides:
The web server of Linkurious Enterprise delivers the application to end users through HTTP/S.
It is configured in the server configuration key within the configuration
file (linkurious/data/config/production.json):
Within the server key:
listenPort (default: 3000): The port of the web serverSome firewalls block network traffic ports other than 80 (HTTP).
Since only root users can listen on ports lower than 1024,
you may want reroute traffic from 80 to 3000 as follows:
sudo iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 3000
If you use SSL, you can add a second rule to redirect 3443 to 443:
sudo iptables -t nat -A PREROUTING -p tcp --dport 443 -j REDIRECT --to-port 3443
Within the server key:
basePath (default: /): The base path where Linkurious Enterprise will be foundIn some cases, you may want to host Linkurious Enterprise on a path other than root for a particular domain.
For example, if you want Linkurious Enterprise to be reachable at http(s)://HOST:PORT/linkurious you should
set basePath equal to linkurious.
This setting can be either a single path segment or multiple ones, for instance /abc/def/ghi.
Within the server key:
domain (default: "localhost"): The domain or sub-domain used to access the web server.
It is mandatory to edit it for publishing visualizations online.
It is also used to restrict the validity of cookies to a domain or sub-domain.publicPortHttp (default: listenPort): The public HTTP port of the web server.publicPortHttps (default: listenPortHttps): The public HTTPS port of the web server.In some cases, Linkurious Enterprise needs to generate links to itself (for example when generating a link to a widget). For that, the server needs to know its public domain and port to generate those links.
The public port can be different from the actual port if you use traffic rerouting
(using a firewall or a reverse-proxy). In the example above (traffic rerouting),
the actual HTTP port (listenPort) is 3000, but the public HTTP port (publicPortHttp)
is 80.
Within the server key:
cookieSecret (optional): Set the secret used as a seed to compute cookie strings. This secret
can be composed of any characters. It must be at least 64 characters long. If it is not set, it
is initialized with a secure random value when the server starts.cookieDomain (optional): Set this value if you need your cookie to be set for a domain
different from domain.cookieHttpOnly (default: true): Set the httpOnly flag of your cookies, so that they
cannot be accessed using JavaScript.cookieSecure (default: false): Set the secure flag of your cookies so that they are
only served via HTTPS (note: if Linkurious Enterprise is behind a reverse proxy, see trustedReverseProxies).cookieSameSite (default: "lax"): set to "none" to allow cookies to be set when Linkurious Enterprise
is embedded in an iframe.trustedReverseProxies (optional): array of reverse proxies to trust, to be used when cookieSecure
is enabled and the server is running behind a reverse proxy. This will cause the server to
trust the following headers set by the reserve proxy: X-Forwarded-For, X-Forwarded-Host,
and X-Forwarded-Proto. Example value: ["loopback", "123.123.123", "192.168.1.0/16"].
The array can contain a mix of:"192.168.1.150")"192.168.0.0/16")"loopback" (for "127.0.0.1/8" + "::1/128")"linklocal" (for "169.254.0.0/16" + "fe80::/10")"uniquelocal" (for "10.0.0.0/8" + "172.16.0.0/12" + "192.168.0.0/16" + "fc00::/7")Within the server key:
allowOrigin: Define the cross-origin resource sharing (CORS) policy.
Accept cross-site HTTP/S requests by default. The value can be:"abc.com"): only requests from "abc.com" domain are allowed."*.abc.com"): request from all sub-domains of abc.com are allowed.["abc.com", "*.def.com"]): requests from abc.com and all sub-domains of def.com are allowed."*"): requests from any domain are allowed.Linkurious Enterprise can be embedded in another Web page via an iframe under certain technical conditions.
This can be tricky due to modern Web browser security mechanisms.
Follow these steps:
https://app.example.com (domain: example.com), then Linkurious Enterprise
must be served under another subdomain of example.com, e.g. https://linkurious.example.com.server.cookieSameSite to "none" in the
configuration (see why).server.allowFraming to true. This will tell Linkurious Enterprise to disable
the default iframe protection by not setting the X-Frame-Options:SAMEORIGIN HTTP header.Within the server key:
customHTTPHeaders (optional): For compliance, custom HTTP headers can be added.
These headers will be returned in each HTTP response from the Web server.Example:
"customHTTPHeaders": { "header1": "value1", "header2": "value2" }
Note: Some header keys are reserved for Linkurious Enterprise and will be overwritten by the server to default values.
Within the ogma.settings.render key:
imgCrossOrigin (default: "anonymous"): Restrict the origin of images
displayed in visualizations to prevent running malicious code on the graphic card of users.
Display images from any origin by default. Read here to learn more.It is possible to disable the gzip compression for dynamic content that is returned by the Linkurious Enterprise server.
Within the server key:
disableCompression (default: false): Disable gzip compression for dynamic content when set to true.If you want to enable content-security-policy for Linkurious Enterprise, you need to use the custom HTTP Headers option of the Web server. The policies required for the application to work are:
default-src 'self': allow scripts, styles and images hosted by Linkurious Enterprise (referenced by URL)default-src 'unsafe-inline': allow code in <script> tags in pages hosted by Linkurious Enterprisedefault-src blob:: to allow running WebWorkers with Blob sources (required to run graph layouts)As a consequence, the recommended CSP policy is:
"customHTTPHeaders": {
"Content-Security-Policy": "default-src 'self' 'unsafe-inline' blob: data:"
}
Within the server key:
listenPortHttps (default: 3443): The port of the web server if HTTPS is enabled. See the "installing" section to learn why you should not set 443 directly.useHttps (default: false): Encrypt communications through HTTPS if true. Requires a valid SSL certificate.forceHttps (default: false): Force all traffic to use HTTPS only if true.
The server will redirect HTTP GET requests to HTTPS and reject all other HTTP requests.
ℹ️ Note: this flag should not be enabled when HTTPS is provided by a reverse proxy and not directly by the server. In that case, enforcing HTTPS needs to be handled by the reverse proxy itself.forcePublicHttps (default: false): Force all generated URL in Linkurious Enterprise to use HTTPS (useful when HTTPS is not enabled in Linkurious Enterprise but offered by an external reverse proxy).certificateFile: The relative path to the SSL certificate (must be in PEM format, located within the linkurious/data folder).certificateKeyFile: The relative path to a private key of the SSL certificate (must be in PEM format, located within the linkurious/data folder).certificatePassphrase: The pass-phrase protecting the SSL certificate (if any).tlsCipherList (optional): The ciphers supported by any connection established by Linkurious Enterprise as a server or client. It expects a string in OpenSSL cipher list format. The default value is tls.DEFAULT_CIPHERS.External communications with the Linkurious Enterprise server can be secured using SSL without installing third-party software.
If the Linkurious Enterprise server, graph database, and the search index are installed on different machines, we recommend using secure communication channels between these machines (e.g. HTTPS or WSS). Please refer to the data-source documentation and search index documentation to learn how to enable HTTPS.
To use custom Certificate Authorities (CA), please check how to use additional Certificate Authorities in Linkurious Enterprise.
The TLS protocol versions supported by Linkurious Enterprise are v1.0, v1.1, v1.2 and v1.3. By default, TLS v1.0 and v1.1 are disabled.
If you want to change the enabled versions of the TLS protocol:
- Stop Linkurious Enterprise
- Open the file at
data/manager/manager.jsonand add a line above"server/app.js",(for example: add"--tls-min-v1.3",to disable all versions of TLS bellow v1.3)- After the change, save the file and restart Linkurious Enterprise.
Available options (source):
--tls-min-v1.0: only enable TLS v1.0 and above--tls-min-v1.1: only enable TLS v1.1 and above--tls-min-v1.2: only enable TLS v1.2 and above (default)--tls-min-v1.3: only enable TLS v1.3 and aboveTo customize the exact list of ciphers used by the TLS protocol, see tlsCipherList in the
server configuration above.
When Linkurious Enterprise is started for the first time, authentication has to be set up so that users can access the platform.
There are two possible authentication options:
By default, when you access Linkurious Enterprise for the first time, you
need to create a local administrator account, unless an
external authentication provider has been configured and
an external group is mapped into the admin group
(see group mapping).
In order to create this first admin account, you need
to provide a valid license as a proof of ownership
of your Linkurious Enterprise instance.
Once this local administrator account has been created, it can be used to connect to Linkurious Enterprise and create other user accounts (see how to create users).
Passwords of local users are hashed with the PBKDF2 algorithm and the following parameters:
When using an external source for authentication, users are automatically created in Linkurious Enterprise when they connect for the first time.
These shadow users allow storing specific data such as preferences, groups, and visualizations.
Passwords of external users are never stored within Linkurious Enterprise.
Linkurious Enterprise supports the following external authentication services:
If your company uses an authentication service that Linkurious Enterprise does not support yet, please get in touch.
If you enable a Single-Sign-On (SSO) capable authentication service (OAuth/OpenID Connect or SAML2), your users don't need to sign in directly in Linkurious Enterprise. They instead sign in by clicking the SSO button and are then redirected to the identity provider for authentication.
If an external source already organizes users into groups, it's possible to use this information to automatically map
external groups into Linkurious Enterprise groups. To do so, you have to set the access.externalUsersGroupMapping configuration key
to be an object with the external group IDs as keys and the internal group IDs, group names, or a combination of both as values
(you can map both built-in and custom groups).
For example, if you want to provide group mapping for Microsoft Active Directory:
{ // under the access configuration key
// ...
"externalUsersGroupMapping": {
"Administrators": 1 // any Active Directory admin is a Linkurious Enterprise admin ("1" being the id of the admin built-in group)
"DataAnalysts": "analyst" // any Active Directory data analyst will be assigned to the "analyst" custom group of each data source(s) containing a group with that name
"ProductManagers": [3, "product manager"] // any Active Directory product manager will be assigned to the group with id "3" and to the "product manager" custom group of each data source(s) containing a group with that name
}
// ...
}
The built-in group names that you can use are the following:
adminread onlyread (which corresponds to "Read and run queries" in the UI)read and editread, edit and deletesource managerGroup name case sensitivity depends on the user-data-store vendor and collation.
For some identity providers, the external group IDs are an actual name; for others, it is an ID:
"818b6e03-15dd-4e19-8cb1-a4f434b40a04"access.ldap.groupField"Administrators" or the group distinguished name, e.g. "CN=Administrators,CN=Users,DC=linkurious,DC=local"To exclude some groups of users from signing in into Linkurious Enterprise, set up a list of
authorized groups in the configuration key access.externalUsersAllowedGroups.
{ // under the access configuration key
// ...
"externalUsersAllowedGroups": [
"CN=Administrators,CN=Users,DC=linkurious,DC=local",
"CN=Analysts,CN=Users,DC=linkurious,DC=local"
]
// ...
}
By default, when an external user is connected for the first time, their external groups are mapped once.
So any change in the user's group in the external source would not be reflected in the Linkurious Enterprise user.
However, setting autoRefreshGroupMapping to true makes an external user's groups
to be reset according to externalUsersGroupMapping, each time the external user signs in.
{ // under the access configuration key
// ...
"autoRefreshGroupMapping": true,
// ...
}
Note that when autoRefreshGroupMapping is true updating external users' groups from within Linkurious Enterprise is not allowed.
When using SSO to sign in to Linkurious Enterprise, if the identity provider groups are mapped to more than one built-in group, Linkurious Enterprise will choose the one with the highest permissions per data-source and ignore the other groups.
If the
adminbuilt-in group is used, it will override all other groups.
You can set default user preferences for any users in Linkurious as follows:
{ // at the root level of the configuration file
// ...
"defaultPreferences": {
"locale": "en", // default language for users (must be a valid language code supported by Linkurious Enterprise)
"pinOnDrag": true, // boolean, whether to pin nodes on drag by default cf https://doc.linkurious.com/user-manual/latest/layout/
"incrementalLayout": true // boolean, whether to enable incremental layout by default https://doc.linkurious.com/user-manual/latest/layout/
}
}
To view the supported languages, open the language selector from the Linkurious main navigation bar. The language code is the lowercase locale code of the language (without the country, ex: "en" for English, "fr" for French, etc.).
If Linkurious Enterprise is connected to an LDAP service, users will be authenticated using the external service at each log-in.
If you have an LDAP service running in your network, you can use it to authenticate users in Linkurious Enterprise.
Contact your network administrator to ensure that the machine where Linkurious Enterprise is installed can connect to the LDAP service.
For OpenLDAP compatible providers, add or edit the existing ldap section inside the access configuration section.
Allowed options in access.ldap:
enabled: true to enable this authentication strategyurl: URL of the LDAP serverbindDN (optional): "Domain Name" of the LDAP account used to search other accountsbindPassword (optional): Password of the LDAP account used to search other accountsbaseDN: Base "Domain Name" in which users will be searched. It can be a string or a non-empty array of stringsusernameField: Name of the LDAP attribute containing the user's nameemailField: Name of the LDAP attribute containing the user's e-mailgroupField (optional): Name of the LDAP attribute containing the user's groupThe bindDN and bindPassword are optional. If specified they will be used to bind to the LDAP server.
Example LDAP configuration:
"access": {
// [...]
"ldap": {
"enabled": true,
"url": "ldap://ldap.forumsys.com:389",
"bindDN": "cn=read-only-admin,dc=example,dc=com",
"bindPassword": "password",
"baseDN": ["dc=example,dc=com"],
"usernameField": "uid",
"emailField": "mail",
"groupField": "group"
}
}
You can configure Linkurious Enterprise to connect to multiple LDAP services.
During the authentication process, Linkurious Enterprise will validate the user credentials against each LDAP service and use the identity resolved by the first successful attempt, following the order in which they appear in the configuration.
Example with multiple LDAP configurations:
"access": {
// [...]
"ldap": [
{
"enabled": true,
"url": "ldap://linkurious.fr:389",
"bindDN": "cn=read-only-admin,dc=example,dc=com",
"bindPassword": "password",
"baseDN": ["dc=example,dc=com"],
"usernameField": "uid",
"emailField": "mail",
"groupField": "group"
},
{
"enabled": true,
"url": "ldap://linkurious.com:389",
"bindDN": "cn=read-only-admin,dc=example,dc=com",
"bindPassword": "password",
"baseDN": ["dc=example,dc=com"],
"usernameField": "uid",
"emailField": "mail",
"groupField": "group"
}
]
}
For Microsoft Active Directory, add a msActiveDirectory section inside the access configuration.
Allowed options in access.msActiveDirectory:
enabled: true to enable this authentication strategyurl: URL of the Active Directory serverbaseDN: Base "Domain Name" in which users will be searcheddomain: (optional) Domain of your Active Directory servernetbiosDomain: (optional) NetBIOS domain of your Active Directory servertls.rejectUnauthorized: (optional) Whether the SSL certificate of your Active Directory server will be checkedtls.enableTrace: (optional) Enable TLS packet trace informationsupportNestedGroups: (optional, default: true) Whether you want Linkurious Enterprise to resolve nested hierarchy in parent groupsUsers can authenticate with their userPrincipalName or their sAMAccountName.
Use the domain configuration key to avoid your users to specify the domain part of their userPrincipalName.
Use the netbiosDomain configuration key to avoid your users to specify the NetBIOS domain part of their sAMAccountName.
Example Active Directory configuration:
"access": {
// [...]
"msActiveDirectory": {
"enabled": true,
"url": "ldaps://ldap.lks.com:636",
"baseDN": "dc=ldap,dc=lks,dc=com",
"domain": "ldap.lks.com",
"netbiosDomain": "LINKURIO",
"tls": {
"rejectUnauthorized": true,
"enableTrace": false
}
}
}
In alternative is possible to use your on premises Active Directory in conjunction with Azure Active Directory to provide SSO to your users. Please refer to Prerequisites for Azure AD Connect for more information and to SSO with Azure AD to know how to setup Azure AD as an identity provider.
You can configure Linkurious Enterprise to connect to multiple Active Directory services.
During the authentication process, Linkurious Enterprise will validate the user credentials against each Active Directory service and use the identity resolved by the first successful attempt, following the order in which they appear in the configuration.
Example with multiple Active Directory configurations:
"access": {
// [...]
"msActiveDirectory": [
{
"enabled": true,
"url": "ldaps://ldap.lks.us:636",
"baseDN": "dc=ldap,dc=lks,dc=us",
"domain": "ldap.lks.us",
"netbiosDomain": "LINKURIOUS",
"tls": {
"rejectUnauthorized": true
}
},
{
"enabled": true,
"url": "ldaps://ldap.lks.fr:636",
"baseDN": "dc=ldap,dc=lks,dc=fr",
"domain": "ldap.lks.fr",
"netbiosDomain": "LINKURIOUS"
}
]
}
Linkurious Enterprise supports SSO authentication via Microsoft Entra ID (formerly known as "Azure Active Directory" or "Azure AD").
To set up Linkurious Enterprise authentication with Microsoft Entra ID, follow these steps:
Add > App Registration, create a new App called LinkuriousDirectory.Read.All access right to the new app (notice: an Azure admin's approval is needed)authorizationURL, e.g. https://login.microsoftonline.com/60d78xxx-xxxx-xxxx-xxxx-xxxxxx9ca39b/oauth2/v2.0/authorizetokenURL, e.g. https://login.microsoftonline.com/60d78xxx-xxxx-xxxx-xxxx-xxxxxx9ca39b/oauth2/v2.0/tokenclientID, e.g. 91d426e2-xxx-xxxx-xxxx-989f89b6b2a2clientSecret, e.g. gt7BHSnoIffbxxxxxxxxxxxxxxxxxxtyAG5xDotC8I=oauth2 section inside the access section in linkurious/data/config/production.jsonExample access.oauth2 configuration with Microsoft Azure Active Directory:
"access": {
// [...]
"oauth2": {
"enabled": true,
"provider": "azure",
"authorizationURL": "https://login.microsoftonline.com/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/oauth2/v2.0/authorize",
"tokenURL": "https://login.microsoftonline.com/XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX/oauth2/v2.0/token",
"clientID": "XXXXXXXX-XXX-XXXX-XXXX-XXXXXXXXXXXX",
"clientSecret": "XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
}
}
Note: Starting from version 4.2.1, Linkurious Enterprise automatically updates the OAuth2 token and authorization URLs to use the v2.0 endpoints:
https://login.microsoftonline.com/TENANT_ID/oauth2/v2.0/tokenhttps://login.microsoftonline.com/TENANT_ID/oauth2/v2.0/authorizeIf your configuration uses the previous URLs (
/oauth2/tokenor/oauth2/authorize), they will be automatically updated at launch.
The OAuth2 redirect URL of Linkurious Enterprise is the following:
http(s)://HOST:PORT/api/auth/sso/return.
When setting the redirect URL, you need to choose a platform inside the application in Azure Active Directory.
The right platform to choose is Web (and not Single Page application).
Linkurious Enterprise supports Google as an external authentication provider with Single Sign-On.
Since Google implements the OpenID Connect standard, it can be configured as an OpenID Connect provider in Linkurious Enterprise.
To set up Linkurious Enterprise authentication with Google, follow these steps:
authorizationURL, e.g. https://accounts.google.com/o/oauth2/v2/authtokenURL, e.g. https://www.googleapis.com/oauth2/v4/tokenclientID, e.g. 1718xxxxxx-xxxxxxxxxxxxxxxx.apps.googleusercontent.comclientSecret, e.g. E09dQxxxxxxxxxxxxxxxxSNoauth2 section inside the access section in linkurious/data/config/production.jsonTo limit the access to the Google accounts from your domain, use
the hd query parameter in the authorizationURL with your domain as value.
Example access.oauth2 configuration with Google:
"access": {
// [...]
"oauth2": {
"enabled": true,
"provider": "openidconnect",
"authorizationURL": "https://accounts.google.com/o/oauth2/v2/auth?hd=YOUR_DOMAIN",
"tokenURL": "https://www.googleapis.com/oauth2/v4/token",
"clientID": "XXXXXXXXXX-XXXXXXXXXXXXXXXX.apps.googleusercontent.com",
"clientSecret": "XXXXXXXXXXXXXXXXXXXXXXX"
}
}
The OAuth2 redirect URL of Linkurious Enterprise is the following:
http(s)://HOST:PORT/api/auth/sso/return.
This redirect url will need to be added in the Authorized redirect URls section of the credentials section on your Google Developers console
Linkurious Enterprise supports any OpenID Connect compatible provider as external authentication providers.
OpenID Connect (OIDC) is an identity layer on top of the OAuth2 protocol. It allows applications (like Linkurious Enterprise) to verify the identity of user based on the authentication performed by a server, as well as to obtain basic profile information about the user (username, email) in an interoperable manner.
To set up Linkurious Enterprise authentication with an OpenID Connect provider, you need to obtain the following parameters from the provider:
authorizationURL, e.g. https://accounts.google.com/o/oauth2/v2/authtokenURL, e.g. https://www.googleapis.com/oauth2/v4/tokenclientID, e.g. 1718xxxxxx-xxxxxxxxxxxxxxxx.apps.googleusercontent.comclientSecret, e.g. E09dQxxxxxxxxxxxxxxxxSNExample access.oauth2 configuration with any OpenID Connect provider:
"access": {
// [...]
"oauth2": {
"enabled": true,
"provider": "openidconnect",
"authorizationURL": "https://accounts.google.com/o/oauth2/v2/auth",
"tokenURL": "https://www.googleapis.com/oauth2/v4/token",
"clientID": "XXXXXXXXXX-XXXXXXXXXXXXXXXX.apps.googleusercontent.com",
"clientSecret": "XXXXXXXXXXXXXXXXXXXXXXX"
}
}
The OAuth2 redirect URL of Linkurious Enterprise is the following:
http(s)://HOST:PORT/api/auth/sso/return.
A claim is a pieces of
information that are returned by the authentication server for a given user (e.g. the e-mail
address of a user is usually in a claim called "email").
A scope is groups of
claims that can be requested from the authentication server (e.g. asking for the scope
"profile" will usually return several claims called "name", "family_name", etc.)
When setting up Linkurious Enterprise with OIDC:
To do so, the following configuration options are available:
access.oauth2.openidconnect.scope (default: "openid profile email"): The scopes that will be requested from the OIDC server (Note: the openid scope will always be requested, regardless of this setting).access.oauth2.openidconnect.emailClaim (default: "email"): The claim that will be used to read the user's e-mail (Note: if the value cannot be found, authentication will fail).access.oauth2.openidconnect.userClaim (default: "name"): The claim that will be used to read the user's name (Note: if the value cannot be found, the email will be used as username).access.oauth2.openidconnect.groupClaim (default: null, required when group mapping is enabled): The claim that will be used to read the user's list of groups.access.oauth2.openidconnect.userinfoURL (default: null, required when groupClaim is set): The URL of the UserInfo endpoint of the OIDC server, used to fetch groups.To set up group mapping in OpenID Connect is necessary to specify additional configuration keys:
openidconnect.userinfoURL, e.g. https://XXXXXXXXXX.oktapreview.com/oauth2/v1/userinfoopenidconnect.scope, e.g. openid profile email groupsopenidconnect.groupClaim, e.g. groupsFor example if you want to set up OIDC with Okta:
"access": {
// [...]
"oauth2": {
"enabled": true,
"provider": "openidconnect",
"authorizationURL": "https://XXXXXXXXXX.oktapreview.com/oauth2/v1/authorize",
"tokenURL": "https://XXXXXXXXXX.oktapreview.com/oauth2/v1/token",
"clientID": "XXXXXXXXXXXXXXXXXXXXXXX",
"clientSecret": "XXXXXXXXXXXXXXXXXXXXXXX",
"openidconnect": {
"userinfoURL": "https://XXXXXXXXXX.oktapreview.com/oauth2/v1/userinfo",
"scope": "openid profile email groups",
"groupClaim": "groups"
}
}
Linkurious Enterprise supports any SAML2 compatible provider as external authentication providers.
To set up Linkurious Enterprise authentication with a SAML2 provider, you need to obtain the following parameters from the provider:
url: The URL of the SAML2 endpoint of the identity provider (e.g. "https://example.com/adfs/ls")identityProviderCertificate (optional): The path to the certificate file of the identity provider in PEM format (e.g. "/Users/example/linkurious/samlIdentityProvider.pem")identityProviderCertificateValue (optional): The text value of the certificate of the identity provider in PEM format (note: if both this and identityProviderCertificate are set, all provided certificates will be used)groupAttribute (optional): The attribute in which the groups of the users is stored (e.g. "Groups")emailAttribute (optional): The attribute in which the email of the users is storedEither the identityProviderCertificate or the identityProviderCertificateValue must be provided for the configuration to be valid.
groupAttribute is the attribute of the SAML response containing the array of groups a user belongs to.
emailAttribute is the attribute of the SAML response that should contain the email address if the NameID format
of the SAML response is not already an email.
Example access.saml2 configuration with any SAML2 provider:
"access": {
// [...]
"saml2": {
"enabled": true,
"url": "https://example.com/adfs/ls",
"identityProviderCertificate": "/Users/example/linkurious/saml.pem",
"groupAttribute": "Groups"
},
}
To complete the login process, you need to configure your identity provider
to return the SAML response to Linkurious Enterprise at the following URL:
http(s)://HOST:PORT/api/auth/sso/return.
Please note that encrypted assertions are not supported by Linkurious Enterprise.
In particular, ADFS (Active Directory Federation Services) is a SAML2 provider that offers Single-Sign-On towards an Active Directory service, see more on Microsoft documentation.
To set up Linkurious Enterprise authentication with ADFS, Linkurious Enterprise has to be configured as a Relying Party Trust in ADFS (see how to configure the ADFS on the Microsoft documentation).
To set up group mapping, the list of groups associated to a user should be passed in the SAML2 response. See how to configure a claim for the groups on the Microsoft documentation.
The authentication is configured within the access configuration key
in the configuration file (linkurious/data/config/production.json):
authRequired (default: true): Whether to require authentication
(see below how to enable or disable authentication).
guestMode (default: false): Enable the guest mode.
enableCustomGroups (default: true): Enable the creation of custom groups.
If set to false, only the built-in groups are available
(see Creating a group).
enablePropertyKeyAccessRights (default: true): Enable the creation of property key access rights
(see Enabling property-key access rights).
loginTimeout (default: 10800: 3 hours): Seconds of inactivity after which a user is logged out.
dataEdition (default: true): Enable the creation, edition, and deletion of nodes and edges in all data-sources.
Permissions can be fine-tuned for each group, see the documentation about users and groups.
If set to false, all edition requests sent through Linkurious Enterprise to the data-sources will be rejected.
widget (default: true): Enable to publish visualizations online.
Published visualizations are always accessible by anonymous users.
externalUsersGroupMapping (optional): How to map external groups to Linkurious Enterprise groups
(see how to configure group mapping).
externalUsersAllowedGroups (optional): List of external groups of users allowed to log in into Linkurious Enterprise.
externalUserDefaultGroupId (optional): Default group id automatically set for new external users
when no other rule is set in externalUsersGroupMapping. This configuration setting should not be used when autoRefreshGroupMapping
is true, otherwise it may result in users with no groups to have no access to the data-source.
autoRefreshGroupMapping (default: false): If true, when an external user logs in, their groups are reset
according to externalUsersGroupMapping and are also not allowed to be updated.
ldap (optional): The connection to the LDAP service (see how to configure LDAP).
msActiveDirectory (optional): The connection to the Microsoft Active Directory service
(see how to configure Active Directory).
oauth2 (optional): The connection to an OAuth2/OpenID Connect identity provider
(see how to configure Azure AD, Google or a generic OpenID Connect provider).
saml2 (optional): The connection to a SAML2 identity provider (see how to configure SAML2 / ADFS).
floatingLicenses (default: Infinity): The maximum number of users that can connect to Linkurious Enterprise at the same time.
visualizationExport (default: true): Whether exporting visualization data in different formats is enabled for all users or not.
disableLocalAuth (optional): If true, users are only able to log in via SSO and the local authentication login form is disabled.
minimumPasswordLength (optional): For local authentication, the minimum required lengths for passwords.
requiredPasswordCharacterClasses (optional): For local authentication, collection of required character classes, by name.
When defined, one character of each class must appear at least once in a password for it to be valid. Example:
"requiredPasswordCharacterClasses": {
"number": "0123456789",
"uppercase": "ABCDEFGHIJQLMNOPQRSTUVWXYZ",
"symbol": "&~#'{}()[]-|`_\\/^@=+°¨£$¤,?;.:!§"
}
The name of each character class is used to generate error messages
To access Linkurious Enterprise when authRequired is true, users need accounts in Linkurious Enterprise.
Administrators can create accounts directly in Linkurious Enterprise (see how to create users)
or rely on an external authentication service.
Linkurious Enterprise supports the following external authentication services:
If your company uses an authentication service that Linkurious Enterprise does not support yet, please get in touch.
When opting for external authentication, it is recommended to have at least one local administrator account configured as a fallback in case the third party authentication provider is unavailable.
Authentication can be disabled by setting authRequired to false.
When user authentication is disabled, all actions are performed under
the special account named Unique User. The unique user has unrestricted
access and does not require a password, so anyone can access the platform.
We strongly discourage you to disable user authentication, as this leaves your data accessible to anyone. This option should only be considered in the case of a standalone local installation for evaluation or demonstration purposes.
If local authentication is disabled, it can be enabled from Linkurious Enterprise user interface.
Once local authentication is enabled, users need an account to access Linkurious Enterprise. Administrators can create accounts directly in Linkurious Enterprise (see how to create users).
To enable authentication use the Web user interface via the Admin > Users menu:
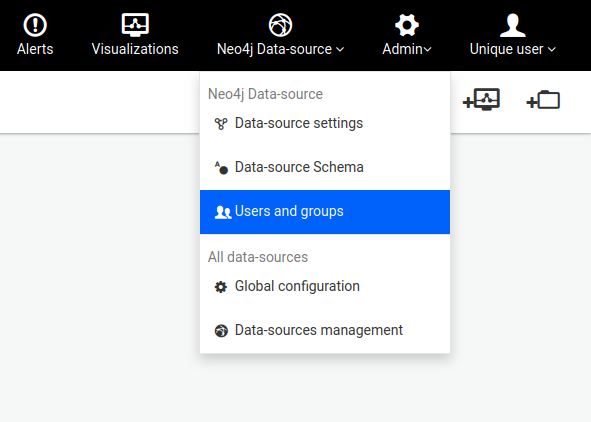
The following screen will be prompted if authentication is disabled. Click Enable Authentication.
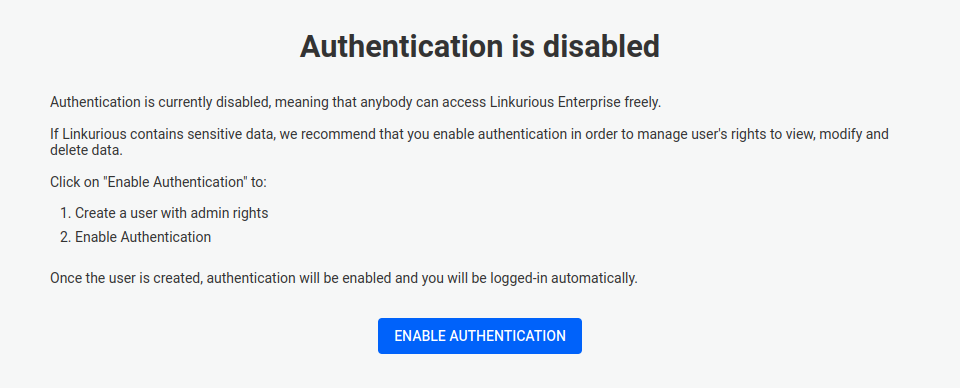
Create an admin account and click Save and enable.
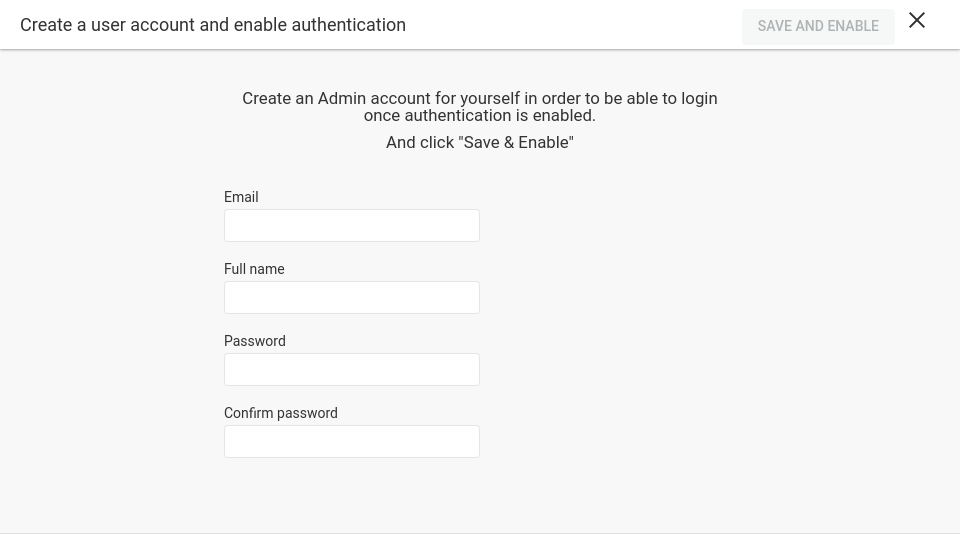
When access.floatingLicenses is defined, this is the behavior when a new user tries to log
into the server while it is full:
This page is accessed via Admin > Users & Groups in the main menu. The page lists all users, both local and external.
User management operations available to Administrators are the following:
When deleting a user who has shared assets, admins are able to transfer these to an eligible user. Shared assets are visualisations, widgets, queries, custom actions or alerts which have been shared with at least one other user. Eligible users, are all admins and users who share the same access right group(s) as the to-be-deleted user.
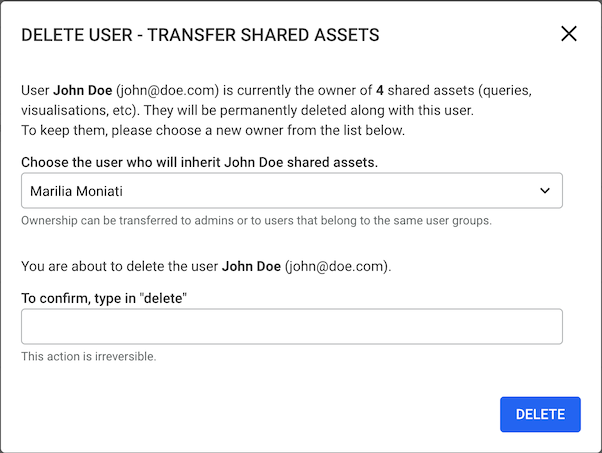
Below, useful information on the characteristics of each asset and their sharing options can be found:
Visualisations
A visualisation can be shared to all the users who have access to the datasource. The owner of a visualisation is able to set the access rights for each user who has access to the visualisation. A visualisation is considered a shared asset when it's shared with at least one user.
Widgets: If a visualisation has a widget, even if the visualisation is not shared, when the widget is transferred to a user, so is the visualisation.
Visualisation folders cannot be shared explicitly with users but they are transferred when they include a shared visualisation which is handed over. ( note this does not appear in the number of shared assets which is shown in the deletion modal )
Alerts, Custom Actions and Queries
You can create new users by clicking the Create a user button in the "users" tab of the "users & groups" page.
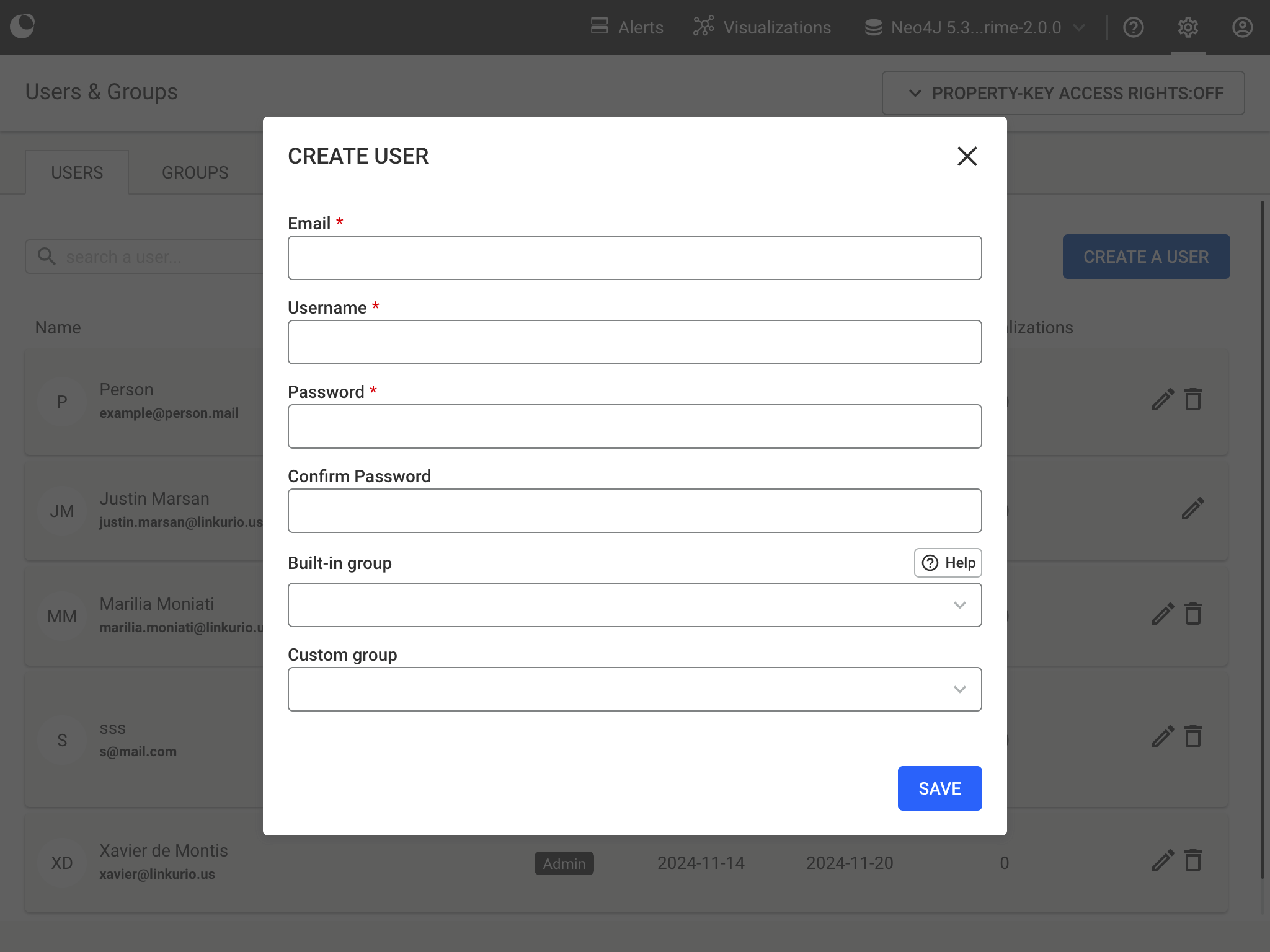
Email and Username fields can be used as login credentials and must therefor be unique.
See Assigning users to groups for details about Built-in group and Custom groups.
You can edit a user by clicking on the Pencil icon at the end of the user's row in the list of all users.
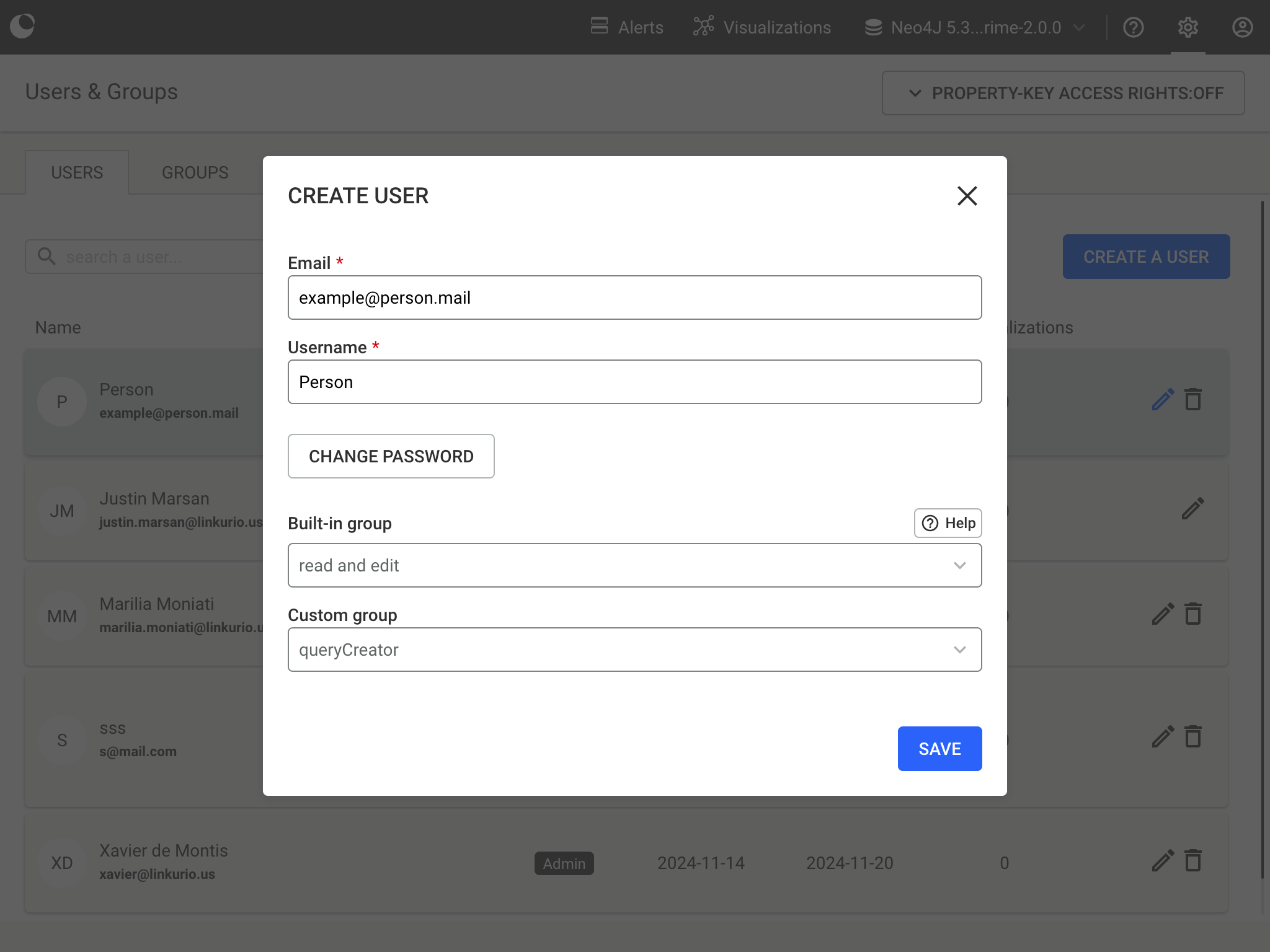
Email and Username fields can be used as login credentials and must therefor be unique.
To change a user's password, click the Change password button.
See Assigning users to groups for details about Built-in group and Custom groups.
You can assign users to groups. A user must be assigned to at least one group in order to have access to Linkurious Enterprise:
Group assignment can be done when creating or editing a user.
Assigning users to groups can be automated if you are using external authentication, using group mapping.
Linkurious Enterprise relies on a role-based access control model:
This page is accessed via Admin > Users & Groups in the main menu.
This page lists:
Group management operations available to the Administrators are the following:
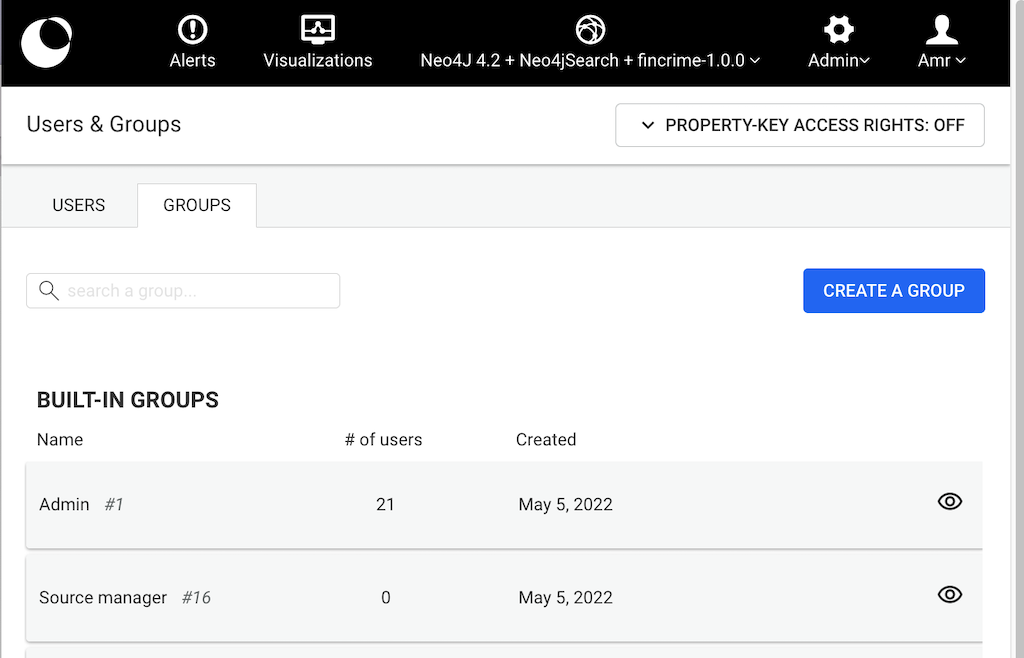
| Built-in group | Description |
|---|---|
| Admin | User in this group can manage all datasources, users and groups. They have the ability to create, read, edit and delete nodes and edges. They can also manage all spaces, alerts, and grouping rules, as well as queries and custom actions that are not private. |
| Source Manager | User in this group can manage this datasource and its users and groups. They have the ability to create, read, edit and delete nodes and edges. They can also manage all spaces, alerts, and grouping rules, as well as queries and custom actions that are not private. |
| Read/Edit/Delete | User in this group has the ability to read, edit, and delete nodes, edges, and properties. They can also create new alerts, queries, custom actions and node grouping rules. |
| Read/Edit | User in this group has the ability to read and edit existing nodes and edges, but not to delete them. They can also process alerts, create read-only queries, custom actions and node grouping rules. |
| Read And Run Queries | User in this group has the ability to display and explore existing nodes and edges. They can also process alerts, queries, custom actions and apply node grouping rules. |
| Read Only | User in this group can only view and explore existing nodes and edges. |
Creating a group is a 2-step process:
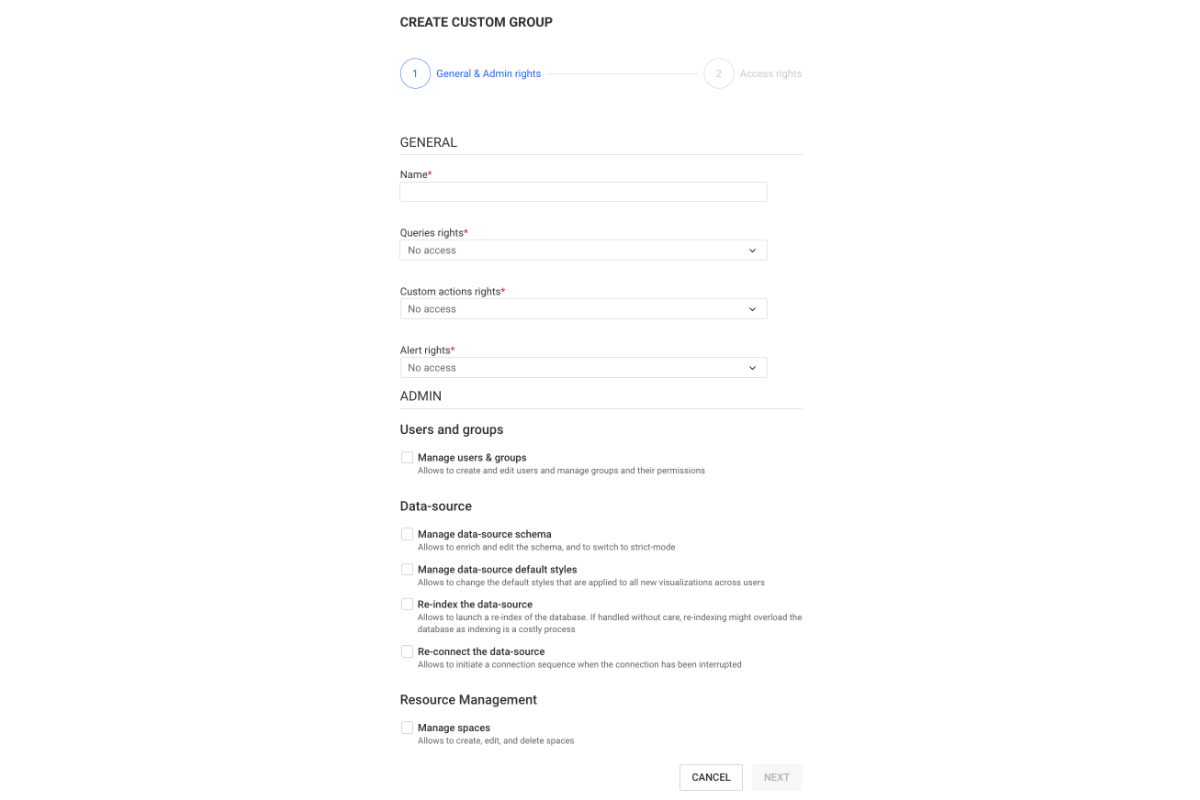
Queries access-rights
No access: the user group cannot execute queries (and cannot create them).Can run queries: the user group can execute read and write queries it was shared with, but cannot create them.Can create read-only queries and run queries:Can create read/write queries and run queries:Can manage, create read/write queries and run queries:Write queries are identified by keywords in their code:
- Cypher:
SET,CREATE,MERGE,DELETE,REMOVE,FOREACH,LOAD,DROP,CALL- Gremlin:
addProperty,property,addE,addV,drop,remove,clear
Custom actions access-rights
No access: the user group cannot execute custom actions (and cannot create them).Can run custom actions: the user group can execute custom action it was shared with but cannot create them.Can create and run custom actions:Can manage, create and run custom actions:Node grouping access-rights
No access: the user group cannot enable a group rule, they can see in their visualization groups from group rules activated by another user.Can apply node grouping rule: the user group can apply node grouping rules they have access to.Can create and apply node grouping rules:Can manage, create and apply node grouping rules:Alert access-rights
No access: The user group cannot access the Alerts (and cannot create them).Process alerts: The user group can access the Alerts, process the cases but cannot create new Alerts.Create and process alerts: Can manage, create and process alerts:IMPORTANT
Please note that users who don’t have access to specific node categories and/ or edge types (see Queries access rights) can still create/access queries that return such information and display it in the case columns/attributes. They will not see the node and/ or edges in the visualization/case view but the data will still be displayed in the alert columns.
Admin access-rights
Users and groups
Manage users & groups: the user group can create and edit users and manage groups and their permissions.Data-source
Manage data-source schema: the user group can enrich and edit the schema, and to switch to strict-mode.Manage data-source default styles: the user group can change the default styles that are applied to all new visualizations across users.Re-index the data-source: the user group can launch a re-index of the database. If handled without care, re-indexing might overload the database as indexing is a costly process.Re-connect the data-source: the user group can initiate a connection sequence when the connection has been interrupted.Resource management
Manage spaces: the user group can create, edit, and delete spaces.For users that belong to multiple groups, access-rights are cumulative. In other words, a user can do something if at least one of their groups allows them to do it.
For example if user belongs to 2 groups: one having No access and the
other Process Alerts for the Alert rights, then they have the right
to Process Alerts because one of their groups allows them to do so.
There are 2 available options. You can read about them in their dedicated sections:
NONE: The user can't access (search or display) nodes (resp. edges) of that category (rest. type).READ: The user can search display nodes (rest.edges) of that category (resp. type).EDIT: The user can edit properties of nodes (rest. edges) of that category (resp. type).CREATE AND DELETE: The user can: 
Foo belong to the groups Accounting and SalesAccounting has NO ACCESS access right on node-category CONTRACTSales has EDIT access right on node-category CONTRACTAs a result: user Foo has EDIT access on node-category CONTRACT
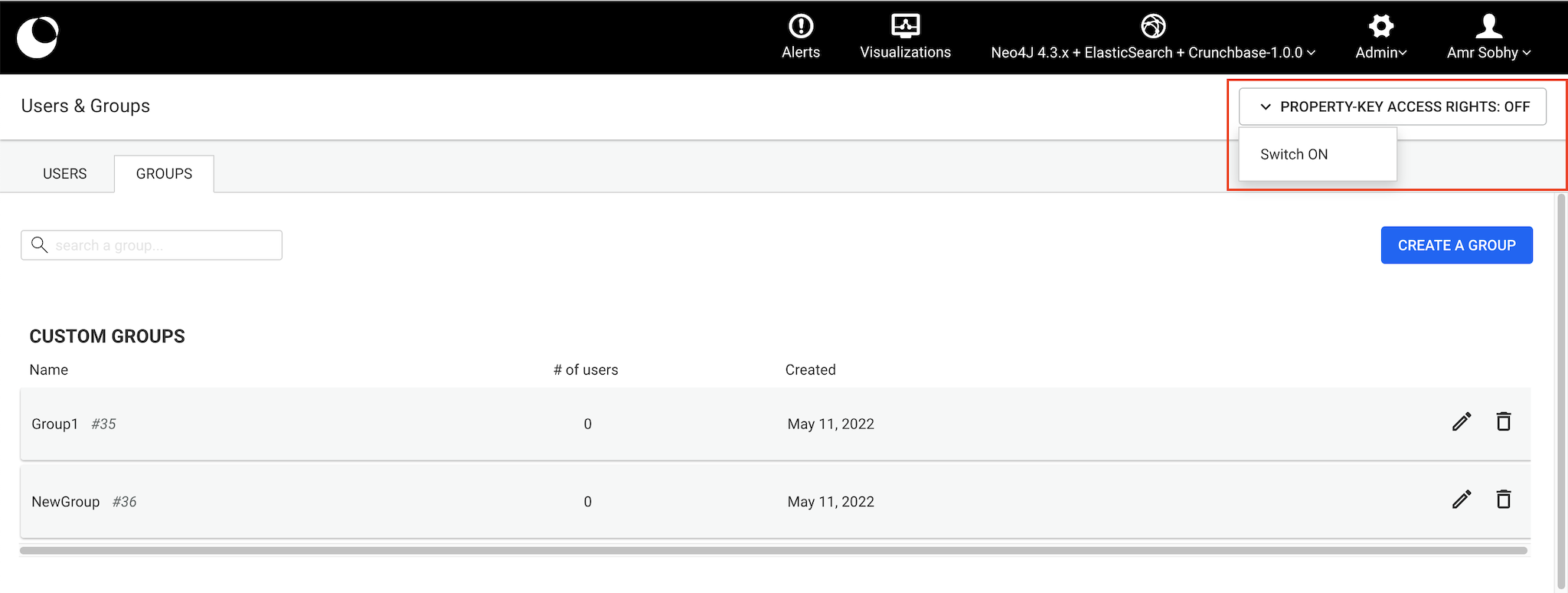
To define property-key access rights, the administrator needs to create (or edit) a custom group: after the access-rights configuration page, with the property-key access rights feature switched on, a second panel will be displayed.
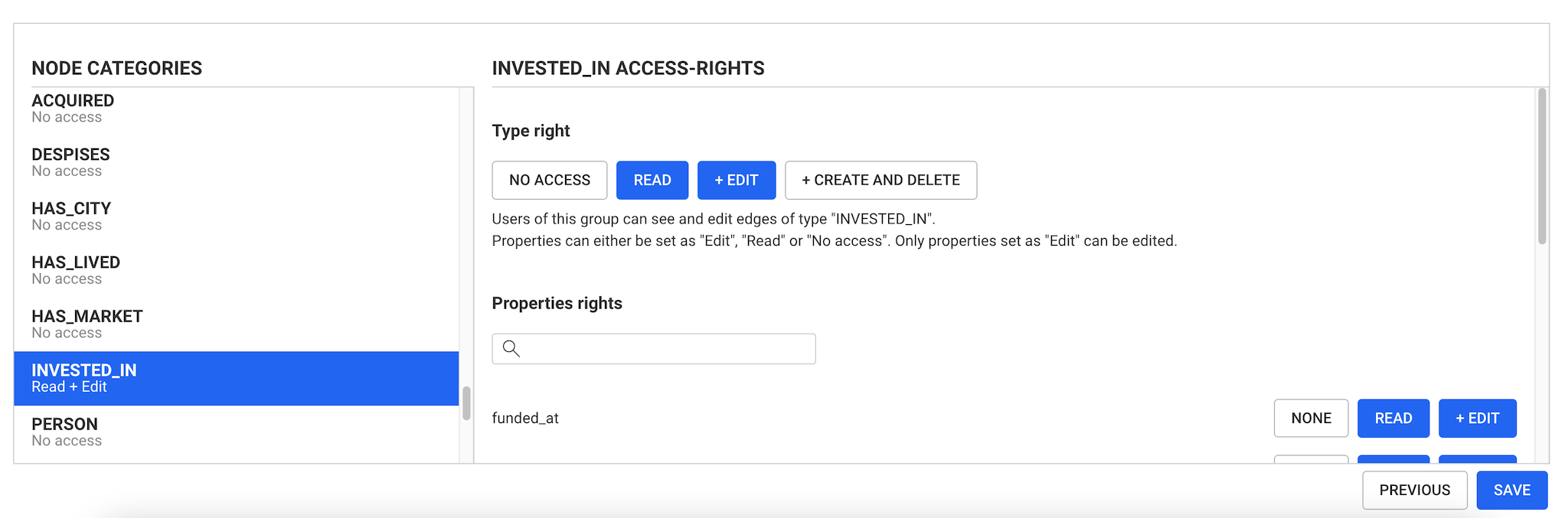
From here:
For each node category (resp. edge type), the administrator is able to set one of the following access-rights (exactly the same as for Standard access rights):
NONE: The user can't access (search or display) nodes (resp. edges) of that category (rest. type).READ: The user can search display nodes (rest.edges) of that category (resp. type).EDIT: The user can edit properties of nodes (rest. edges) of that category (resp. type).CREATE AND DELETE: The user can: For each property the administrator is able to set one of the following access rights:
NO ACCESS: neither the property nor its value can be seen by this user group. READ: the property value is displayed to this user group but cannot be edited.EDIT: the property value is dipsplayed to this user and can be edited.Access rights are cumulative (see example below).
Foo belong to the groups Accounting and SalesAccounting has: READ access right on node-category COMPANYREAD access right on the property address of the category COMPANYSales has: EDIT access right on node-category COMPANYNO ACCESS access right on the property address of the category COMPANYAs a result, user Foo has:
EDIT access right on node-category COMPANYREAD access right on the property address of the category COMPANYThe Guest mode is a way to share graphs with people who do not have an account on Linkurious Enterprise.
Key characteristics:
Standard user interface:
Guest mode user interface:
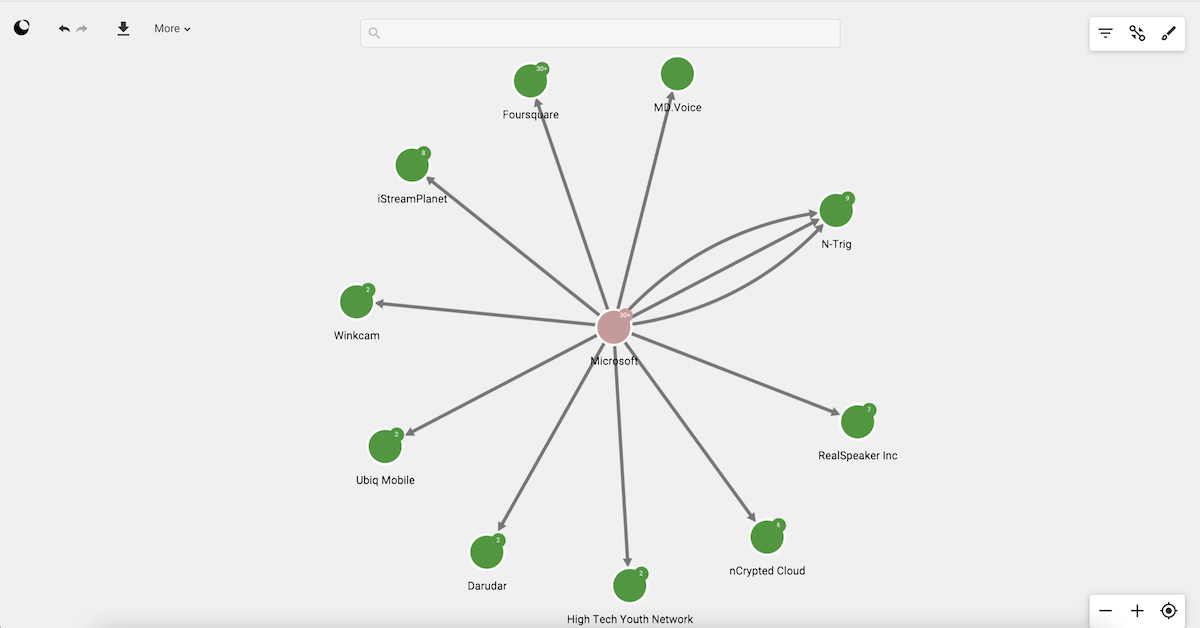
By default, the Guest mode is disabled. Enabling the Guest mode is done on a per-source basis so that you can manage the access rights associated with the Guest mode at the source level.
Enabling it is a 3-steps process:
guest@linkurio.us. By default, it is not associated
with any user group. Assign the Guest user
to the Read-Only group, or any custom group if you need to restrict
its rights (see the security warnings below).Once enabled, the Guest mode is available at http://your-domain.com/guest
(replace your-domain.com with the actual host and port of your server).
By default, guest users won't be allowed to search, export and use the design, filter and edge grouping panel.
If you want to allow guest users to use these features, you can go to the Configuration screen (Menu > Admin > Global configuration) and, under the Guest Mode configuration, change the following values:
uiWorkspaceSearch (default false): Whether to allow to searchuiExport (default false): Whether to allow the exportuiLayout (default simple): Whether to allow guest users to have the same UI for layouts as logged-in users (regular), a simpler UI (simple) or no possibility to layout at all (none)uiDesign (default false): Whether to allow the design paneluiFilter (default false): Whether to allow the filter paneluiEdgeGrouping (default false): Whether to allow the edge grouping panellocale (default en): The language to use for the guest user interface. It must be a valid locale supported by Linkurious Enterprise.All people who have access to /guest will be able to browse the whole
database (in read-only mode), even if nobody has explicitly shared a
specific visualization with them. You may want to check who has access
to /guest before enabling the Guest mode.
If you have assigned the Guest user to the Read Only built-in user
group, all node categories and edge types will be available to see by
the people who can access /guest. If the database contains sensitive
data, you should create a custom group
with limited rights on the data and assign the Guest user to that group.
Even if the Guest user is assigned to a group that has "Write" or "Delete" permissions, Guest mode users will not be able to write or edit data.
When initialized with a visualization, the Guest mode allows the user to expand the graph beyond the content of that visualization. Consider restricting the Guest user access rights if that is an issue.
Accessing /guest directly will return an empty workspace.
Using parameters in the URL you can populate the Guest mode workspace with:
/guest?populate=visualizationId&item_id=123/guest?populate=nodeId&item_id=123/guest?populate=expandNodeId&item_id=123/guest?populate=searchNodes&search_query=paris&search_fuzziness=0.8/guest?populate=queryId&item_id=123/guest?populate=queryId&item_id=123&query_parameters={"param1":"value1"}The Guest user sees the current state of a visualization. Any change to a visualization from an authenticated user will be automatically applied to the public link shared to the Guest user.
Users accessing visualizations through Guest Mode are considered regular users under the Linkurious Enterprise License. A valid license for these users is required to enable the use of Guest Mode.
Linkurious Enterprise uses a data schema to deliver some of its features. However, most graph databases are schema-less. As a consequence, Linkurious Enterprise automatically detects the data schema from each data-source. The automatically detected schema is:
The schema can be extended manually. An administrator can:
The schema has two modes:
The Partial mode is flexible and incremental, whereas the Strict schema is stable and normative. Therefore the Partial mode is a better fit in early projects when the data schema is poised to change. The Strict mode is a better fit for production-ready projects that require a more controlled environment.
IMPORTANT
Statements made in the schema DO NOT alter the data in the database:
- Setting a property type in Linkurious Enterprise will not change the type of the corresponding values in the graph database (see section about the property types).
- Switching search/visibility options for a node-category, edge-type or property in Linkurious Enterprise will not remove or change the data stored in the graph database.
- Switching to strict mode in Linkurious Enterprise will not remove or change the data stored in the graph database.
The schema can be reached through the Admin menu.
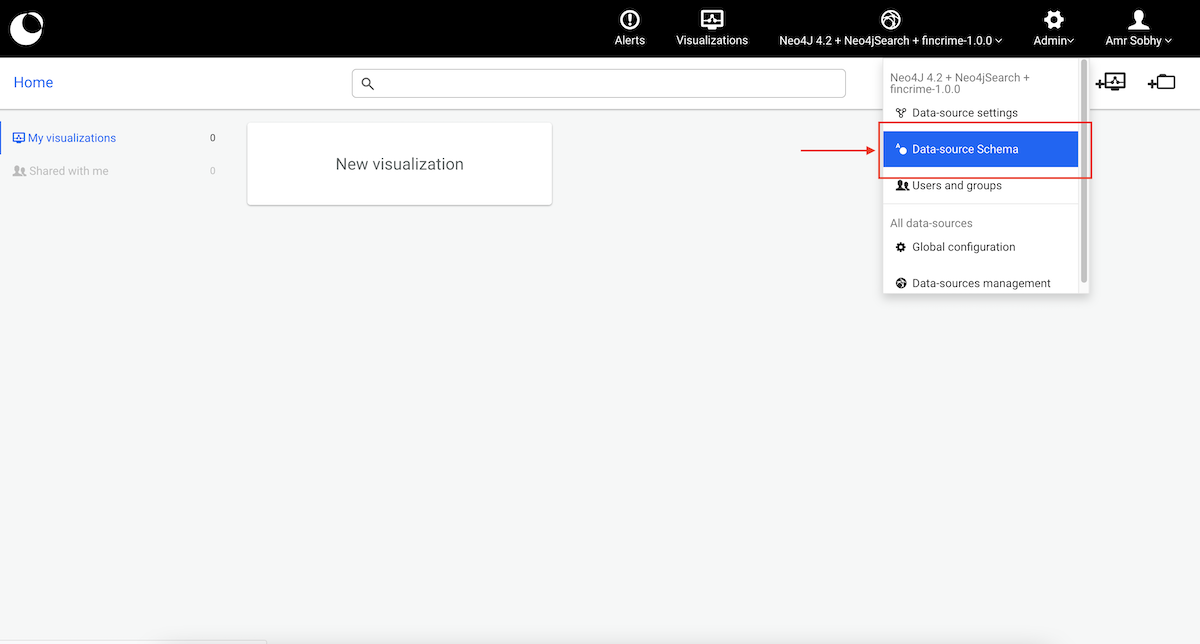
The schema is presented as two columns:
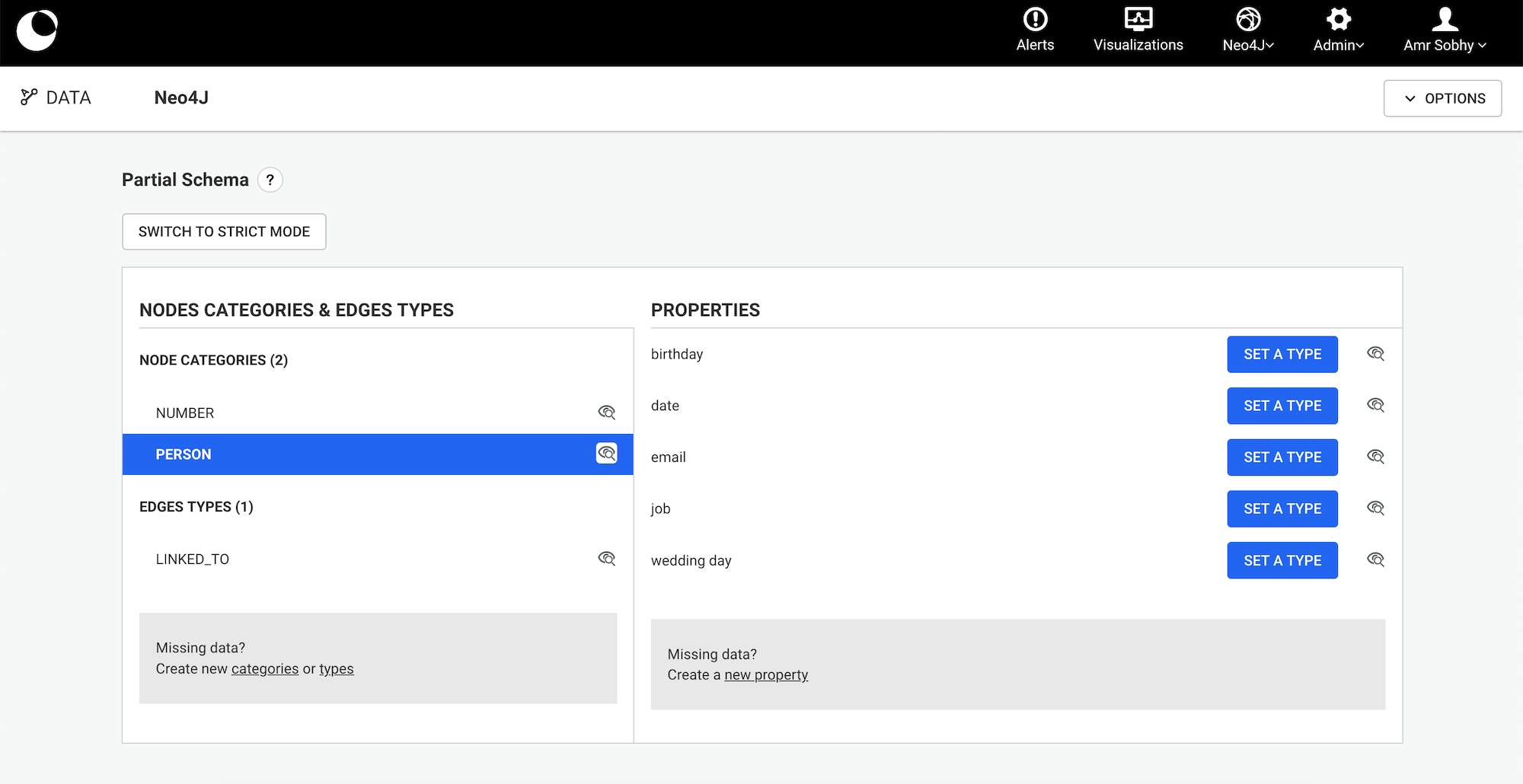
The "eye" icon next to node categories, edge types and properties allows to switch the visibility to View & Search, Only view or No access. See the dedicated section for more details.
The schema may be incomplete. Or you may want to add a category, type or property that is not yet in the data. You can create them manually through action links available at the bottom the list.
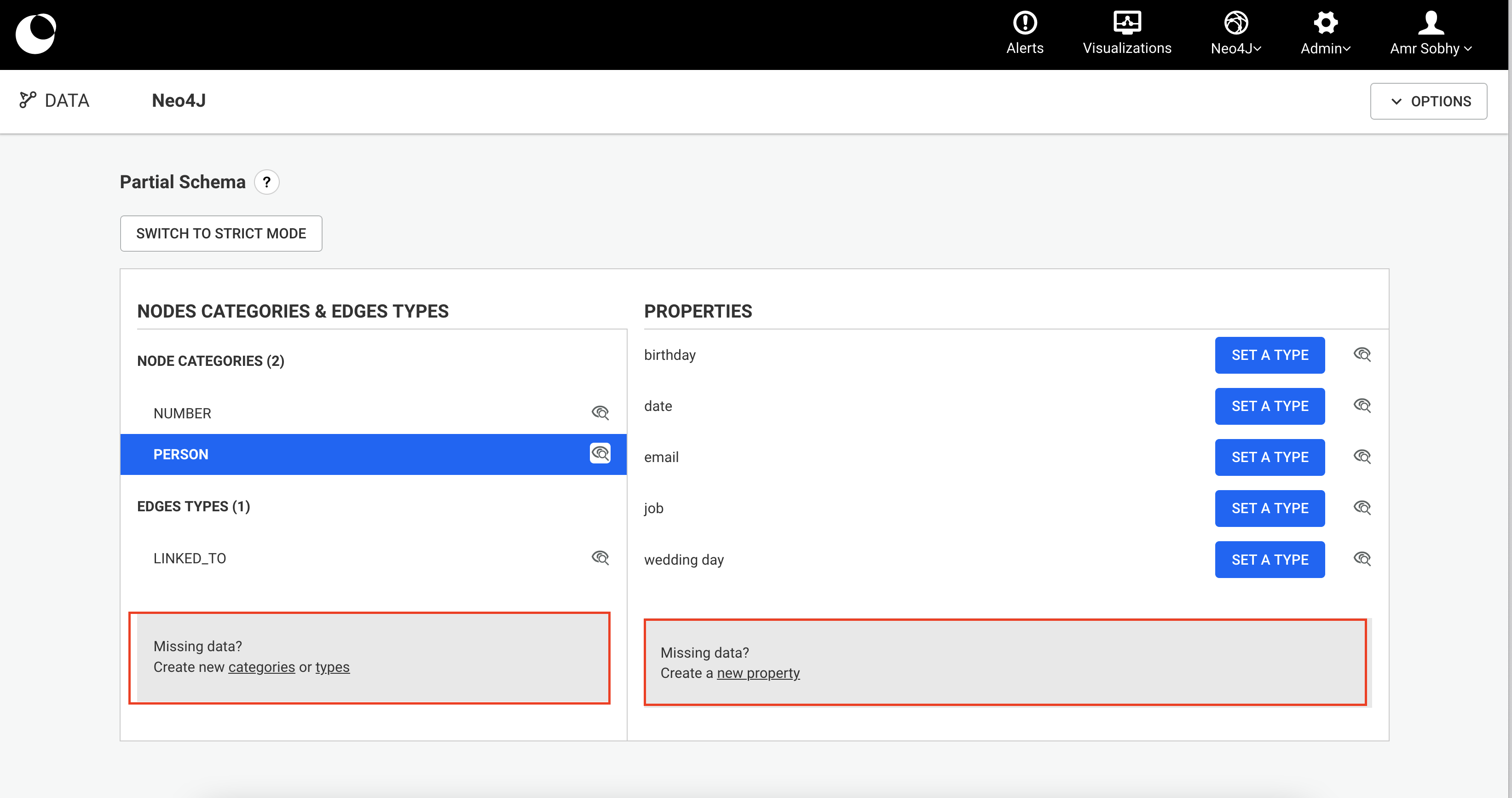
Some node-categories or edge-types are unlikely to be searched for. As a consequence they pollute the search results.
You can disable the search by clicking on the "eye" icon and select Only view option. The nodes or the edges will then be not searchable but stay visible.
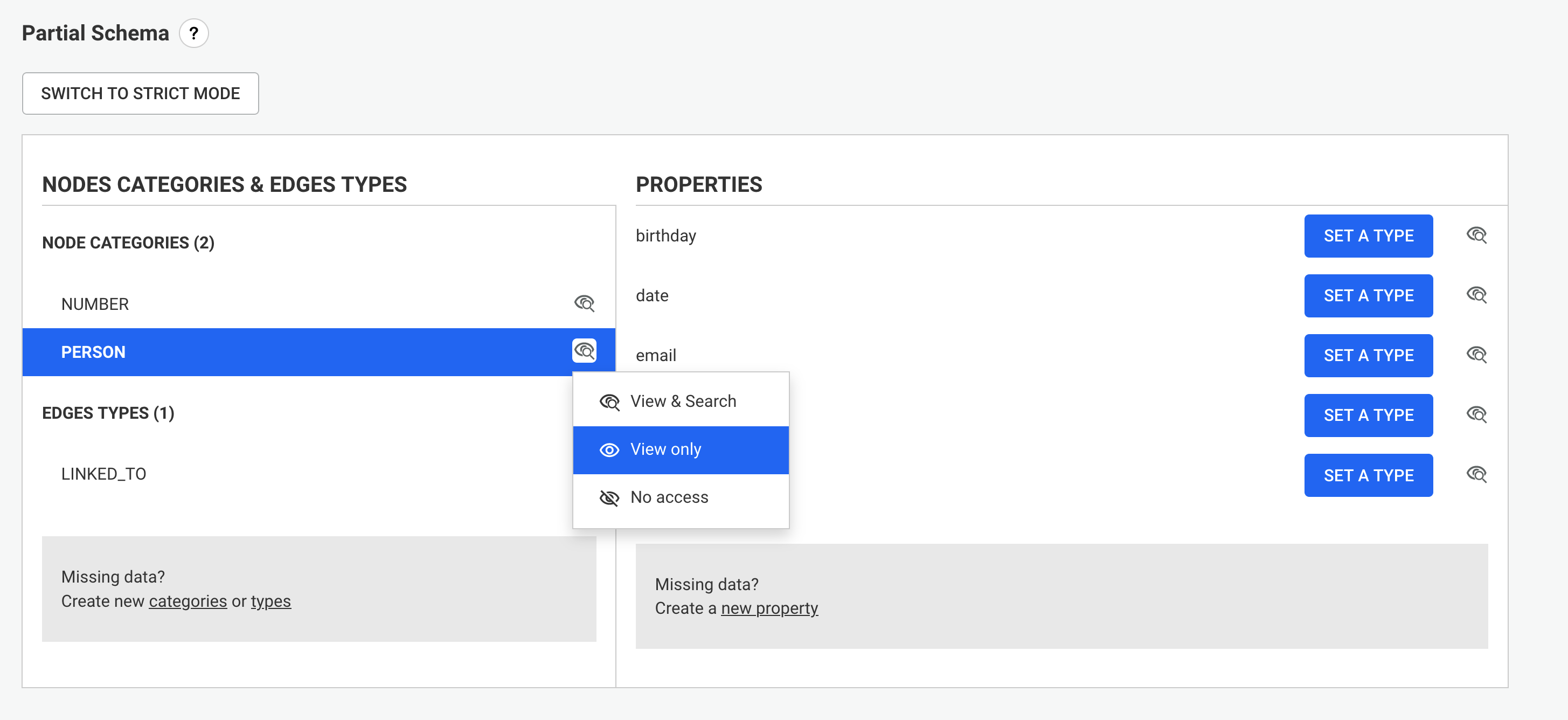
You can also remove them from the search by selecting No access option. The nodes or the edges will then be not searchable and not visible.
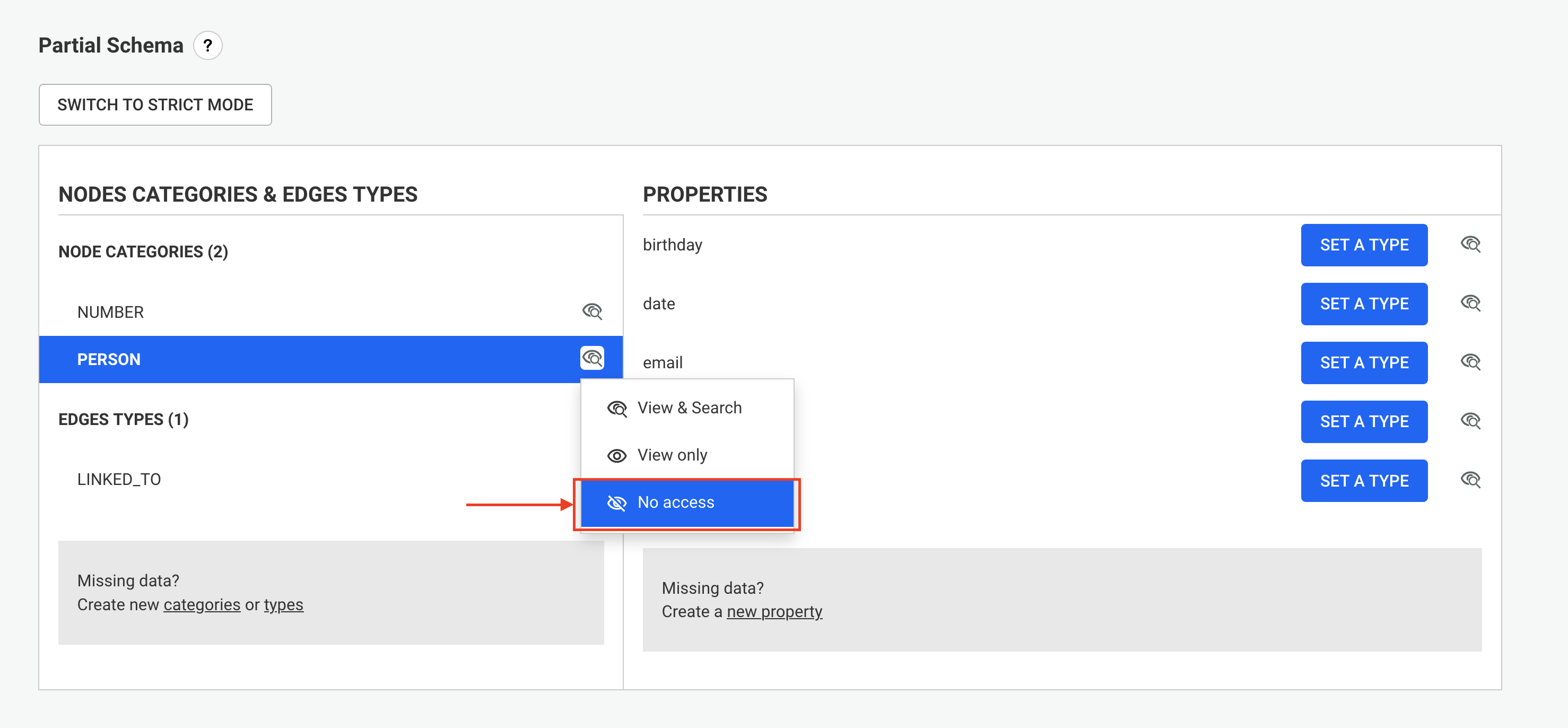
The "eye" icon will be updated by the selected search/visibility option
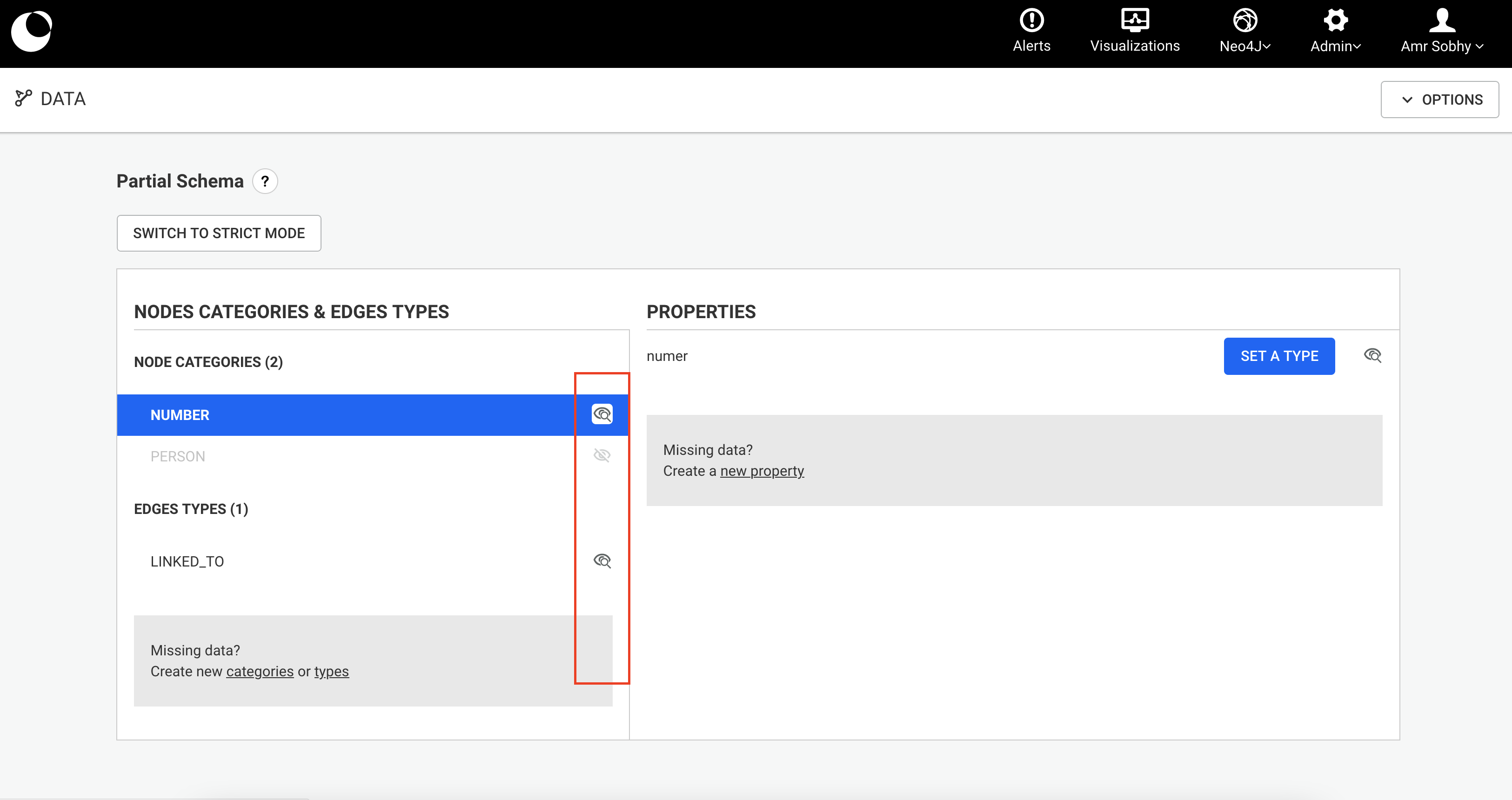
The button "Switch to strict mode" allows you to switch to a strict mode. See the dedicated section for more information.
If the schema has changed a lot and you want to start fresh, it is possible to "Reset the schema": this will remove any schema declaration, and trigger a new sampling of the database.
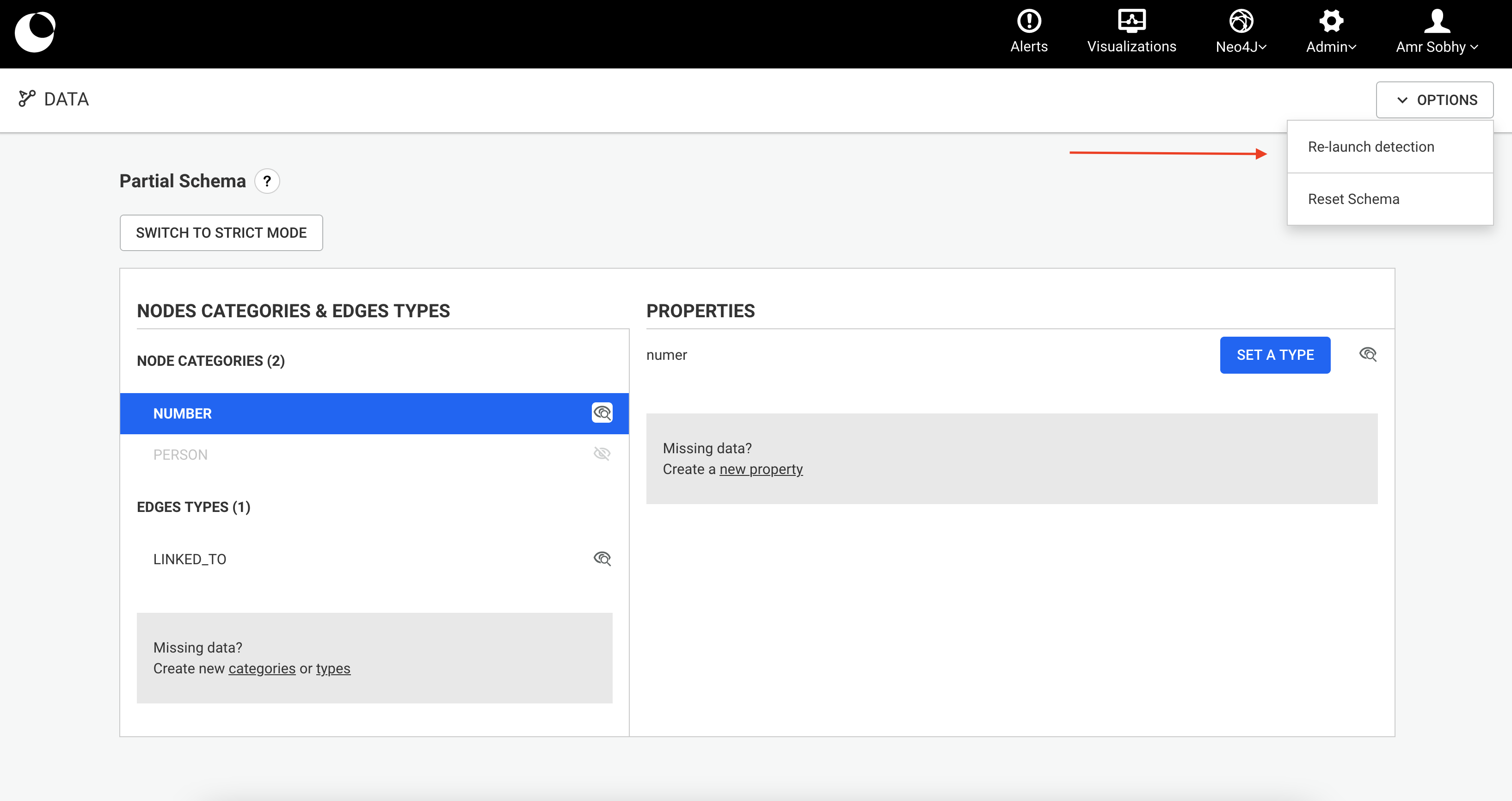
If the schema is too incomplete (due for example to a recent import in the graph database with lots of new node categories / edge types / properties) it's possible to launch manually another sampling round to detect the missing categories / types / properties, using the Re-launch detection option in the Options menu.
The sampling of the database will scan only part of the database. The larger the sample, the more accurate but the longer the detection.
The default setting for the sampling size is 500 nodes per node category, 500 edges per edge type.
You can change this by editing the value of sampledItemsPerType in the Advanced section of the configuration (via Admin > Global configuration).
When Linkurious Enterprise indexes your data, it will only index nodes and edges whose categories and properties are marked as searchable.
On the Linkurious Enterprise interface to set a category / property to be searchable, you need to select the (view & search) option, However if you want a category / property to be non-searchable you need to select the (view-only) option.
If for example in the schema I declare:
In search, I will be able to search by "last_name" but not by "first_name". In case, I want to enable search also by "first_name", I will need to mark this property as searchable, however if I do this after indexing has occurred, I will see a warning in the schema configuration page telling me that there are inconsistencies I will need to solve in order to search for some properties. In order to fix the issue, a full indexing is required.
In case a property has been changed from searchable to visible, another information is shown, telling us that, the current search index is not optimized, which means there are more properties indexed than what are really needed to search. Running a full indexing should optimize the search index.
The type of a property can be set by clicking on the "Set a type" button next to a property's name. A popup allows you to choose a type.
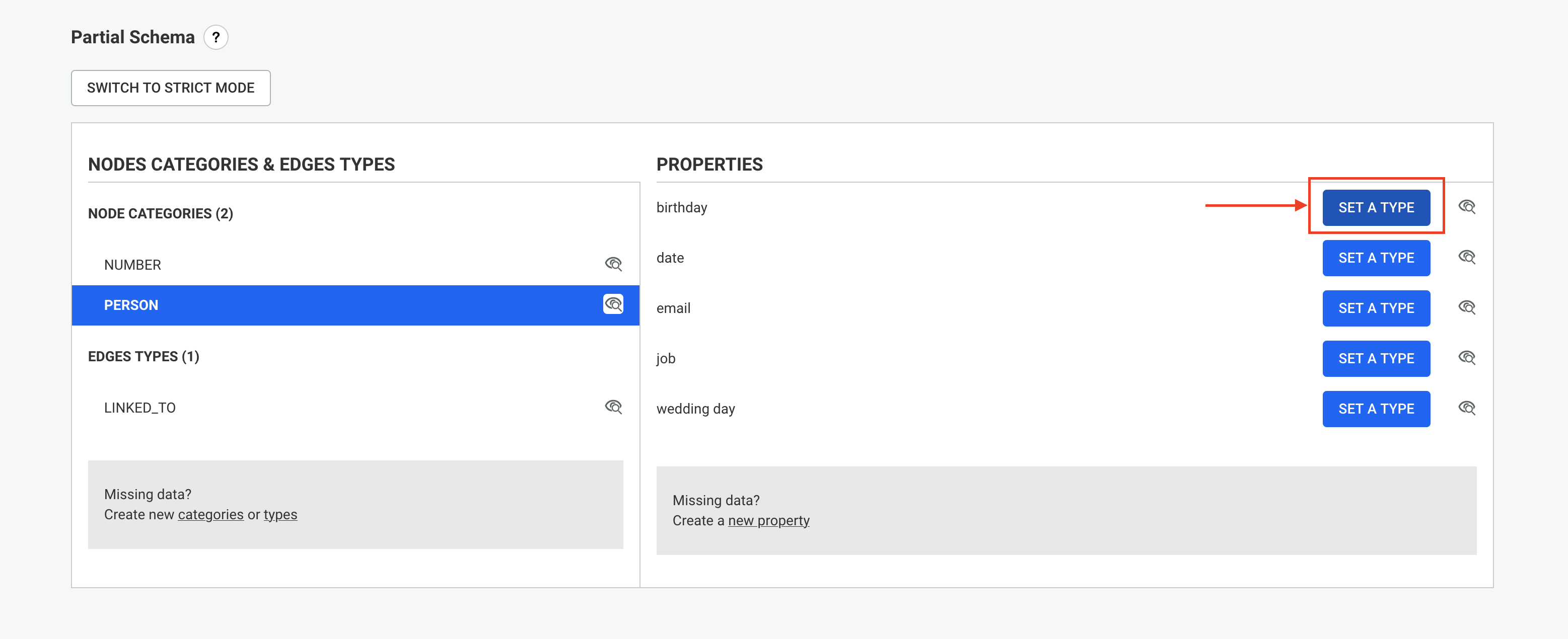
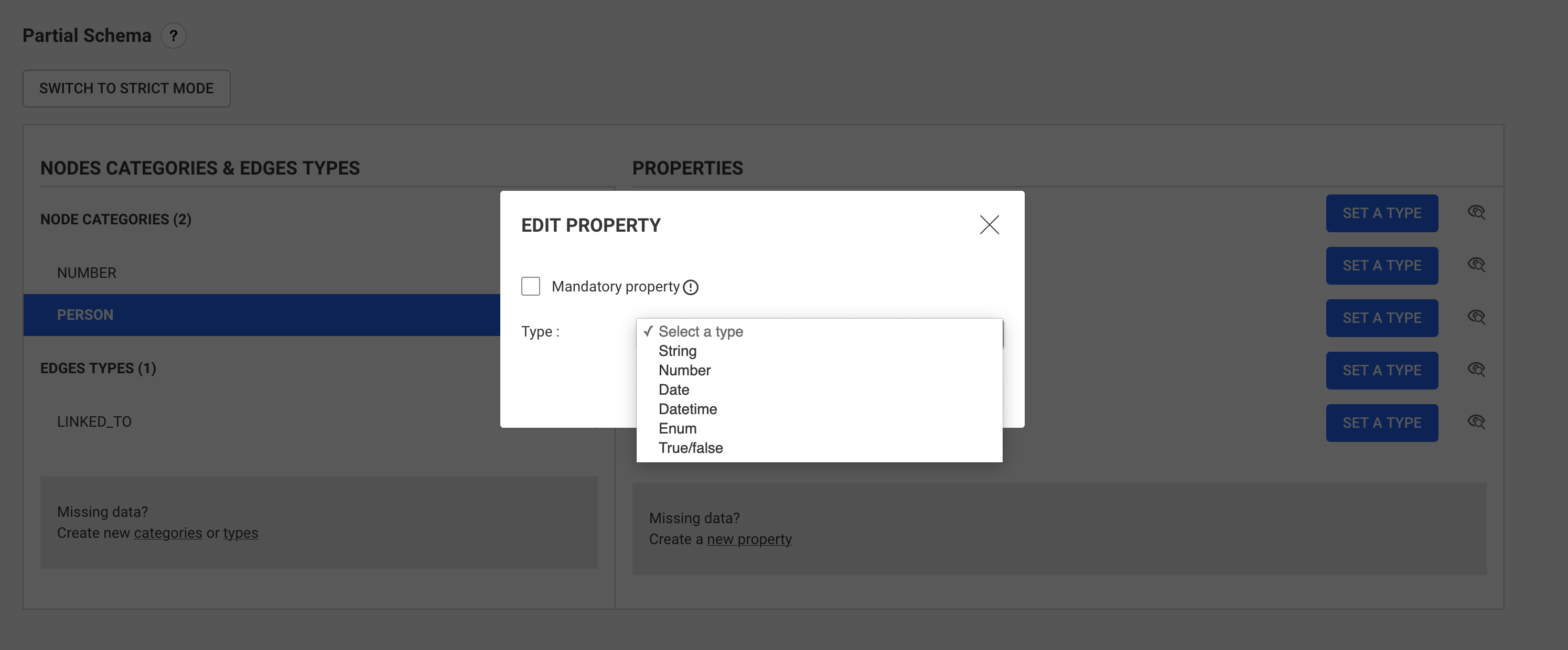
Once a property type has been set, the type is displayed next to the property name, and it is possible to change it using the "Edit" link.

IMPORTANT
Setting a property type in Linkurious Enterprise will not change the type of the corresponding values in the graph database. The consequences are explained below for each property type.
Setting a property type as String does not require any additional information:
Once a property type has been set as a String, all values for that property are processed as a String.
In the Workspace Filter panel:
Setting a property type as Number does not require any additional information:
Once a property type has been set as a Number, values for that property fall into 2 categories:
In the Workspace Property panel, invalid values are displayed as string with a warning.
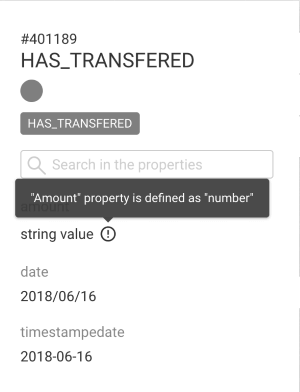
When using Google Spanner as a data-source, a technical limitation will cause some properties defined as
INT64with large values (≥ 2^53) to be displayed as invalid, even though they are correctly defined as a number in the schema.
In the Workspace Filter panel:
When editing or creating a node/edge, properties set as Number can only accept a valid number.
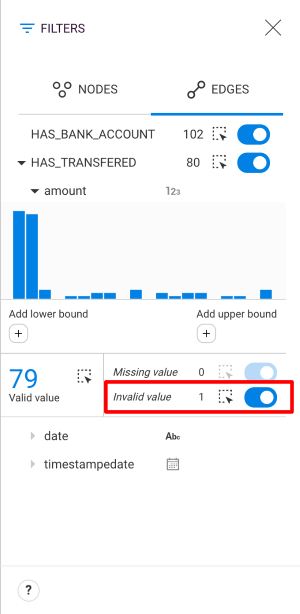
Setting a property type as "Enum" requires to enter a list of authorized values:
, or click on the "Add" button.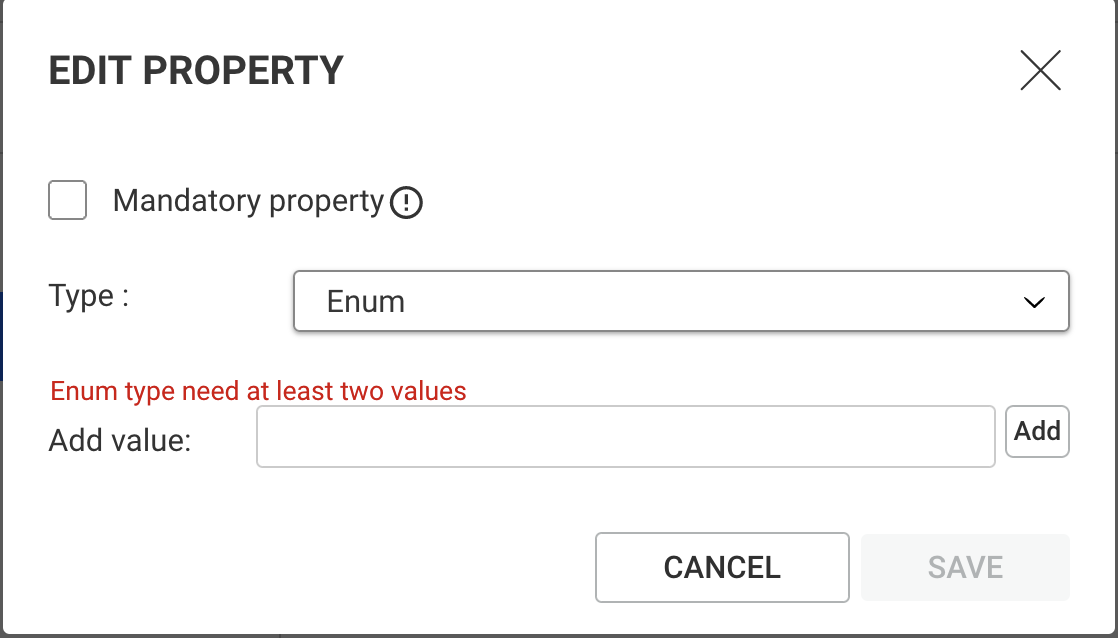
Once a property type has been set as Enum, values for that property fall into 2 categories:
In the Workspace Property panel, invalid values are displayed as string with a warning.
In the Workspace Filter panel:
When editing or creating a node/edge, the user pick the value of an Enum property from the list of the authorized values.
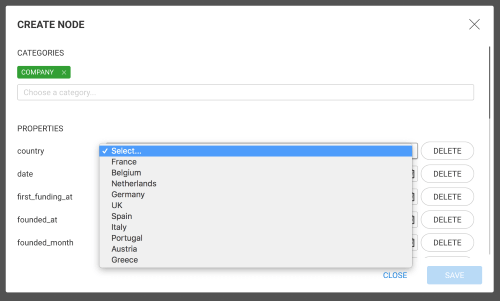
Setting a property type as True/false does not require any additional information:
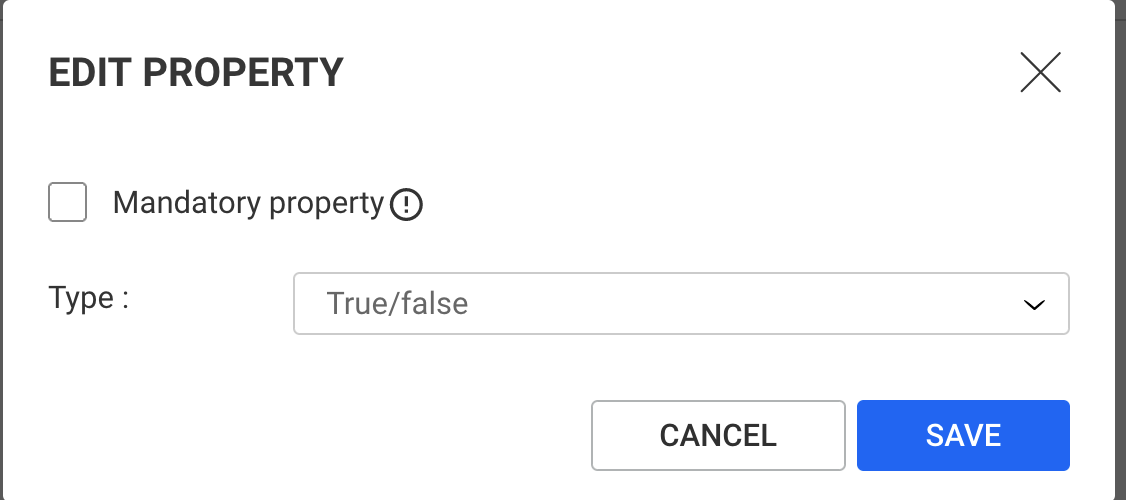
Once a property type has been set as a True/false, values for that property fall into 2 categories:
In the Workspace Property panel, invalid values are displayed as string with a warning.
In the Workspace Filter panel:
When editing or creating a node/edge, the user picks the value of a True/false property from a list containing "true" and "false".
Setting a property type as Date requires to select the storage format of the date in the graph database:
Native: the values are stored as native date.
yyyy-mm-dd, dd/mm/yyyy, mm/dd/yyyy: the values are stored as String in the graph database according to one of these formats.
Timestamp (in milliseconds), Timestamp (in seconds): the values are stored as Numbers in the graph database. They represent a date as the number of milliseconds (or seconds) elapsed since January 1st, 1970 GMT and the date to be encoded.
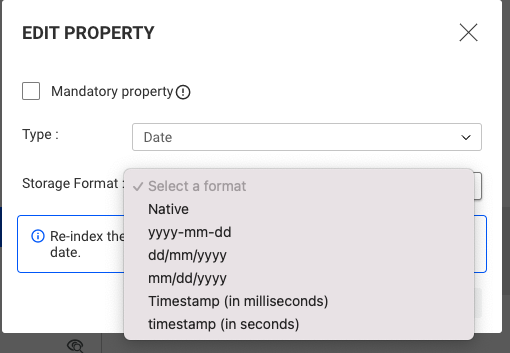
Once a property type has been set as Date, values for that property fall into 2 categories:
In the Workspace Property panel:
Anywhere a date value is displayed (including the Property panel):
yyyy-mm-dd regardless of their storage format.In the Workspace Filter panel:
When editing or creating a node/edge, the user picks the value of a Date property from a Date picker.
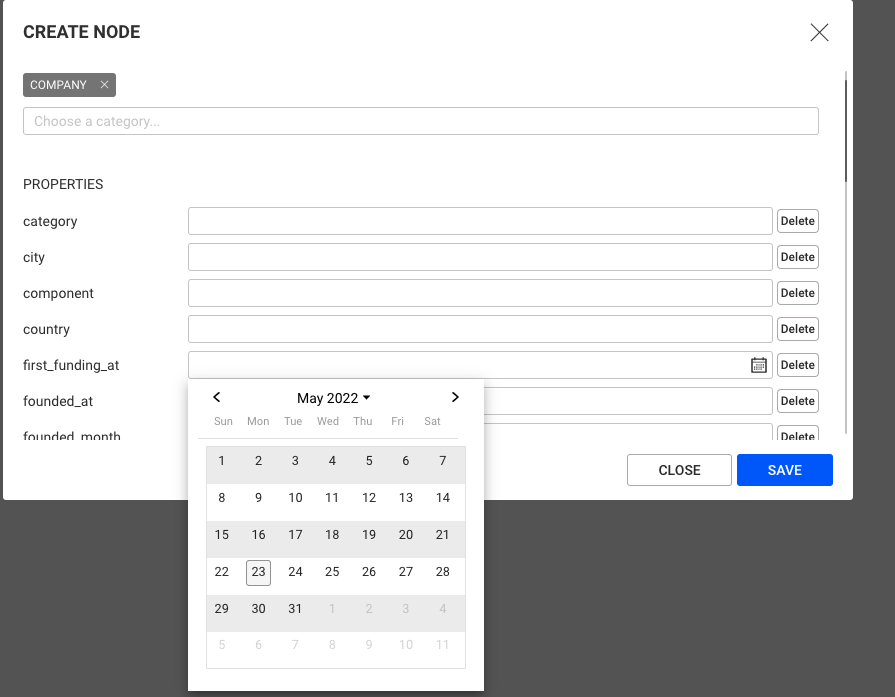
Setting a property type as Datetime requires to select the storage format of the date in the graph database:
Native: the values are stored as native date-time.
YYYY-MM-DDThh:mm:ss: the values are stored as String in the graph database according to one of this format.
Timestamp (in milliseconds), Timestamp (in seconds): the values are stored as Numbers in the graph database. They represent a date as the number of milliseconds or seconds between January 1st 1970 and the date to be encoded.
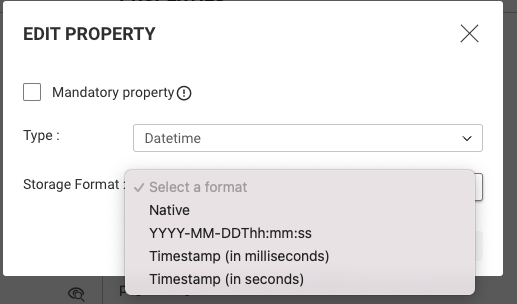
In case the Date-time is stored as Native type:
in Neo4j, there are 2 possible options:
Using a DateTime object: these objects contain an explicit time zone which is used.
Using a LocalDateTime object: these objects do not contain an explicit time zone,
no time zone conversion is applied to display them.
Memgraph only supports LocalDateTime, which does not contain an explicit time zone,
so no time zone conversion is applied.
Neptune only supports DateTime, so an explicit time zone is always used.
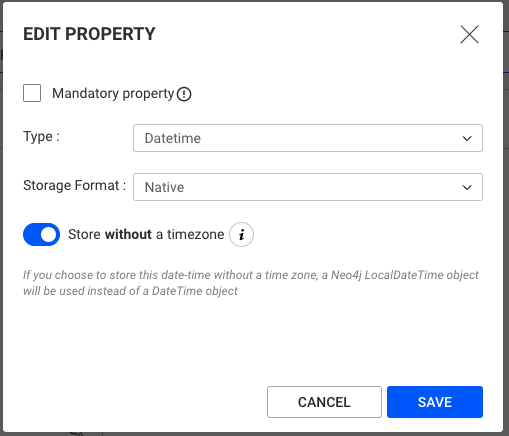
Once a property type has been set as Datetime, values for that property fall into 2 categories:
In the Workspace Property panel:
Anywhere a date value is displayed (including the Property panel):
YYYY-MM-DDThh:mm:ss regardless of their storage format.In the Workspace Filter panel:
When editing or creating a node/edge, the user picks the value of a Datetime property from a Date picker.
Setting a property type as Currency requires to select the currency symbol and the display format of values in Linkurious Enterprise:
[Symbol] #,###.##: Currency symbol is displayed first, comma is used as thousands separator and dot as decimal separator.
#.###,## [Symbol]: Currency symbol is displayed last, dot is used as thousands separator and comma as decimal separator.
# ###,## [Symbol]: Currency symbol is displayed last, space is used as thousands separator and comma as decimal separator.
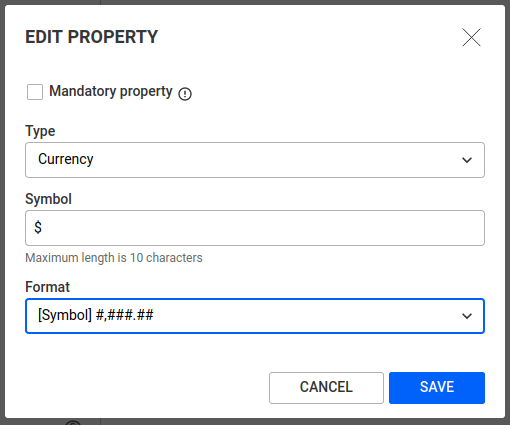
Once a property type has been set as Currency, values for that property fall into 2 categories:
In the Workspace Property panel, invalid values are displayed as string with a warning.
In the Workspace, displayed currency values are formatted according to their property type configuration.
In the Workspace Filter panel:
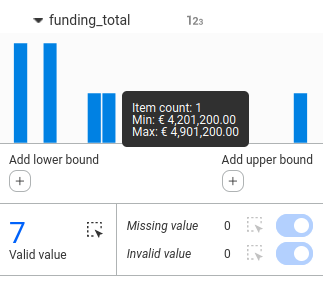
When editing or creating a node/edge, properties set as Currency can only accept a valid number.
Each property can be set as "Mandatory" by clicking the corresponding checkbox in the property type popup.
Consequences of making a property mandatory:
In the Workspace Property panel:
- The property key is always displayed.
- If the item at hand does not have this property, the property is displayed with a warning that the value is missing.
When editing or creating a node/edge, the value of a mandatory property cannot be empty.
When nodes have multiple categories, it is possible that a property can be given 2 different types. For example:
When such conflicts arise:
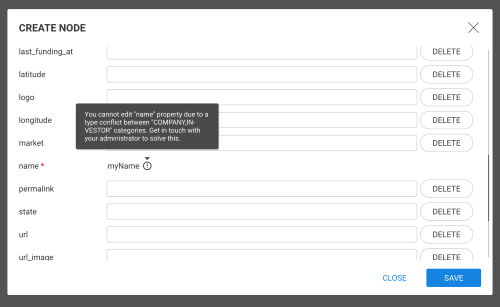
The schema allows to switch the search/visibility options for node-categories and edge-types by clicking on the "eye" icon next to the category/type name.
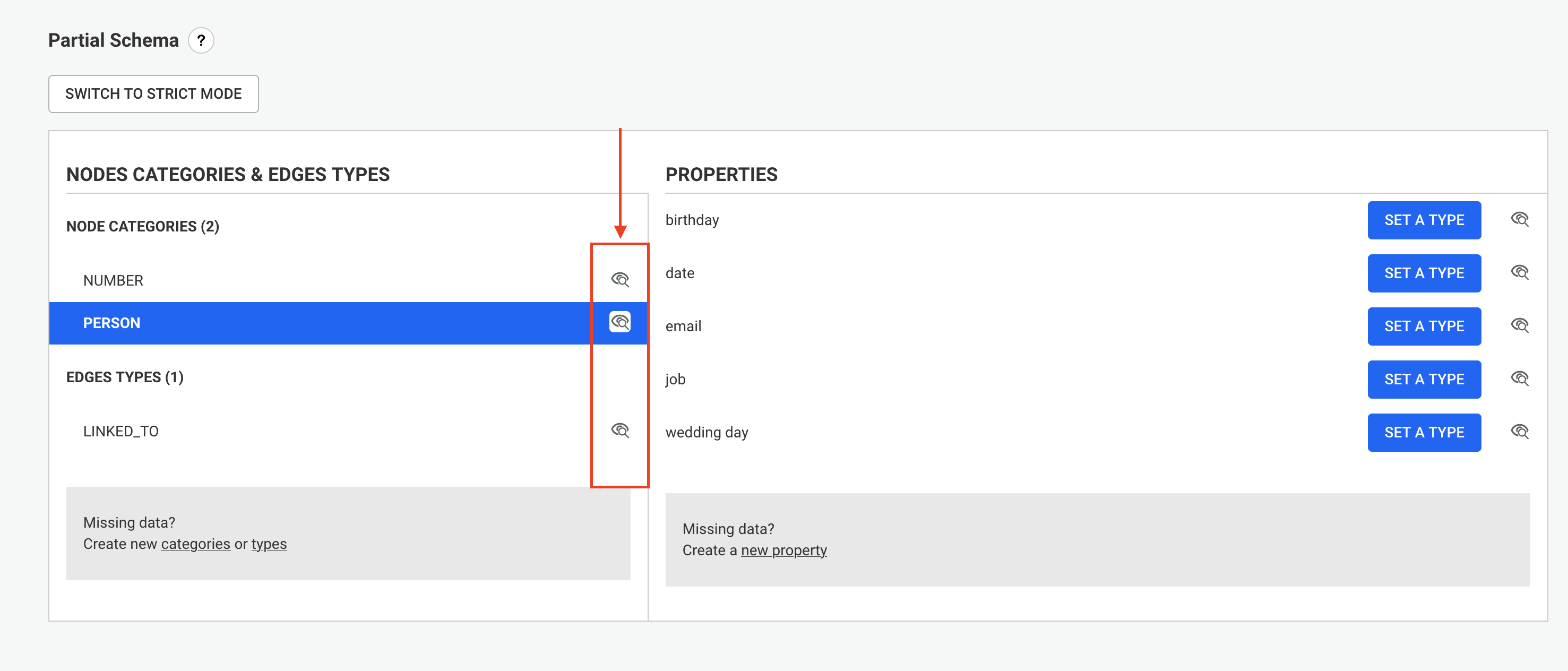
Node-categories and edge-types search option can be set to "Search & view", "View only" or "No access"
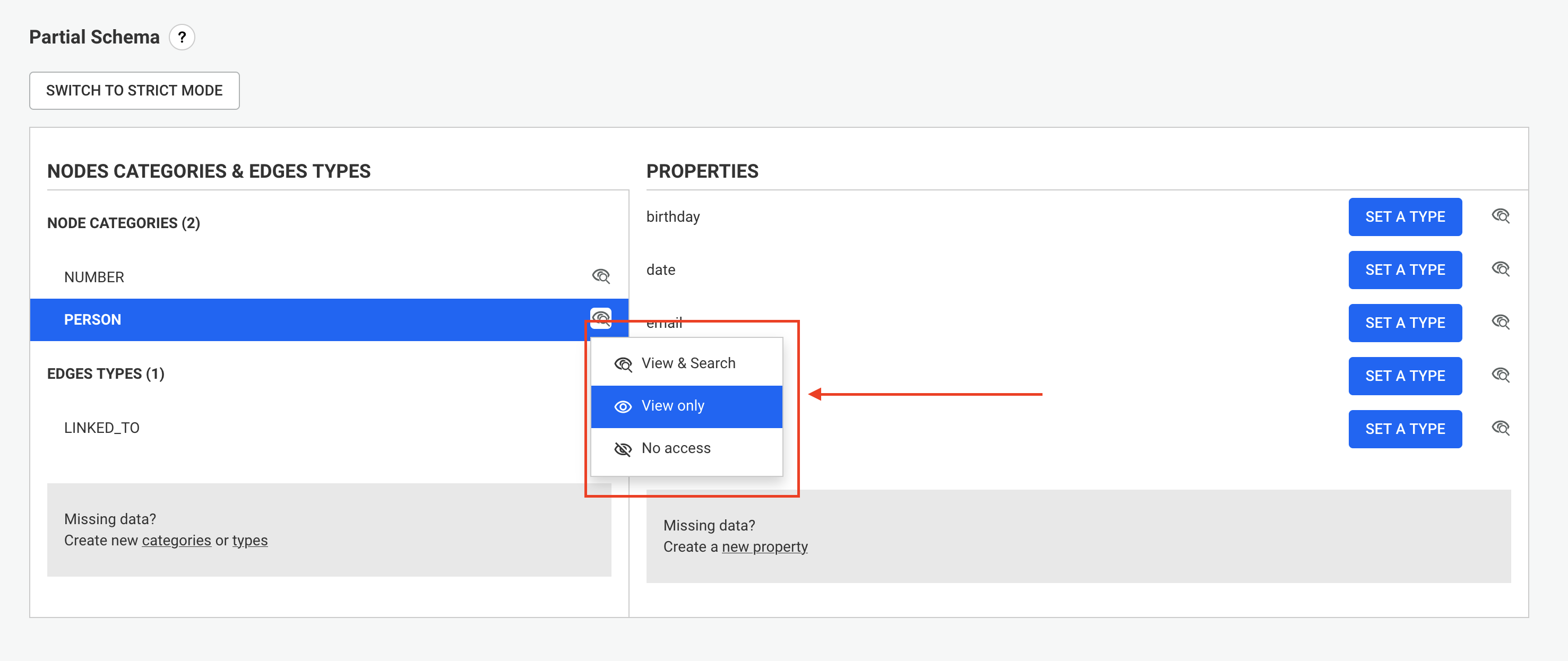
Switching the visibility off of a node-category (or an edge-type) can be useful when some data is stored in the database for technical reasons but is useless for the users.
Switching a node-category (or an edge-type) to "Only view" will make them not searchable, but they can still appear in the visualisation as result of a query or of a graph expansion.
Switching a node-category (or an edge-type) to "No access" is equivalent to setting it to the "No Access" access right for all existing and future User Groups. Nobody will have access to this category / type.
When switching a node-category (or an edge-type) to "No access", a warning is displayed, since it may be used in some existing visualizations, and may impact users.
Switching a property search options can be done by clicking on the "eye" icon next to the property name.
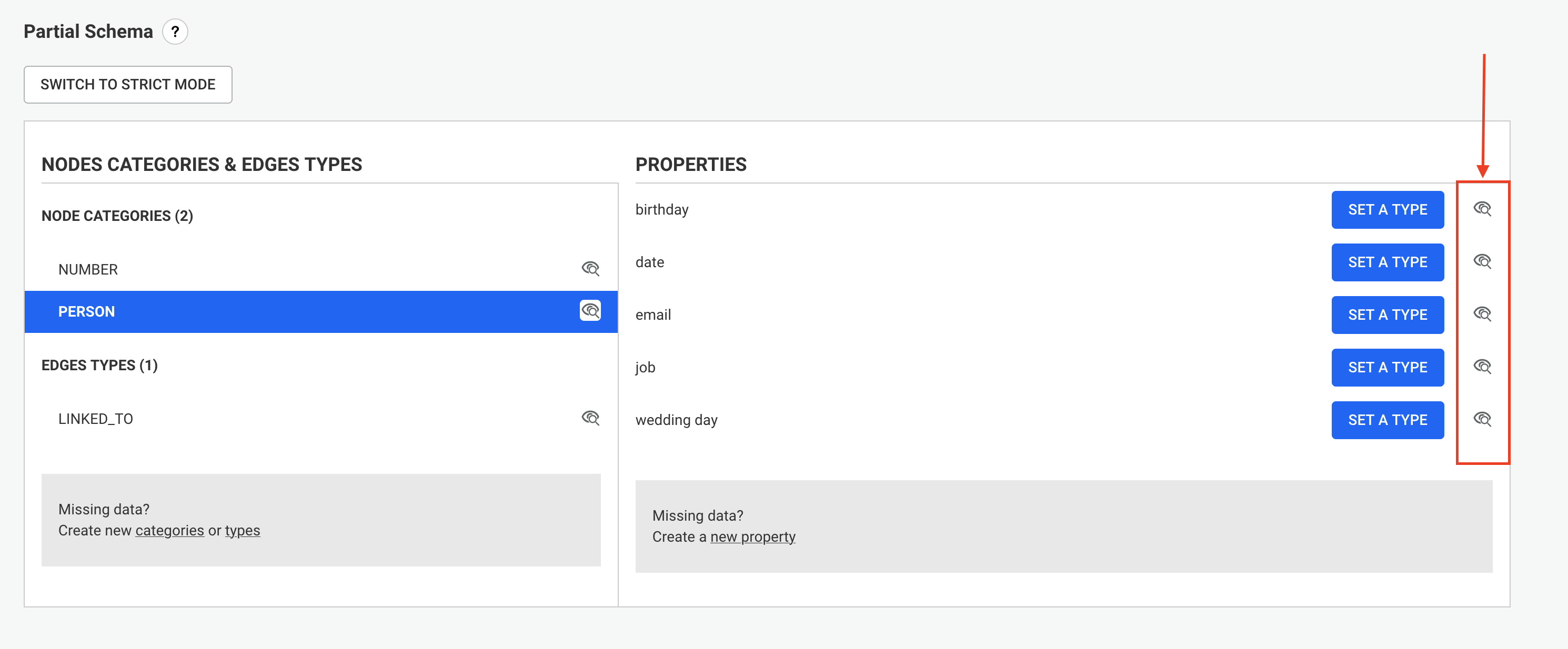
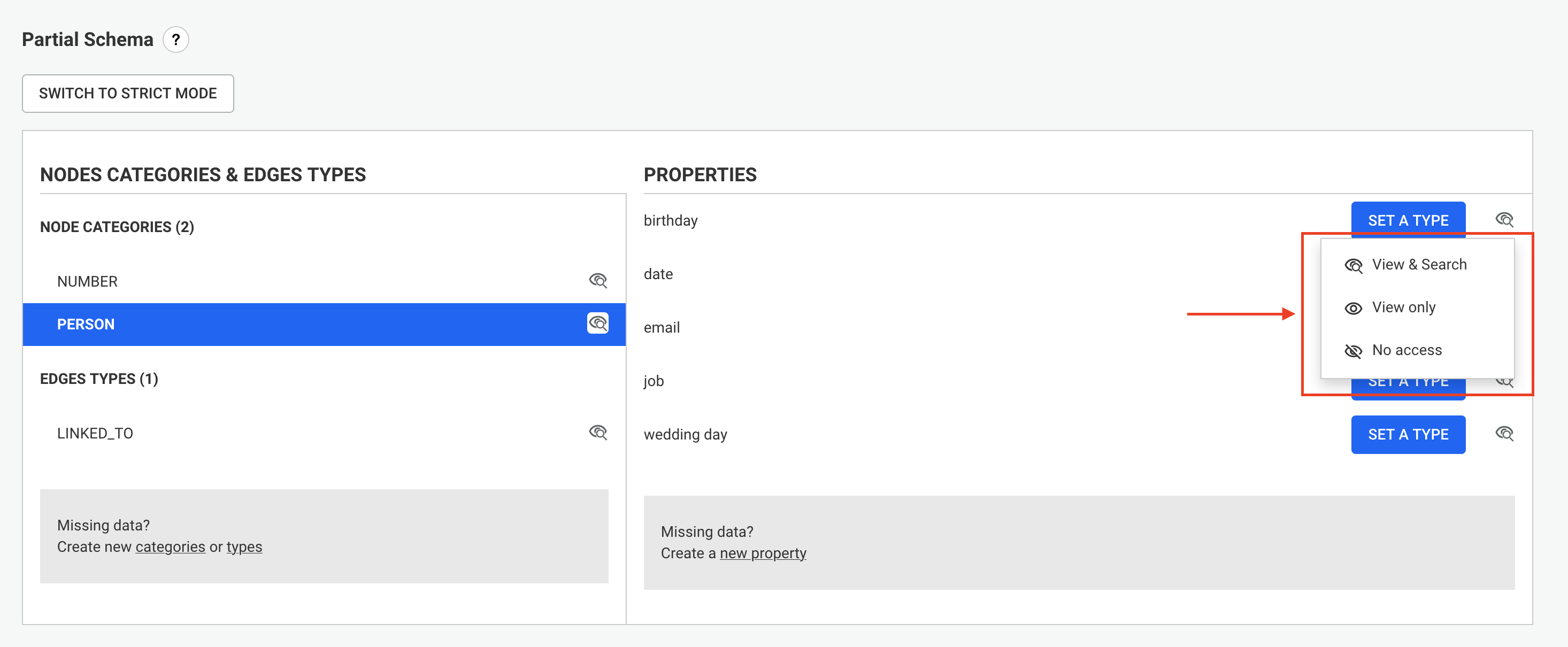
Properties can be hidden from all users by switching them to "No access". A "No access" property:
Properties can be only visible and not searchable by switching them to "Only view". A "Only view" property:
Contrary to the "partial mode", when in "strict mode", you cannot deviate from the data schema when creating or editing a node or an edge.
More specifically, since all properties are typed, you cannot enter a value that is inconsistent with the schema or add arbitrary properties to nodes and edges.
A property must be declared in the schema first, before being available to users.
The schema can be switched to "strict mode" by clicking on the "Switch to strict mode" button.

The "strict mode" requires to have types declared for all properties. As a consequence, when enabling "strict mode", all properties that do not have a type are switched to No access.
When switching to "strict mode", a warning is displayed with the list of properties that are being automatically switched to No access.
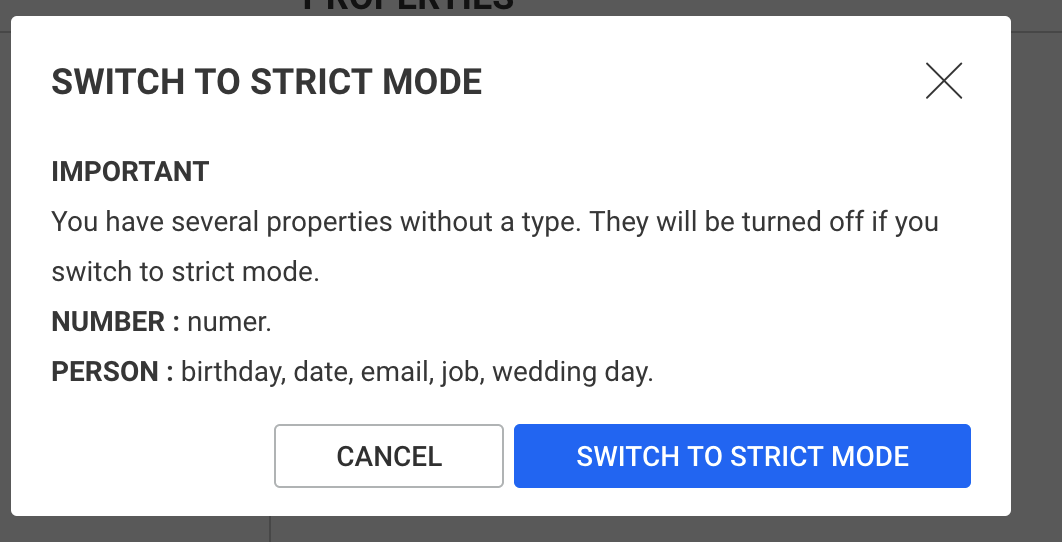
A schema in "strict mode" cannot evolve without an explicit action from the administrator. That means that any node-category, edge-type or property that would be detected after switching to "strict mode" would be added to the schema but be switched to No access by default.
A schema administrator can add new node-categories, edge-types or properties manually.
A schema in "strict mode" should be stable, so it is non-editable by default. To enable schema edition, the schema administrator needs to click on the corresponding toggle button.

Alerts is Linkurious Enterprise' response to the need behind automating pattern detection through a rule-based system. Imagine there's a pattern on a datasource that repeats itself multiple times. Instead of manually detecting each occurrence of the said pattern, users can delegate this to the system. With the use of alerts, Linkurious Enterprise is responsible for automatically detecting the pattern and consequently creating cases based on it.
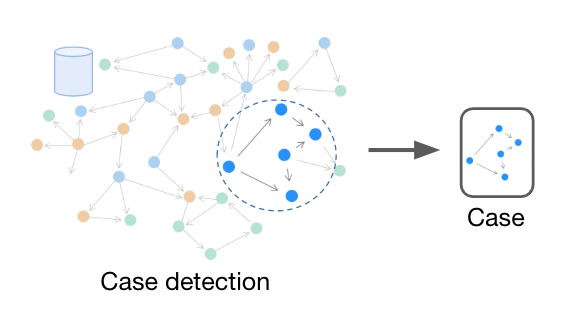 Automated detection of patterns in the graph database
Automated detection of patterns in the graph database
More information on how to set up and use alerts can be found in the user documentation.
The next section walks you through how to configure the feature.
Alerts are currently supported with the following graph vendors:
If you are using a different graph vendor, please get in touch.
Alerts can be configured and customised on the Global Configuration page that can be accessed under the Admin menu.
The following
enabled (default: true): This is the feature activation parameter. Its default value true will enable the feature while false will disable it completely.
maxMatchesLimit (default: 5000): This parameter sets the maximum number of matches an alert can return.
maxRuntimeLimit (default: 600000): This parameter sets the maximum execution time for an alert, in milliseconds.
alwaysRefreshCaseAttributes (default: false): This parameter determines whether the case attributes will be recomputed during every alert run or not. When set to false, only the cases with new matches will have their attributes recomputed. When set to true, recomputation for all cases will be forced.
enableDataPreprocessing (default: true): When this parameter is enabled, a new section called "Data preprocessing" will be enabled in the alert creation/edition window. This will allow users to use queries that write to the database in order to prepare data for the alert.
Example of alerts configuration:
alerts: {
"enabled": true,
"maxMatchesLimit": 5000,
"maxRuntimeLimit": 600000,
"enableDataPreprocessing": true
}
Entity Resolution in Linkurious Enterprise helps you detect duplicate records and non-obvious relationships in your graph data. It leverages Senzing's engine to find records that likely represent the same real-world person or organization, even when there are small variations between them.
ℹ️ Entity Resolution is currently only available in Linkurious Enterprise v4.2.0 and later. If you would like to get a license to test it, please contact us and follow the instructions for Installation and Configuration.
Whether you like the feature or think it could be improved, please don't hesitate to send us your feedback, it is highly valued and will help us enhance the feature further.
Without Entity Resolution, duplicate records remain disconnected, which may hide crucial relationships or lead to misleading results in your investigations. This feature helps:
Entity Resolution is based on Senzing's engine and integrates seamlessly into Linkurious Enterprise's visualization and investigation workflows.
Once activated and configured, Entity Resolution enhances your graph by:
The following pages will guide you through all aspects of the feature:
This section describes the technical requirements to install and run Entity Resolution in Linkurious Enterprise.
Entity Resolution is a separate service that runs independently of the Linkurious Enterprise server. The Entity Resolution server is powered by Senzing and communicates with the Linkurious Enterprise server through a configured HTTP endpoint.
To use Entity Resolution:
⚠️ The Entity Resolution module can only be used on a single datasource at a time.
Before using Entity Resolution, make sure your environment meets the following requirements:
If any of the above conditions are not met, Entity Resolution will not be available in the UI. Users will be shown a contextual explanation (e.g., unsupported vendor, read-only mode, or missing configuration).
Example of "unsupported data-source vendor" message.
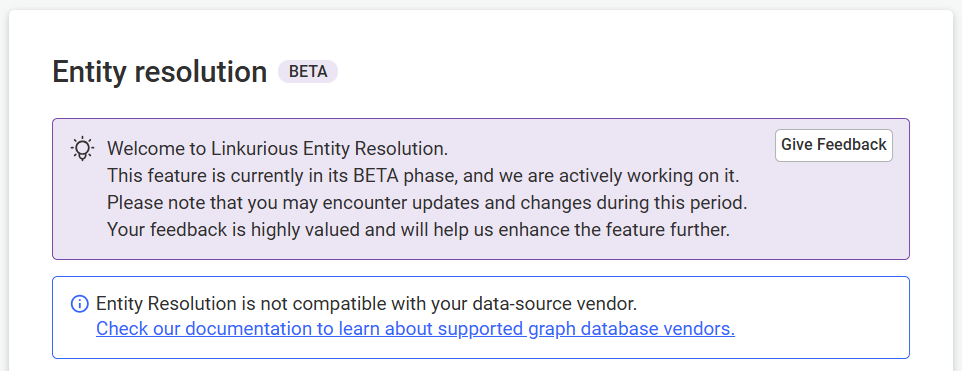
⚠️ Even if you are testing the module with very few data, the system needs to load the Entity Resolution model in RAM, so it's important to respect the minimum requirements to avoid any unexpected crash.
Minimum requirements:
For more details, please refer to Senzing's technical documentation:
This section is for administrators setting up Entity Resolution for the first time.
For configuring the feature once installed, see how to configure Entity Resolution.
When installing the Entity Resolution service, please refer to this table for compatibility between the Linkurious Enterprise server and the Entity Resolution server:
| Entity Resolution server version | Compatible Linkurious Enterprise versions |
|---|---|
| v1.0.0 (not recommended) | v4.2.0 |
| v1.1.0+ | v4.2.1+ |
When updating from Linkurious Enterprise from v4.2.0 to v4.2.1, you must clear Entity Resolution results.
The following steps will help you run Entity Resolution using the docker command line.
If you are working with Kubernetes, you can start quickly with our public helm chart.
The Entity Resolution server can only be download via the Linkurious private Docker repository. Follow the same instructions to deploy Linkurious Enterprise.
ℹ️ You will need to replace the
linkurious-enterprise:4.3.10image name withlinkurious-entity-resolution:1.2.2.
The Entity Resolution server requires access to an existing MySQL or a MSSQL database.
⚠️ Despite MySQL is supported, MariaDB is not and is known for having compatibility issues.
ℹ️ For the first run, you will need to create a specific database for the entity resolution service (called
my-database-namein the examples below).
To connect to the database, you need to set environment variables
when starting the linkurious-entity-resolution docker container.
For simplicity, you can create a file called linkurious-er.env (used in below commands) to store the relevant environmental variables.
Example configuration for MySQL:
SENZING_DATABASE_VENDOR=mysql
SENZING_DATABASE_HOST=127.0.0.1
SENZING_DATABASE_PORT=3306
SENZING_DATABASE_NAME=my-database-name
SENZING_DATABASE_USER=my-database-user
SENZING_DATABASE_PASSWORD=my-database-password
SENZING_DATABASE_TRUST_CERTIFICATE is optional, and only supported on MSSQL.
When set to true, connecting to the database using a self-signed certificate is allowed.
It is recommended to set this variable to false in production.
Example configuration for MSSQL:
SENZING_DATABASE_VENDOR=mssql
SENZING_DATABASE_HOST=127.0.0.1
SENZING_DATABASE_PORT=1433
SENZING_DATABASE_NAME=my-database-name
SENZING_DATABASE_USER=my-database-user
SENZING_DATABASE_PASSWORD=my-database-password
SENZING_DATABASE_TRUST_CERTIFICATE=true
docker run -p 8080:8080 --env-file ./linkurious-er.env MY_PRIVATE_REGISTRY/linkurious/linkurious-entity-resolution:1.2.2
Visit http://localhost:8080/status to confirm the service is running (it will show the service uptime in seconds):
{"status":"API is up","uptime":10}
Go to Global configuration > Entity Resolution to enable Entity resolution in Linkurious Enterprise and set the service URL for your local setup.
{
"enabled": true,
"url": "http://localhost:8080"
}
For more information, see how to configure Entity Resolution.
In production, it is strongly recommended to enable authentication and use private networking.
You can enable authentication to make sure that API calls to the Entity Resolution service are only accepted if the call contains an API Key.
To enable authentication:
linkurious-entity-resolution docker container with a
LINKURIOUS_ENTITY_RESOLUTION_API_KEY environment variable (the key must be at least 32
characters long).{
"enabled": true,
"url": "http://my-linkurious-entity-resolution-server.svc:8080",
"serviceApiKey": "your api key here"
}
The docker image exposes the port 8080 for HTTP connections, but you can use another port via
docker mapping.
Please visit the docker documentation
to learn how publish the ports of a container.
In production, we strongly advise you to use a private network between Linkurious Enterprise and the Entity Resolution service.
The Entity Resolution container will deploy a Java based Web Server and the Senzing library. Standard Java configurations can be passed via environmental variables for more advanced deployments.
The Java Web Server can be monitored using Prometheus, which is an open source monitoring tool, by adding the following environment variable to the existing list:
PROMETHEUS_METRICS_ENABLED=true
When metrics are enabled, the docker image also exposes the port 9400 for HTTP connections, but you can use another port via
docker mapping. The API endpoint on /metrics that can be scrapped by Prometheus (http://localhost:9400/metrics).
The system is not designed to scale horizontally with automatic deployments of multiple replicas (docker scale option).
In case you have an high volume of data and experience some performance issues, please get in touch.
Once Entity Resolution is installed, you must then configure the server settings in the global configuration.
Then:
enabled is true by default)⚠️ You cannot save your configuration and use any part of the Entity Resolution feature (mapping, running, etc.) unless a valid Entity Resolution server URL is configured.

You can enable email notifications for Entity Resolution-related events, such as:
✉️ Email notifications are disabled by default and must be explicitly enabled in the global configuration. Please ensure that your email notifications are correctly configured beforehand.
Once enabled, Entity Resolution is accessible from the Admin & Settings wheel menu.
⚠️Entity Resolution can only be used on one data-source at a time.

| Role | Access to Entity Resolution features |
|---|---|
| Admins | ✅ Full access (config, mapping, running, license) |
| Source Managers | ✅ Access to mapping, running, explanations |
| End-users | ✅ View results in the graph and request explanations |
| Custom groups | ❌ Not supported at this stage |
ℹ️ Note: All users can view Entity Resolution results in the graph, but only Admins and Source Managers can configure or run Entity Resolution.
Possible actions based on your role are detailed in the following table:
| Action | Admin | Source Manager | End-User |
|---|---|---|---|
| Configure the Entity Resolution server | ✅ | ❌ | ❌ |
| Upload & manage the Entity Resolution license | ✅ | ❌ | ❌ |
| Create/Edit/Delete Entity Resolution mappings | ✅ | ✅ | ❌ |
| Run or stop the Entity Resolution process | ✅ | ✅ | ❌ |
| Clear Entity Resolution results | ✅ | ✅ | ❌ |
| View Entity Resolution results in visualizations | ✅ | ✅ | ✅ |
| Ask "WHY?" or "WHY NOT?" in visualizations | ✅ | ✅ | ✅ |
| Modify Entity Resolution nodes/categories/edges/schema | ❌ (read-only) | ❌ (read-only) | ❌ (read-only) |
Mapping is a required step before running any Entity Resolution process. A mapping defines how the properties in your dataset should be compared by the Entity Resolution engine to identify potential duplicates.
ℹ️ Note: Only Admins and Source Managers can create, view, edit, or delete mappings.
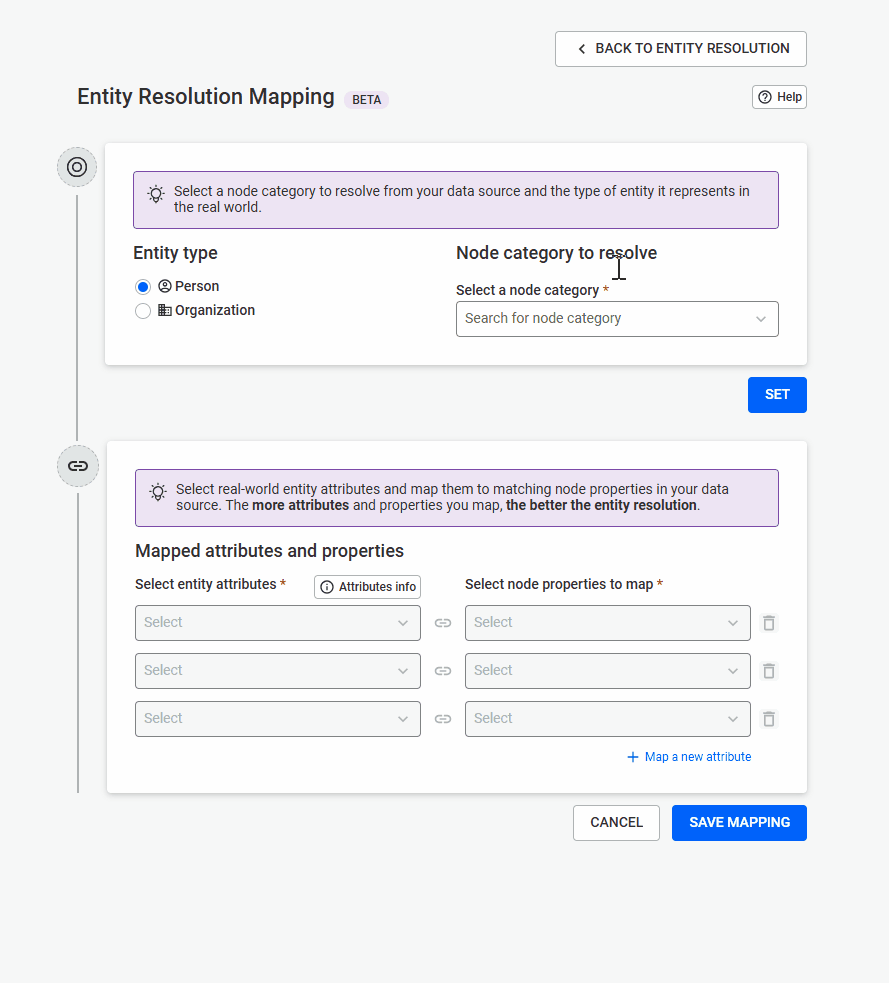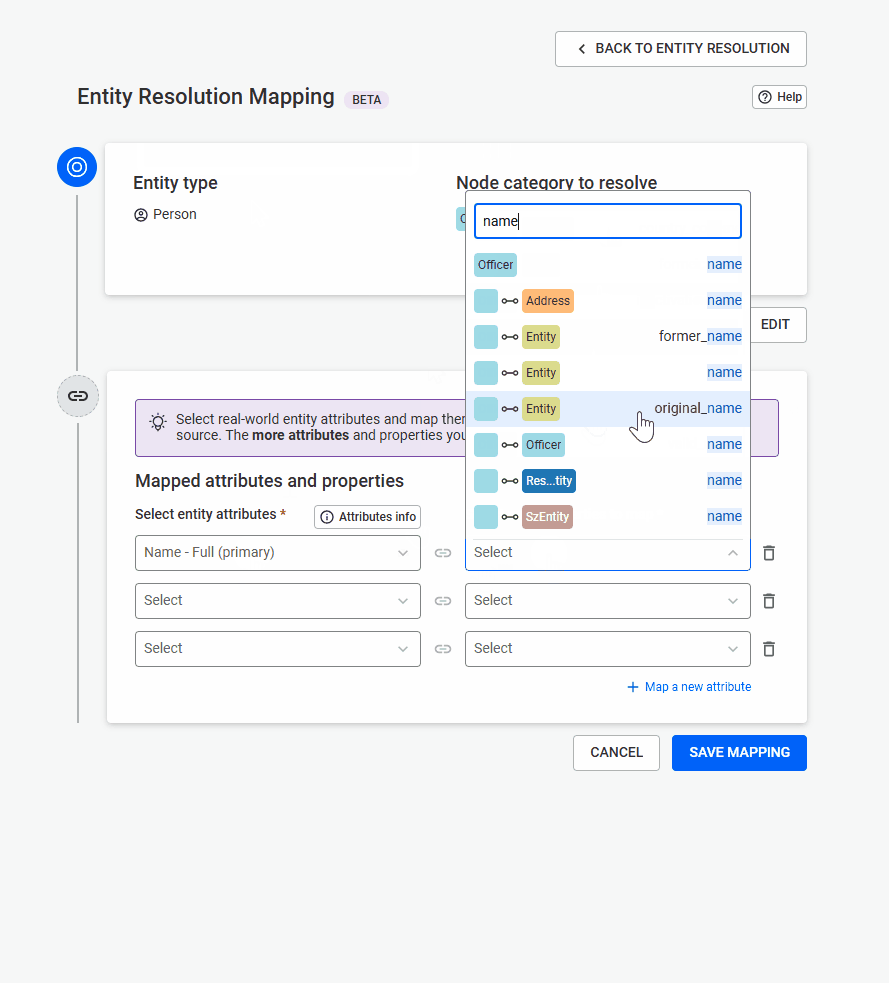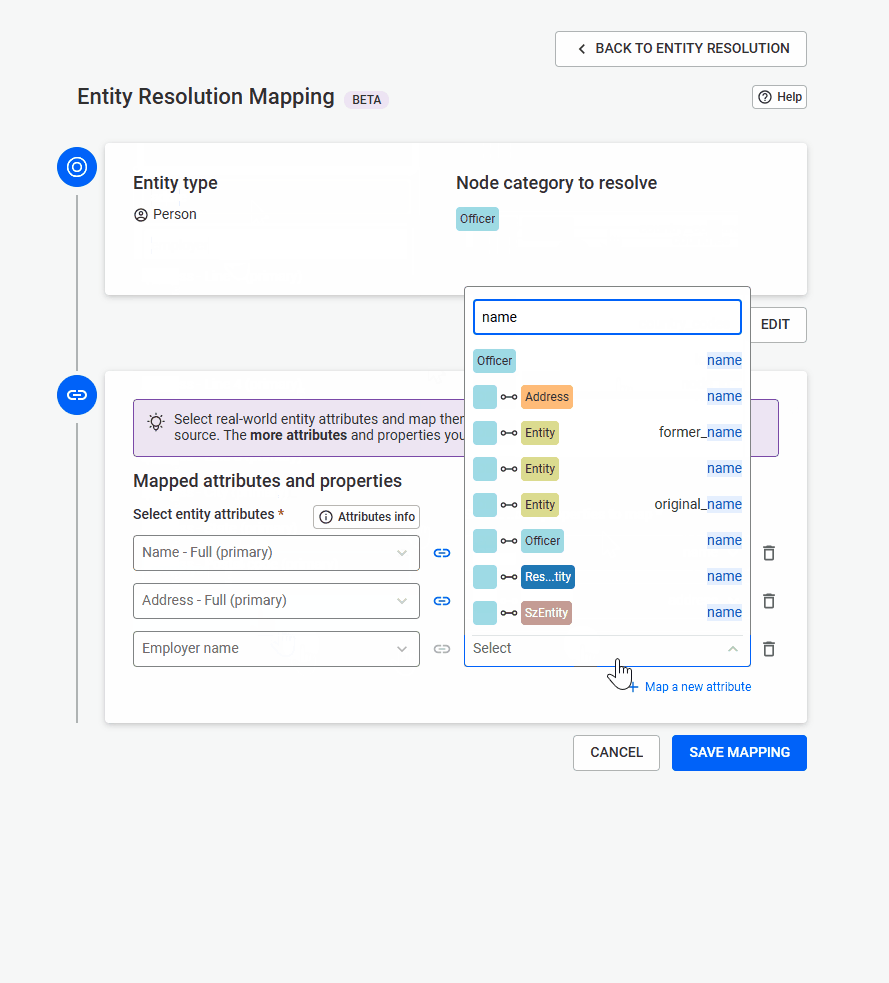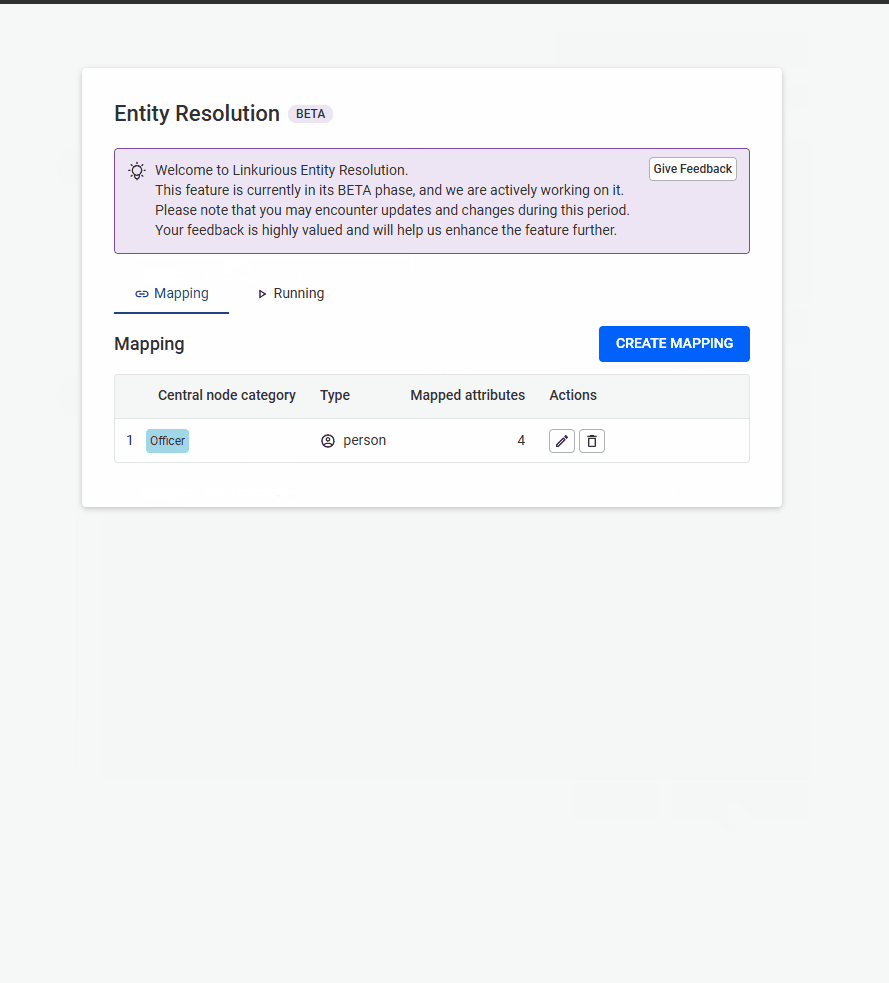
In case mappings already exist, they will be listed in this tab. See Viewing Saved Mappings section.
ℹ️ Note: If you see that Entity Resolution is unavailable, please refer to the Troubleshooting section to understand why.
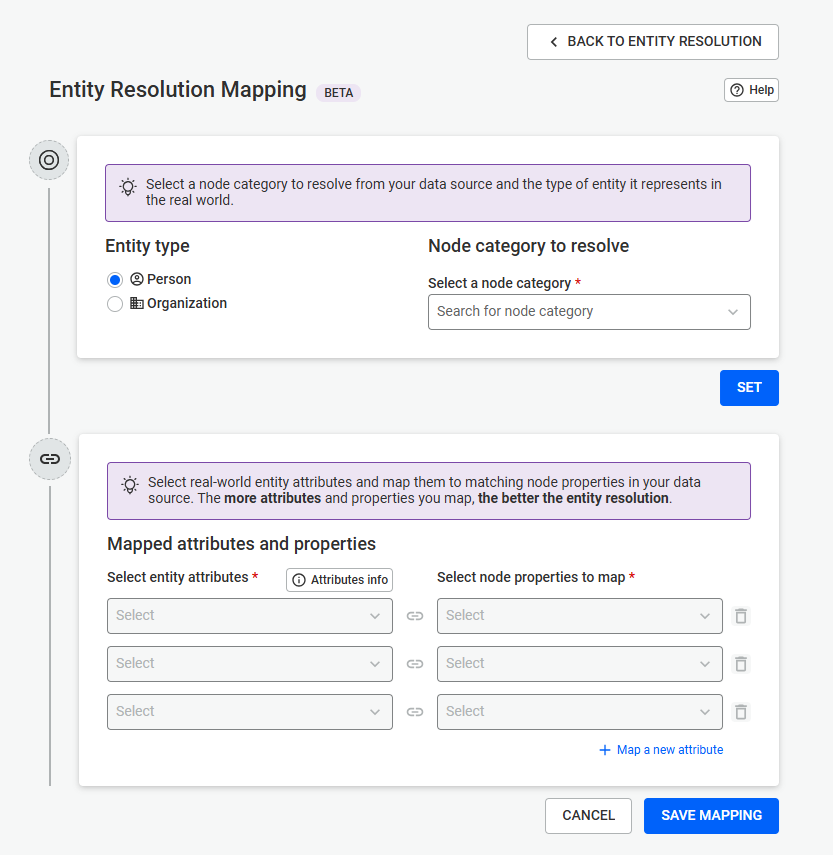
PERSON or ORGANIZATIONPerson, Company)ResolvedPersonEntity, are excludedOnce both values are selected, click SET to unlock Step 2.
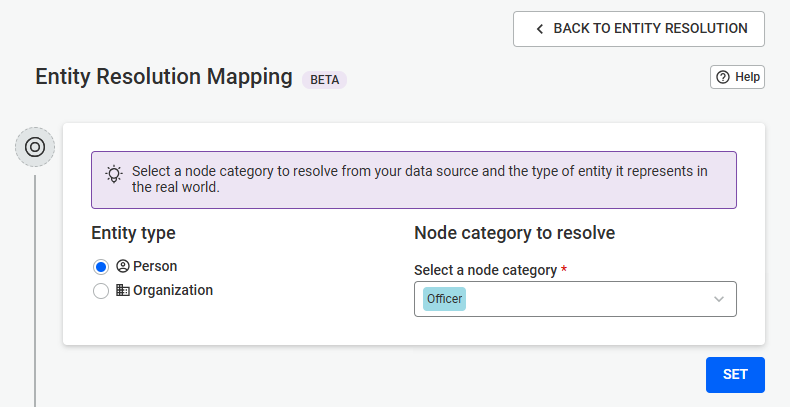
⬅️ On the left: Choose Attributes required by Entity Resolution (e.g., NAME, ADDRESS, DOB)
➡️ On the right: Select the corresponding Property from your graph schema
🔁 Repeat this on next lines to map more attributes, and clicking Map a new attribute to add more lines.
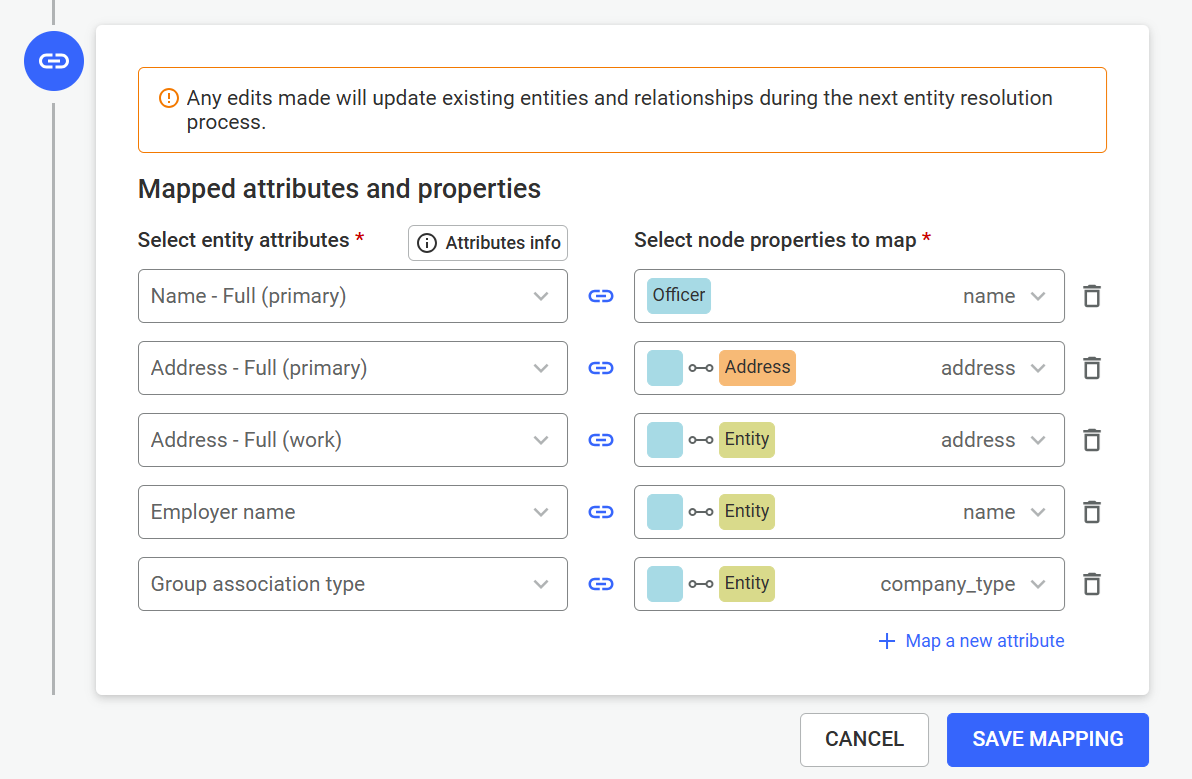
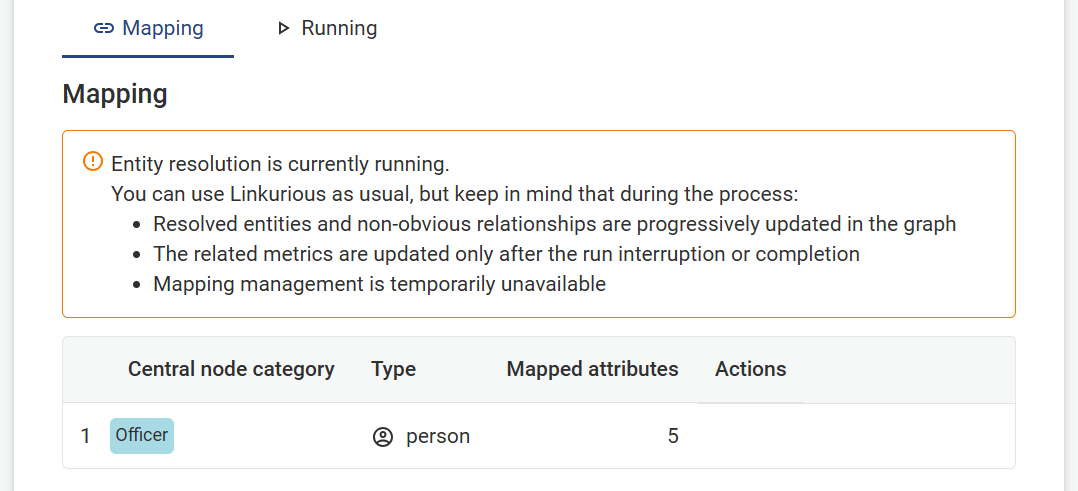
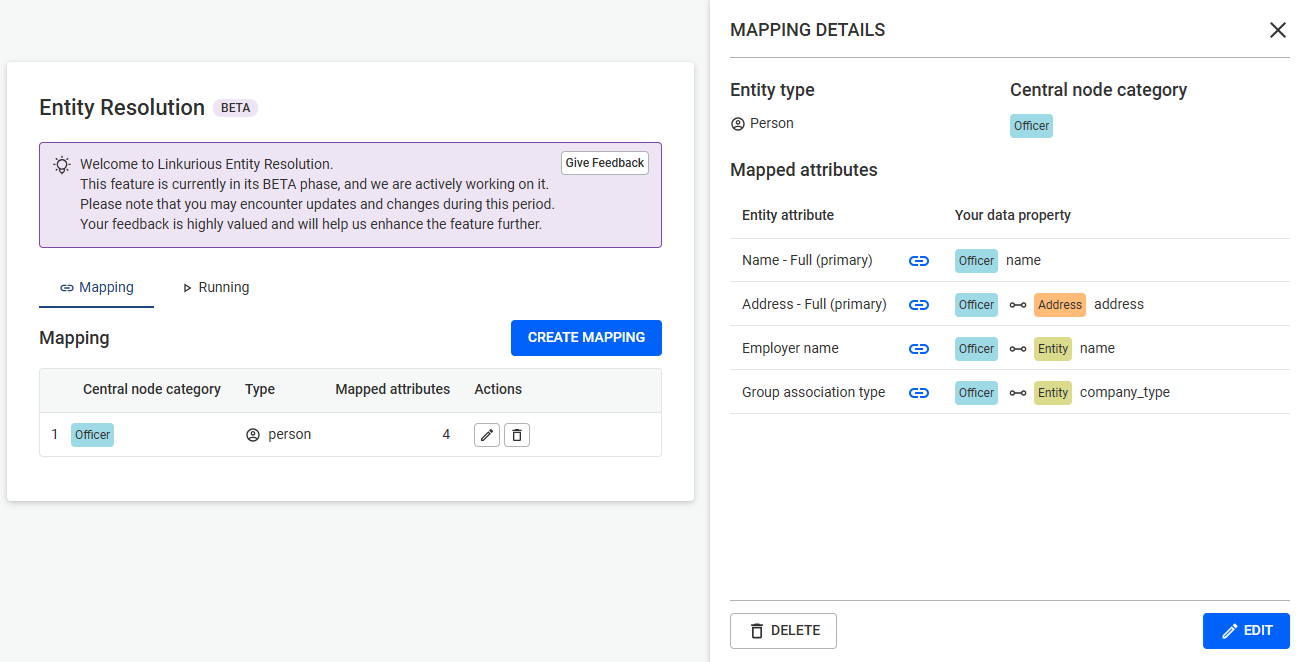
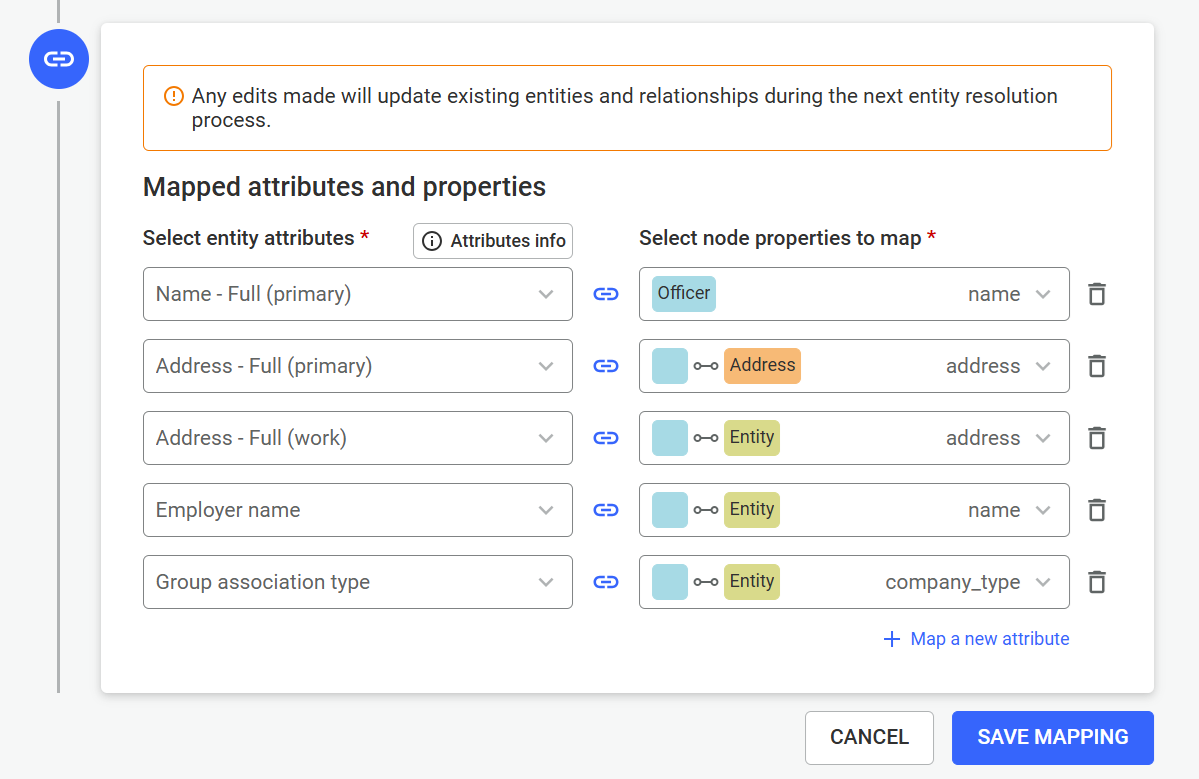
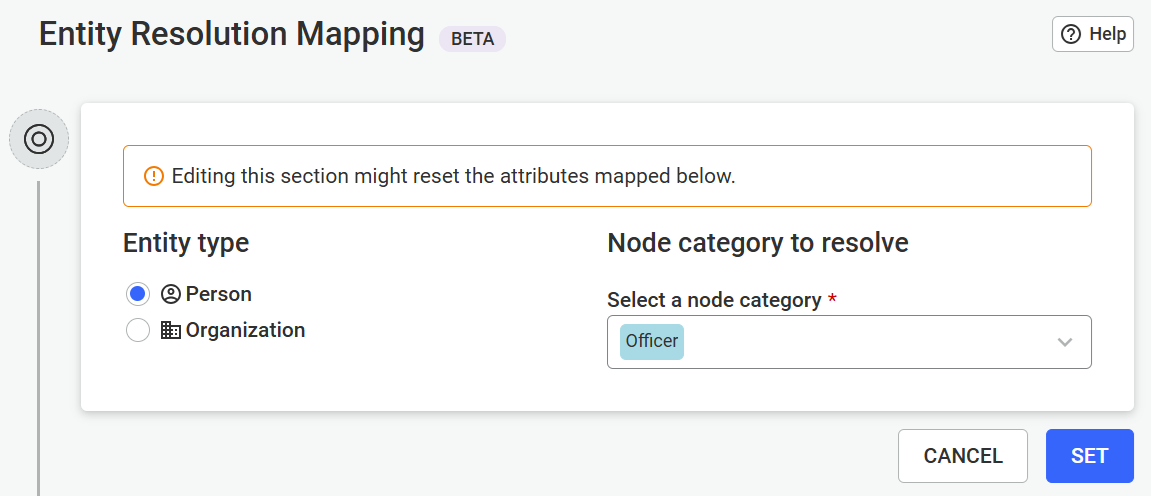
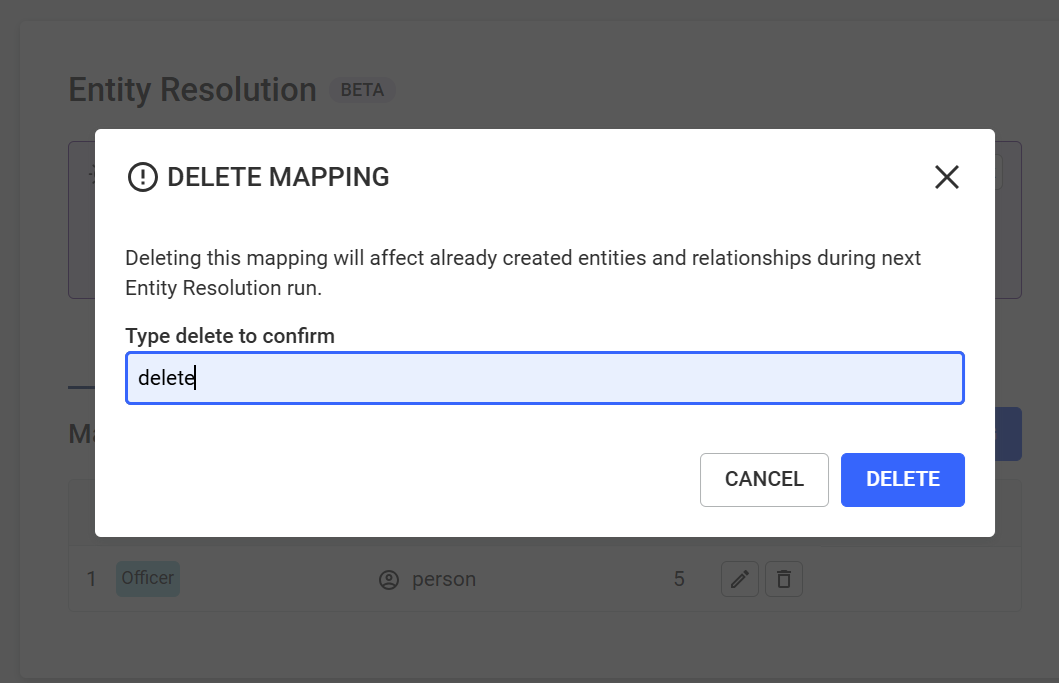
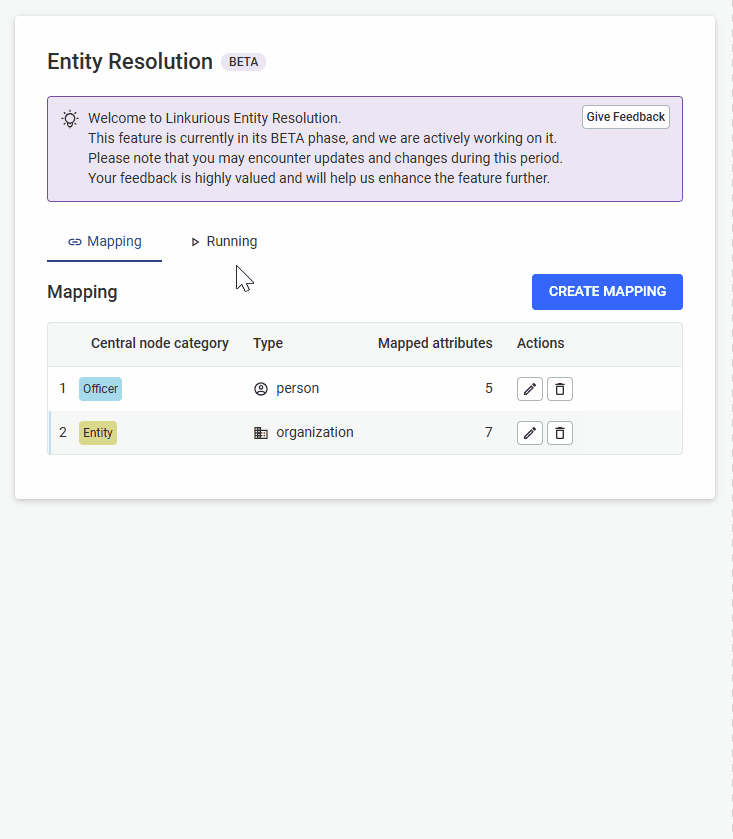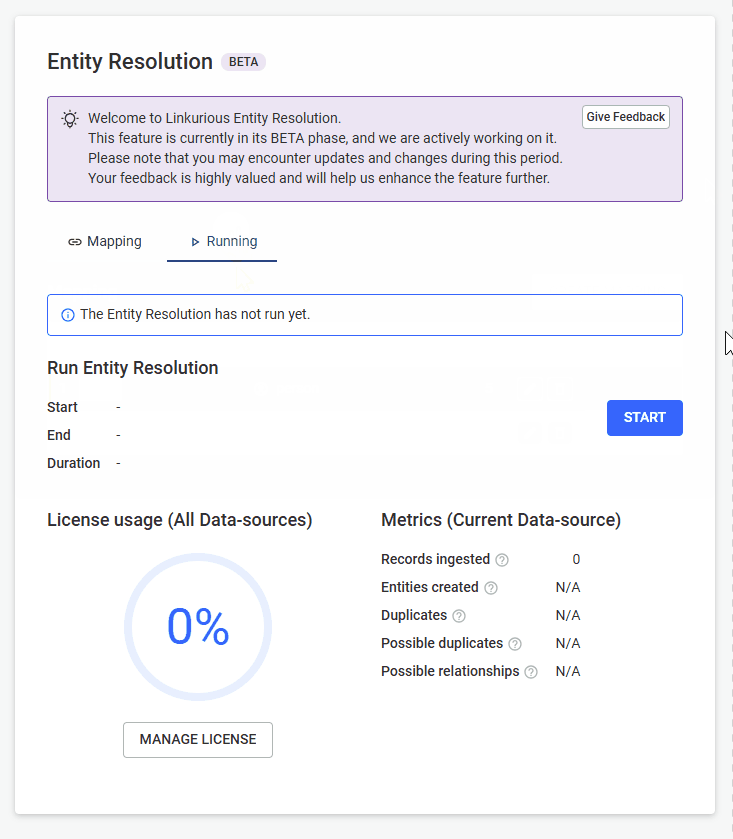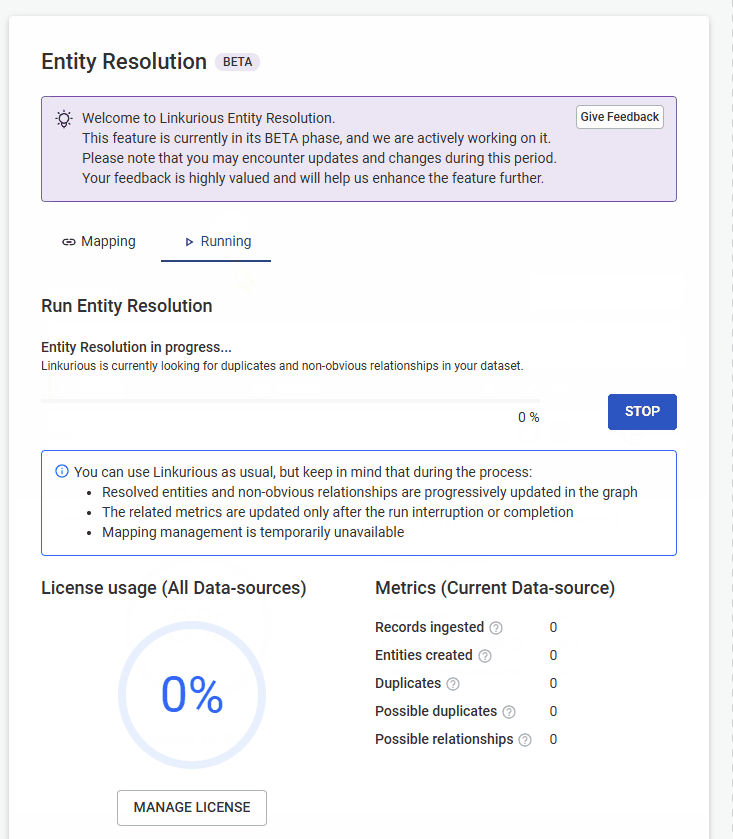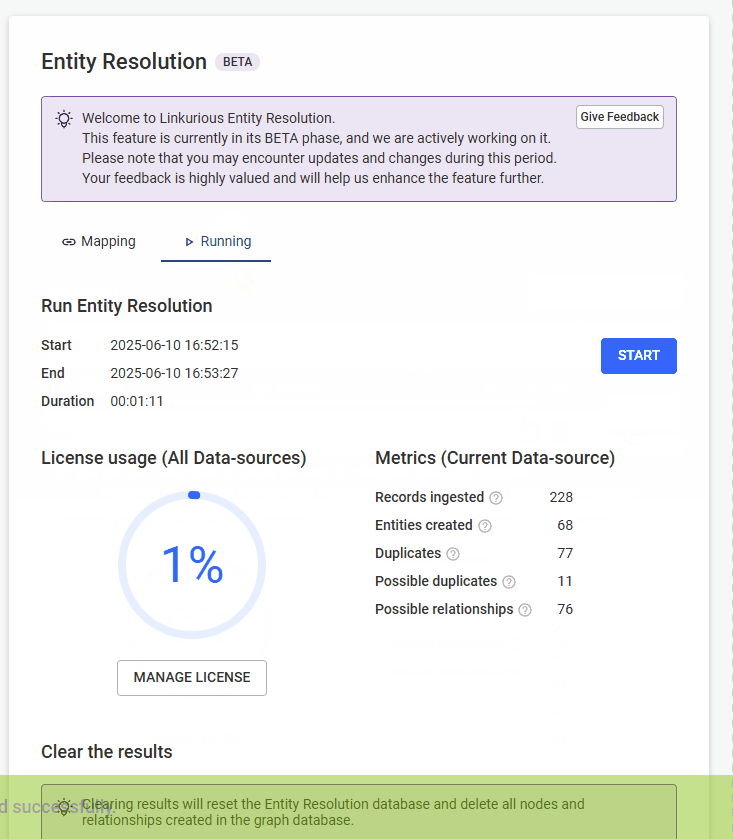
Once at least one mapping is configured, Admins and Source Managers can launch the Entity Resolution process from the Running tab.
This process scans your dataset to identify and group duplicate or related records based on the mappings defined.
From the Entity Resolution menu, click on the Running tab to manage the Entity Resolution process and monitor results.
From there, you are able to:
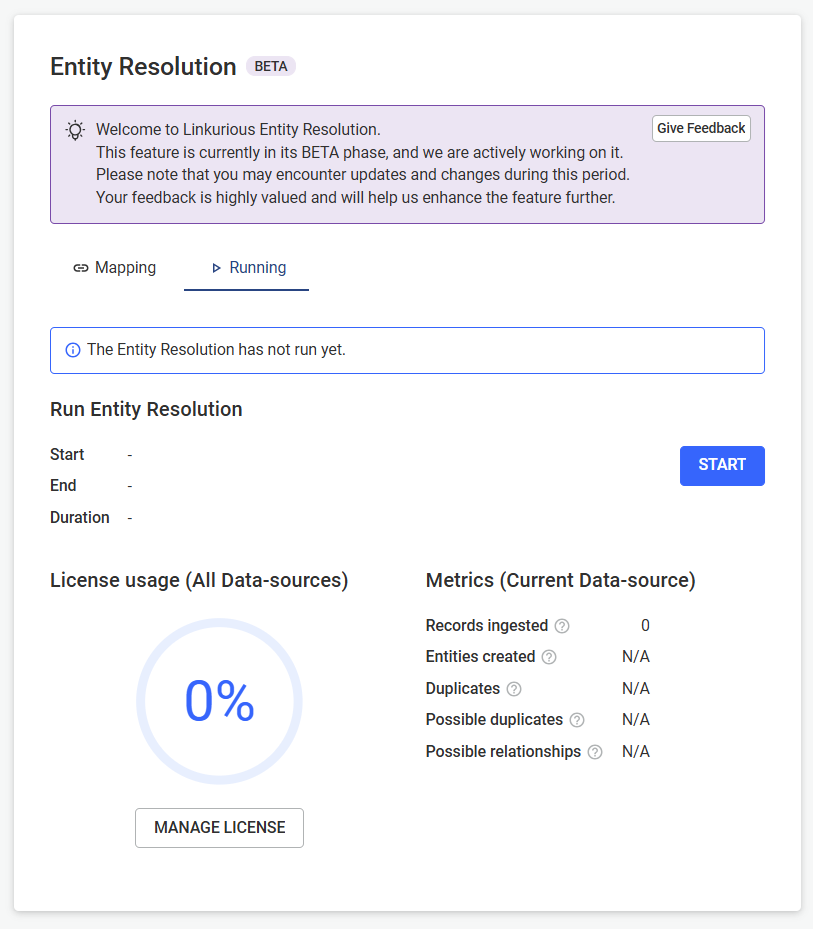
Click the Run button to begin the resolution process.
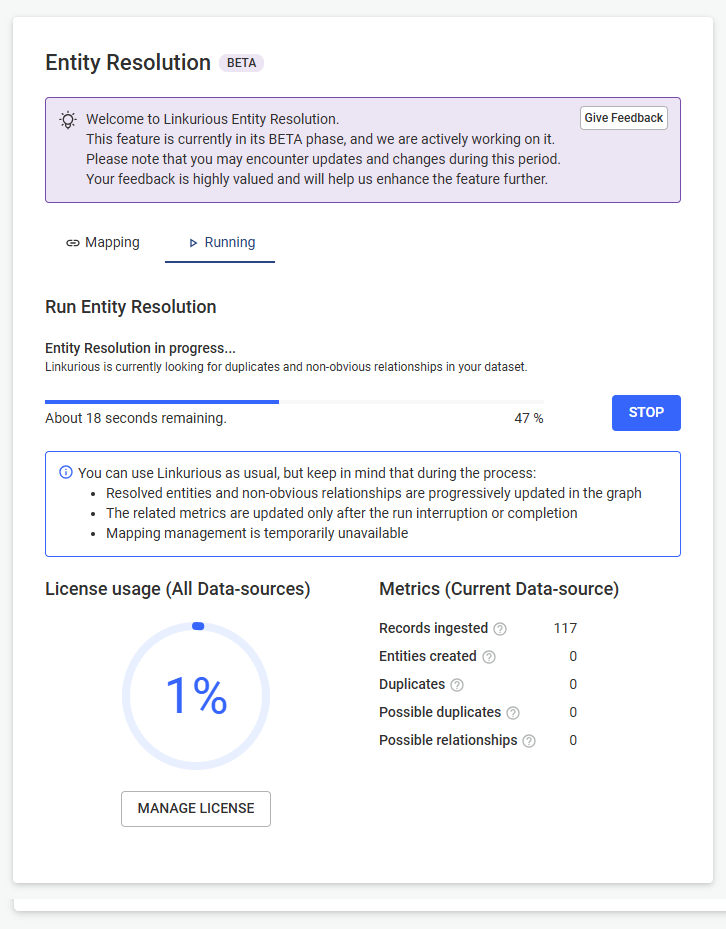
ℹ️ The Entity Resolution process works incrementally, like data-source indexing. This means that :
- on the first run, all records from node categories listed in the mappings will be ingested and resolved.
- on the next run (or resume after a stop), only records that are new to the Entity Resolution engine since the last run will be ingested and resolved (i.e., new or modified nodes).
At any time while Entity Resolution is running, click the Stop button to halt the process.
ℹ️ Stopping may take some time as the process is resolving records by batches, and waits for a batch to be resolved before completely stopping.
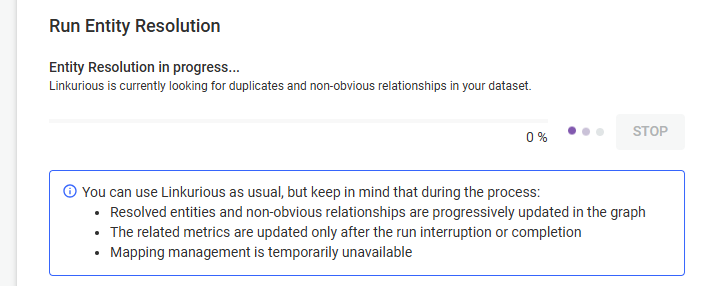
If the process is stopped manually or interrupted due to an error, click Resume to restart it. The process will resume from where it left off.
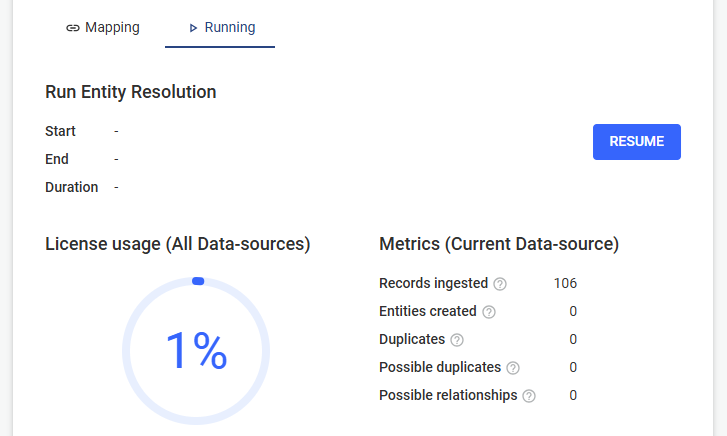
When the process completes successfully:
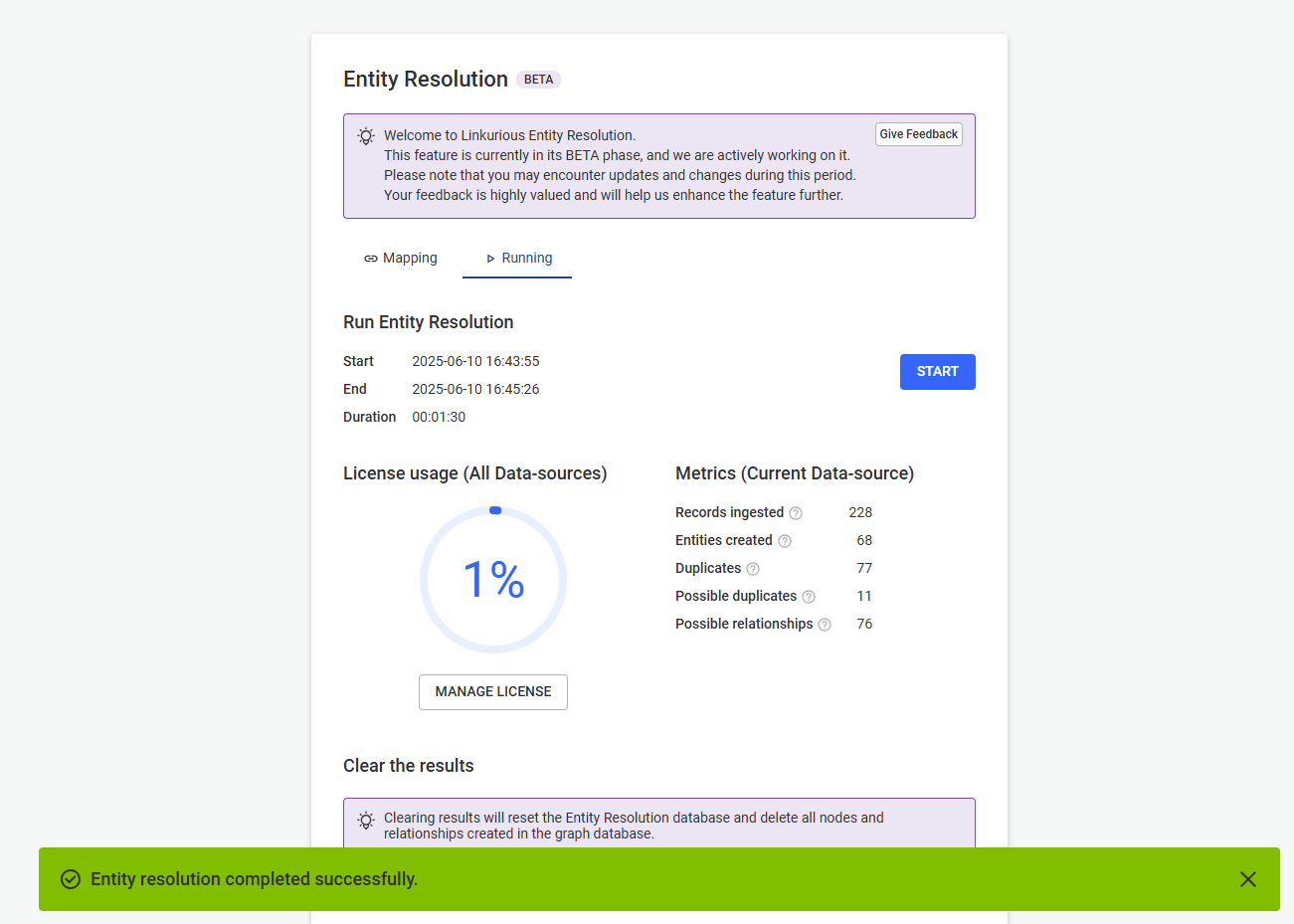
If the Entity Resolution process encounters an error:
You can resume the process once the problem has been fixed.
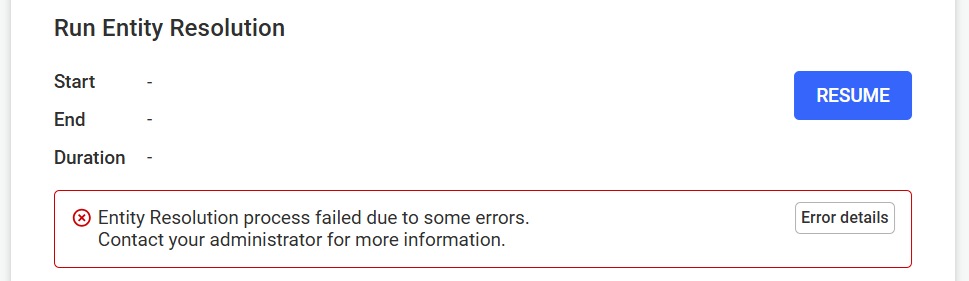

After the first successful run, key metrics become visible in the Running tab. These include:
YYYY-MM-DD or hh:mm:ss)hh:mm:ss)ℹ️Admin users can use the Manage License button to access more details about license consumption.
POSSIBLY_SAME relationship.POSSIBLY_RELATED relationship.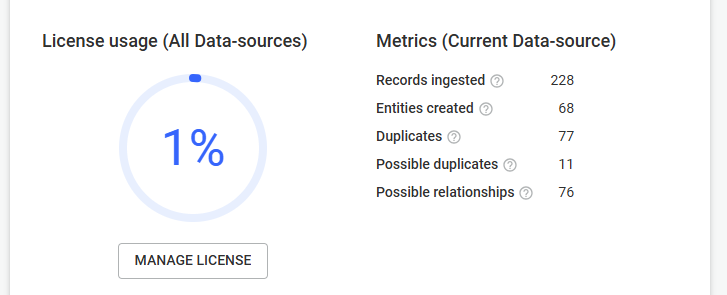
You may need to clear results during testing or after editing mappings.
ℹ️This will remove all nodes and relationships created by Entity Resolution from your dataset, and reset your license credits to start over.
Click the Clear results button and confirm your action to clean your dataset from Entity Resolution results.
ℹ️ The process may take some time depending on the number of resolved entities created by Entity Resolution.
⚠️ If you cancel the confirmation popup, no clearance is performed.
Upon success:
![]()
![]()
Once the Entity Resolution process has completed successfully, the graph is enriched with new nodes and relationships representing resolved entities and their connexion to original records.
Users who have access to visualizations of data-sources where Entity Resolution has been performed can explore these results directly in visualizations, and ask for Explanations about records and entities linkage.

As soon as ER finishes, your graph will contain:
ResolvedPersonEntityResolvedOrganizationEntityThese represent deduplicated entities created by the Entity Resolution process, based on your initial records and mappings. They are automatically named by the Entity Resolution process, according to the most relevant name found based on records matching.
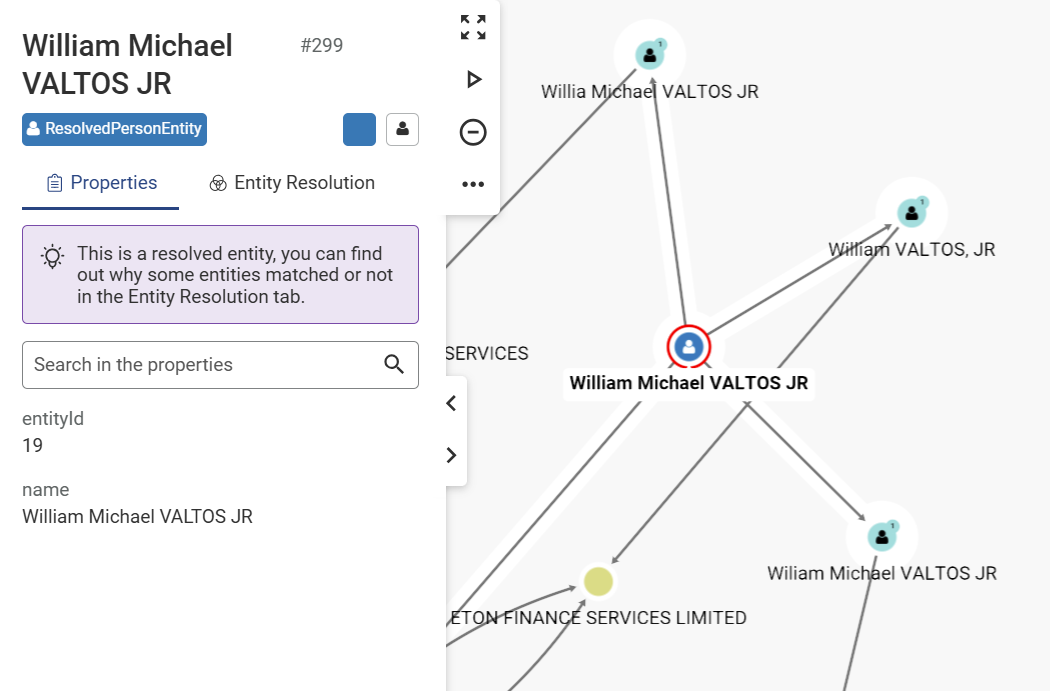
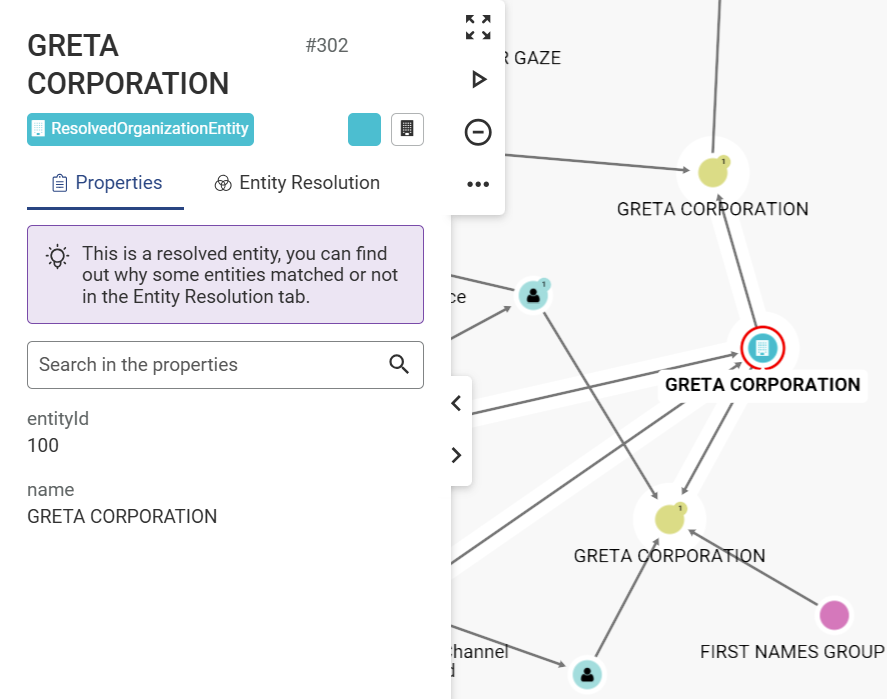
They don't contain all properties from the records they are linked to, but you can inspect all records resolved by this entity manually by clicking on the Entity Resolution tab.
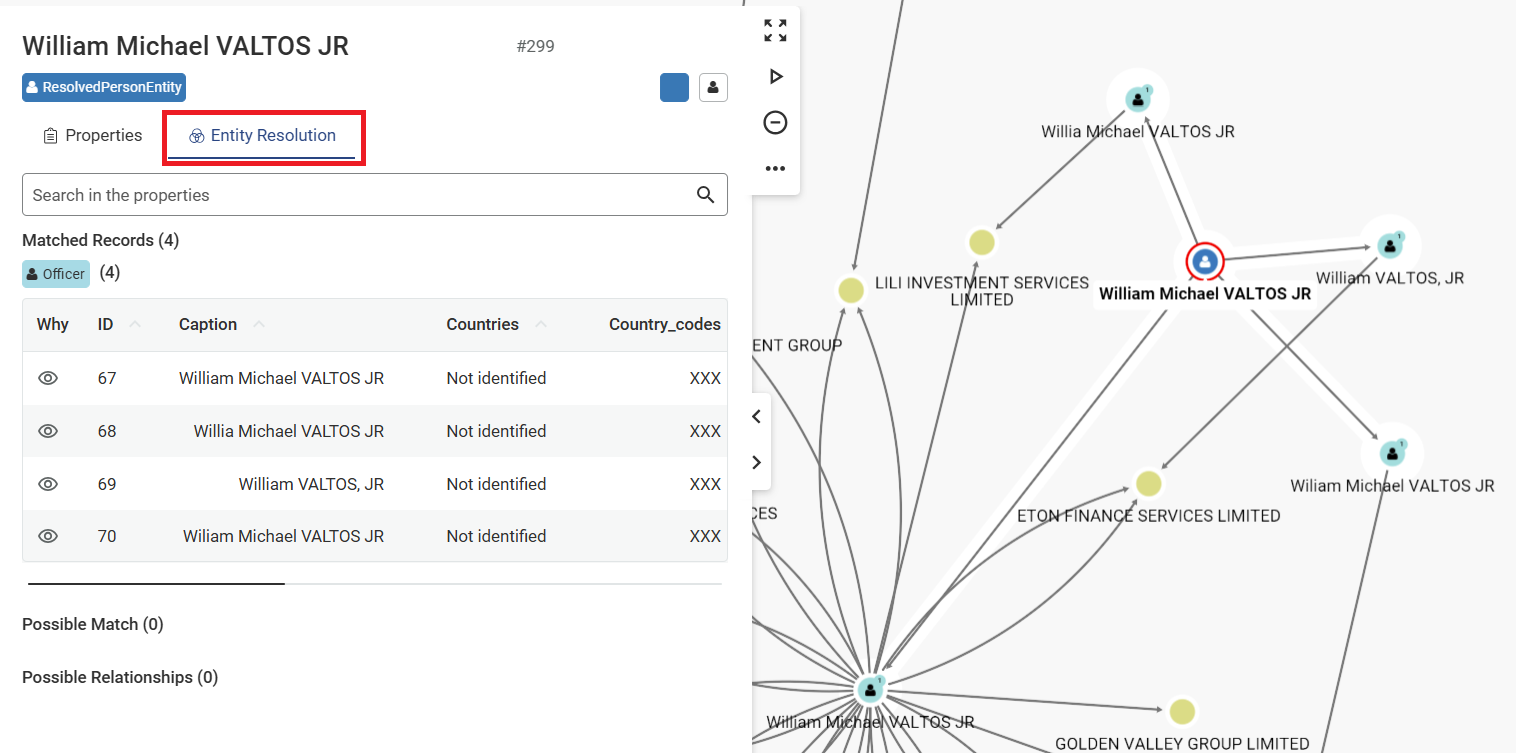
ℹ️ These node categories cannot be modified or deleted. They are read-only system entities generated by Entity Resolution.
RESOLVED: between a record and the resolved entity it belongs to, identifies obvious duplicates in your dataPOSSIBLY_SAME: between entities that may be duplicatesPOSSIBLY_RELATED: between entities that are likely relatedThe MATCH_KEY property gives you a quick hint about which attributes were selected to set the relationship type.
You can also ask for more detailed explanations by asking WHY on records and entities. See "WHY" and "WHY NOT" Explanations section.
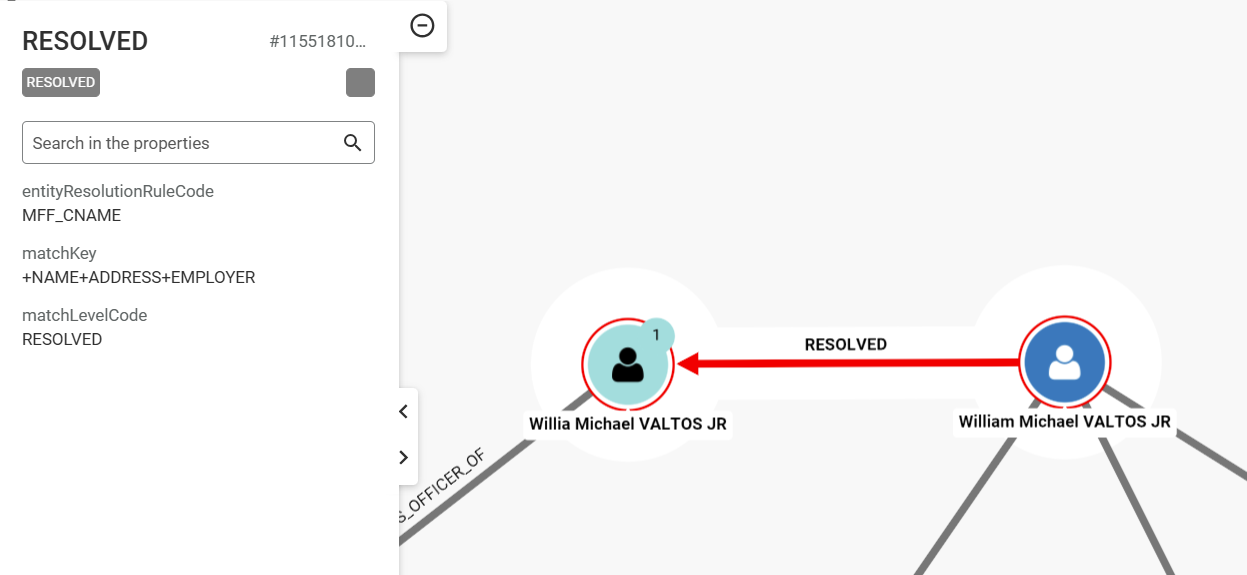
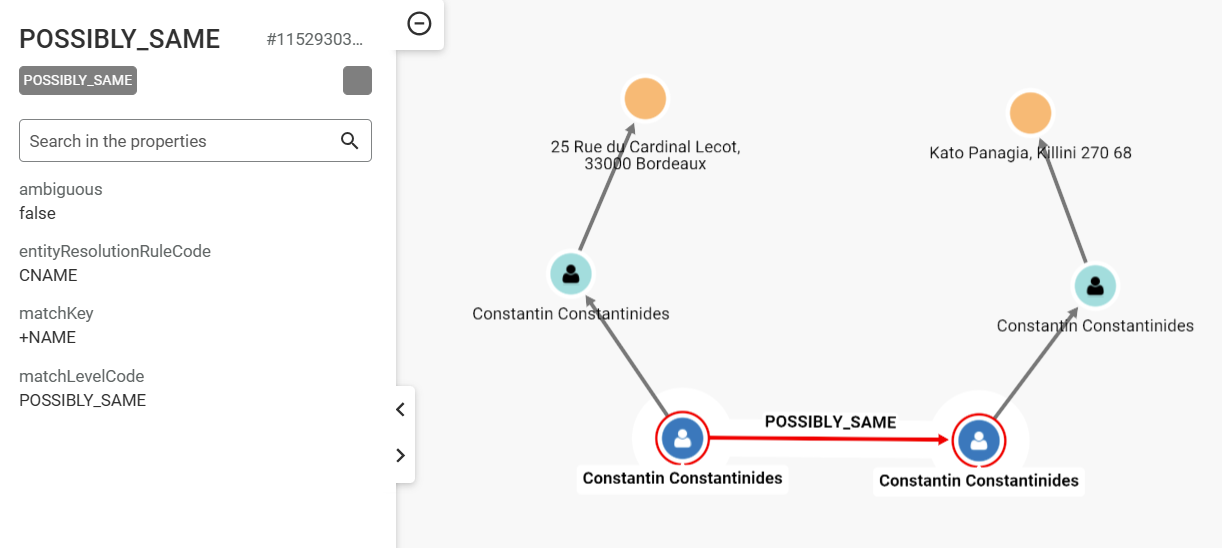
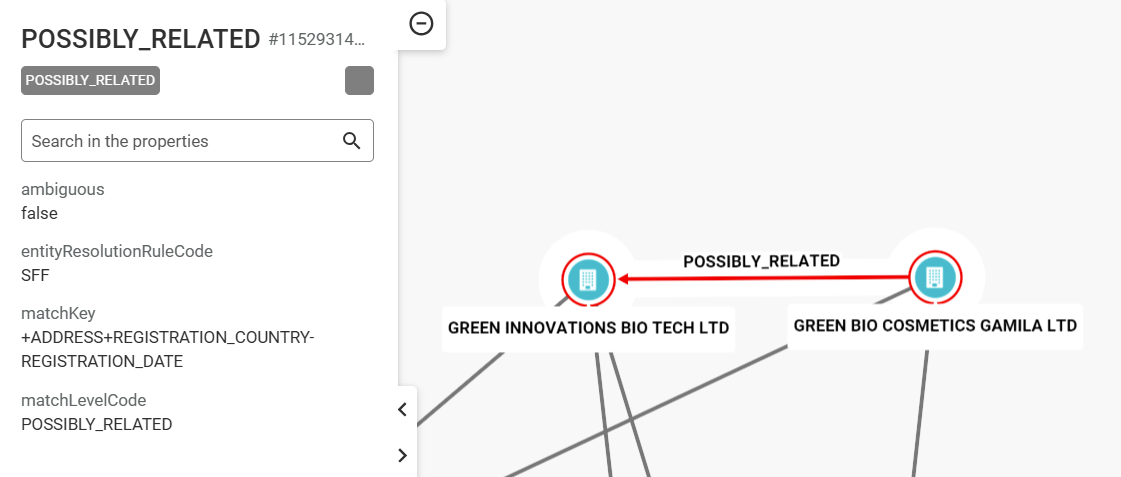
To better understand why records resolved to entities or why entities didn’t match, you can ask for explanations directly from the visualization.
There are two ways to see why records have been resolved into the same entity:
💡 If a resolved entity has only one linked record, the "WHY?" option is not shown (no explanation needed).
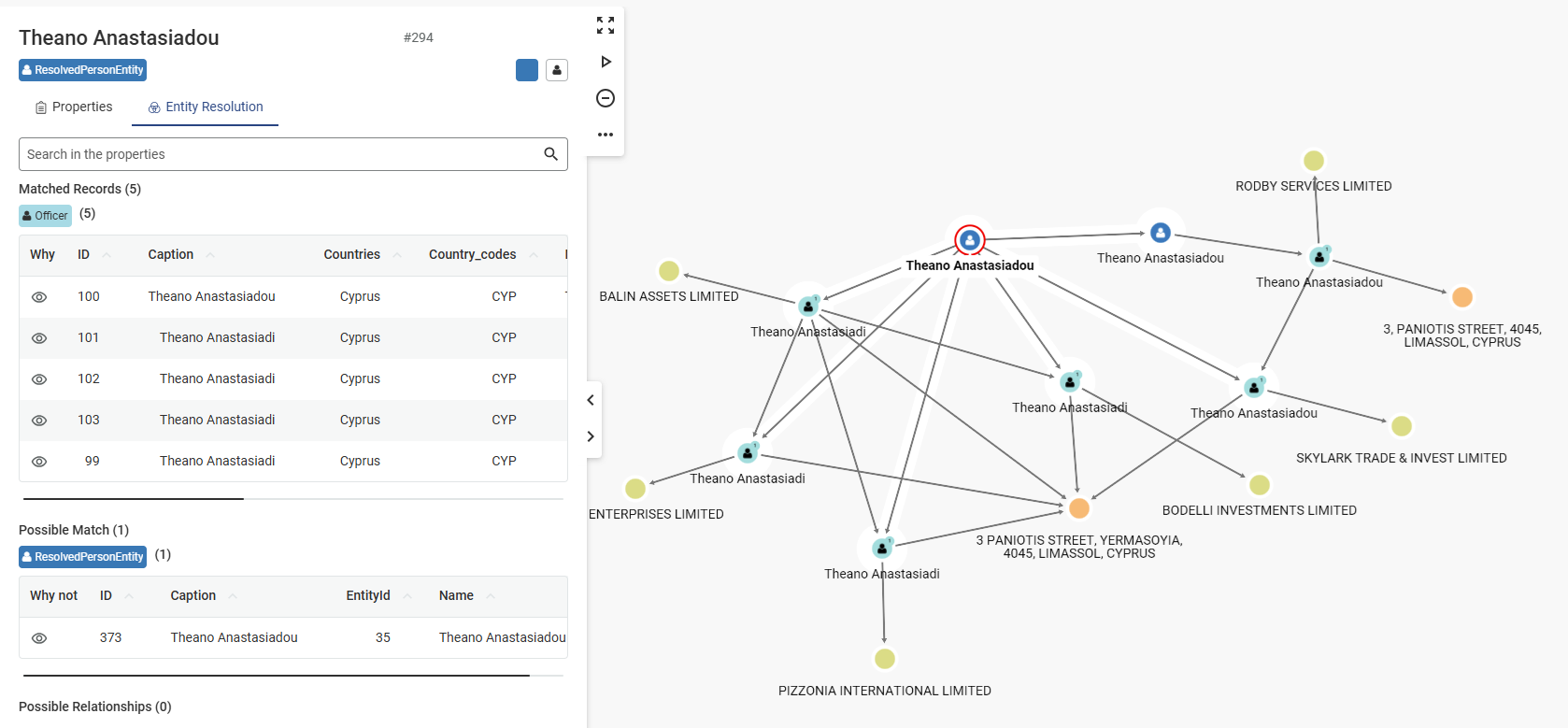
Clicking the eye (👁) icon opens a popup with:
POSSIBLE MATCH or POSSIBLE RELATIONSHIP)MATCHKEY that shows what properties contributed to the match (e.g., +NAME+DOB)Example of WHY a record matched an Entity
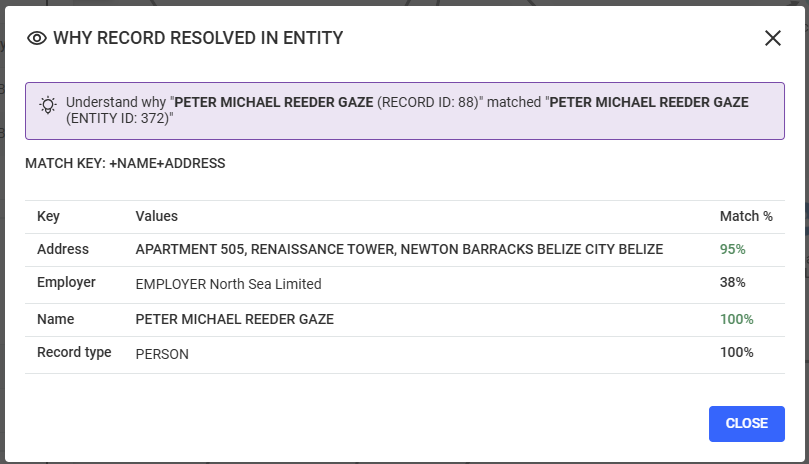
Example of WHY two entities did NOT resolve together (possible relationship)
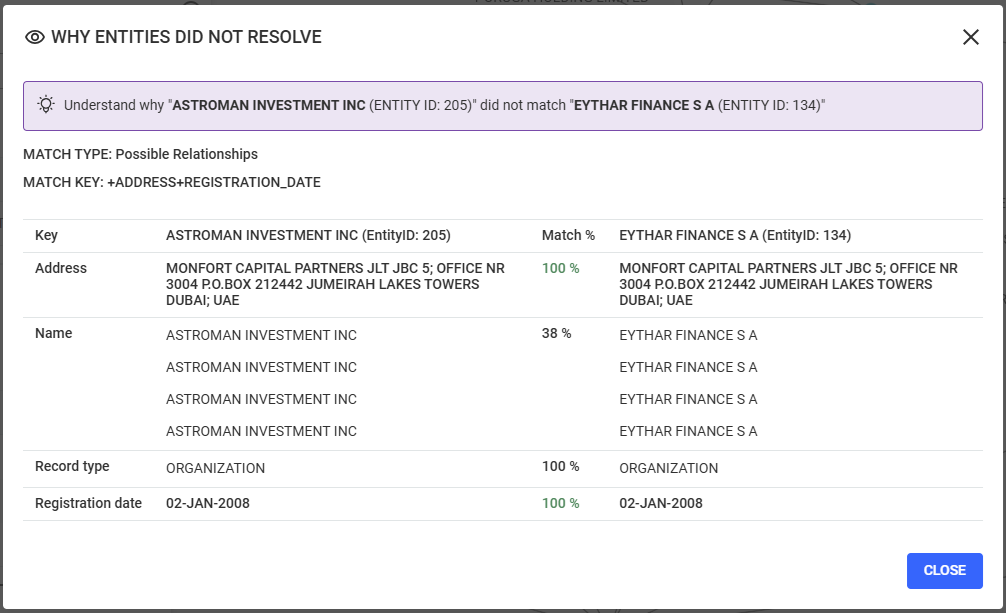
🛠️ All explanations rely on data from the Senzing engine. If Entity Resolution is disabled or results are cleared, explanations are no longer available.
Entity Resolution may introduce many new nodes into your visualization. To simplify exploration, Linkurious Enterprise automatically provides special grouping rules for resolved entities.
A default grouping rule named "Duplicates" is available when Entity Resolution is enabled.
RESOLVED relationship.ResolvedPersonEntity and ResolvedOrganizationEntity.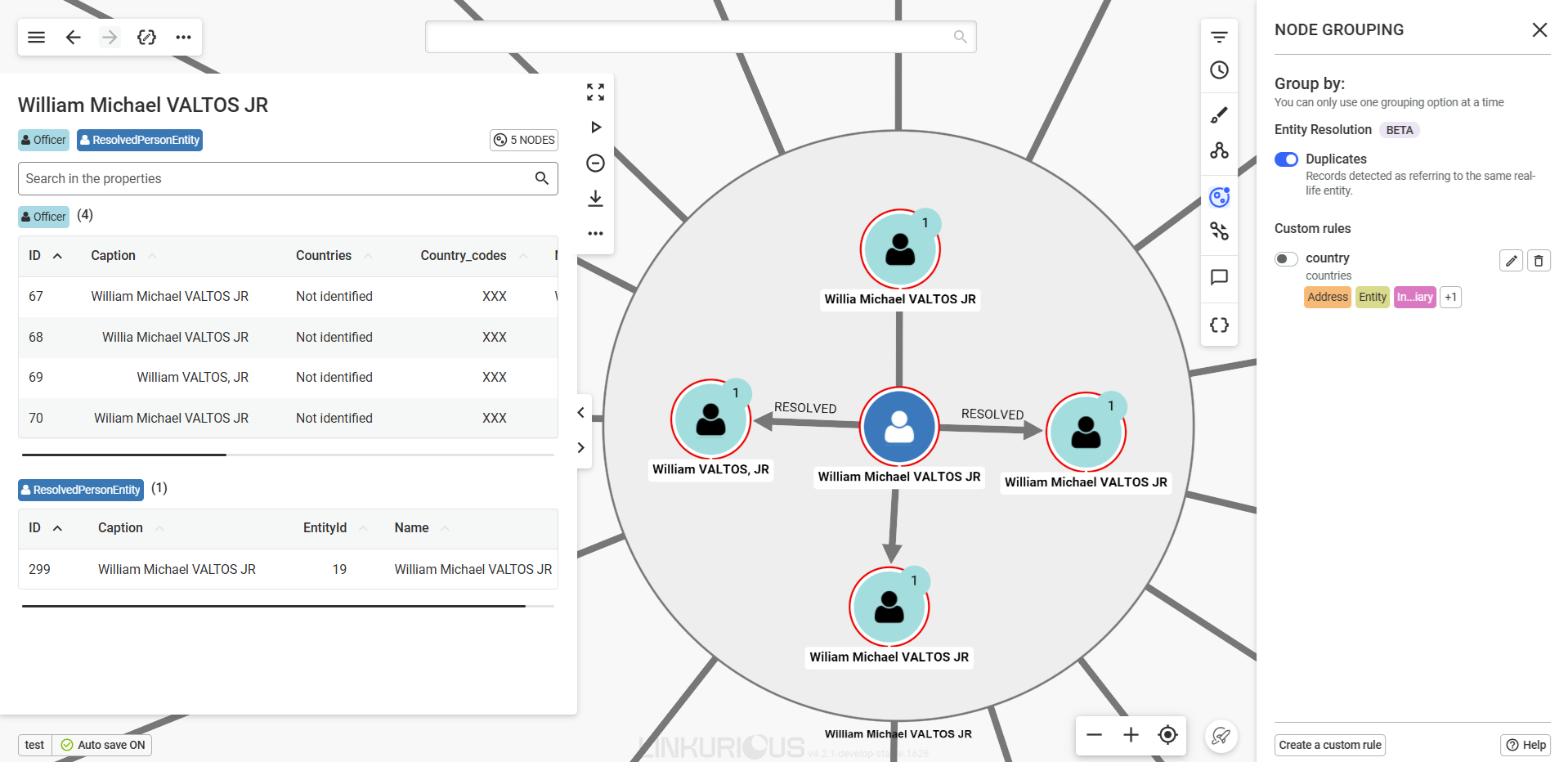
To reduce visual noise, users can collapse or expand grouped nodes.
By default, when enabling a grouping rule, node groups appear as collapsed.
Double-click on a node-group to collapse or expand it.
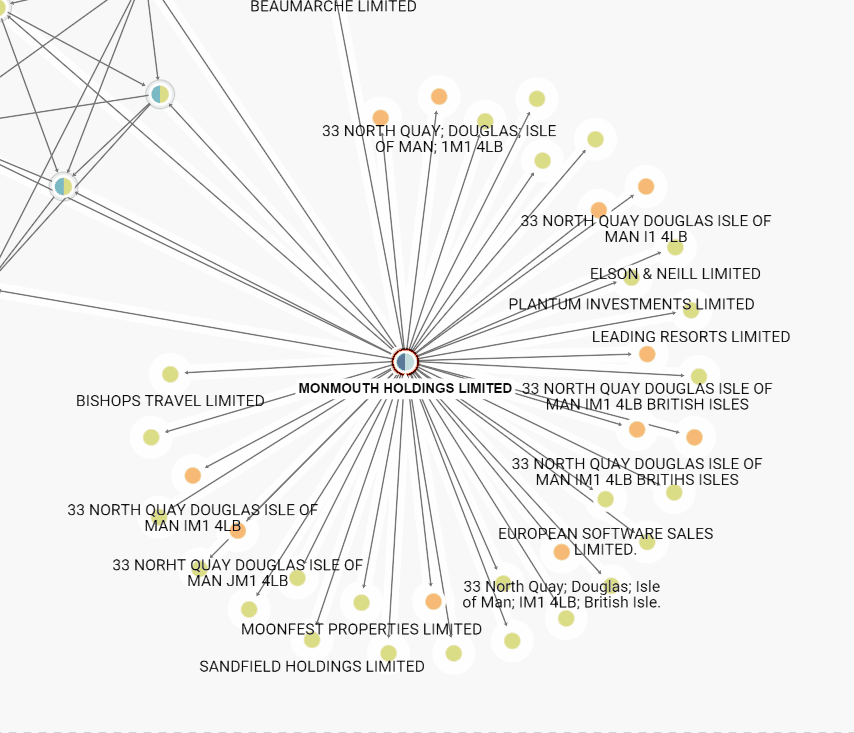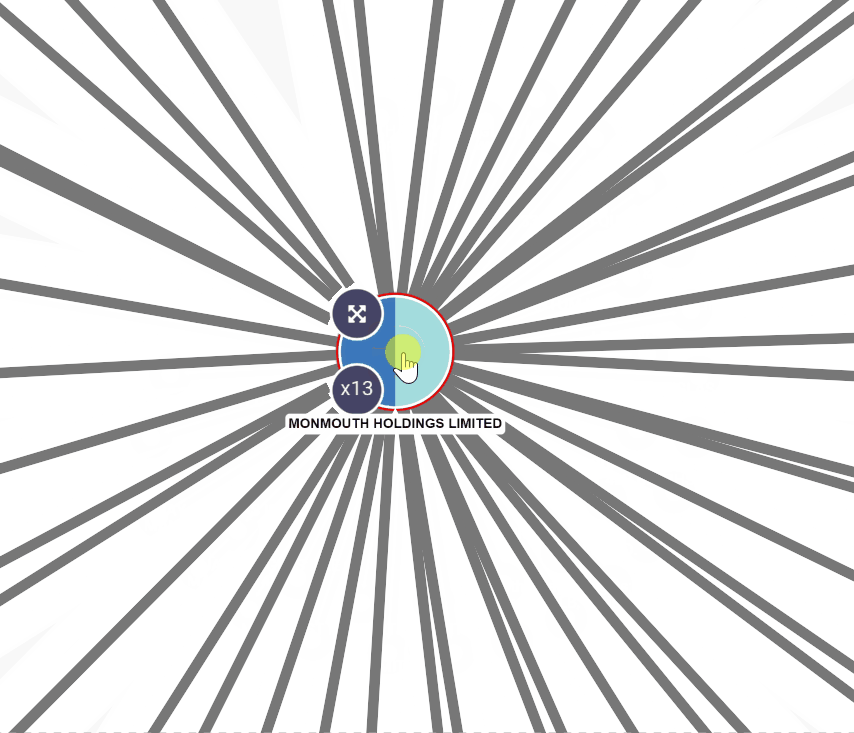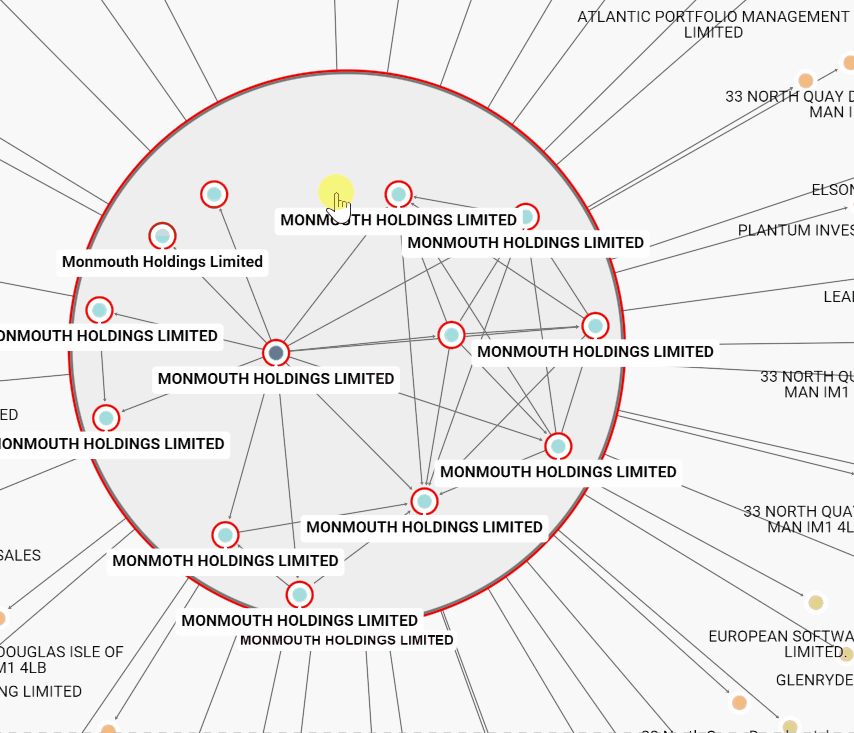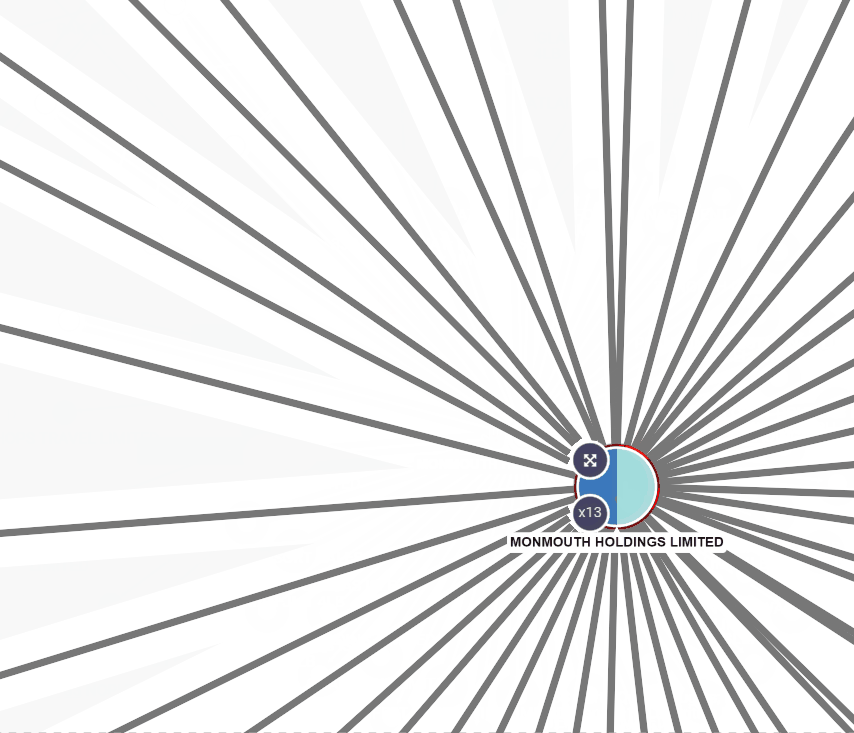
You can also choose to "Collapse all groups" or "Expand all groups" via right-click in an empty space of the visualization.
x4)⚠️ Collapsed groups do not allow expansion of connections (edges) via double-click. Use the right-click menu to expand connections instead.

For test use or trials, please contact us and we will provide you with a evaluation license.
For production use, admins must ensure a valid Linkurious Enterprise license containing Entity Resolution credits is configured for Entity Resolution to function.
ℹ️ Get in touch with us to get access to a production license according to your needs.
License details appear in the License Management menu of Linkurious Enterprise. You can access License Management from the wheel menu, or from Entity Resolution license metrics section.
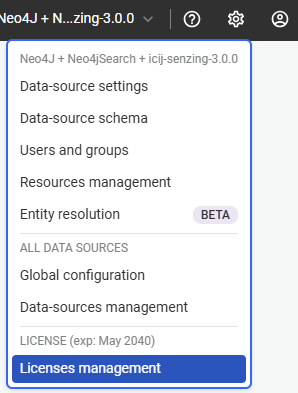

If you have bought a license that contains credits for Entity Resolution, you can upload this license in Linkurious Enterprise. Your new license contains Entity Resolution information. Once uploaded and validated, you will be able to see Entity Resolution license details, with credits available and expiration date.
After running the Entity Resolution process, you will be able to see your credit consumption.
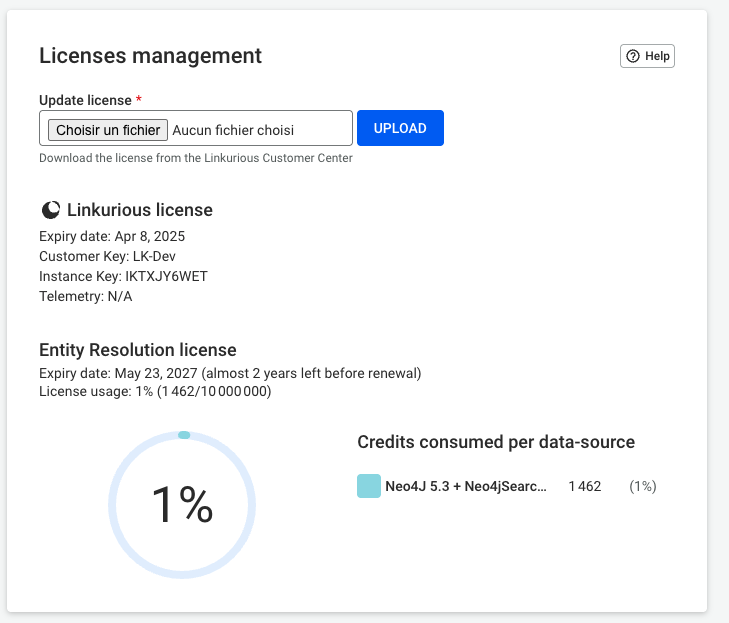
⚠️Uploading an invalid license will disable Entity Resolution. If you have a problem with the license you received, please get in touch.
If your Entity Resolution license expires (by date or credit limit):
⚠️ Metrics may show zero if the license is expired, due to a limitation in the Senzing engine.
| Problem | Solution |
|---|---|
| Entity Resolution is not available | - Check that the selected data-source is Neo4j, and not read-only |
| - Check that the feature is enabled in the global configuration | |
| - Check the Entity Resolution server is up and running | |
| - Entity Resolution may have been run on another dataset already. Clear results on this dataset and try again. | |
| The "Run" button is disabled | Ensure at least one mapping is configured, and that the license is valid (not expired) |
| Mapping edit/delete are disabled | Wait for the current ER process to finish |
| "WHY?" explanations are not available | The record may be alone, Entity Resolution results may have been cleared, or Entity Resolution server is not reachable |
| Email notifications are not received | Ensure mailer settings are configured and notifications are enabled |
| Metrics show 0 after license expiry | This is expected behavior due to Senzing license validation limitations |
Linkurious Enterprise supports email notifications for the following events, when they are correctly configured by admins.
Email notifications when new cases appear in alerts.
Alert users can expect an email including information on the latest activity on alerts which they have access to and URLs of the alerts for easy access.
Email notifications when a case is assigned to a user.
Alert users who have cases assigned to them by another user, will receive an email including the case assigned to them, the status and creation date of the case and the user who assigned it to them as well as the URL for easy access to the case.
Email notifications when a user is mentioned in a visualization.
Users who are mentioned in a specific visualization will receive an email containing a URL. When opening the URL, depending on their access rights in said visualization, they will be redirected to it.
Email notifications when a user is mentioned in a case.
Users who are mentioned in a comment of a case, will receive an email containing the URL of the case they were tagged in. When opening the URL, depending on their access rights in said alert, they will be redirected to the case view.
To enable, disable and customise the email notifications go to Admin > Global configuration.
The following options are available in the email configuration key:
alertNotifications (default: false): This is the feature activation parameter. Its default value false will disable the feature completely while true would enable the feature. Keep in mind that in order for the feature to work properly the rest of the parameters should also be successfully set.
newCasesDigestNotificationFrequency (default: 0 9 * * *): This is a parameter which refers to the time interval you would wish to receive a digest email at. This parameter is a cron expression. The default value stands for 9:00 AM daily.
caseAssignmentNotificationFrequency (default: */10 * * * *): This is a parameter which refers to the maximum time interval before the user is notified if they got assigned to a case. This parameter is a cron expression. The default value stands for a time interval of 10 minutes.
caseMentionNotificationFrequency (default: */10 * * *): This is a parameter which refers to the maximum time interval before the user is notified if they got mentioned in a comment in a case of an alert. This parameter is a cron expression. The default value stands for a time interval of 10 minutes.
visualizationNotifications (default: false): This is the feature activation parameter. Its default value false will disable the feature completely while true would enable the feature. Keep in mind that in order for the feature to work properly the rest of the parameters should also be successfully set.
visualizationMentionNotificationFrequency (default: */10 * * *): This is a parameter which refers to the maximum time interval before the user is notified if they got mentioned in a comment in a visualization. This parameter is a cron expression. The default value stands for a time interval of 10 minutes.
fromEmail: This is the parameter for the sender's email address.
mailer: This is the configuration object which will contains all the required properties for sending emails.
type (default: smtp): This parameter refers to the email protocol used. Linkurious Enterprise only supports smtp for the moment.
host (default: 127.0.0.1): Refers to the server address of your mail service provider.
port (default: 25): Port number for the email server.
ssl (default: false): if true, the connection will use TLS when connecting to the email server. If false, TLS is used if the email server supports the STARTTLS extension. In most cases set this value to true if you are connecting to port 465. For port 587 or 25 keep it false.
allowSelfSigned (default: false): If true self-signed certificates are enabled.
auth (optional): The credentials to connect to the mail server.
user (default: user@serviceProvider.com ): The username (e.g., the email address)password (default: password): The password, it is recommended to provide the password as an environment variable.Example of email configuration
{
"alertNotifications": true,
"newCasesDigestNotificationFrequency": "0 0 9 * * ?",
"caseAssignmentNotificationFrequency": "*/10 * * * *",
"caseMentionNotificationFrequency": "*/10 * * * *",
"visualizationNotifications": true,
"visualizationMentionNotificationFrequency": "* * * * *",
"fromEmail": "john@myCompany.com",
"mailer": {
"type": "smtp",
"host": "127.0.0.1",
"port": 25,
"ssl": false,
"allowSelfSigned": false,
"auth": {
"user": "user@serviceProvider.com",
"password": "password"
}
}
}
Linkurious Enterprise allows you to modify the visualizations appearence by modifying the ogma.options settings.
To edit the Ogma settings,
you can either use the Web user-interface
or edit the configuration file located at linkurious/data/config/production.json.
Example configuration:
{
"renderer": "webgl",
"nodeGrouping": {
"displayCollapsedByDefault": false
},
"options": {
"styles": {
"node": {
"nodeRadius": 5,
"shape": "circle",
"text": {
"minVisibleSize": 24,
"maxLineLength": 35,
"font": "roboto",
"color": "#000",
"size": 14,
"maxTextLength": 60
}
},
"edge": {
"edgeWidth": 1,
"shape": "arrow",
"text": {
"minVisibleSize": 4,
"maxLineLength": 35,
"font": "roboto",
"color": "#000",
"size": 14,
"maxTextLength": 60
}
}
},
"interactions": {
"zoom": {
"modifier": 1.382
},
"pan": {
},
"rotation": {
"enabled": false
}
},
"backgroundColor": "rgba(240, 240, 240, 0)"
}
}
Supported ogma.options settings are available here.
In addition to what you find in the Ogma documentation, Linkurious Enterprise allows the following extra configuration keys:
styles.node.nodeRadius (optional) The node radiusstyles.node.shape (optional) The default shape of a nodestyles.node.text.maxTextLength (optional) The maximum length of a node captionstyles.edge.edgeWidth (optional) The width of the edgestyles.edge.shape (optional) The default shape of an edgestyles.edge.text.maxTextLength (optional) The maximum length of an edge captionThere are also the following top level options in this ogma settings object:
renderer: (optional) Same as the renderer Ogma option available here.nodeGrouping.displayCollapsedByDefault (optional) Whether node groups should be displayed as collapsed by defaultIn Linkurious Enterprise, you can customize the default visual aspect of nodes, edges, edge-groups for new visualizations.
Your users can then jump head-first into the exploration of their data.
Styles can be configured individually by each user using the design panel. Default values can be configured for all users by an administrator.
Default styles are set on a per data-source basis. To set the default styles of a data-source, you have two options:
In any visualization, you can edit the styles using the design panel. Once the styles match what you want to use as default styles for the current data-source:
⚠️ Visualizations can contain their own styles or user preferences, which can differ from the current default styles. Because of that, using Save styles and captions as default can cause existing default style-rules to be lost. To avoid losing existing rules, we recommend resetting the styles of the current visualization before defining and saving new default styles.
Open the data-source configuration page and scroll to the Default styles section.
In this section, you can edit the default styles using the style-rules syntax.
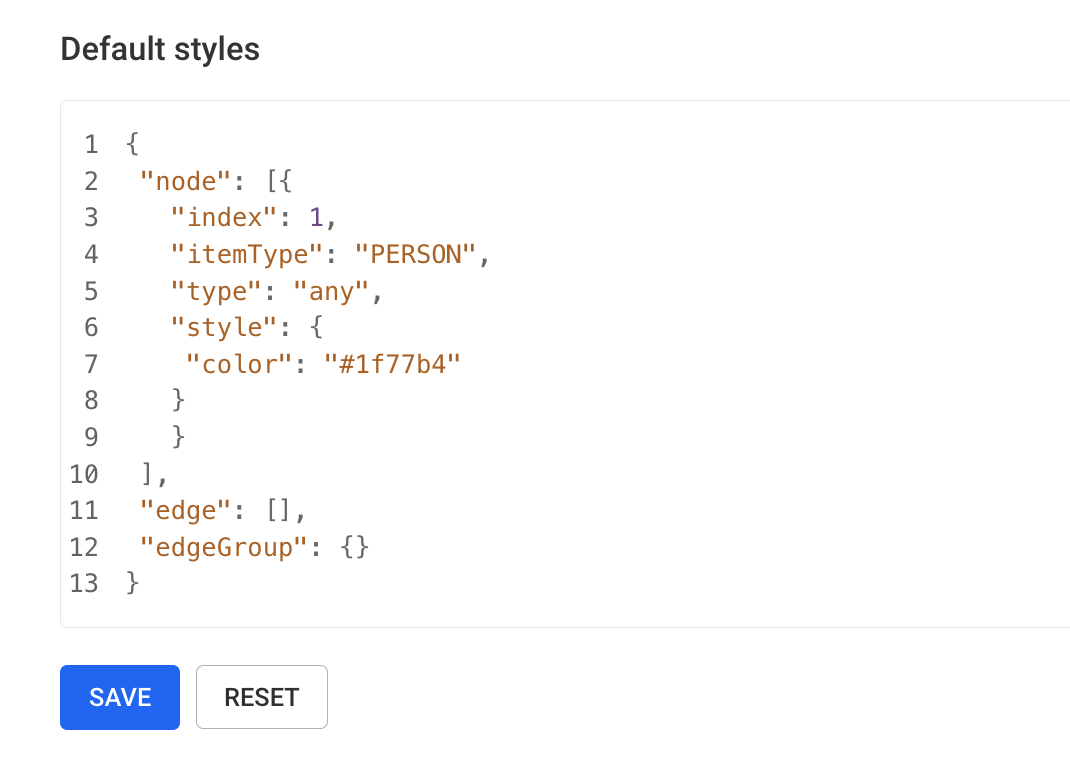
The nodes, edges, and edgeGroup sections define the default styles for nodes, edges,
and edge-groups respectively.
To define default styles for the graph, you need to add new style-rules in each of these sections.
By default, every node-category has a pre-assigned color, thanks to a default node color rule
(the rule with "index": 0 in the image above).
While this is convenient for a new project, you may want to remove the default rule in some
cases to have better control on the styles. A typical use case is to avoid nodes with multiple
categories (e.g. PERSON and CLIENT) to be displayed with several colors (which makes them
look like a pie chart with one color slice for each category).
Removing the default node color rule allows having node-categories without an explicit color, thus preventing the "pie chart" effect on nodes with multiple colors, by assigning a color to only one of the categories.
A style-rule defines style to apply to a subset of the graph. For example:
A style-rule is made of two parts:
itemType, input, type, and value fields. See selectors section for details)style field, see styles section for details)The fields of a style-rule are:
index: a unique number (>= 0) used to influence the order in which rules are applied (see style-rule priorities section for details)itemType: node-category or edge-type the style-rule applies to (optional if type is any)type: a value among "any", "novalue", "nan", "range", "is"input (optional): identify on which the style is computed onvalue (optional): a value to be used by the selector (see selectors section for details)style: the style applied by this rule (see styles section for details)The input field is an array of strings identifying the path to a value within a node (or edge).
Supported paths are:
"properties": is the container for all properties of a node (or edge).
For example, to identify the property called name, the input value should be ["properties", "name"]."statisics": is the container of the internal statistics computed by Linkurious Enterprise on a visualization object. Current available statistics are:"degree": defines a node, represents the number of nodes connected through any type of relationship (in case of supernode, the value is not defined).
To access this attribute, the input value should be ["statisics", "degree"].For example:
{
"index": 3,
"itemType": "COMPANY",
"input": ["properties", "name"],
"type": "is",
"value": "linkurious",
"style": {
"color": "blue"
}
}
The above rule will apply the style {"color": "blue"} to all nodes
with category "COMPANY" where the name is "linkurious".
{
"index": 4,
"itemType": "COMPANY",
"input": ["statistics", "degree"],
"type": "range",
"value": {
">": 20
},
"style": {
"size": "150%"
}
},
{
"index": 5,
"itemType": "COMPANY",
"input": ["statistics", "degree"],
"type": "novalue",
"style": {
"size": "200%"
}
}
The above rule will apply the style {"size": "150%"} to all nodes with category "COMPANY" that are
connected to more that 20 other nodes and the style {"size": "200%"} to all supernodes with category "COMPANY".
indexhas to be unique. It is currently required for technical reasons. This will be made more user-friendly in future releases.
The selector is used to specify to which items the style is applied to.
For example, you can configure all the "COMPANY" founded more than 12 years ago to have a particular
style. To do so, we use a style-rule with a range type and with value:
{
">": 12
}
The overall style-rule will look like the following (assuming we want to color the nodes in red):
{
"index": 3,
"type": "range",
"itemType": "COMPANY",
"input": ["properties", "age"],
"value": {
">": 12
},
"style": {
"color": "red"
}
}
For range queries, you can use one or more among the following operators: >, <, >=, <=.
range: matches numerical values that are contained in the range defined in the value parameter, e.g.{"<=": 12} means "smaller or equal to 12"{">": 0, "<": 10} means "between 0 and 10 excluded"any: matches any valueis: matches all values that are equal to the value parameter, e.g.:{
"input": ["properties", "name"],
"type": "is",
"value": "linkurious",
// ..
}
novalue: matches values that are null, missing or contain an empty stringnan: matches values that do not contain a numerical value (Not A Number)In addition to
type,input, andvalue, you must always specifyitemTypeto filter by node-category or edge-type except iftypeisany.
Set under the style property key an object with one key, color, e.g.:
"style": {
"color": "blue" // or "#0000FF", "rgba(0, 0, 255, 1)"
}
propertyName in our case):"style": {
"color": {
"type": "auto",
"input": ["properties", "propertyName"]
}
}
The syntax is the same to define the color for node, edges, and edge-groups.
For nodes, under style, use the size key to define a percentage of a regular node's size, e.g.:
"style": {
"size": "200%" // twice as large as a regular node
}
For edges, under style, use the width key to define a percentage of a regular edge's width, e.g.:
"style": {
"width": "220%"
}
Just like you can set the size (for nodes) or width (for edged) using a fixed value, you can also set the size dynamically, based
on a numerical property of the node (or edge) e.g.:
For nodes:
"style": {
"size": {
"type": "autoRange",
"input": ["properties", "age"],
"scale": "linear"
}
}
For edges:
"style": {
"width": {
"type": "autoRange",
"input": ["properties", "age"],
"scale": "linear"
}
}
The scale attribute can take two values:
linear: Edges and nodes are sized using a linear scale function based on their property values.logarithmic: Edges and nodes are sized using a logarithmic scale function based on their property values.If scale is not defined, linear is applied by default.
In the example above, all selected nodes and edges are scaled linearly based on the property age.
Nodes will be sized between the range of 50% (the smallest) and 500% (the largest).
Edges will be sized between the range of 50% (the smallest) and 200% (the largest).
⚠️ Note that when dynamic sizing is enabled, the layout is recomputed every time a visualization is opened (except if you have "incremental expand" enabled in layout user settings).
Under the style, use the shape key to define the shape of the selected node (or edge).
"circle" (default), "cross", "diamond", "pentagon", "equilateral", "square" or "star"."style": {
"shape": "star" // "circle", "cross", "diamond", "pentagon", "equilateral", "square" or "star"
}
"arrow" (default), "dashed", "dotted", "line" or "tapered"."style": {
"shape": "dotted" // "arrow", "dashed", "dotted", "line" or "tapered"
}

You can host your custom icons in Linkurious Enterprise itself by storing them in the folder
located in linkurious/data/server/customFiles/icons.
Users will find them in the Design panel:
![]()
If you want to edit style-rules manually, the style-rules to access these images would look like:
"style": {
"image": {
"url": "/icons/company.png"
}
}
Nodes can be filled with an image if one of their property is a URL to an image. Available image formats are PNG, JPG, GIF, and TIFF.
The following style will set an image:
Example:
"style": {
"image": {
"url": "http://example.com/img/company.png"
}
}
To assign dynamically an image to a node,
for example if the logo is stored in a node property called "logo_url",
you just need to set the following style:
"style": {
"image": {
"url": {
"type": "data",
"path": [
"properties",
"logo_url" // change it to the property key where your image urls are stored
]
}
}
}
If you want to resize your images in a node you can you use the additional properties scale, fit and tile, e.g.:
"style": {
"image": {
"url": ... // one of the above
"scale": 0.8, // scale the image in the node
"fit": false, // if true, fill the node with the image
"tile": false // if true, repeat the image to fill the node
}
}
Within the edgeGroup property key, we can directly set the color, shape, and width that will apply to all grouped edges of a data-source.
"edgeGroup": {
"color": "red",
"shape": "dashed", // "arrow", "dashed", "dotted", "line" or "tapered"
"width": "320%"
}
Editing the default styles in the data-source page automatically changes captions for existing users for newly created visualizations. These changes are not applied to existing visualizations.
When style-rules are applied, an implicit priority is used to define in which order they are applied. The idea behind the order is that "the last applied rule wins" (like in CSS).
Style-rules are sorted by:
Specificity (how specific their selector is):
4: When both itemType and input are defined (i.e., the rule applies to a specific property of a given node-category, or edge-type)3: When only input is defined (i.e., the rule applies to a specific property for all nodes, or edges)2: When only itemType is defined (i.e., the rule applies to all nodes with that node-category, or edge with that edge-type)1: When neither itemType nor input are defined (i.e., the rule applies to all nodes or edges)ItemType (the name of the node-category or edge-type they apply to):
itemType alphanumericallyIndex:
index.index is not defined for a given rule, we consider rules in the order they are defined
in the style-rules array and define index as the largest previous value + 1.As a consequence, this would be the sorting order of these rules:
| itemType | input | specificity | index |
|---|---|---|---|
undefined |
undefined |
1 | 1 |
undefined |
undefined |
1 | 2 |
undefined |
undefined |
1 | undefined => max(index) + 1 = 3 |
"AAA" |
undefined |
2 | 1 |
"AAA" |
undefined |
2 | 2 |
"BBB" |
undefined |
2 | 1 |
"BBB" |
undefined |
2 | 2 |
undefined |
["property", "name"] |
3 | 1 |
undefined |
["property", "name"] |
3 | 2 |
"COMPANY" |
["property", "name"] |
4 | 1 |
"COMPANY" |
["property", "name"] |
4 | 2 |
In Linkurious Enterprise, node and edge captions are the texts displayed next to a node or an edge.
Captions, as for Styles, can be configured individually by each user using the Design panel.
As for Styles, an administrator can set the default values from its own workspace or by editing them from the data-source configuration page.
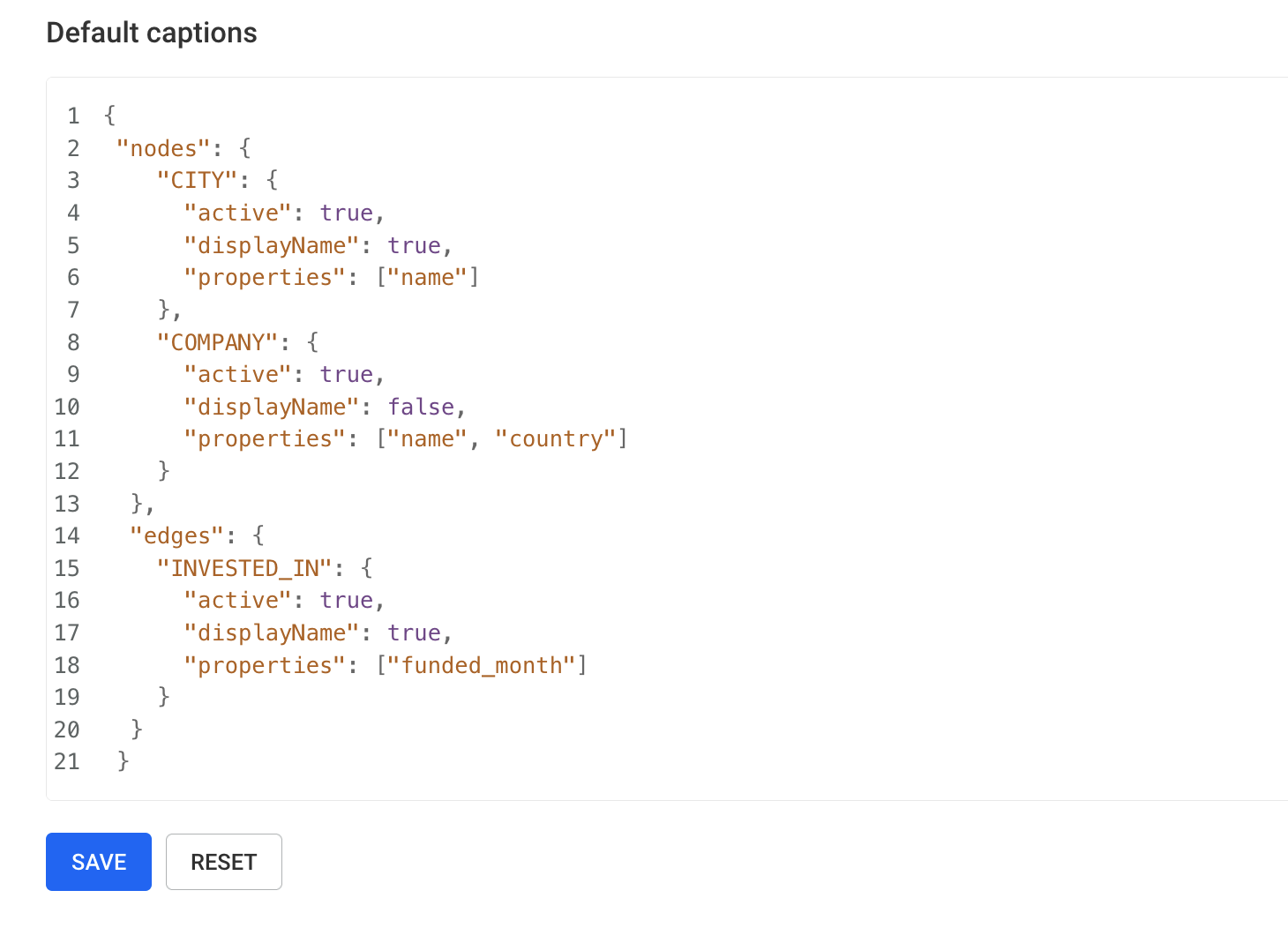
Inside Default Captions, the nodes and the edges sections define the
default captions for nodes and edges respectively.
Each of these two sections is an object where the keys are node categories or edge types and the values are objects with the following keys:
active: Whether this caption definition is useddisplayName: Whether to prefix the caption text with the node category or edge typeproperties: An array of properties keys that will be concatenated to create the captionsExample:
"defaultCaptions": {
"nodes": {
"CITY": {
"active": true,
"displayName": true,
"properties": ["name"]
},
"COMPANY": {
"active": true,
"displayName": false,
"properties": ["name", "country"]
}
},
"edges": {
"INVESTED_IN": {
"active": true,
"displayName": true,
"properties": ["funded_month"]
}
}
}
CITY and name: "Paris" would have the caption CITY - Paris.COMPANY, name: "Google" and country: "USA" would have the caption Google - USA.INVESTED_IN and funded_month: "2016-04" would have the caption INVESTED_IN - 2016-04.Editing the default captions in the data-source page does automatically change captions for existing users for newly created visualizations. Existing visualizations are not touched.
In Linkurious Enterprise, you can configure the properties order per data-source that will be displayed in the following:
You will need “Manage data-source default styles” access right or be an administrator to edit them in the data-source settings page.
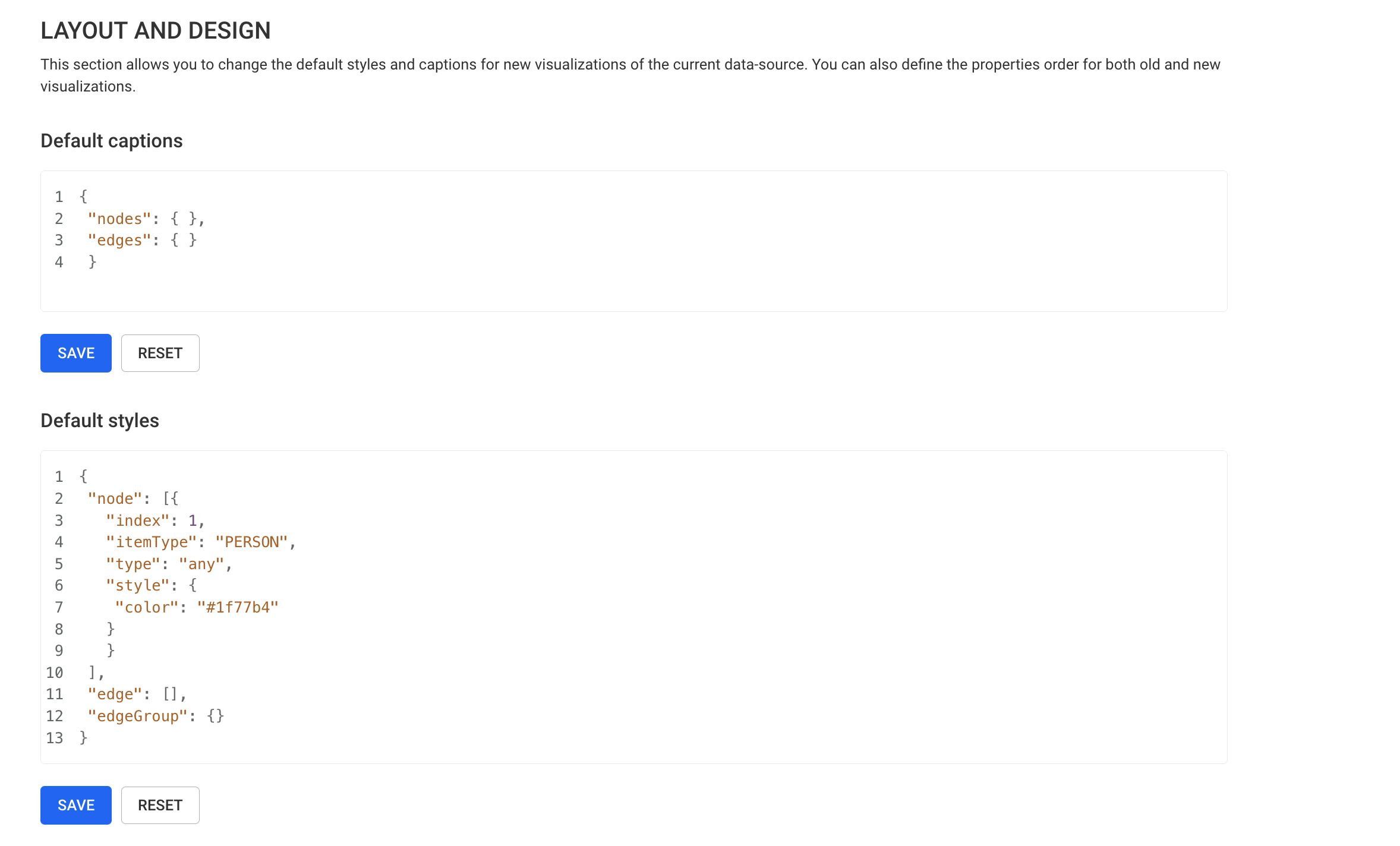
To do so, you will need to add an object with the properties that you want to see in the top of the list for each category and/or edge type.
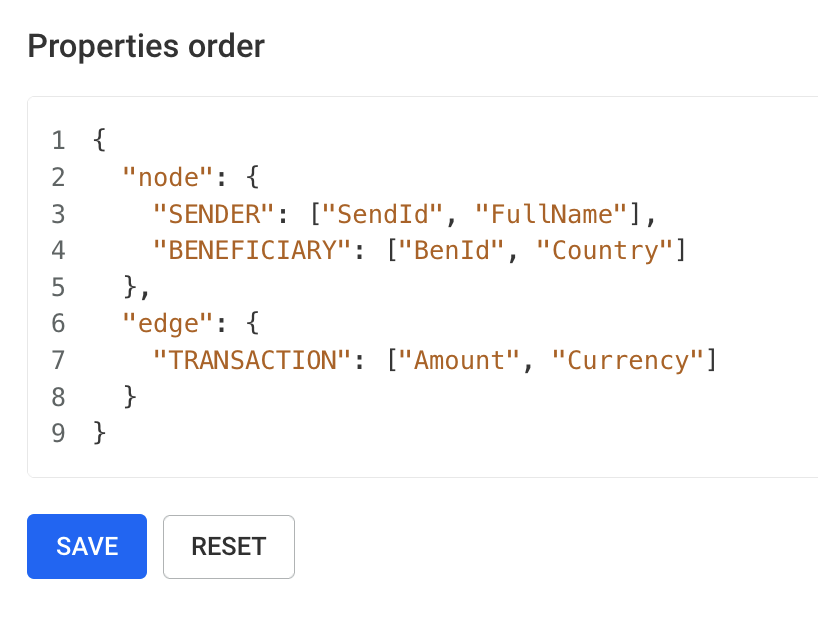
Example:
{
"node": {
"SENDER": ["SendId", "FullName"],
"BENEFICIARY": ["BenId", "Country"]
},
"edge": {
"TRANSACTION": ["Amount", "Currency"]
}
}
Will allow the users to see SendId and FullName on top of the list for the SENDER
while the remaining properties will be shown with the default alphabetical order.
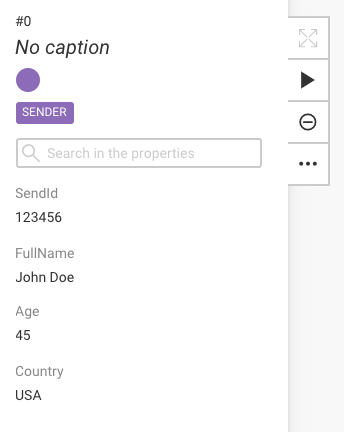
Properties not defined in JSON will remain alphabetically-ordered, and will appear after the defined properties.
The category order is always alphabetical and is case-sensitive:
Linkurious Enterprise supports displaying nodes with geographic coordinates (latitude and longitude) on a map.
Users are able to switch a visualization to geo mode when geographic coordinates are available on at least one node of the visualization. The map tiles layer used in geo mode can be customized by users.
By default, Linkurious Enterprise comes pre-configured with several geographical tile layers.
Administrators change the available geographical tile layers by editing the leaflet section in the configuration file (linkurious/data/config/production.json).
The leaflet key is an array of geographical tile layer configurations.
Each entry has the following attributes:
name (required, string): Name of the geo tiles layer.urlTemplate (required, url): Tile URL template with {x}, {y} and {z} parameters ({s} is optional).minZoom (required, number): The minimum zoom level supported by the layer.maxZoom (required, number): The maximum zoom level supported by the layer.thumbnail (required, url): URL of a 128x60 image to be used as a thumbnail for the layers (for user-added layers, the URL is relative to the linkurious/data/customFiles folder).attribution (required, string): The layer copyright attribution in HTML format.subdomains (string): Letters to use in the {s} tile URL template (required if urlTemplate contains {s} ).overlay (boolean): Whether this layer is a base layer (false) or a transparent layer that can be used as an overlay (true).id (string): Unique tiles layers identifier (MapBox only).accessToken (string): Tiles layer access-token (MapBox only).Geographical tile layers and overlay layers can be found at https://leaflet-extras.github.io/leaflet-providers/preview/.
Example configuration:
"leaflet": [
{
"overlay": true,
"name": "Stamen Toner Lines",
"thumbnail": "",
"urlTemplate": "http://stamen-tiles-{s}.a.ssl.fastly.net/toner-lines/{z}/{x}/{y}.png",
"attribution": "Map tiles by <a href=\"http://stamen.com\">Stamen Design</a>, <a href=\"http://creativecommons.org/licenses/by/3.0\">CC BY 3.0</a> — Map data © <a href=\"https://www.openstreetmap.org/copyright\">OpenStreetMap</a>",
"subdomains": "abcd",
"id": null,
"accessToken": null,
"minZoom": 2,
"maxZoom": 20
},
{
"name": "MapBox Streets",
"thumbnail": "/assets/img/MapBox_Streets.png",
"urlTemplate": "https://api.tiles.mapbox.com/v4/{id}/{z}/{x}/{y}.png?access_token={accessToken}",
"attribution": "Map data © <a href=\"https://openstreetmap.org\">OpenStreetMap</a>, <a href=\"https://creativecommons.org/licenses/by-sa/2.0/\">CC-BY-SA</a>, Imagery © <a href=\"http://mapbox.com\">Mapbox</a>",
"subdomains": null,
"id": "mapbox.streets",
"accessToken": "YOUR_MAPBOX_ACCESS_TOKEN",
"minZoom": 2,
"maxZoom": 20
}
]
Audit trails are detailed logs about the operations performed by your users on your graph databases, when using the search bar in the visualization workspace and when using Linkurious Enterprise plugins. Because they have the potential to take up a substantial amount of memory depending on the number of users and the operations performed, they are disabled by default.
Audit trails can be enabled and configured in linkurious/data/config/production.json.
They are found under the auditTrail key, which contains the following options:
enabled (default: false): Whether to enable audit trail recording.logFolder (default: "audit-trail"): Where to store the results of the audit trail. This path is relative to the linkurious/data directory.fileSizeLimit (default: 5242880, i.e. 5MB): Maximum size of one log file in bytes. A new file is created when the limit is reached (i.e. the logs are rotated). This avoids the creation of unworkably large log files.strictMode (default: false): Whether to ensure that each operation has been logged before returning its result to the user.
By setting it to true (synchronous), no results will be returned to the user until the logging operation is complete;
if false (asynchronous), the user will be able to receive the results while the logging operation is still not finalized.
Setting this parameter to true will ensure that no audit trail records are lost in case of system crash but can have a substantial negative effect on the responsiveness of the server if, for example, large queries are run.mode (default: "rw", read and write): Which kinds of user operation to log ("r" for READ, "w" for WRITE, "rw" for READ WRITE). Read operations are those that do not make changes to the database. Note that raw queries are considered READ WRITE and will appear in the audit trail whether or not they make changes do the database.logResult (default: true): Whether to include the result of each operation in the log, i.e. whether to return a JSON representation of each node that has been added, updated, deleted, or simply matched. This can have a huge effect on log size: by setting logResult to false, the audit trail will only capture the properties of the nodes requested, the changes made to those nodes, or raw queries, and not the nodes themselves.logPlugins (default: true): Whether to include in the audit trail all requests and JSON responses flowing between the front-end and back-end components of a plugin installed on the Linkurious Enterprise server.logFullTextSearch (default: false): Whether to include in the audit trail all requests and JSON responses related to the search API. The search API is the one used to empower the search bar feature in the visualization workspace. Full text search audit trail logs require "r" or "rw" mode.Enabling the audit trail can impact performances negatively.
Here are options to consider to improve performances:
"mode": "w": only log write queries, ignore read queries"logResult": false: only log the query sent by the user, not the response sent by the server"strictMode": false: do not strictly wait for the audit-trail log to be written to response to each user requestThe audit trail log files contain JSON lines in JSONL format.
You can easily bind a log-management system like Logstash to interpret them.
Each log line contains the following information when the action is a graph request:
mode: "READ", "WRITE" or "READ WRITE".date: The date of the operation (in ISO 8601 format).user: The email of the user performing the operation.sourceKey: The identifier of the data-source the operation was applied to.action: The type of the operation, which is one of:"getNode""getEdge""rawQuery""createNode""createEdge""updateNode""updateEdge""deleteNode""deleteEdge""getNodesAndEdges""getAdjacentNodes""searchFull""searchFullText"params: The parameters of the operation.result: The result of the operation (if auditTrail.logResult is set to true in linkurious/data/config/production.json).Each log line contains the following information when the action is a plugin request:
mode: "PLUGIN".date: The date of the operation (in ISO 8601 format).user: The email of the user performing the operation.action: "pluginRequest".params: The parameters of the operation which contains the following:pluginName: The name of the plugin.requestUrl: The http request url.requestMethod: The http method (POST, GET, etc.).requestBody: The content of the request data.result: The result of the operation (if auditTrail.logResult is set to true in linkurious/data/config/production.json).Lines are written to the log as follows:
{"mode":"WRITE","date":"2017-01-09T17:34:07.446Z","user":"simpleUser@example.com","sourceKey":"e8890b53","action":"createEdge","params":{"createInfo":{"source":4328,"target":4332,"type":"ACTED_IN","data":{"tata":"toto"}}},"result":{"edge":{"id":5958,"data":{"tata":"toto"},"type":"ACTED_IN","source":4328,"target":4332}}}
{"mode":"READ","date":"2017-01-09T17:34:07.478Z","user":"simpleUser@example.com","sourceKey":"e8890b53","action":"getNode","params":{"id":4330},"result":{"node":{"id":4330,"data":{"tagline":"Welcome to the Real World","title":"The Matrix","released":1999,"nodeNoIndexProp":"foo"},"categories":["Movie","TheMatrix"]}}}
{"mode":"READ","date":"2017-01-09T17:34:07.507Z","user":"simpleUser@example.com","sourceKey":"e8890b53","action":"getEdge","params":{"edgeId":5950},"result":{"edge":{"id":5950,"data":{"edgeNoIndexProp":"bar","roles":["Neo"]},"type":"ACTED_IN","source":4313,"target":4330}}}
{"mode":"READ WRITE","date":"2017-01-09T17:34:12.253Z","user":"user@linkurio.us","sourceKey":"e8890b53","action":"rawQuery","params":{"query":"MATCH (n:Person) RETURN n","dialect":"cypher"},"result":{"nodes":[{"id":4357,"data":{"born":1967,"name":"Andy Wachowski"},"categories":["Person"],"edges":[]},{"id":4359,"data":{"born":1967,"name":"Carrie-Anne Moss"},"categories":["Person"],"edges":[]},{"id":4360,"data":{"born":1954,"name":"James Cameron"},"categories":["Person"],"edges":[]},{"id":4361,"data":{"born":1964,"name":"Keanu Reeves"},"categories":["Person"],"edges":[]},{"id":4362,"data":{"born":1965,"name":"Lana Wachowski"},"categories":["Person"],"edges":[]},{"id":4364,"data":{"born":1901,"name":"Phillip Cameron"},"categories":["Person"],"edges":[]},{"id":4365,"data":{"born":1976,"name":"Sam Worthington"},"categories":["Person"],"edges":[]}]}}
{"mode":"PLUGIN","date":"2022-04-21T12:37:40.339Z","user":"user@linkurio.us","action":"pluginRequest","params":{"pluginName":"data-table","requestMethod":"POST","requestUrl":"/plugins/table/api/runQueryByIDPlugin","requestBody":"{\"query\":{\"id\":1,\"sourceKey\":\"d80aefa8\",\"name\":\"test\",\"content\":\"match (n:TEST) return n\",\"dialect\":\"cypher\",\"description\":\"\",\"sharing\":\"private\",\"type\":\"static\",\"write\":false,\"createdAt\":\"2022-04-21T12:02:55.124Z\",\"updatedAt\":\"2022-04-21T12:02:55.124Z\",\"builtin\":false,\"right\":\"owner\",\"owner\":{\"name\":\"Unique user\",\"email\":\"user@linkurio.us\"}},\"queryParams\":{\"global\":{\"queryId\":\"1\",\"sourceKey\":\"d80aefa8\"},\"templateFields\":{}}}"},"result":""}
Each line is a JSON objects in the following format (with logResult set to true):
{
"mode": "WRITE",
"date": "2017-01-09T17:34:07.446Z",
"user": "simpleUser@example.com",
"sourceKey": "e8890b53",
"action": "createEdge",
"params": {"createInfo":{"source":4328,"target":4332,"type":"ACTED_IN","data":{"tata":"toto"}}},
"result": {"edge":{"id":5958,"data":{"foo":"bar"},"type":"BAZ","source":4328,"target":4332}}
}
The params key contains the parameters of the operation being performed. In this case, the user has run as createEdge action; params then contains the source and target IDs of the edge, as well as the edge type and a data key which holds the properties set on that edge.
result contains a JSON representation of the edge produced by the action. As can be seen, there is a substantial amount of duplication between the information in params and in data. This may not be a consideration with operations on single nodes, but with larger collections can mean that log size increases substantially. Consider the example below:
{
"mode": "READ WRITE",
"date": "2017-01-09T17:34:12.289Z",
"user": "user@linkurio.us",
"sourceKey": "e8890b53",
"action": "rawQuery",
"params": {
"query": "MATCH (n1)-[r:DIRECTED]->(n2) RETURN n1, r",
"dialect": "cypher"
},
"result":{"nodes":[{"id":4357,"data":{"born":1967,"name":"Andy Wachowski"},"categories":["Person"],"edges":[{"id":6009,"data":{},"type":"DIRECTED","source":4357,"target":4366},{"id":6010,"data":{},"type":"DIRECTED","source":4357,"target":4367},{"id":6011,"data":{},"type":"DIRECTED","source":4357,"target":4368}]},{"id":4358,"data":{"tagline":"Return to Pandora","title":"Avatar","released":1999},"categories":["Avatar","Movie"],"edges":[{"id":6034,"data":{},"type":"DIRECTED","source":4360,"target":4358}]},{"id":4360,"data":{"born":1954,"name":"James Cameron"},"categories":["Person"],"edges":[{"id":6034,"data":{},"type":"DIRECTED","source":4360,"target":4358}]},{"id":4362,"data":{"born":1965,"name":"Lana Wachowski"},"categories":["Person"],"edges":[{"id":6020,"data":{},"type":"DIRECTED","source":4362,"target":4366},{"id":6021,"data":{},"type":"DIRECTED","source":4362,"target":4367},{"id":6022,"data":{},"type":"DIRECTED","source":4362,"target":4368}]},{"id":4366,"data":{"tagline":"Welcome to the Real World","title":"The Matrix","released":1999,"nodeNoIndexProp":"foo"},"categories":["Movie","TheMatrix"],"edges":[{"id":6020,"data":{},"type":"DIRECTED","source":4362,"target":4366},{"id":6009,"data":{},"type":"DIRECTED","source":4357,"target":4366}]},{"id":4367,"data":{"tagline":"Free your mind","title":"The Matrix Reloaded","released":2003},"categories":["Movie","TheMatrixReloaded"],"edges":[{"id":6021,"data":{},"type":"DIRECTED","source":4362,"target":4367},{"id":6010,"data":{},"type":"DIRECTED","source":4357,"target":4367}]},{"id":4368,"data":{"tagline":"Everything that has a beginning has an end","title":"The Matrix Revolutions","released":2003},"categories":["Movie","TheMatrixRevolutions"],"edges":[{"id":6022,"data":{},"type":"DIRECTED","source":4362,"target":4368},{"id":6011,"data":{},"type":"DIRECTED","source":4357,"target":4368}]}]}
}
In this case, we've used a raw query to read nodes from the database without making any changes to them. The results of the query are returned to us in result, and include a substantial number of nodes and edges. To maximize the usefulness of audit trails and to minimize their footprint, it might be advisable to exclude unnecessary data, including passive queries such as these. Disabling logResult and setting mode to "w" (logging only operations which perform write operations to the database) is one strategy for accomplishing this.
Thanks to Webhooks, investigation workflow is improved by integrating the results of Linkurious Enterprise-generated alerts into a third-party case management system in real time. You can also subscribe to events to monitor usage of Linkurious Enterprise's alert system within a third-party case management tool.
Webhooks can be configured in the Global configuration page in the Webhooks section. The following configuration options are available:
enabled (default: true): This is the feature activation parameter. Its default value true enables the feature; false disables it completely.deliveryFrequency (default: "* * * * *", i.e. "once per minute"): The frequency at which
to deliver Webhook calls, expressed as a CRON expression.
Using "none" disables the delivery of Webhook calls.cleanupFrequency (default: "0 0 * * *", i.e. "once per day"): The frequency at which to
clean-up delivered Webhook calls from the database, expressed as a CRON expression.
Using "none" disables the clean-up of delivered Webhook calls.deliveryRetentionDelayMs (default: 86400000, i.e. "one day"): How long to keep delivered
Webhook calls in the database after they have been delivered, expressed in milliseconds.You can create Webhooks that subscribe to the events listed below.
To limit the number of HTTP requests made to your server, take care to subscribe only to the events you wish to use.
This event will be triggered when an alert create a new case.
{
"eventType": "newCase",
"sourceKey": "b4675b85",
"data": {
"alert": {
"id": 1,
"title": "Example alert",
"description": "This is an example"
},
"case": {
"id": 2,
"createdAt": "2024-02-26T15:07:20.333Z",
"target": {
"nodes": ["1", "2", "3"],
"edges": ["4", "5"]
},
"url": "https://example.com/alerts/1/case/2"
}
}
}
This event will be triggered when a new match is found for an existing case.
{
"eventType": "newMatch",
"sourceKey": "b4675b85",
"data": {
"alert": {
"id": 1,
"title": "Example alert",
"description": "This is an example"
},
"case": {
"id": 2,
"createdAt": "2024-02-26T15:07:20.333Z",
"updatedAt": "2024-02-27T13:00:49.020Z",
"target": {
"nodes": ["1", "2", "3"],
"edges": ["4", "5"]
},
"url": "https://example.com/alerts/1/case/2"
}
}
}
This event will be triggered when a user will change the status of a case.
{
"eventType": "caseStatusChange",
"sourceKey": "b4675b85",
"data": {
"alert": {
"id": 1,
"title": "Example alert",
"description": "This is an example"
},
"case": {
"id": 2,
"createdAt": "2024-02-26T15:07:20.333Z",
"updatedAt": "2024-02-27T14:09:30.207Z",
"status": "confirmed",
"url": "https://example.com/alerts/1/case/2"
},
"user": {
"id": 3,
"username": "john.doe",
"email": "john.doe@linkurious.com"
},
"comment": "The case is confirmed!"
}
}
You can subscribe, unsubscribe and list the configured Webhooks by using API.
Only users with the built-in Admin role can manage Webhooks.
POST /api/admin/webhooks : Create a webhook. Webhooks can subscribe to one or more events for one or many data-sources.
GET /api/admin/webhooks : Return the list of all Webhooks.
DELETE /api/admin/webhooks/:webhookId : Delete a specific webhook.
You can find all details on these API in the Rest-client documentation.
You can also install and use the Webhook Manager from the official plugins to easily use the above APIs.
To handle deliveries, you must configure a HTTP endpoint that can handle POST requests and
answer with a 2xx status response. The body of the POST request contains the payload of the
event subscribed.
You should ensure that your server uses an HTTPS connection.
In order to give the recipient endpoint the ability to authenticate hook deliveries, a secret
is attached to each webhook. This secret is used to compute the HMAC hex digest of the delivery
payload, using the SHA-256 hash function. This HMAC is attached in the X-Payload-HMAC HTTP
header (see https://nodejs.org/api/crypto.html#class-hmac).
Two specific API are available for you to test and ensure that Webhooks and your integration are correctly configured.
POST /api/admin/webhooks/:webhookId/ping : Trigger a ping pseudo-event on a given webhook (details here)
GET /api/admin/webhooks/:webhookId/deliveries : Return the list of the deliveries for a given webhook (details here)
Linkurious Enterprise can be monitored using Prometheus, which is an open source
monitoring tool.
When metrics are enabled, Linkurious Enterprise will provide an API endpoint on /metrics that can be
scrapped by Prometheus.
Metrics can be enabled and configured in linkurious/data/config/production.json.
They are found under the metrics key, which contains the following options:
enabled (default: false): Whether to enable metrics.listenPort (default: 9400): Port where the metrics server will listen for incoming requests.You will then need to configure Prometheus to scrap this endpoint. If you are not familiar with Prometheus, please refer to their "getting started" guide.
Once metrics are ingested by Prometheus, you could set up a dashboard using Grafana to visualize these metrics. An example Grafana dashboard is provided here.
This dashboard can be imported by following the official grafana documentation and using the link above.
As an illustration of the available metrics and data format, this is an example response from
the /metrics API endpoint:
# HELP process_cpu_user_seconds_total Total user CPU time spent in seconds.
# TYPE process_cpu_user_seconds_total counter
process_cpu_user_seconds_total 82.296112
# HELP process_cpu_system_seconds_total Total system CPU time spent in seconds.
# TYPE process_cpu_system_seconds_total counter
process_cpu_system_seconds_total 30.634486
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 112.930598
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1693901797
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 182259712
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 11938127872
# HELP process_heap_bytes Process heap size in bytes.
# TYPE process_heap_bytes gauge
process_heap_bytes 246452224
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 47
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1048576
# HELP nodejs_eventloop_lag_seconds Lag of event loop in seconds.
# TYPE nodejs_eventloop_lag_seconds gauge
nodejs_eventloop_lag_seconds 0
# HELP nodejs_eventloop_lag_min_seconds The minimum recorded event loop delay.
# TYPE nodejs_eventloop_lag_min_seconds gauge
nodejs_eventloop_lag_min_seconds 0.006279168
# HELP nodejs_eventloop_lag_max_seconds The maximum recorded event loop delay.
# TYPE nodejs_eventloop_lag_max_seconds gauge
nodejs_eventloop_lag_max_seconds 58.988691455
# HELP nodejs_eventloop_lag_mean_seconds The mean of the recorded event loop delays.
# TYPE nodejs_eventloop_lag_mean_seconds gauge
nodejs_eventloop_lag_mean_seconds 0.010528417698386331
# HELP nodejs_eventloop_lag_stddev_seconds The standard deviation of the recorded event loop delays.
# TYPE nodejs_eventloop_lag_stddev_seconds gauge
nodejs_eventloop_lag_stddev_seconds 0.0949220590624985
# HELP nodejs_eventloop_lag_p50_seconds The 50th percentile of the recorded event loop delays.
# TYPE nodejs_eventloop_lag_p50_seconds gauge
nodejs_eventloop_lag_p50_seconds 0.010330111
# HELP nodejs_eventloop_lag_p90_seconds The 90th percentile of the recorded event loop delays.
# TYPE nodejs_eventloop_lag_p90_seconds gauge
nodejs_eventloop_lag_p90_seconds 0.010510335
# HELP nodejs_eventloop_lag_p99_seconds The 99th percentile of the recorded event loop delays.
# TYPE nodejs_eventloop_lag_p99_seconds gauge
nodejs_eventloop_lag_p99_seconds 0.011575295
# HELP nodejs_active_resources Number of active resources that are currently keeping the event loop alive, grouped by async resource type.
# TYPE nodejs_active_resources gauge
nodejs_active_resources{type="PipeWrap"} 12
nodejs_active_resources{type="ProcessWrap"} 10
nodejs_active_resources{type="TCPServerWrap"} 2
nodejs_active_resources{type="TCPSocketWrap"} 5
nodejs_active_resources{type="Timeout"} 11
nodejs_active_resources{type="Immediate"} 1
# HELP nodejs_active_resources_total Total number of active resources.
# TYPE nodejs_active_resources_total gauge
nodejs_active_resources_total 41
# HELP nodejs_active_handles Number of active libuv handles grouped by handle type. Every handle type is C++ class name.
# TYPE nodejs_active_handles gauge
nodejs_active_handles{type="Socket"} 7
nodejs_active_handles{type="Pipe"} 10
nodejs_active_handles{type="ChildProcess"} 10
nodejs_active_handles{type="Server"} 2
# HELP nodejs_active_handles_total Total number of active handles.
# TYPE nodejs_active_handles_total gauge
nodejs_active_handles_total 29
# HELP nodejs_active_requests Number of active libuv requests grouped by request type. Every request type is C++ class name.
# TYPE nodejs_active_requests gauge
# HELP nodejs_active_requests_total Total number of active requests.
# TYPE nodejs_active_requests_total gauge
nodejs_active_requests_total 0
# HELP nodejs_heap_size_total_bytes Process heap size from Node.js in bytes.
# TYPE nodejs_heap_size_total_bytes gauge
nodejs_heap_size_total_bytes 89440256
# HELP nodejs_heap_size_used_bytes Process heap size used from Node.js in bytes.
# TYPE nodejs_heap_size_used_bytes gauge
nodejs_heap_size_used_bytes 81652264
# HELP nodejs_external_memory_bytes Node.js external memory size in bytes.
# TYPE nodejs_external_memory_bytes gauge
nodejs_external_memory_bytes 5334109
# HELP nodejs_heap_space_size_total_bytes Process heap space size total from Node.js in bytes.
# TYPE nodejs_heap_space_size_total_bytes gauge
nodejs_heap_space_size_total_bytes{space="read_only"} 0
nodejs_heap_space_size_total_bytes{space="old"} 62533632
nodejs_heap_space_size_total_bytes{space="code"} 7024640
nodejs_heap_space_size_total_bytes{space="map"} 2891776
nodejs_heap_space_size_total_bytes{space="large_object"} 14950400
nodejs_heap_space_size_total_bytes{space="code_large_object"} 991232
nodejs_heap_space_size_total_bytes{space="new_large_object"} 0
nodejs_heap_space_size_total_bytes{space="new"} 1048576
# HELP nodejs_heap_space_size_used_bytes Process heap space size used from Node.js in bytes.
# TYPE nodejs_heap_space_size_used_bytes gauge
nodejs_heap_space_size_used_bytes{space="read_only"} 0
nodejs_heap_space_size_used_bytes{space="old"} 57058280
nodejs_heap_space_size_used_bytes{space="code"} 5979200
nodejs_heap_space_size_used_bytes{space="map"} 2025864
nodejs_heap_space_size_used_bytes{space="large_object"} 14768216
nodejs_heap_space_size_used_bytes{space="code_large_object"} 972544
nodejs_heap_space_size_used_bytes{space="new_large_object"} 0
nodejs_heap_space_size_used_bytes{space="new"} 861432
# HELP nodejs_heap_space_size_available_bytes Process heap space size available from Node.js in bytes.
# TYPE nodejs_heap_space_size_available_bytes gauge
nodejs_heap_space_size_available_bytes{space="read_only"} 0
nodejs_heap_space_size_available_bytes{space="old"} 4319168
nodejs_heap_space_size_available_bytes{space="code"} 603072
nodejs_heap_space_size_available_bytes{space="map"} 813112
nodejs_heap_space_size_available_bytes{space="large_object"} 0
nodejs_heap_space_size_available_bytes{space="code_large_object"} 0
nodejs_heap_space_size_available_bytes{space="new_large_object"} 1030976
nodejs_heap_space_size_available_bytes{space="new"} 169544
# HELP nodejs_version_info Node.js version info.
# TYPE nodejs_version_info gauge
nodejs_version_info{version="v18.16.1",major="18",minor="16",patch="1"} 1
# HELP nodejs_gc_duration_seconds Garbage collection duration by kind, one of major, minor, incremental or weakcb.
# TYPE nodejs_gc_duration_seconds histogram
nodejs_gc_duration_seconds_bucket{le="0.001",kind="minor"} 145
nodejs_gc_duration_seconds_bucket{le="0.01",kind="minor"} 553
nodejs_gc_duration_seconds_bucket{le="0.1",kind="minor"} 560
nodejs_gc_duration_seconds_bucket{le="1",kind="minor"} 560
nodejs_gc_duration_seconds_bucket{le="2",kind="minor"} 560
nodejs_gc_duration_seconds_bucket{le="5",kind="minor"} 560
nodejs_gc_duration_seconds_bucket{le="+Inf",kind="minor"} 560
nodejs_gc_duration_seconds_sum{kind="minor"} 0.9594195639983442
nodejs_gc_duration_seconds_count{kind="minor"} 560
nodejs_gc_duration_seconds_bucket{le="0.001",kind="incremental"} 28
nodejs_gc_duration_seconds_bucket{le="0.01",kind="incremental"} 34
nodejs_gc_duration_seconds_bucket{le="0.1",kind="incremental"} 35
nodejs_gc_duration_seconds_bucket{le="1",kind="incremental"} 35
nodejs_gc_duration_seconds_bucket{le="2",kind="incremental"} 35
nodejs_gc_duration_seconds_bucket{le="5",kind="incremental"} 35
nodejs_gc_duration_seconds_bucket{le="+Inf",kind="incremental"} 35
nodejs_gc_duration_seconds_sum{kind="incremental"} 0.027089656999247376
nodejs_gc_duration_seconds_count{kind="incremental"} 35
nodejs_gc_duration_seconds_bucket{le="0.001",kind="major"} 0
nodejs_gc_duration_seconds_bucket{le="0.01",kind="major"} 4
nodejs_gc_duration_seconds_bucket{le="0.1",kind="major"} 21
nodejs_gc_duration_seconds_bucket{le="1",kind="major"} 21
nodejs_gc_duration_seconds_bucket{le="2",kind="major"} 21
nodejs_gc_duration_seconds_bucket{le="5",kind="major"} 21
nodejs_gc_duration_seconds_bucket{le="+Inf",kind="major"} 21
nodejs_gc_duration_seconds_sum{kind="major"} 0.42418163500053924
nodejs_gc_duration_seconds_count{kind="major"} 21
# HELP http_request_duration_seconds duration histogram of http responses labeled with: status_code, method, path
# TYPE http_request_duration_seconds histogram
http_request_duration_seconds_bucket{le="0.003",status_code="304",method="GET",path="/"} 0
http_request_duration_seconds_bucket{le="0.03",status_code="304",method="GET",path="/"} 3
http_request_duration_seconds_bucket{le="0.1",status_code="304",method="GET",path="/"} 3
http_request_duration_seconds_bucket{le="0.3",status_code="304",method="GET",path="/"} 4
http_request_duration_seconds_bucket{le="1.5",status_code="304",method="GET",path="/"} 4
http_request_duration_seconds_bucket{le="10",status_code="304",method="GET",path="/"} 4
http_request_duration_seconds_bucket{le="+Inf",status_code="304",method="GET",path="/"} 4
# HELP up 1 = up, 0 = not up
# TYPE up gauge
up 1
A plugin is an extension that adds functionality to Linkurious Enterprise.
Customers and third party developers can easily create their own plugins using our detailed Plugins Development Guide.
Official plugins are plugins built and maintained by the Linkurious team. They are distributed with Linkurious Enterprise by default.
config-migration): Migrate settings (e.g. queries, alerts, etc.) from one Linkurious Enterprise
instance to another. Ideal to synchronize a pre-production and production instance.data-table): Display graph-query results as a table.query-ai): Translate natural language questions into Cypher graph queries tailored for your graph.third-party-data): Enrich companies and people in your graph using
data from external data-vendor APIs.webhook-manager): Add, delete, and test webhooks in Linkurious Enterprise.Additionnally, the following legacy plugins are distributed with Linkurious Enterprise. They are deprecated and will be removed in future versions of Linkurious Enterprise. Please use the corresponding built-in functionality instead.
csv-importer): Import data into your graph quickly from a CSV file.plugin-manager): Install and manage plugins in Linkurious Enterprise.If you want the system to automatically install official plugins, you can set the LKE_PLUGINS
environment variable as an array of strings for every
plugin to be deployed. The valid strings are available in the list of official plugins.
If you are using Docker, the environment variable needs to be set for the container.
The version of each plugin that will be installed depends on your Linkurious Enterprise version. Be sure to keep the system up to date to have the latest version of the plugins installed.
First obtain the .lke file of the plugin you need to install. You can download official plugins from the "Releases" section of the plugin page.
The plugin may be installed throught the Linkurious Enterprise user interface:
LKE_PLUGINS_ENABLE_UPLOAD
environment variable to trueAdmin -> Plugins manager. This page is restricted to admin accountsUpload your own plugin banner at the top of the page and select the .lke file.In case you need to perform a manual installation, you can proceed as follows:
Make sure to have write access to the Linkurious Enterprise installation folder as well as an application admin account.
.lke file to the following path <linkurious>/data/pluginsAdmin -> Global configurationPlugins settings fieldPlugins settings sectionAdmin -> Plugins managerConfigure pluginYou can configure multiple instances of a single plugin by adding a new JSON object to the plugin's array.
Configuration keys supported by all the plugins:
| Key | Type | Description | Example |
|---|---|---|---|
basePath |
string (optional) | A base path on which the plugin will be mounted. Defaults to the plugin name defined in the manifest. | "my-path" |
debugPort |
number (optional) | A debug port on which to attach a debugger for the plugin NodeJS process. If not specified, the plugin won't be started in debug mode. | 9230 |
The following example will deploy:
my-plugin that will be accessible by its default path /plugins/my-plugin (the plugin name)my-second-plugin that will be accessible from the custom path /plugins/my-pathmy-second-plugin that will be accessible from the custom path /plugins/my-other-path{
"my-plugin": [
],
"my-second-plugin": [
{
"basePath": "my-path"
},
{
"basePath": "my-other-path"
}
]
}
To completely uninstall a plugin from the system (i.e. all the deployed instances), you can remove the file manually added through the manual installation.
After the above procedure, any configuration for to the removed plugin will be ignored by the system. If you are not foreseeing to reuse the plugin in the future, you may want to clear the related plugin's configurations to only keep active ones.
If you have deployed several instances of a plugin and want to uninstall some of them, edit the plugins configuration and remove the entries for the instances you want to remove.
Once installed and configured, any Linkurious Enterprise authenticated user can use the plugin. Additional restrictions may be imposed by the plugin itself.
Compatibility is mentioned on the download page of each plugin. You can easily identify that by looking at the minimal and maximal supported Linkurious Enterprise version.
If you are facing problems with a plugin follow the next steps:
If you are still facing problems, please get in touch with support while keeping this in mind:
Query AI is a Linkurious Enterprise plugin that allows analysts to query the graph using natural language.
Example:
User: Show me bank accounts owned by more than one person
Query AI:
MATCH (p:PERSON)-[r:HAS_BANK_ACCOUNT]->(b:BANK_ACCOUNT) WITH b, COUNT(p) AS personCount WHERE personCount > 1 RETURN b
The feature is currently available for Neo4j and Memgraph.
The Query AI plugin is installed and enabled by default.
To set up the plugin, you must be logged in as an administrator in Linkurious Enterprise and follow the steps below to configure the LLM model and create a custom action for users to access the plugin.
To set up the LLM model:
/plugins/query-ai/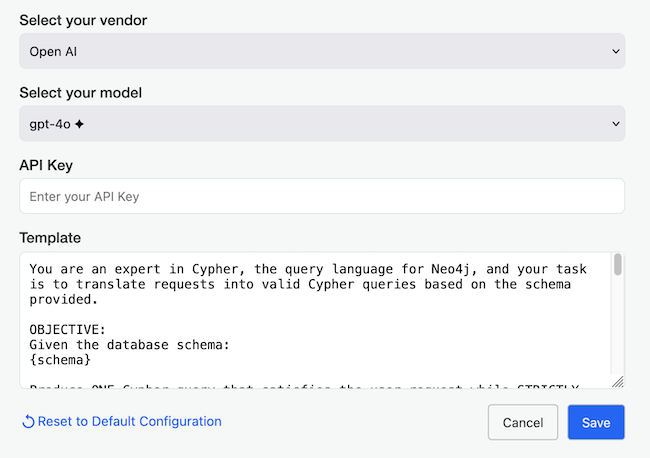
To configure a custom actions that allows users to open the plugin:
{{baseURL}}plugins/query-ai/?sourceKey={{sourceKey}}#linkurious-modal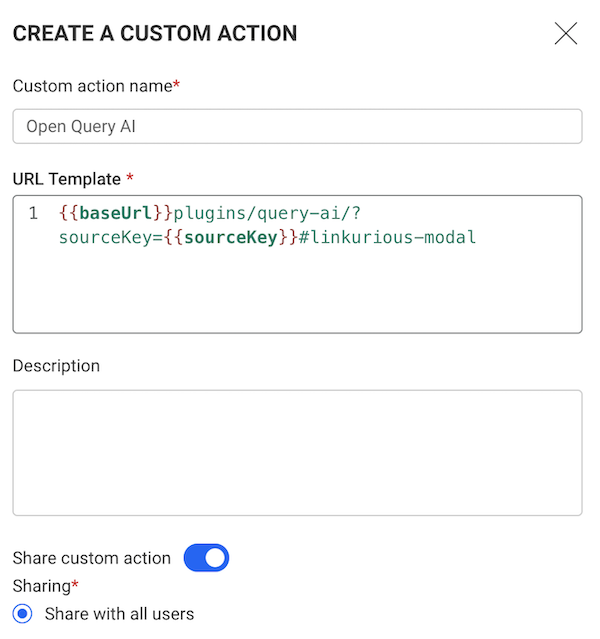
Only administrators can edit the plugin's configuration, which includes seeing and changing the following values: LLM vendor, LLM model, LLM API key, and system prompt.
The plugin never shares your graph data (i.e., the content of individual nodes or edges) with the LLM. The plugin only shares your graph schema (i.e., the list of node-categories, edge-types, and associated property names) with the LLM, in order to generate valid queries for your graph.
When running a graph query in the Query AI plugin, the same security mechanism is used as for running a query in the rest of Linkurious Enterprise, and the access-rights of the current user are applied. There is nothing that can be done using this plugin that cannot be done manually by the current user using the regular query interface:
Using query-string parameters, you can create visualizations on the go to integrate Linkurious Enterprise in your workflow.
To open a visualization pre-filled with data, you need to use the /workspace/new URL.
Then, by adding query-string parameters, you can fill your visualization with a specific nodes & edges:
e.g.
http://localhost:3000/workspace/new?populate=nodeId&item_id=45869This URL will open a visualization containing the node with ID
45869.
Please find below the list of supported parameters.
| Parameter | Description | Accepted values |
|---|---|---|
key |
Key of the data-source. | A valid source key (default is the first connected data source) |
populate |
Describes how the sandbox should be populated. | visualizationId, expandNodeId, nodeId, edgeId, queryId, searchNodes, searchEdges, pattern, caseId |
item_id |
ID of the node, edge, query, pattern or visualization to load (required when populate is one of visualizationId, queryId, nodeId, edgeId, expandNodeId). |
The ID of the resource to load |
case_id |
ID of alert case to load (required when populate is caseId). |
An existing alert case ID |
search_query |
Search query to search for nodes or edges (required when populate is one of searchNodes or searchEdges). |
Any string of characters |
search_fuzziness |
Search query fuzziness (when populate is one of searchNodes or searchEdges). |
Any number between 0 and 1 (default is 0.1) |
pattern_query |
Pattern query to match nodes and/or edges (required when populate is pattern). |
Any valid Cypher or Gremlin query (depending of the datasource query language) |
pattern_dialect |
Query dialect to use (required when populate is pattern). |
cypher or gremlin |
query_parameters |
Template query parameters (required when populate is queryId and the query is a template). |
Any valid template query parameters in JSON format (e.g. {"param1": "abc", "param2": 123} |
geo_mode |
Whether the sandbox should be opened with geo mode activated | true or false (default is false) |
You can also open a visualization by using the /workspace/:id URL.
You can use specific parameters to customize it.
e.g.
http://localhost:3000/workspace/5This URL will open the visualization with ID
5.
| Parameter | Description | Accepted values |
|---|---|---|
id |
ID of the visualization. | An existing visualization ID |
geo_mode |
Whether the visualization should be opened with geo mode activated | true or false (default is false) |