Welcome to the user manual of Linkurious Enterprise!
We will be exploring the features Linkurious Enterprise offers. Each feature is throroughly explained. Examples and tips on how to use Linkurious Enterprise are given in order to help you make the most out of it.
The first three chapters, Spaces, First Visualization and Manage Visualizations will teach you the basics to successfully create and manage your visualizations.
The following chapters will walk you through the different features Linkurious Enterprise provides and explain how to use them in order to successfully visualize your graphs and extract the necessary knowledge from your investigations.
Just like our software, this guide assumes no prior knowledge of graph visualization techniques. By reading the user guide thoroughly, you will be able to use all the tools Linkurious Enterprise provides efficiently in order to find valuable connections and structural patterns in your data, improve your graph database and communicate your findings!
Depending on your license and your deployment model, you will have access to different features. A complete comparison of the features available in Linkurious Enterprise Cloud and the Linkurious Enterprise on Premise can be found on our pricing page, which provides an overview of the features available in Linkurious Enterprise depending on your deployment model.
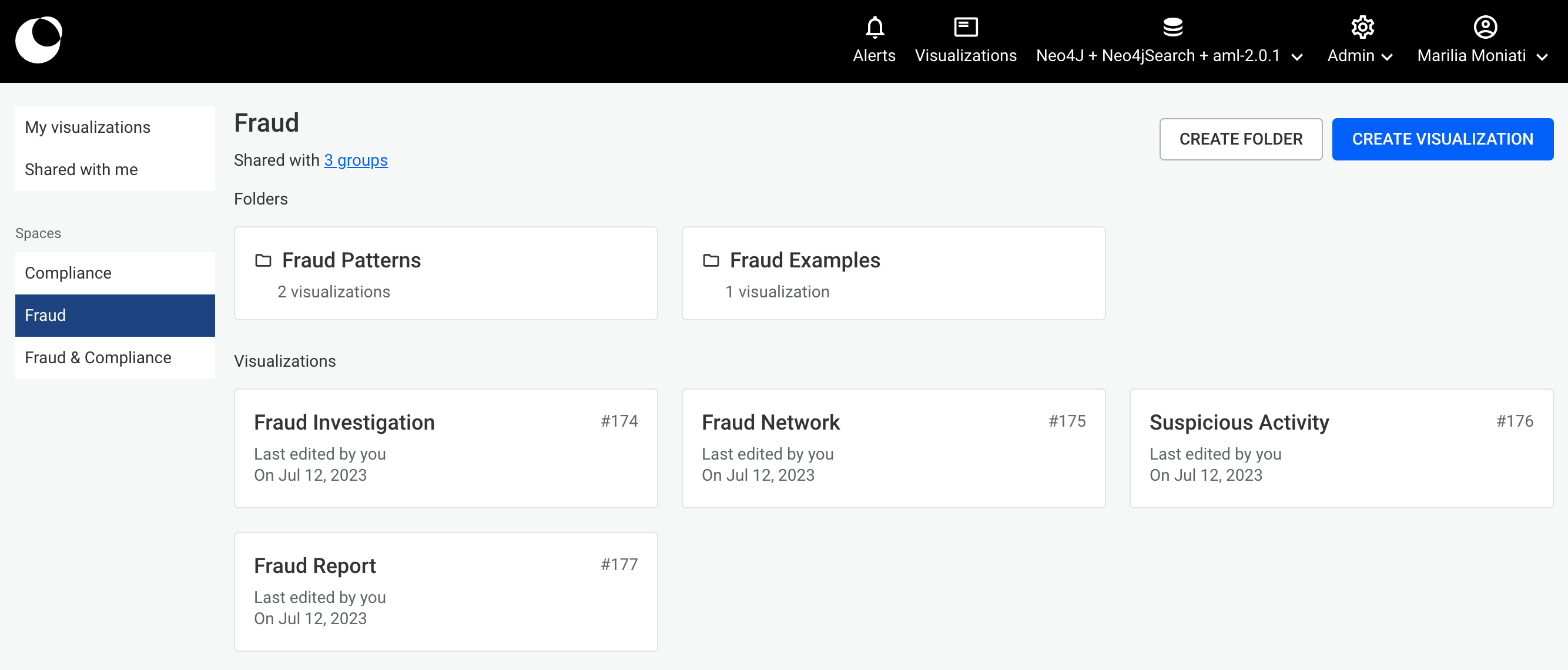
In this chapter, we look into spaces and what you can do with them. Spaces are containers of visualizations shared with user groups. A space can be shared with one or multiple groups. Users who are part of the groups the space is shared with can access and edit all the space’s contents.
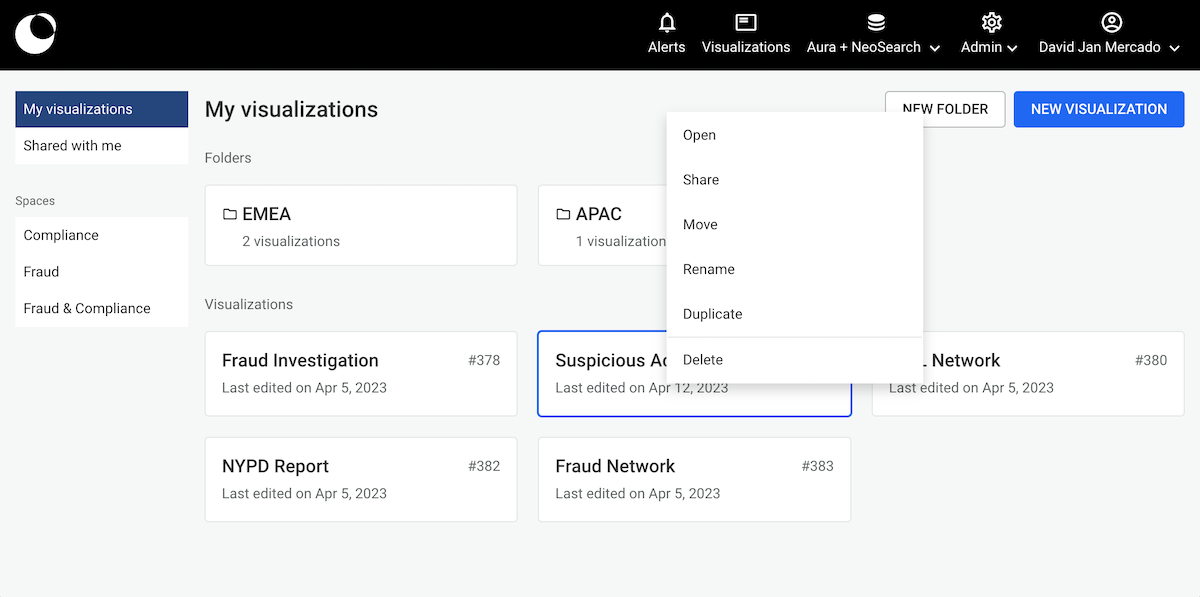
As shown below, you can see the list of spaces you have access to on the left section of the page. On the right, you can see the folders and visualizations that are created in the currently selected space. To ensure a common understanding of who has access to a space and its content, below the space's title information on the groups the space is shared with is shown. When clicked, a detailed list of the users belonging to each group is displayed.
Users who can access a specific space can do the following by right-clicking on the visualization tile:
Creating a visualization
Opening and editing a visualization
Moving a visualization
Editing informations of a visualization
Duplicating a visualization
Deleting a visualization
IMPORTANT
Users who have access to a space can edit all visualizations stored in that space (i.e. they can open and edit, move, rename, duplicate, and delete these). However, only one user can edit the visualization at a time while other users who open it will be in View-only mode. See Managing visualizations to know more.
Folders can be created in any space to organize visualizations. Users can do the following:
Creating a folder
Opening a folder
Moving a folder
Renaming a folder
Deleting a folder
Users with permission to create and edit nodes and edges can import new data using the CSV import functionality.
To start importing data, go to the Dashboard and click Import data from CSV.
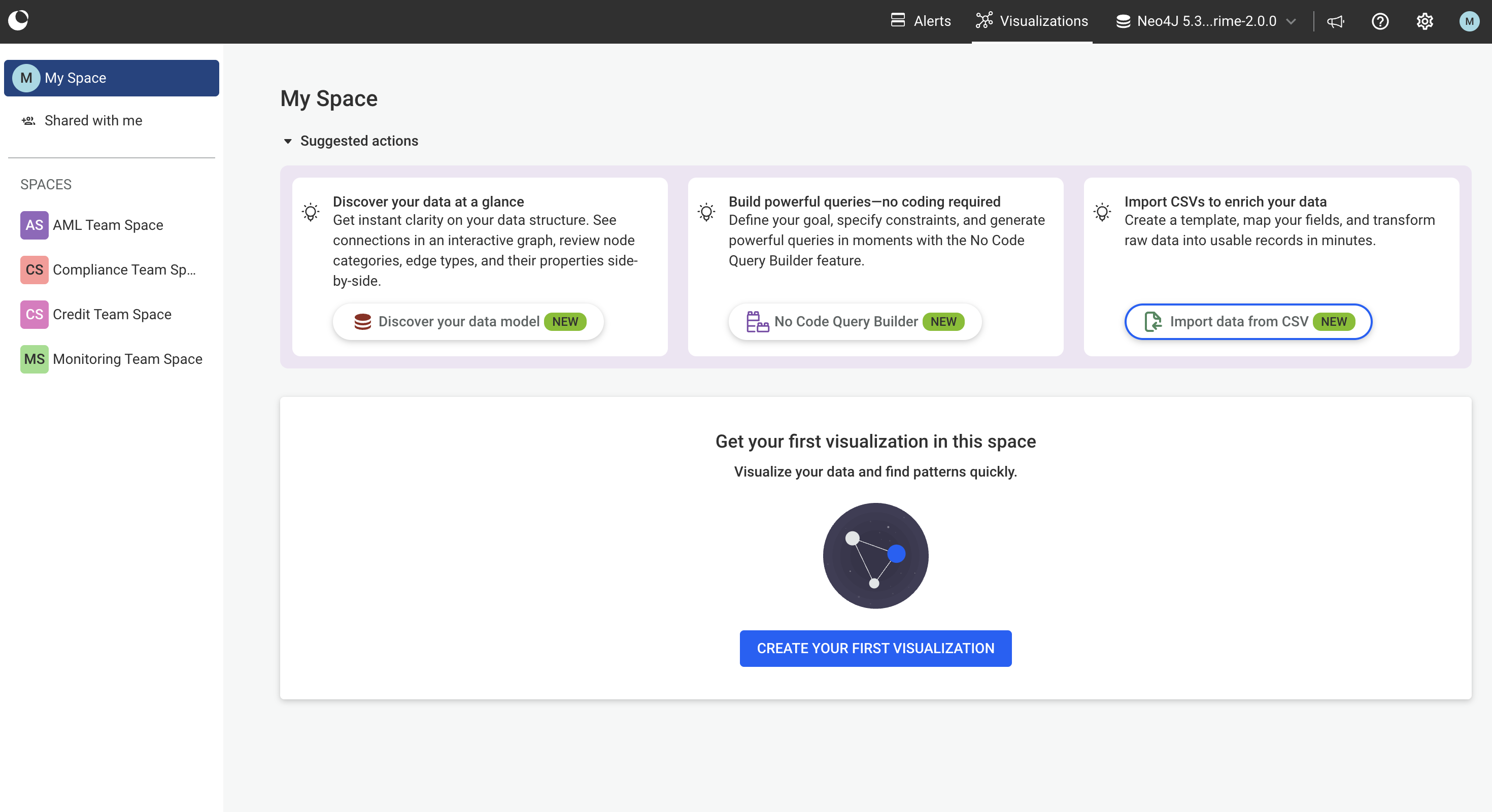
Choose one of the available CSV import templates.
Templates define:
Only templates shared with you (or available to all users) will appear in the list.
After selecting a template, click Next.
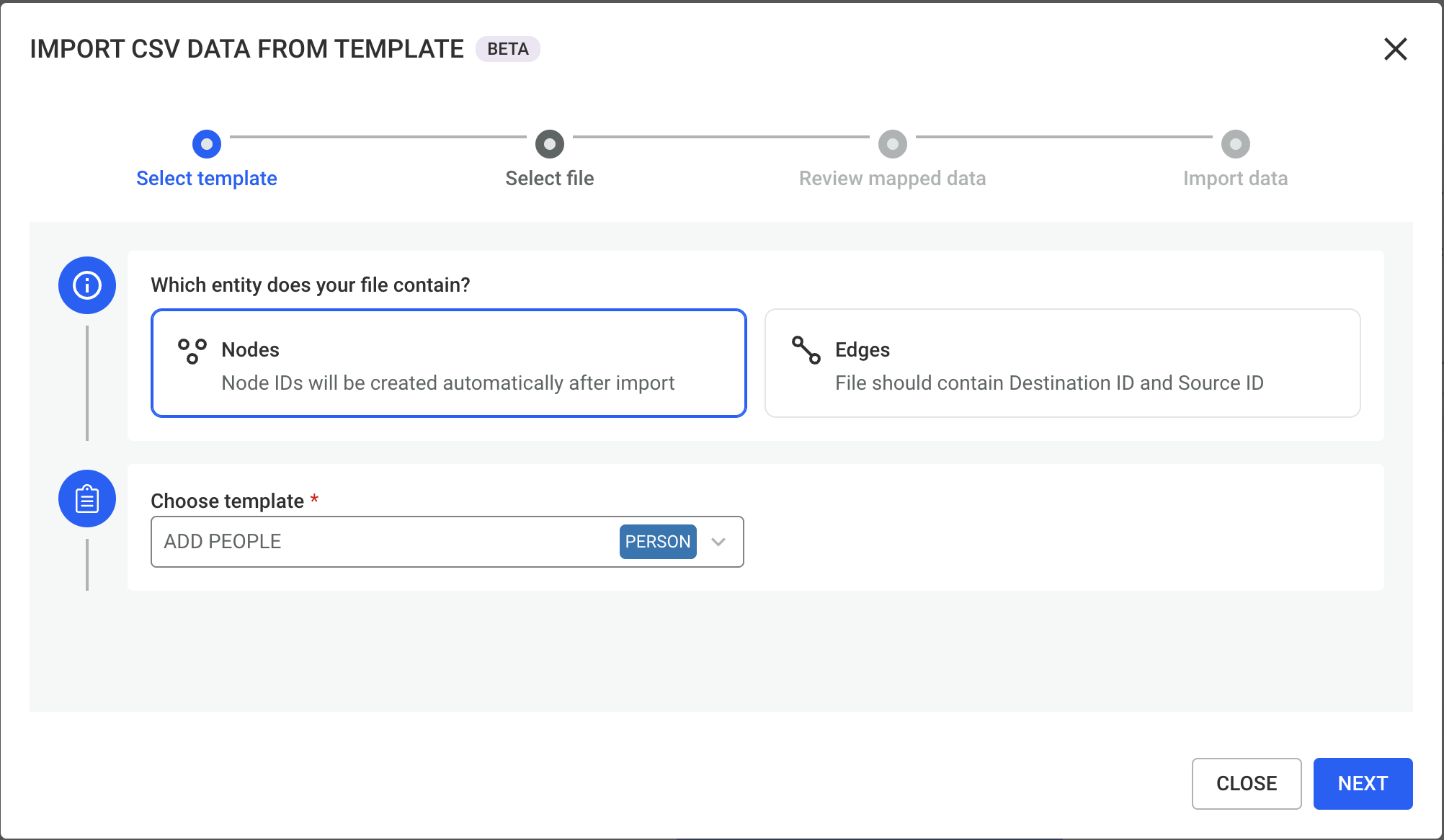
Upload the CSV file you want to import.
Make sure:
Once uploaded, a preview of the file will be displayed so you can verify that the data is correctly parsed.
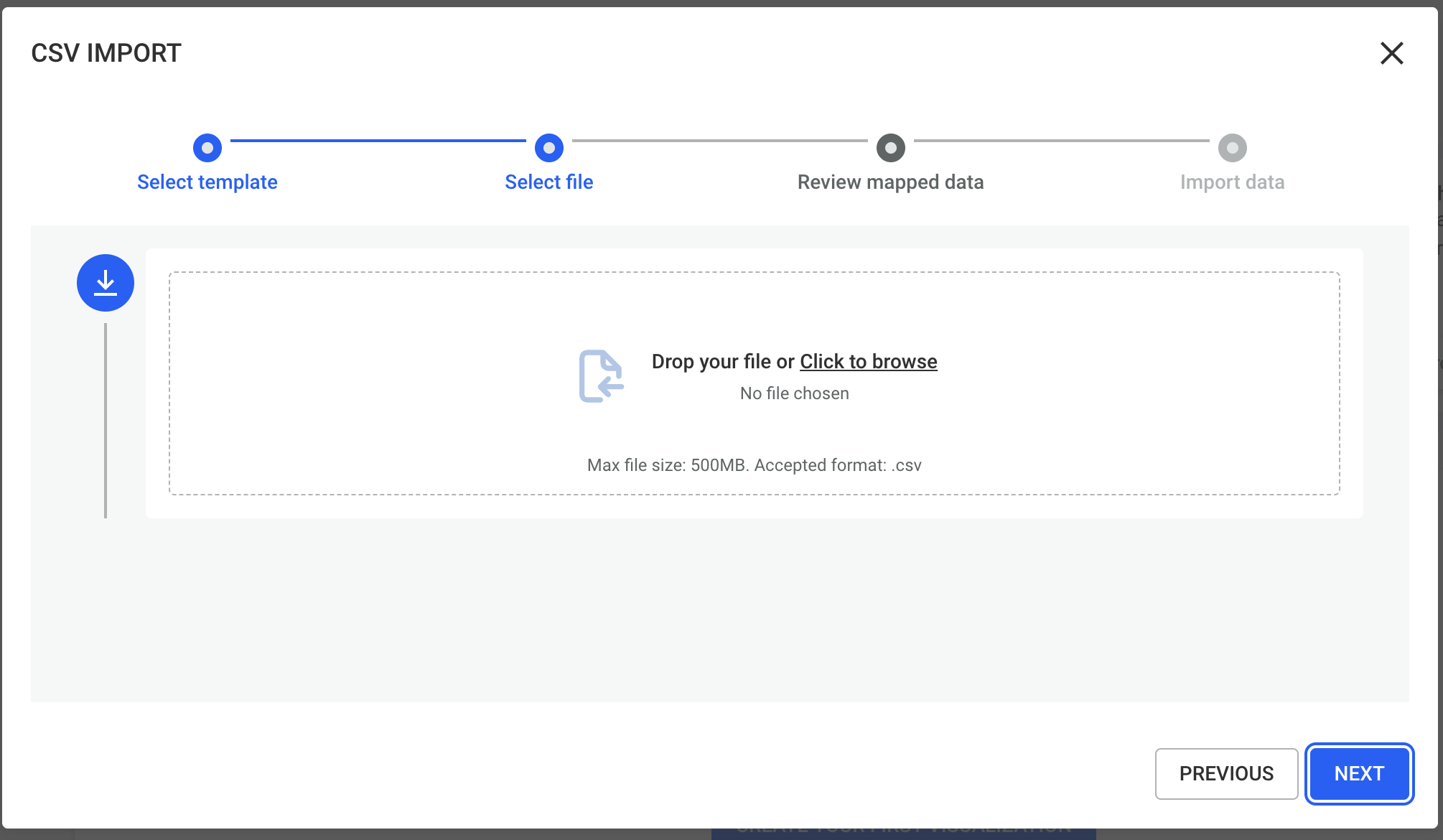
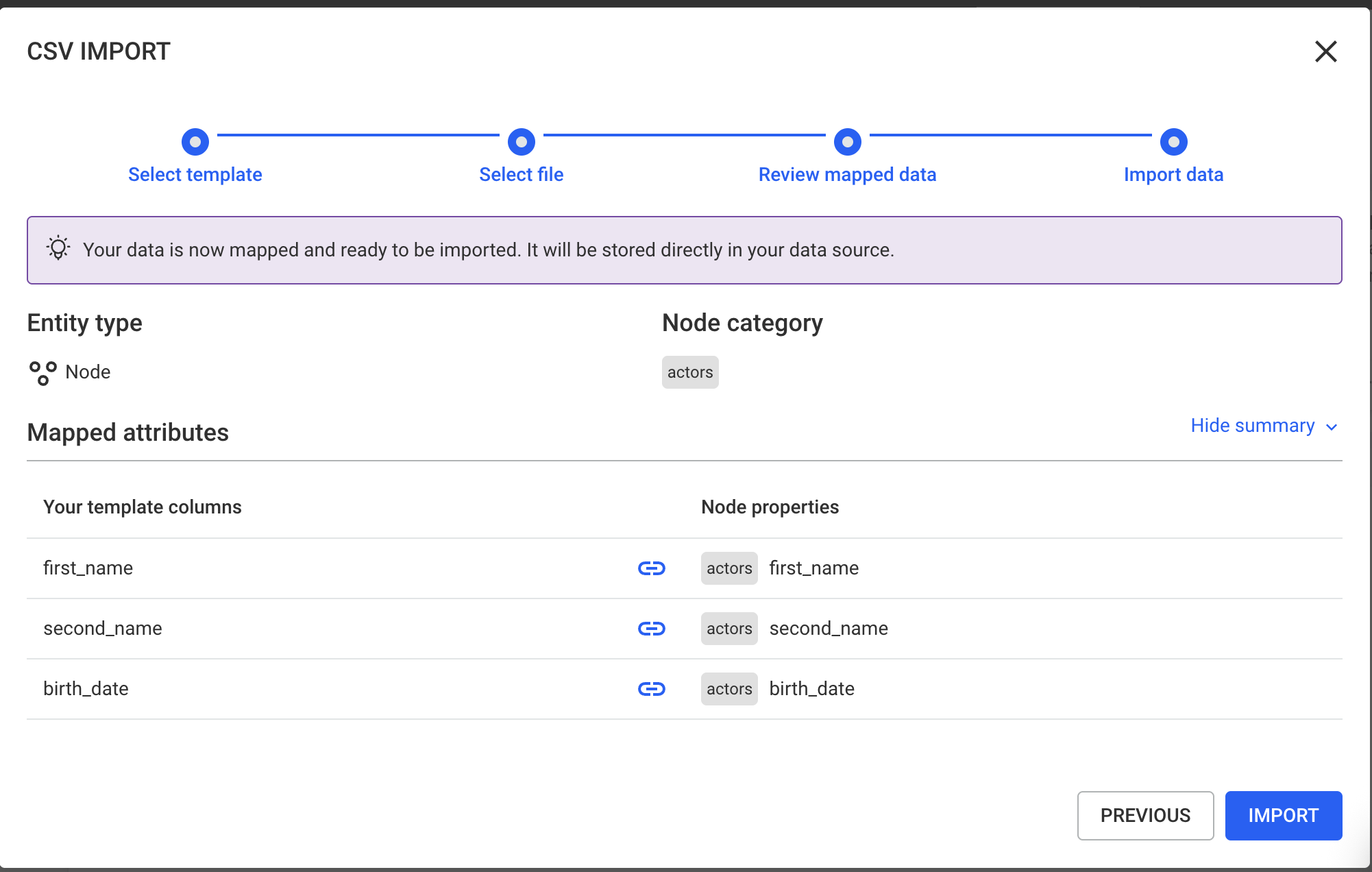
In this step, you can review how your CSV columns are mapped based on the selected template.
Verify that:
For edge imports:
Make sure that the source and target node identifiers are correctly mapped. The values in your CSV must match existing node identifiers in the graph; otherwise, the edges cannot be created.
If everything looks correct, proceed to the next step.
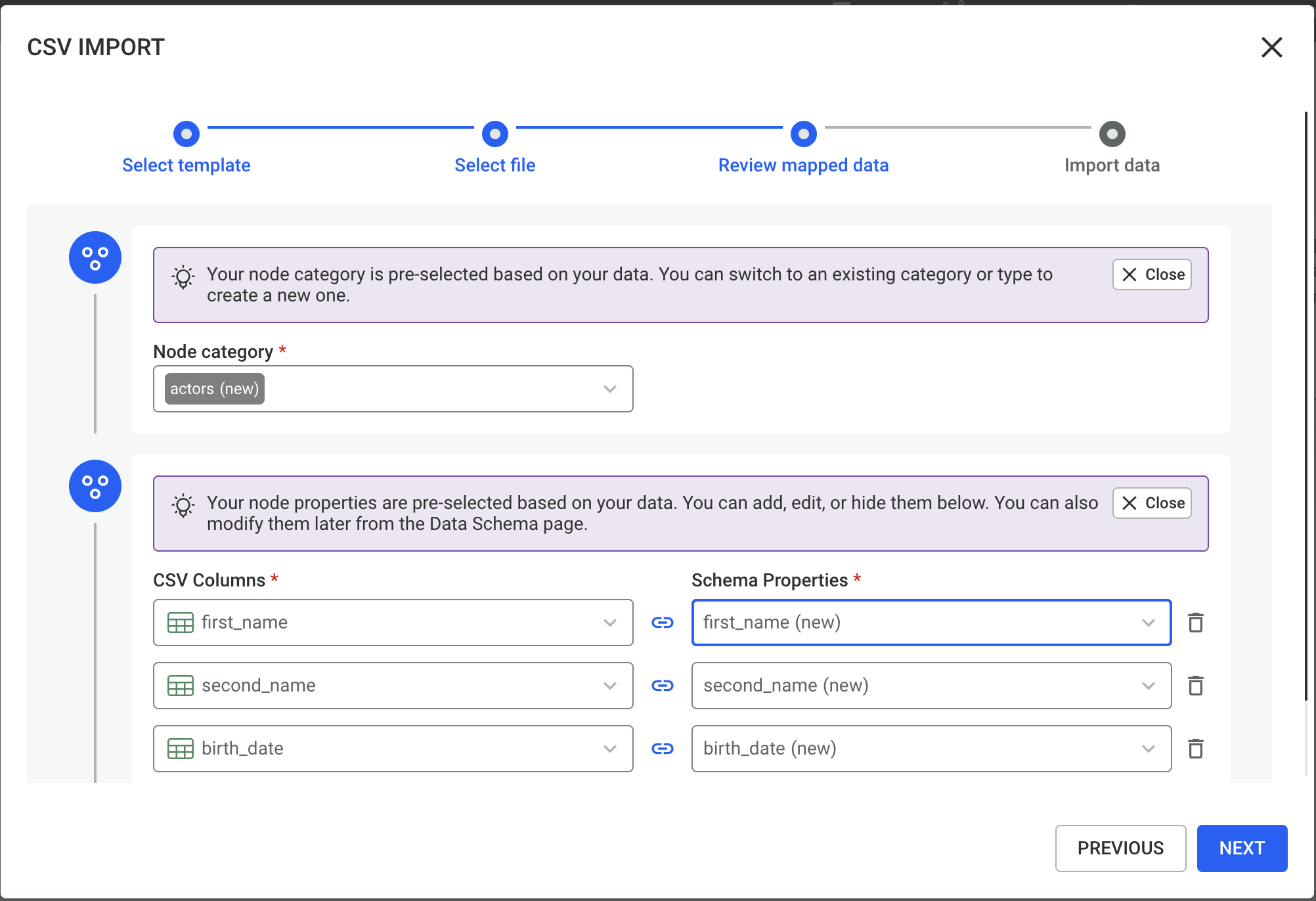
Click Import to start the import process.
Once the import begins:
After completion, the newly imported nodes or edges will be available in your graph.
In this chapter, we will learn the basics of how to explore and visualize a graph database with Linkurious Enterprise.
If you want to be guided on how to use Linkurious Enterprise end user features, you can enroll to our academy and get certified for free by following this link : Linkurious Enterprise Academy
Two courses are publicly available:
Here is a look at the interface of Linkurious Enterprise.
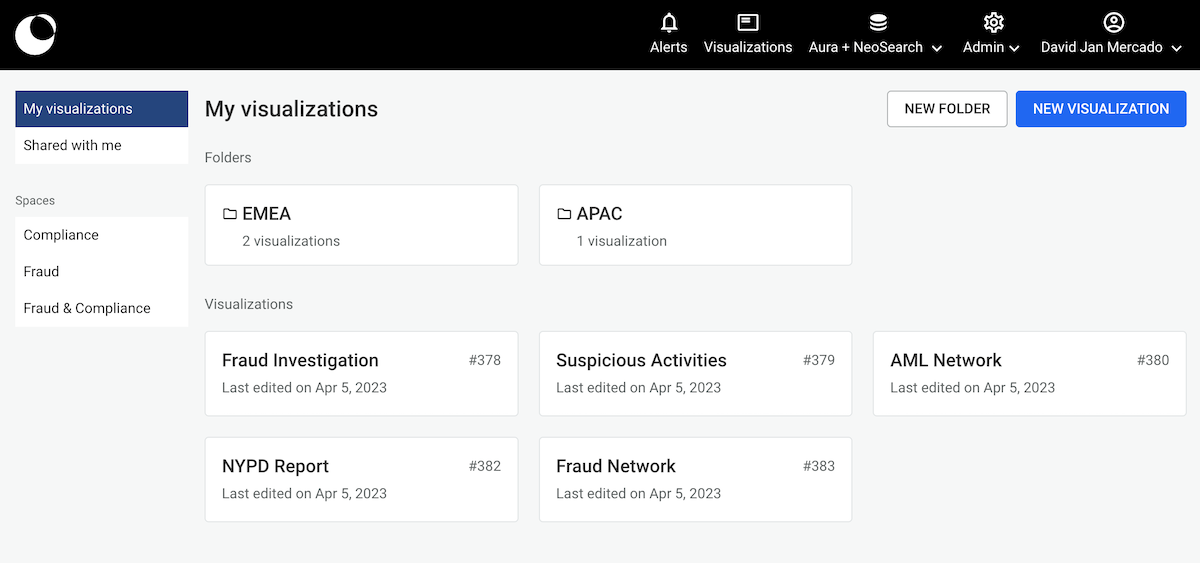
The dashboard lists the visualizations created by the user and those that have been created in a space. The following image is a typical dashboard of Linkurious Enterprise.
The workspace allows you to explore the graph database and represent it visualization as a node-link diagram.
You can start exploring the data by creating a new visualization. Click "Create Visualization" in the top right hand corner.
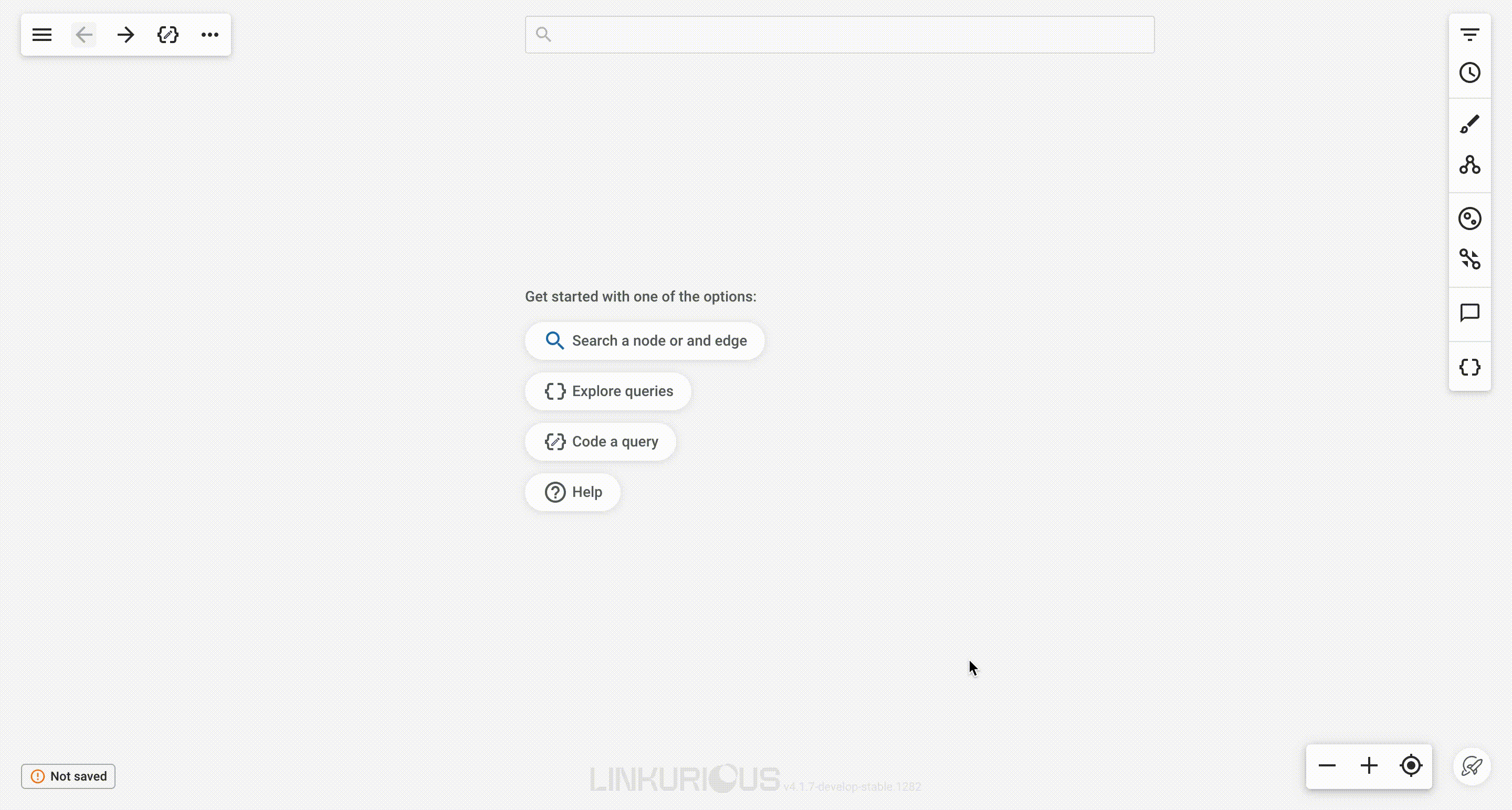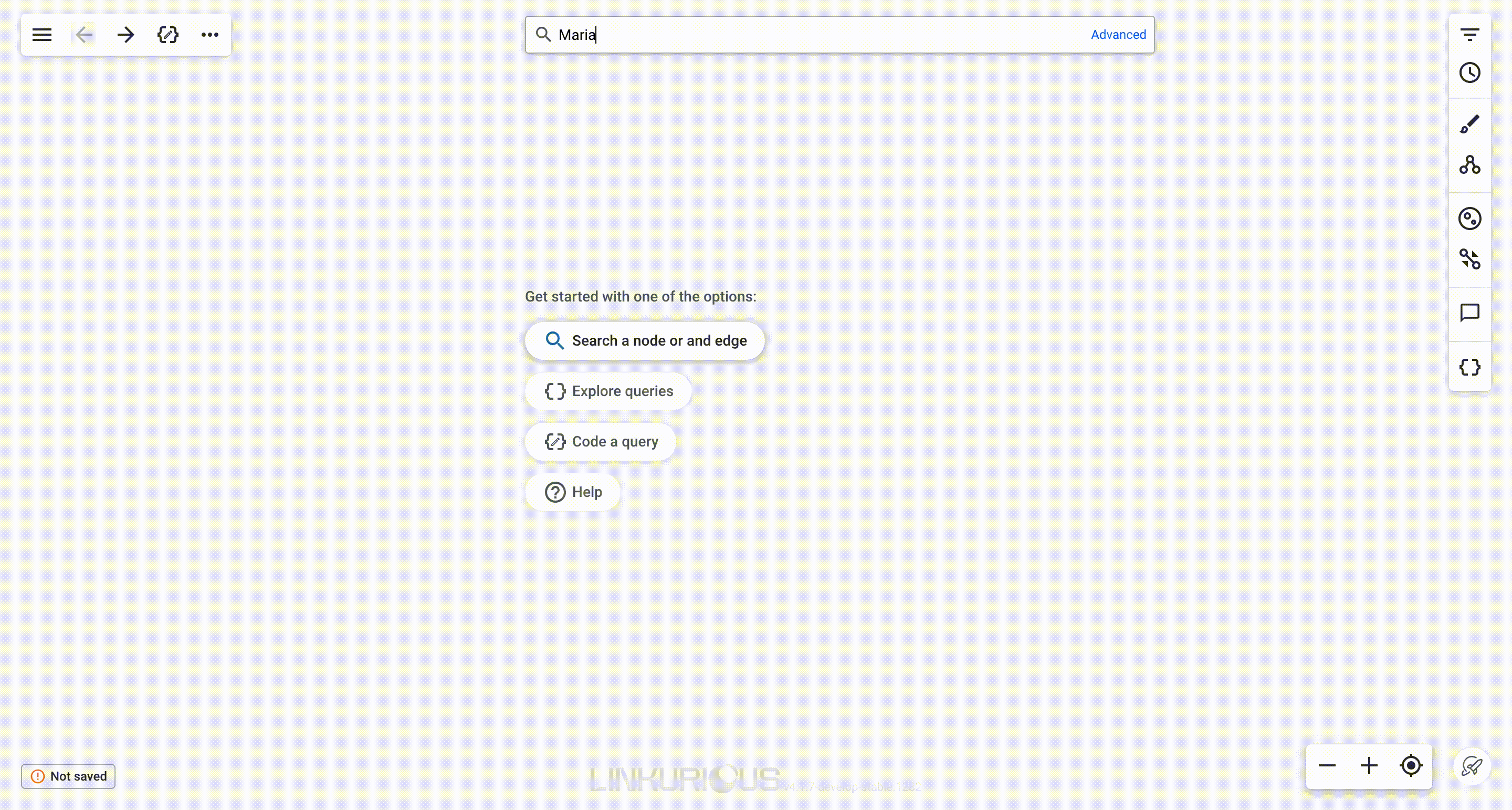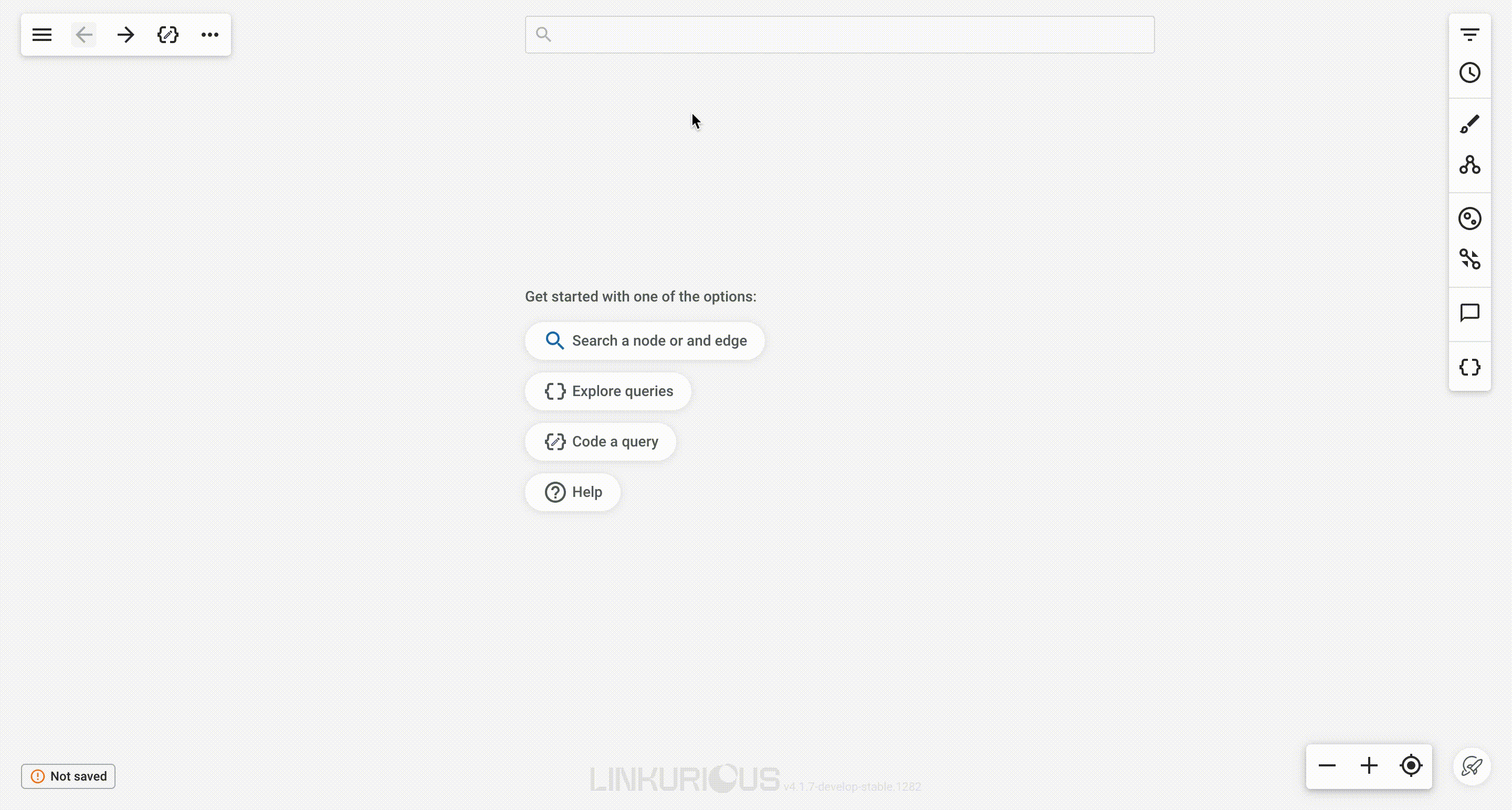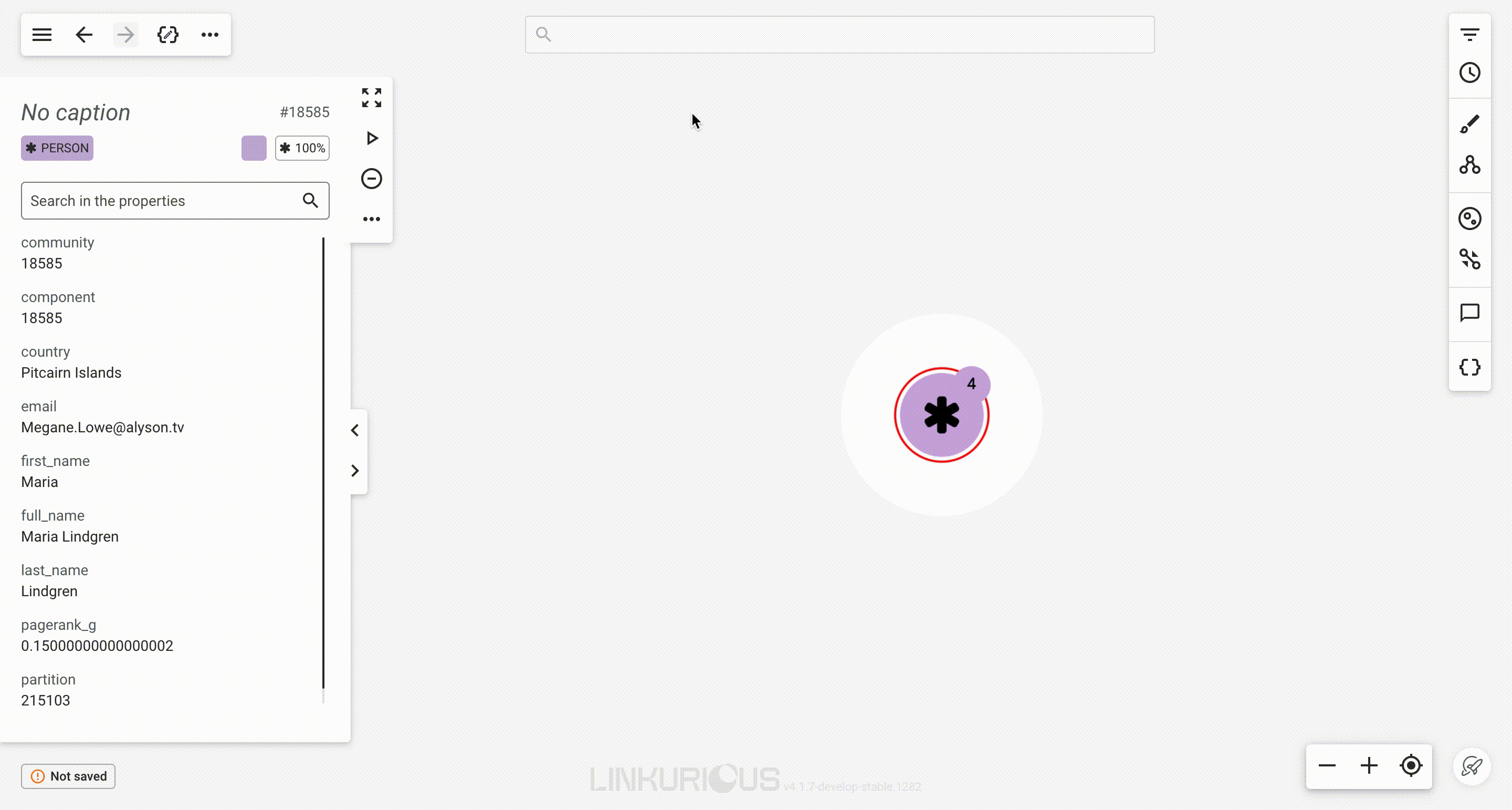
Upon entering the visualization's workspace, you can see the quick actions menu (as shown in the screenshot below) which will guide you on key steps to take in order to start your investigation. You will be one click away from searching for nodes, exploring and running existing queries, coding a new query, building a new query using the No Code Query Builder, discovering your data model or accessing Linkurious Enterprise documentation.
You can discover your data model directly from the quick access menu.
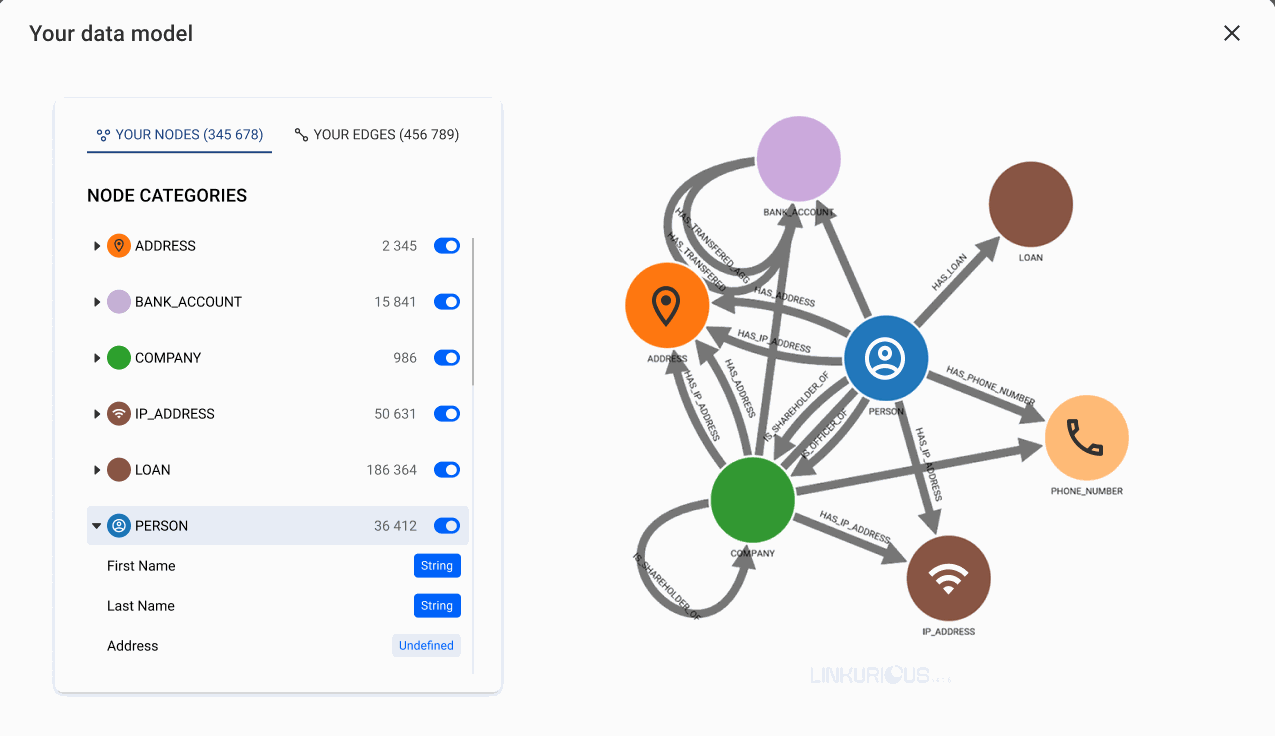
As shown above, this view gives you information on all available node categories, edge types and how they're connected. Moreover, you can view the properties of each node category and edge type as well as their data type. This improves upfront understanding of your data which helps making investigations more efficient.
You can now search for nodes and edges.

For example, if you want to look for the person Maria Lindgren, you can simply type the name of any property associated with this node.
Here, we type Maria, which is the first name of the person.
Several results which contain the word Maria in one of their
properties are returned. We can click on the one that we're interested in. Upon selection, the node will appear in the workspace.
You can always access the quick actions menu from the workspace.
In this section we will cover how to inspect detailed properties of your data, from single data points to relationships, and how to compare several data points from a table view.
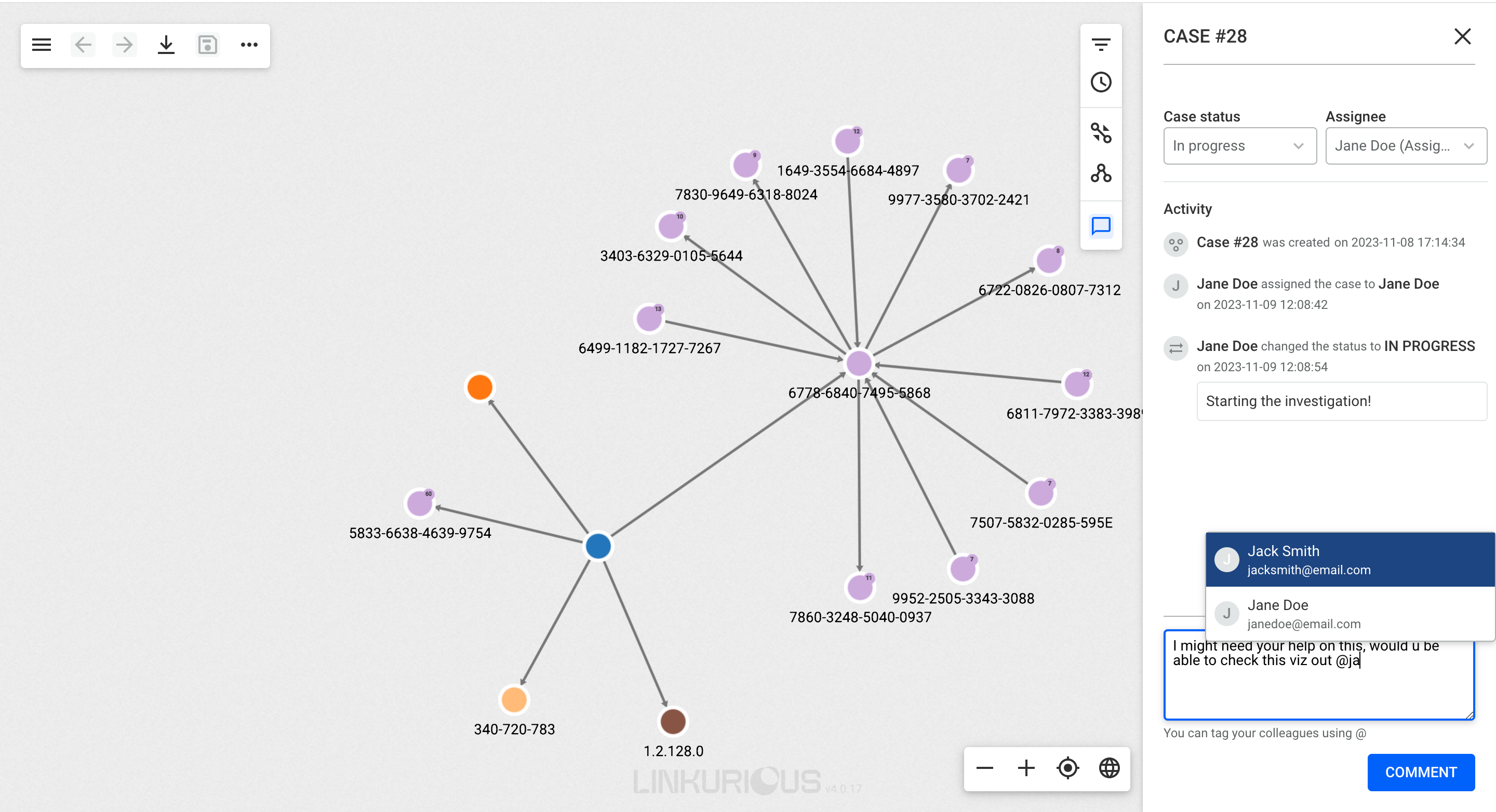
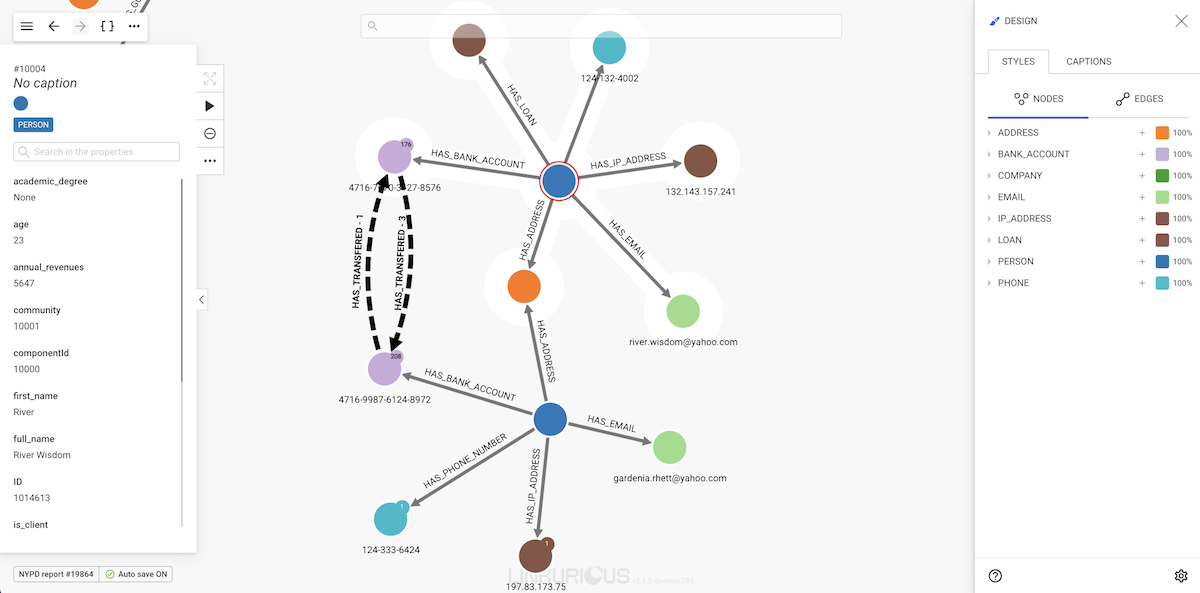
Once you've added some nodes and/or edges to your visualisation, you can select one of them and click on "Open selection panel" icon at the top left side of your screen to see its properties and data. By default, the property panel remains closed on selection to give you more space to explore the graph.
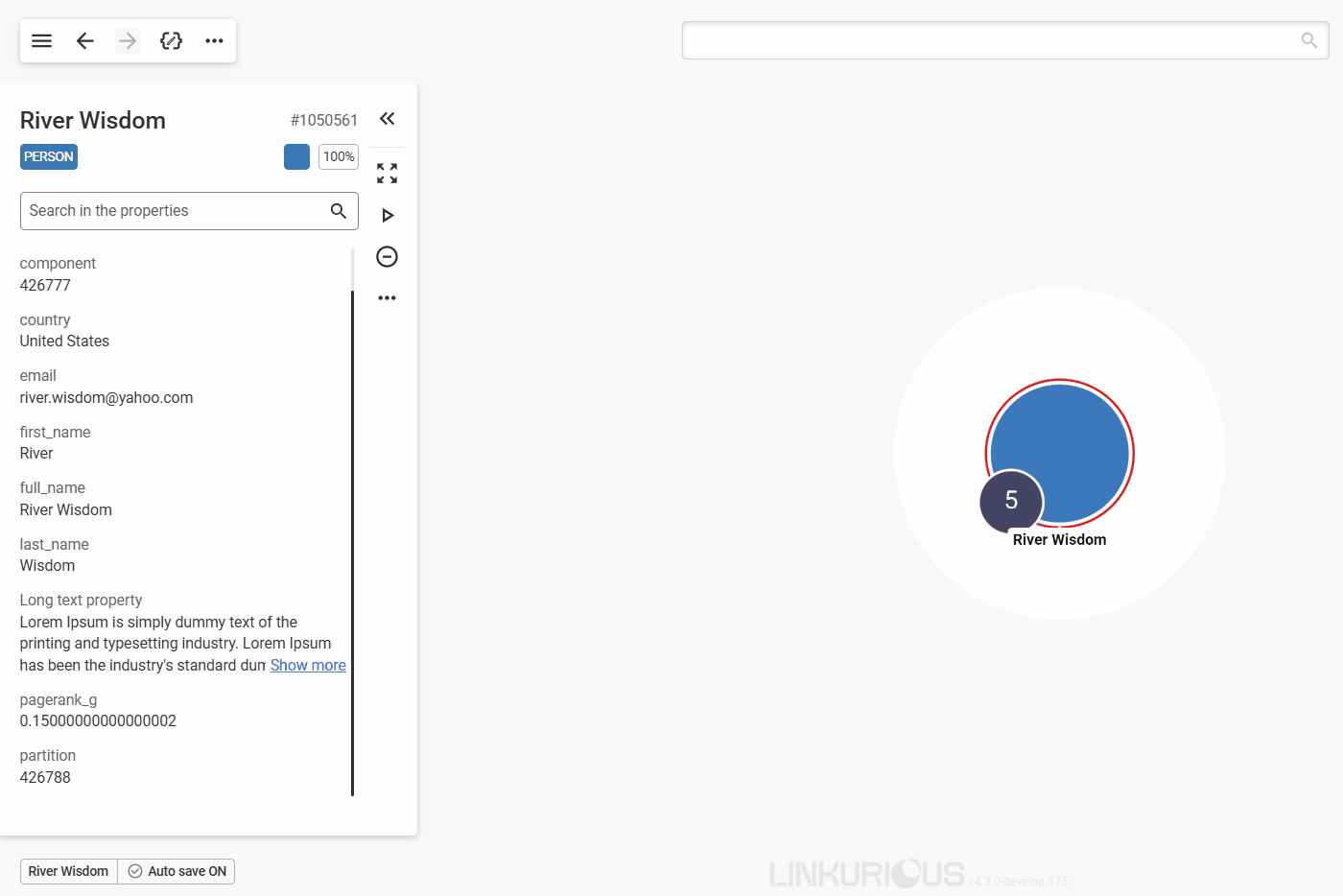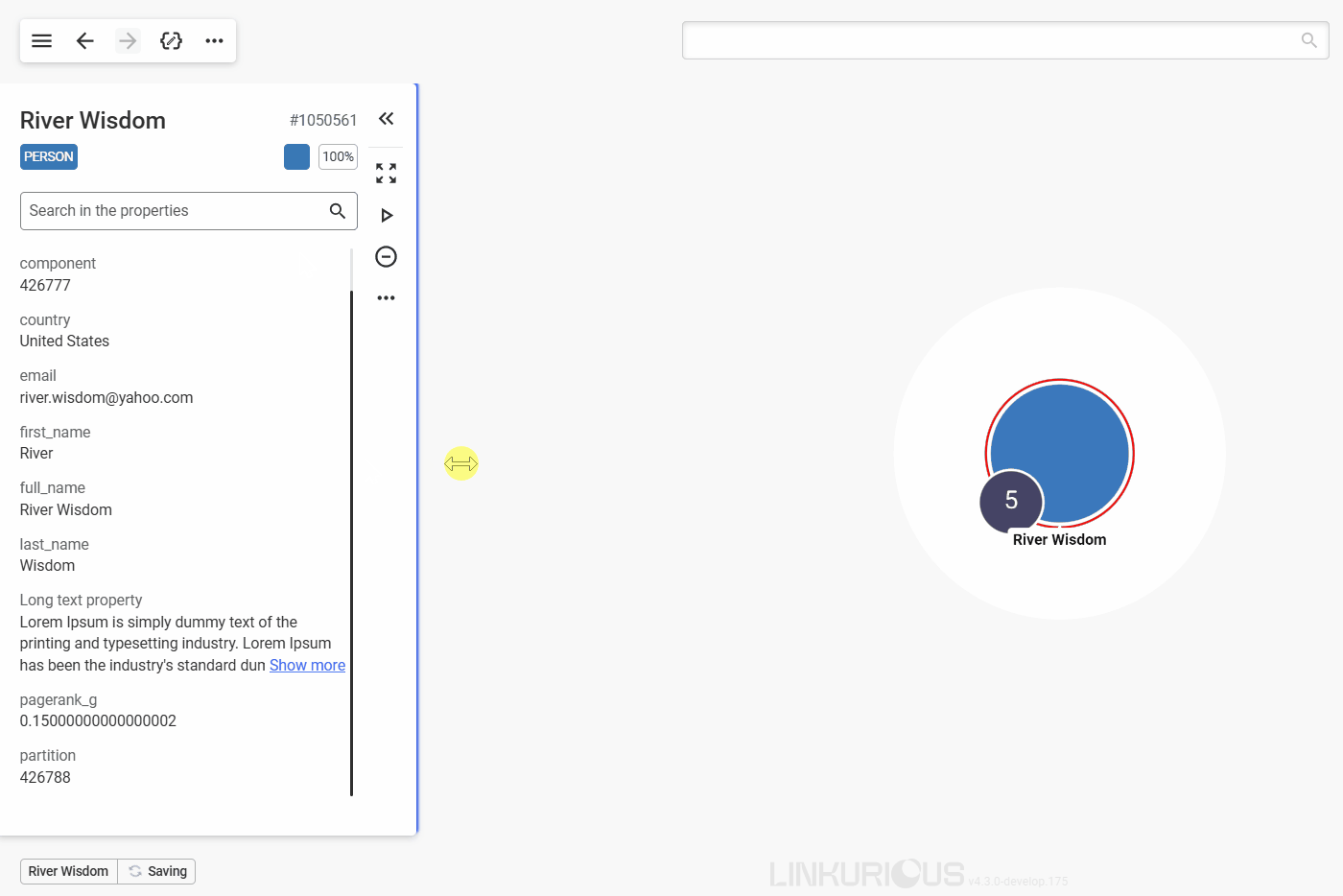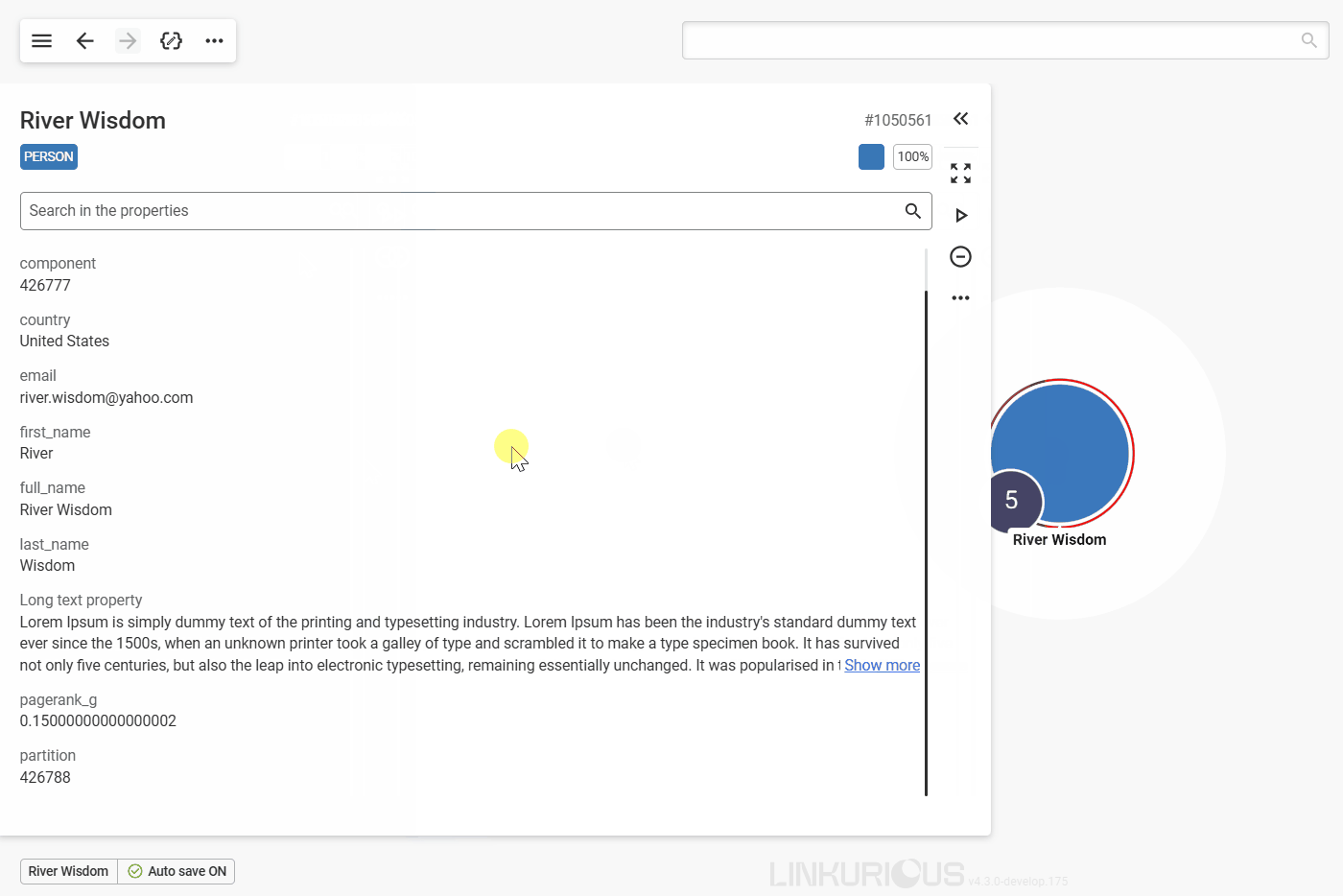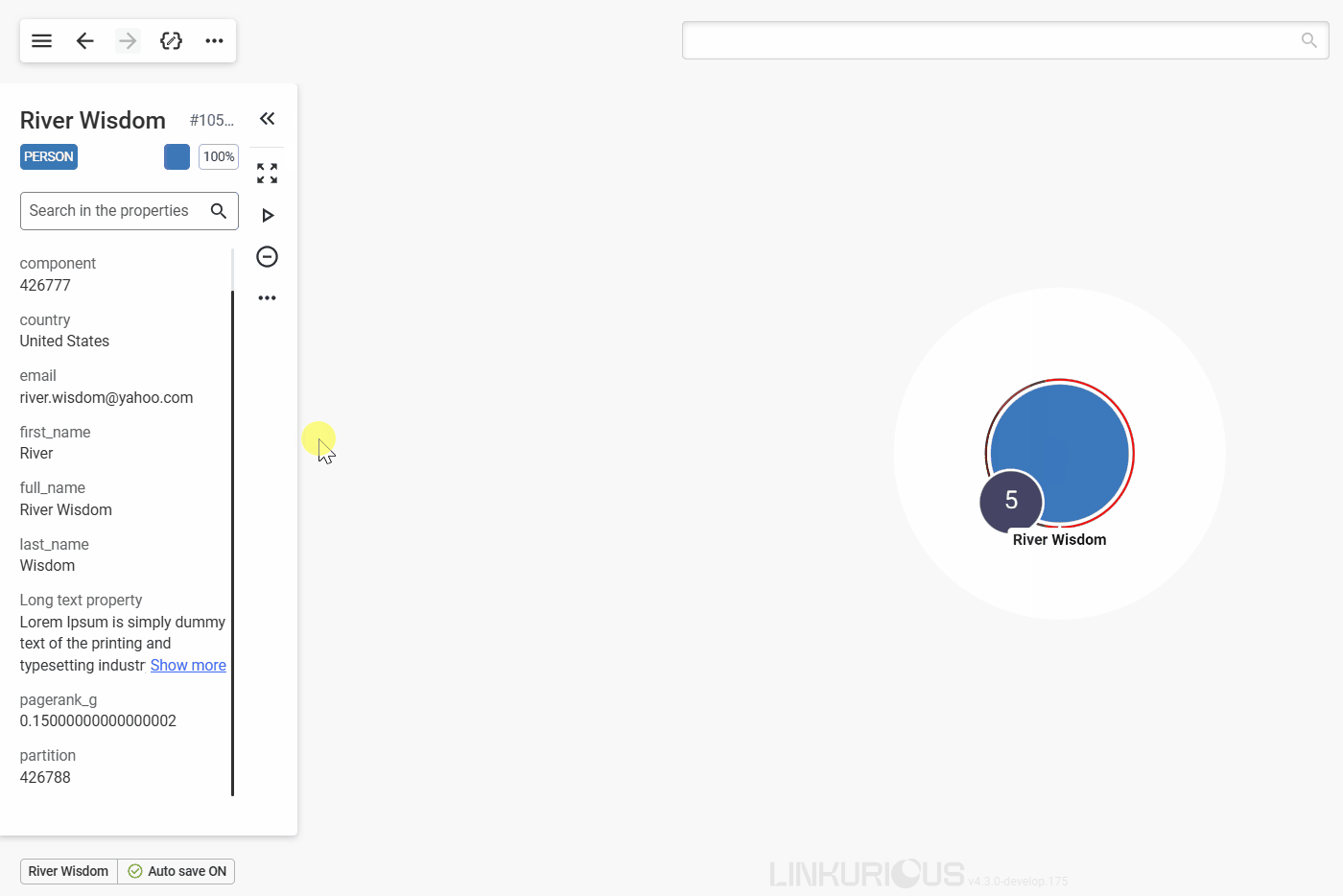
Let's take the example of River Wisdom.
#1050561.Person, which is represented with the blue color and a default size of 100%. You can scroll down the property panel to inspect all listed properties, or directly search for a property using the search bar.
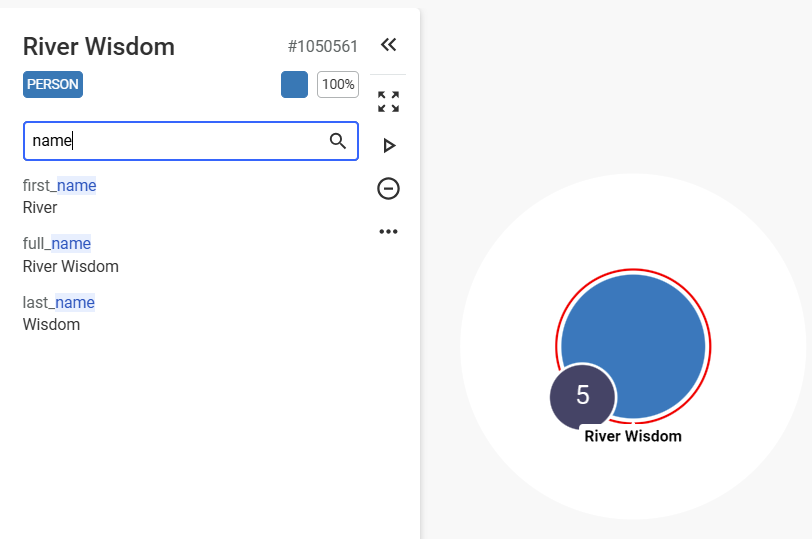
You can adjust the size of the panel for your reading comfort. The size will persist as your preference if you select other nodes.
Now, notice the number in the circular badge next to the node in the graph viewport, it is the number of undisplayed relationships of that node. Let's see how to look for them.
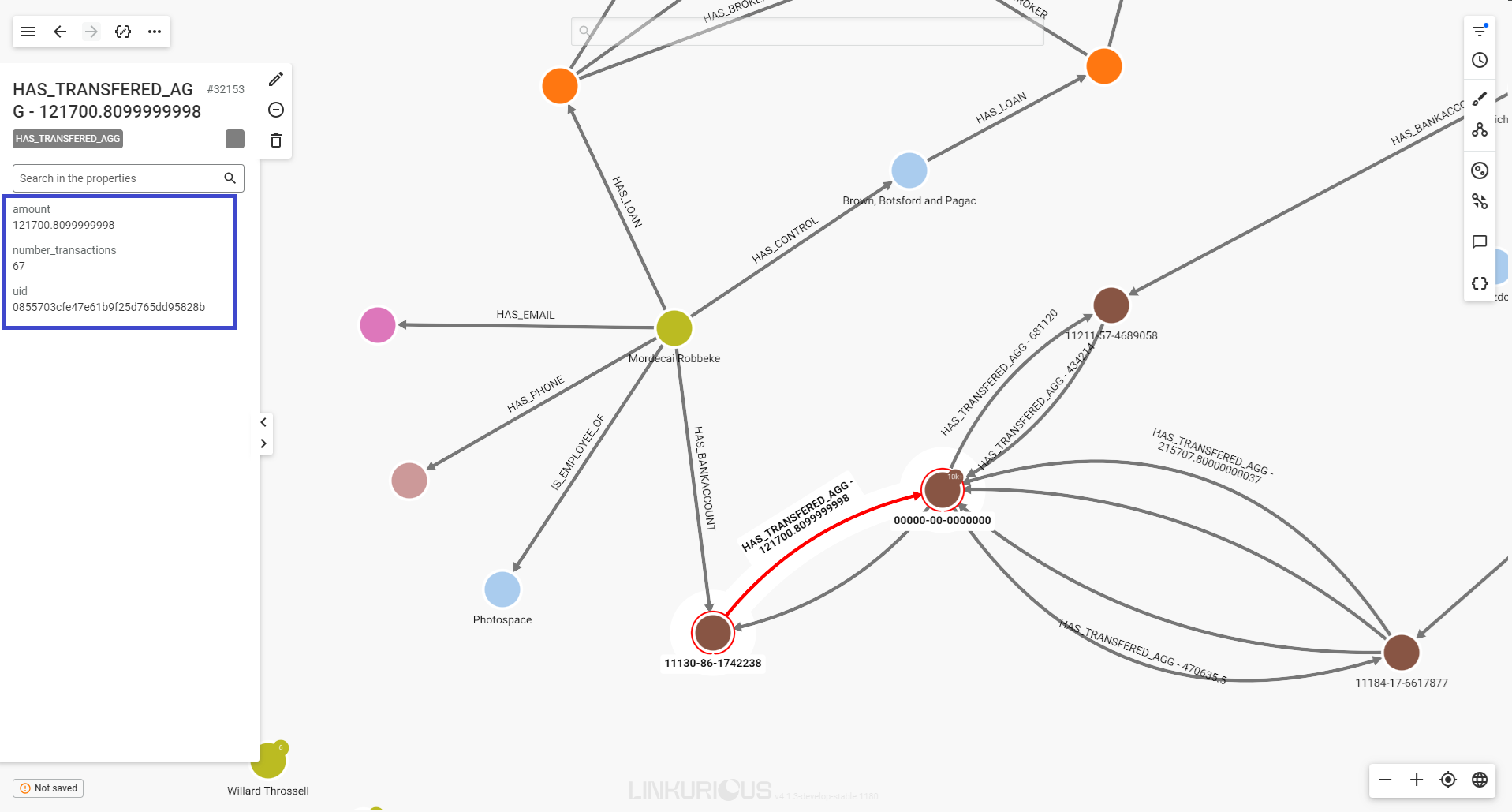
Time to find out about the particular relationships, or edges, of a node.
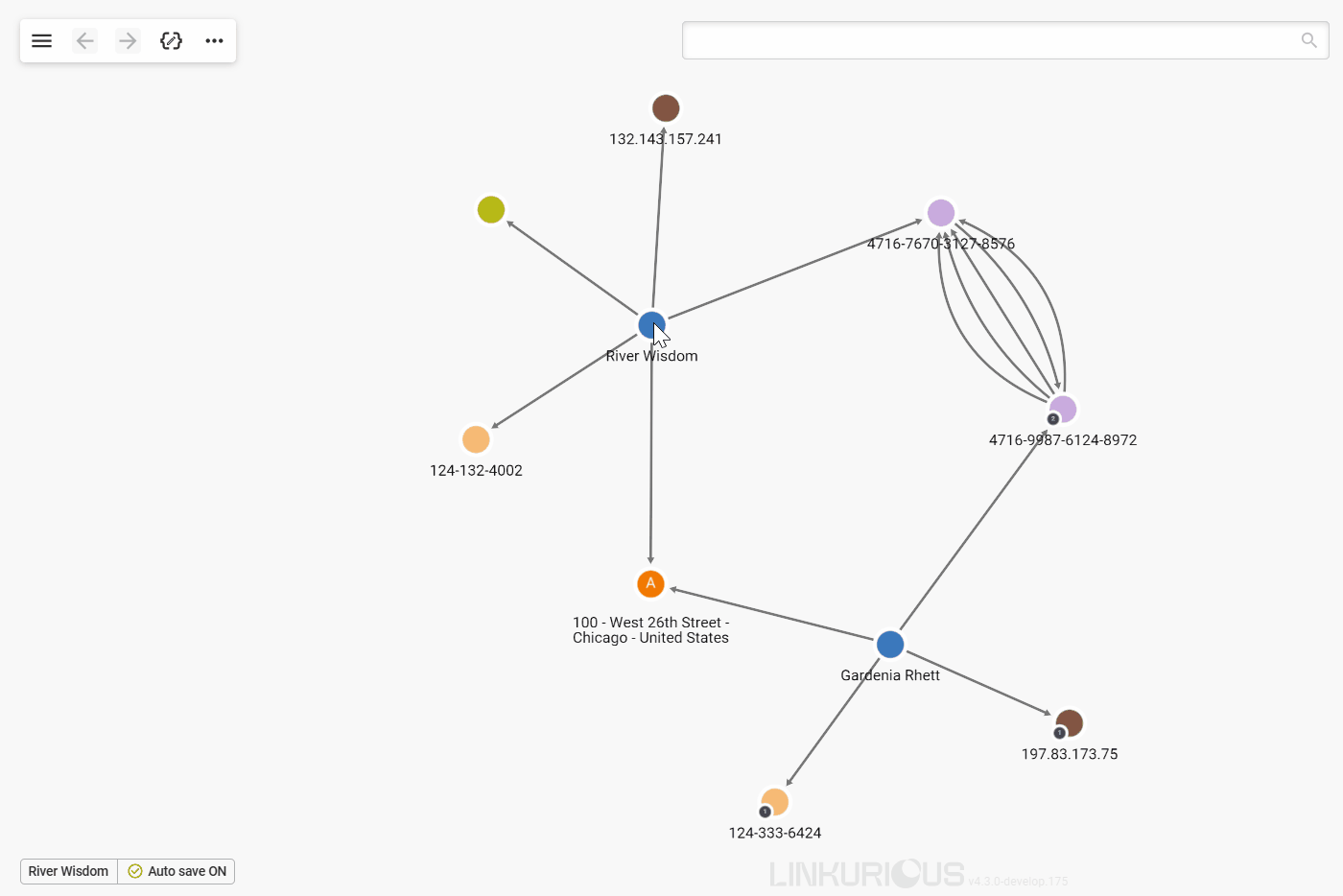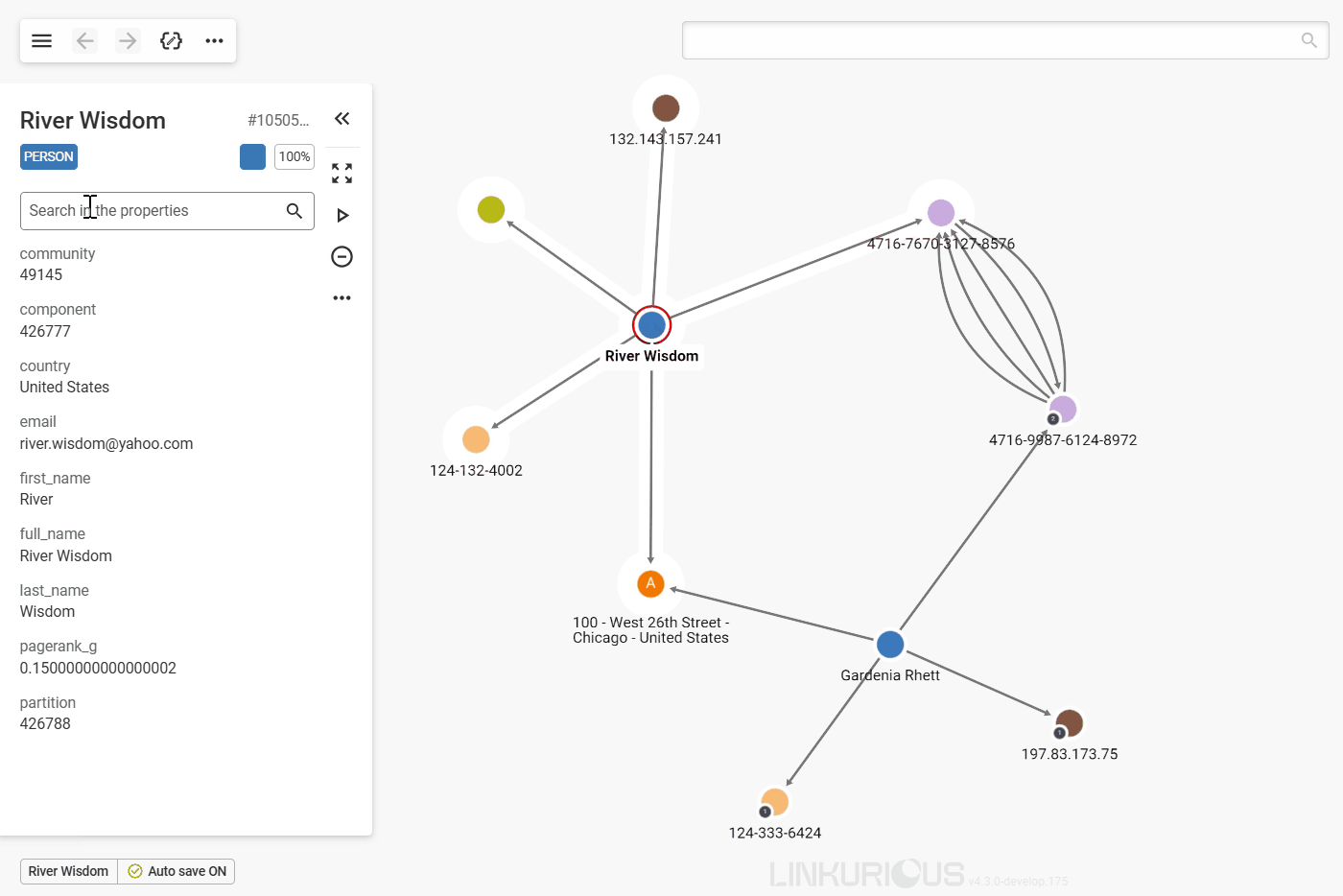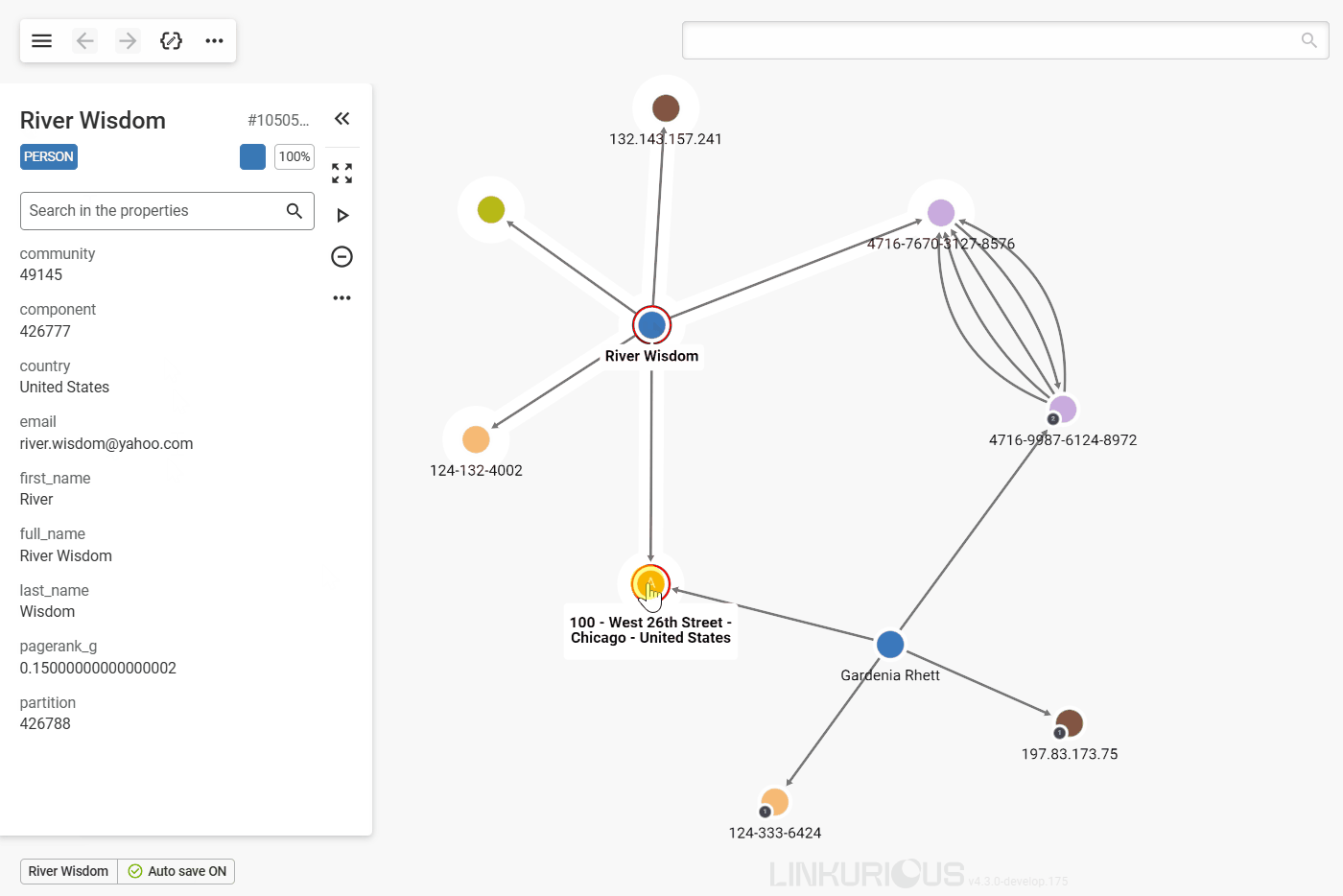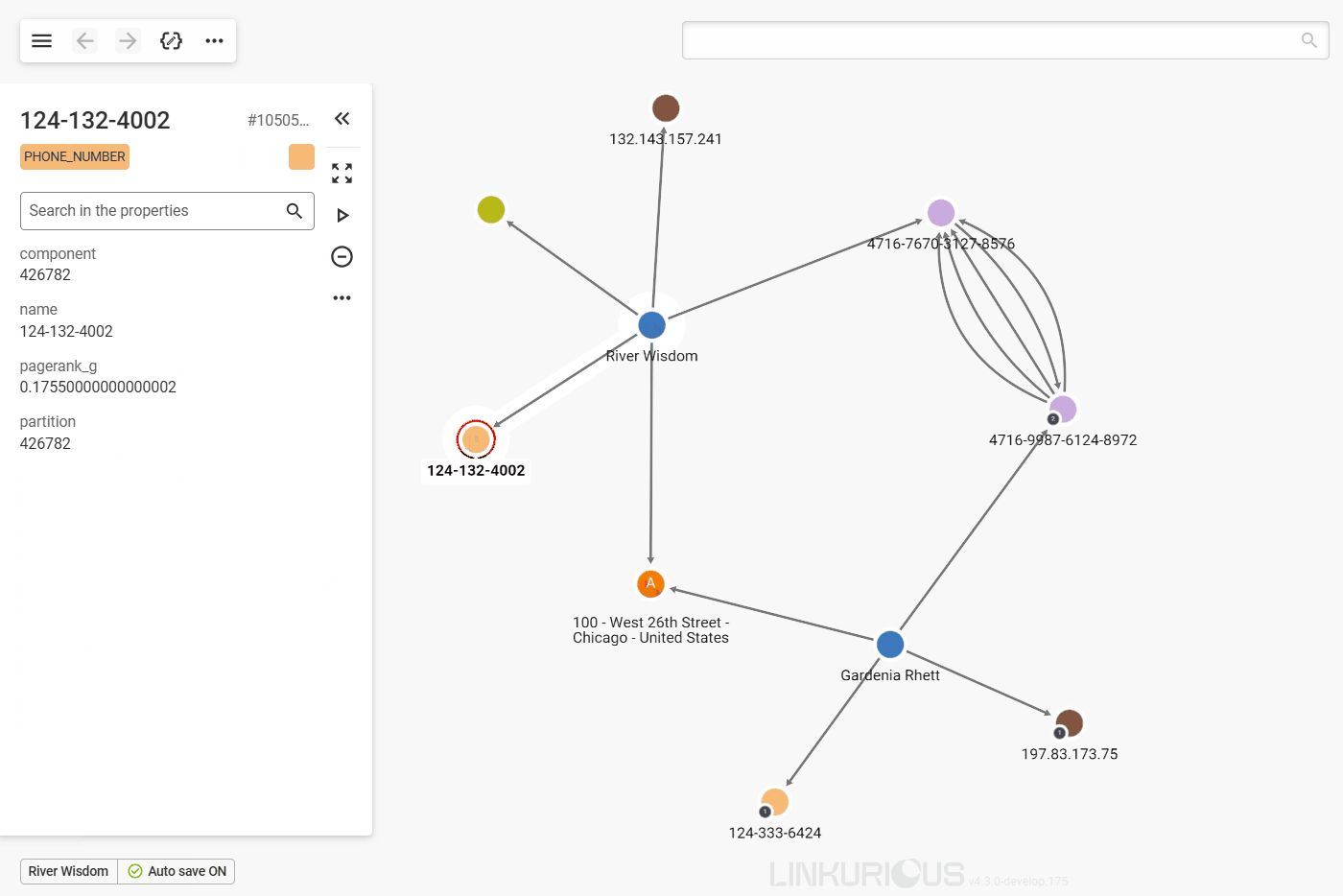
The easiest way to get that information is to double-click on the node we are interested in.
Now we can see 5 other nodes that are connected to River Wisdom through edges.

All the edges have a direction from one node to another, represented by an arrow.
If we click on a given edge, the properties of that edge will be
displayed in the property panel, just like for nodes.
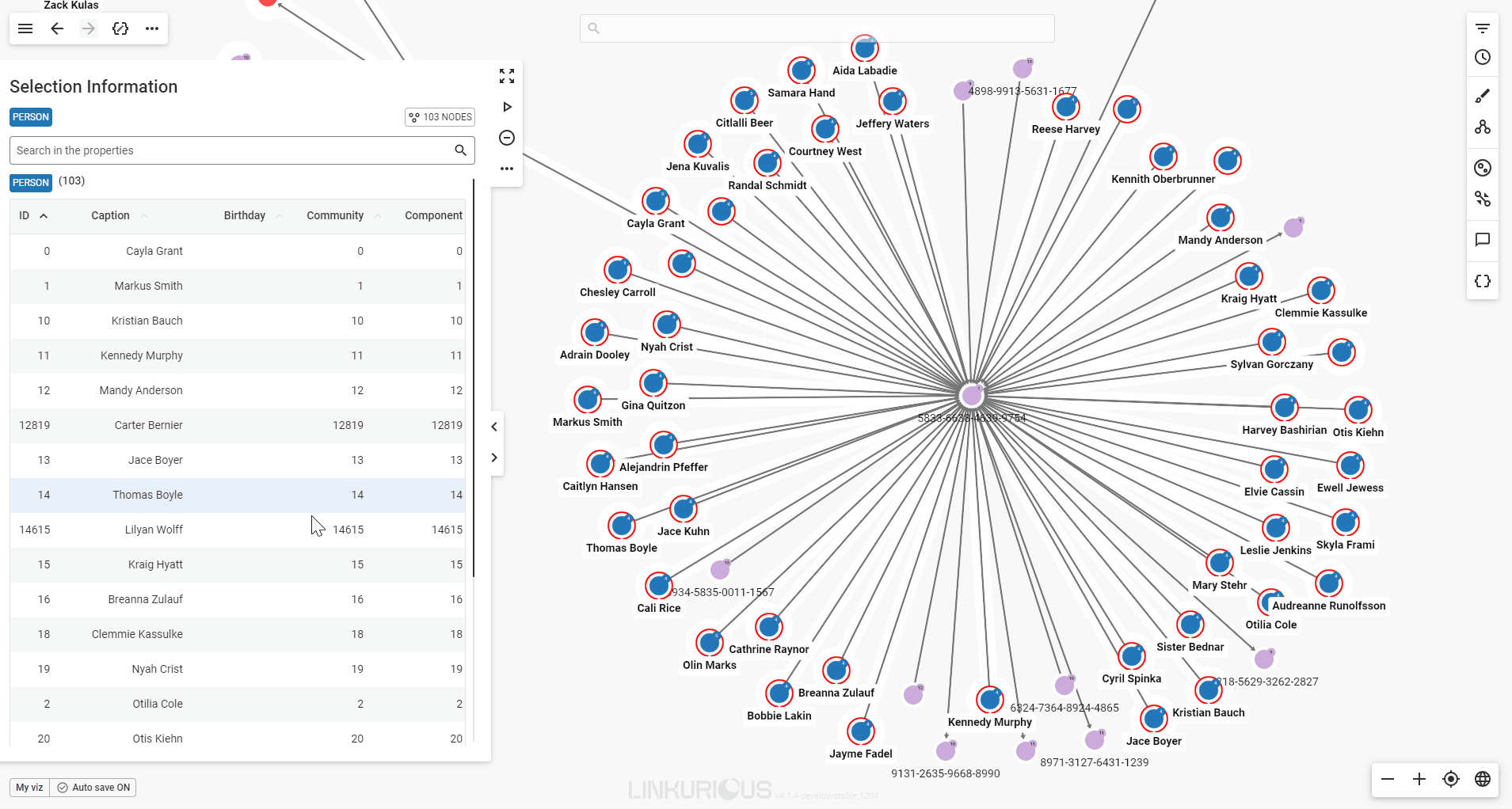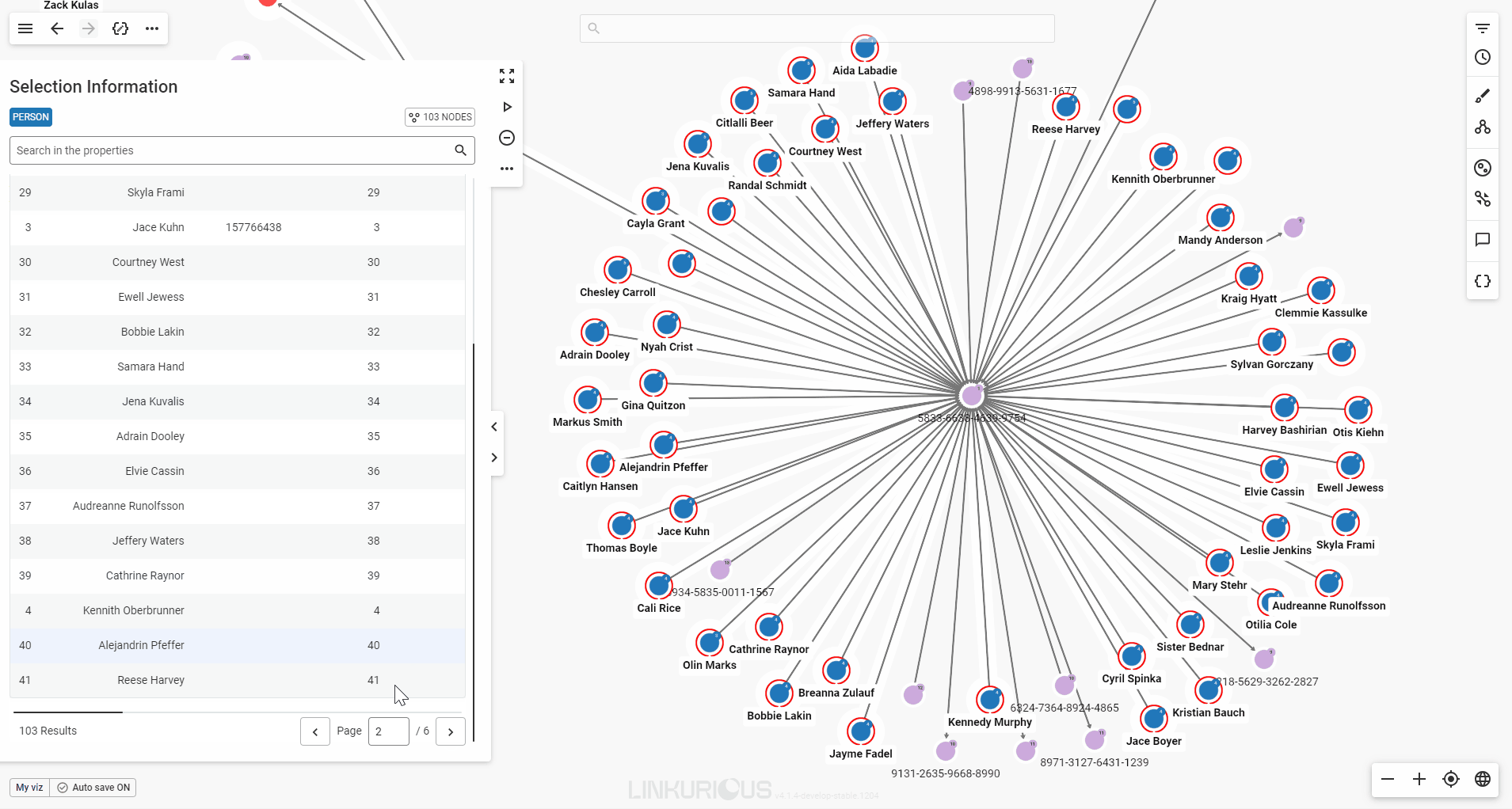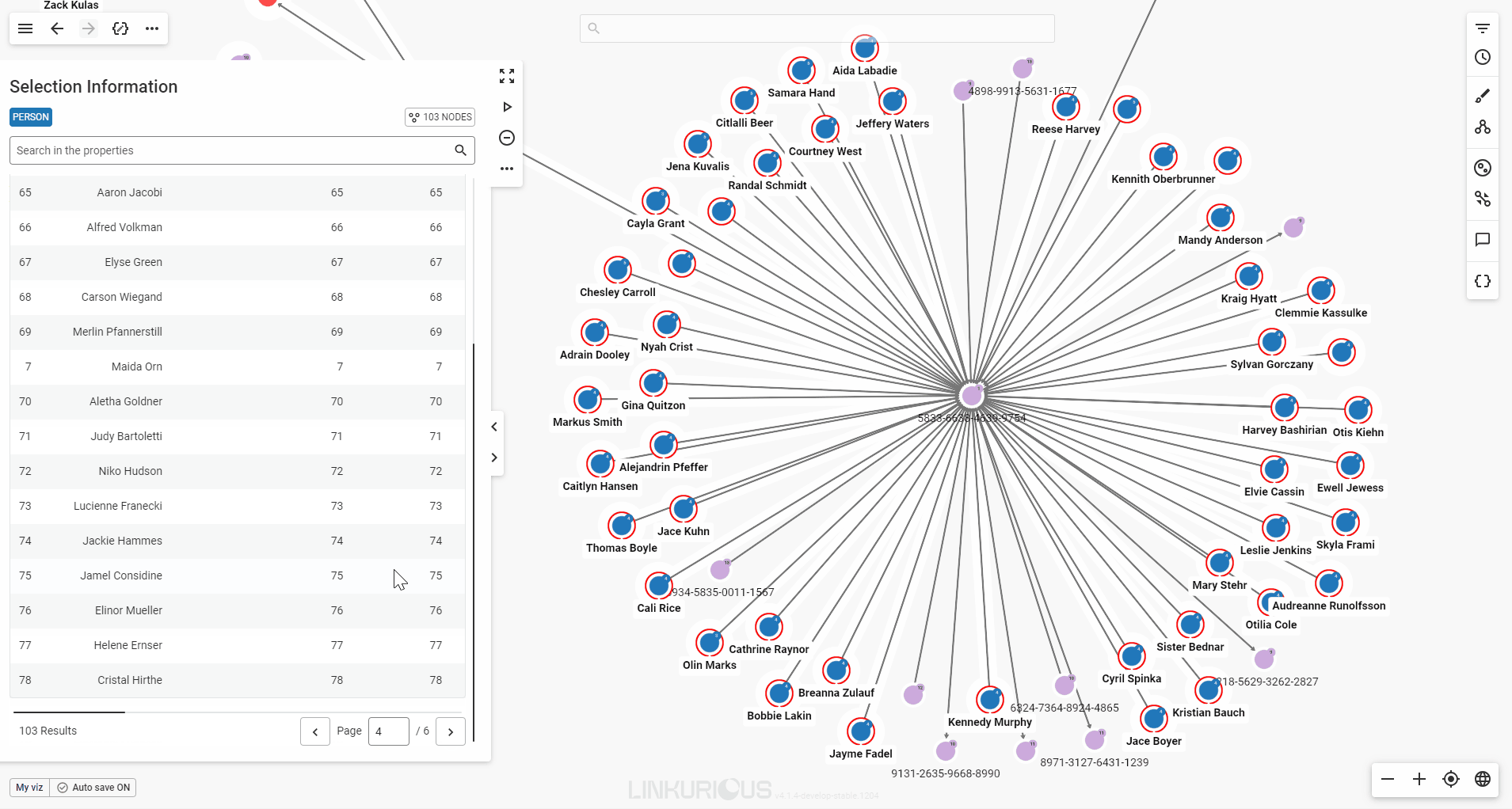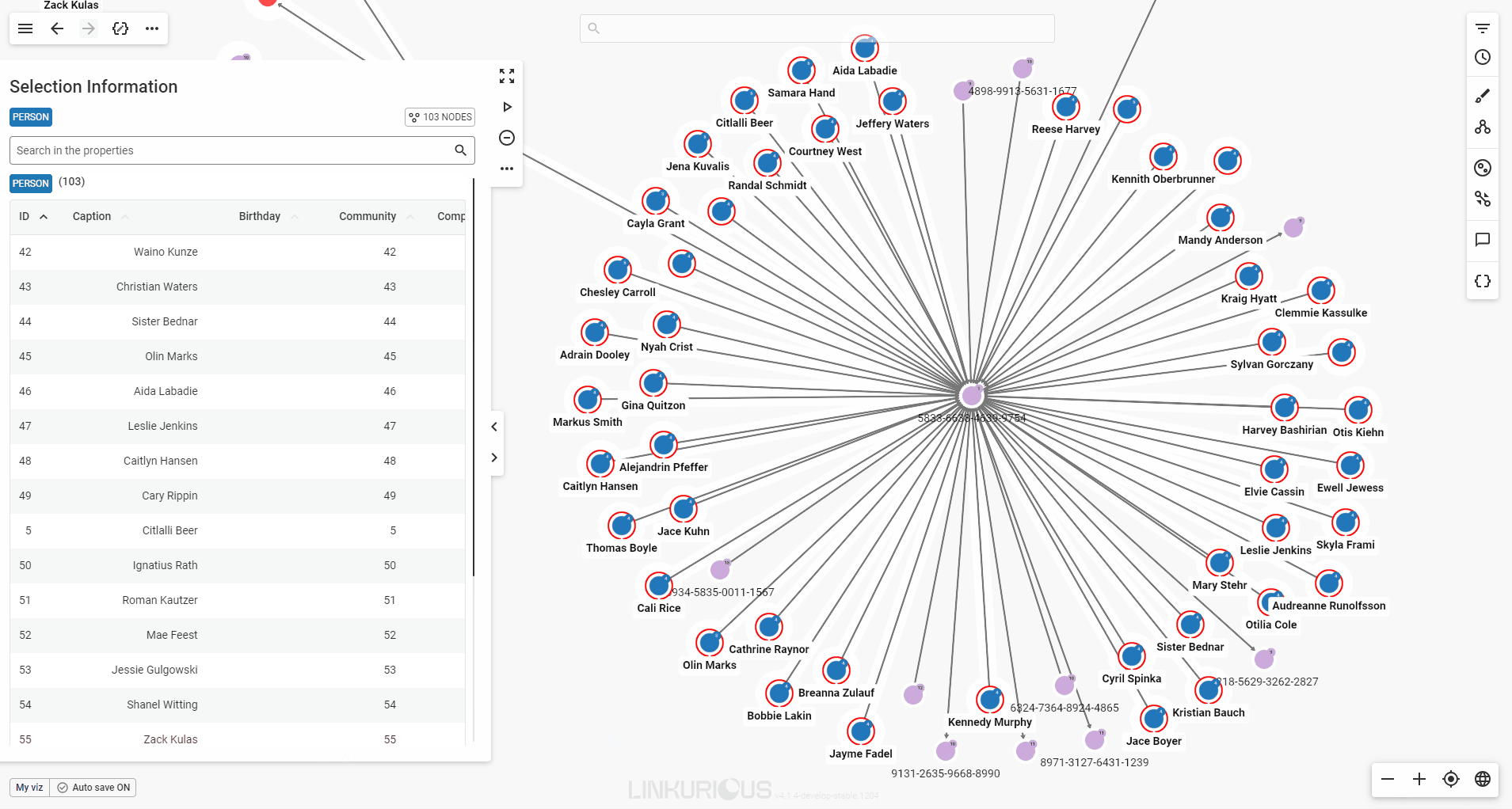
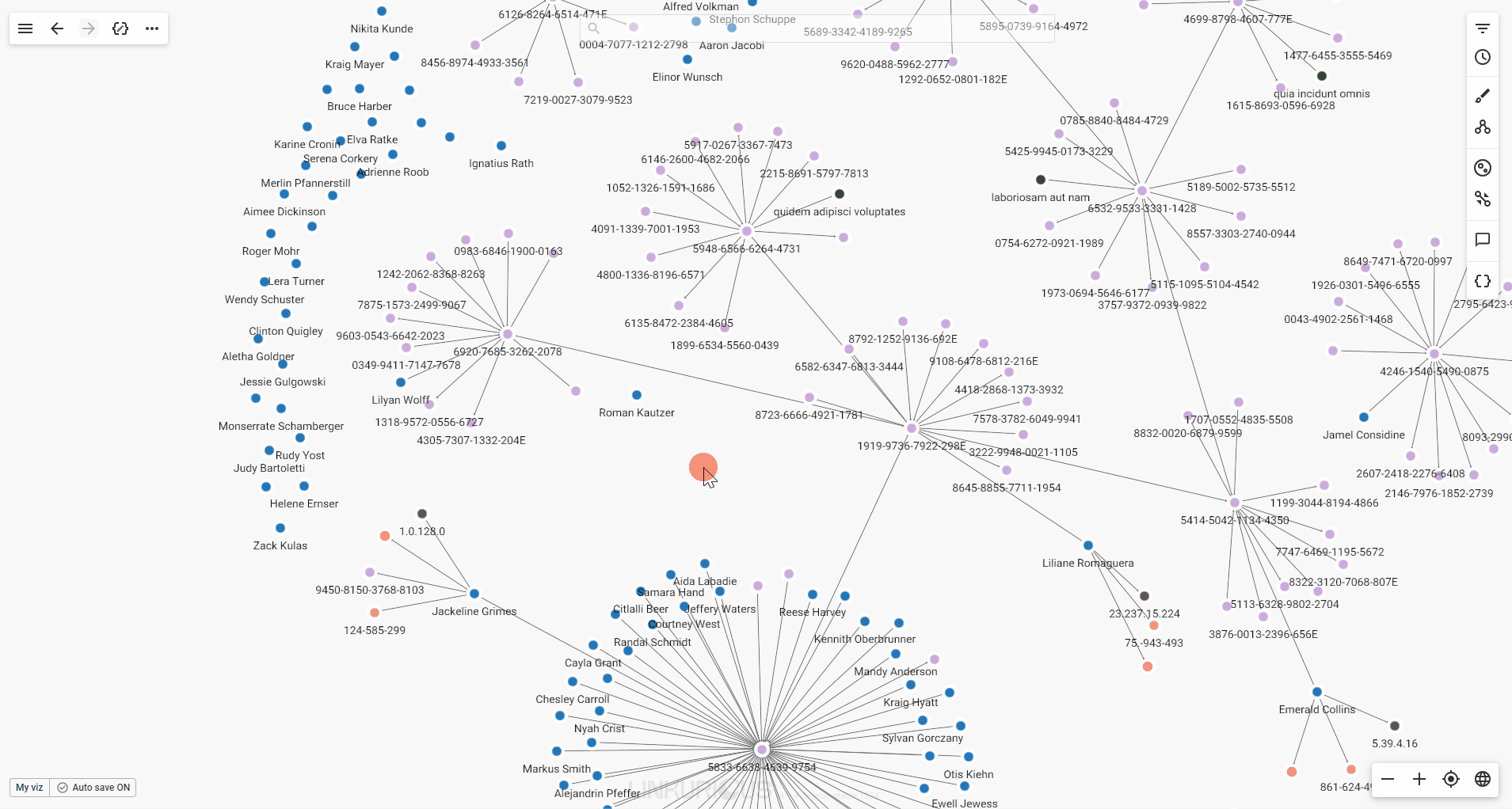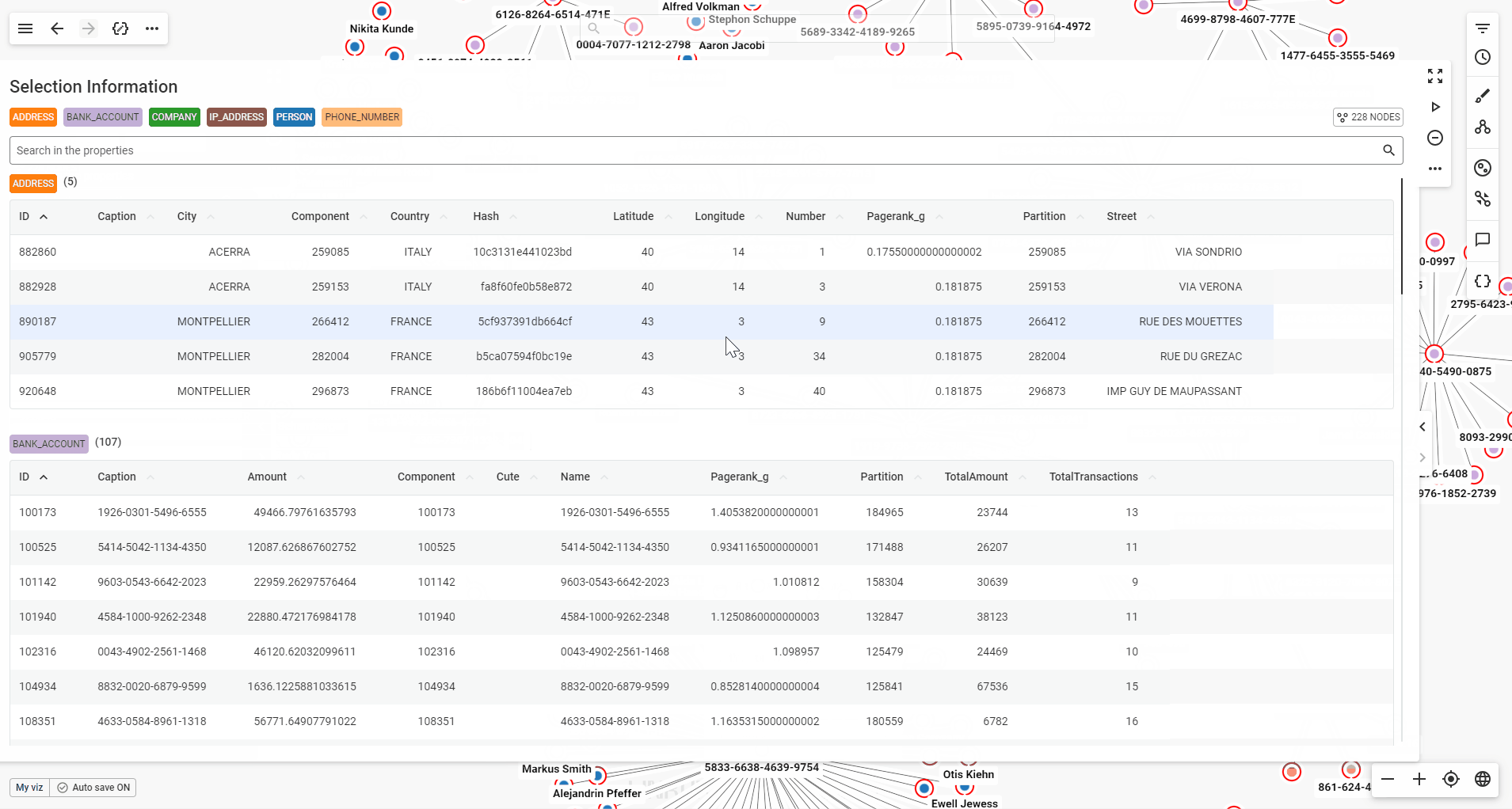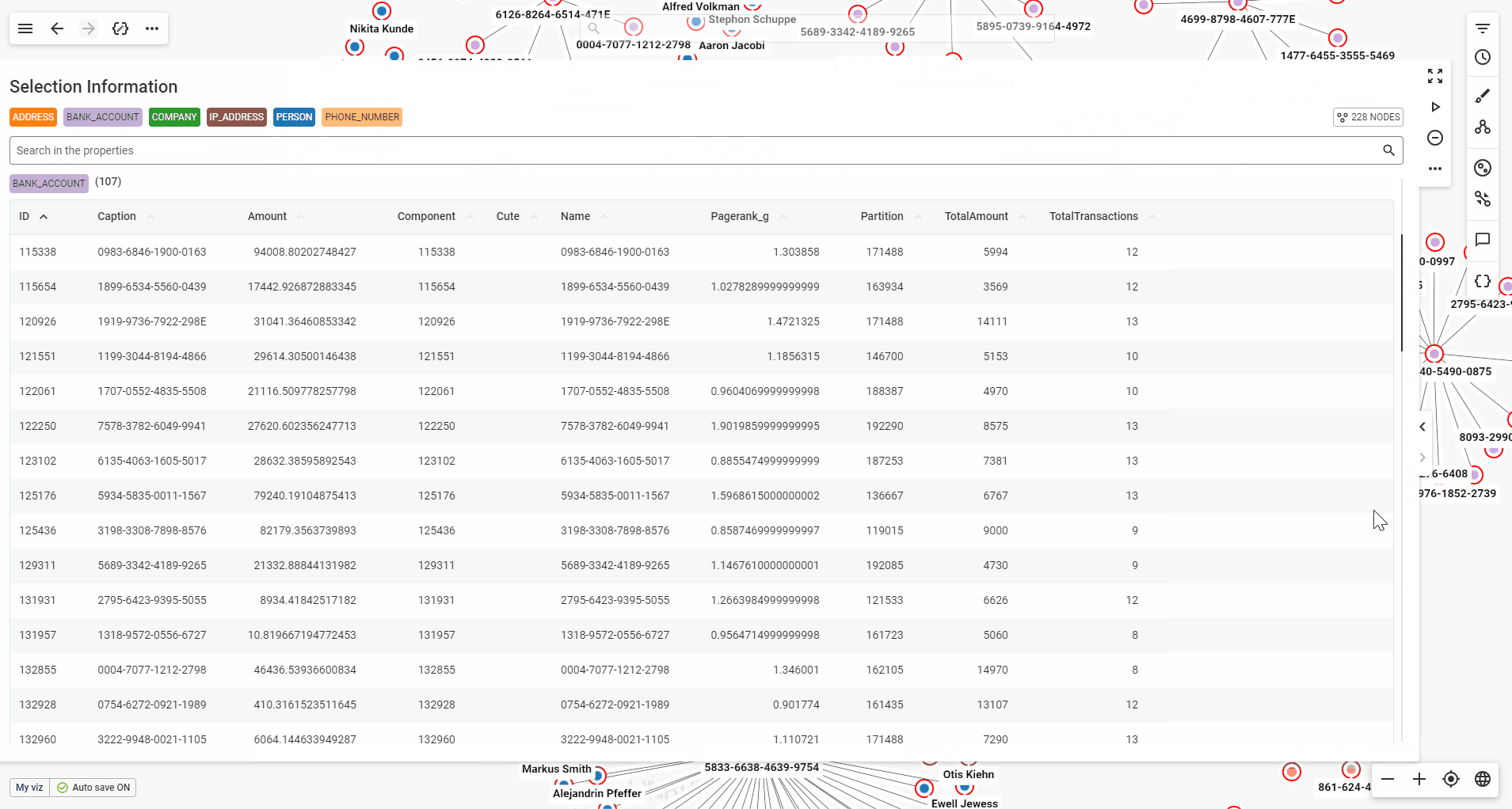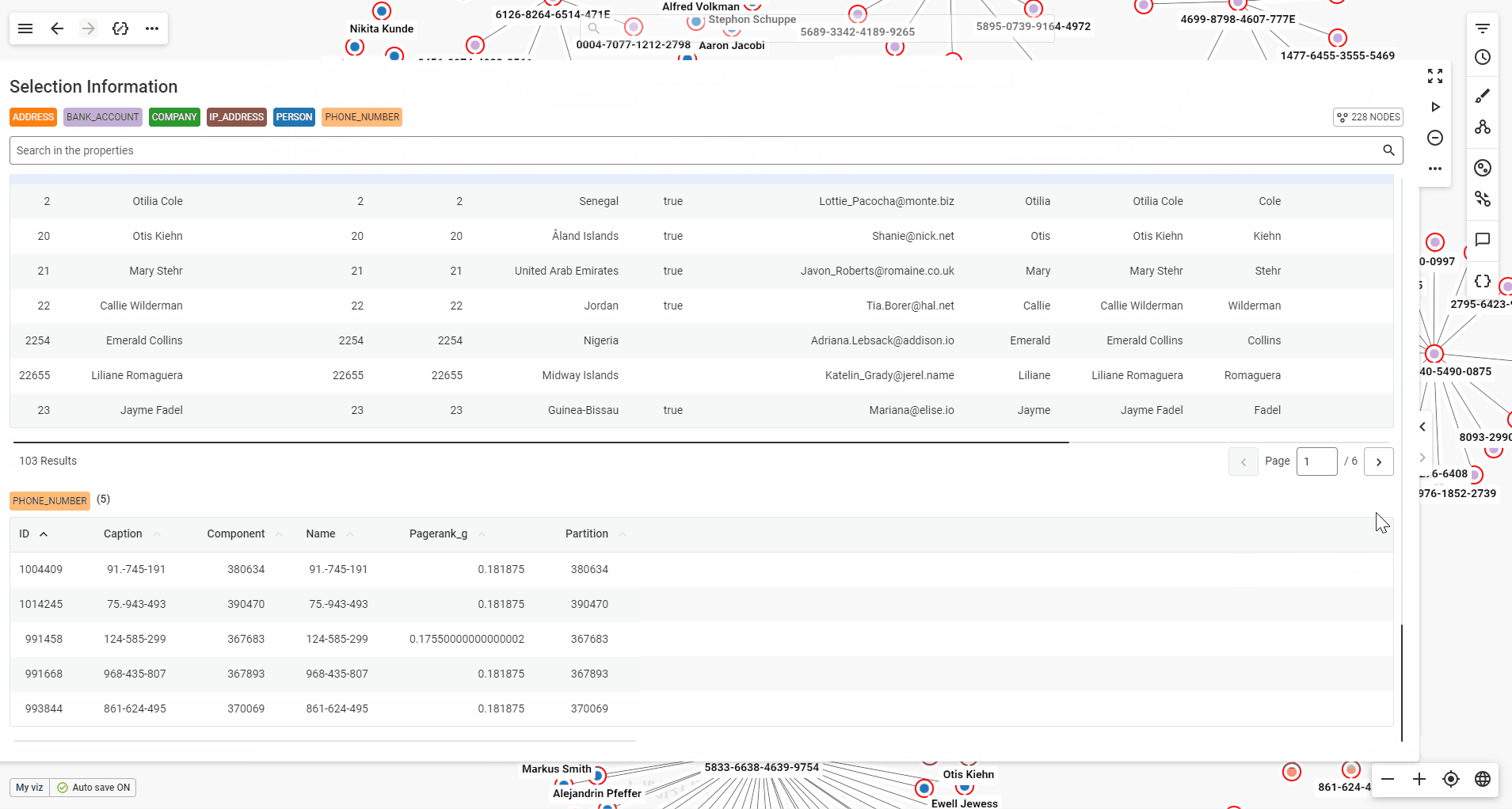
When you select multiple nodes or edges, the property panel will present their detailed properties in a table format for easy viewing.
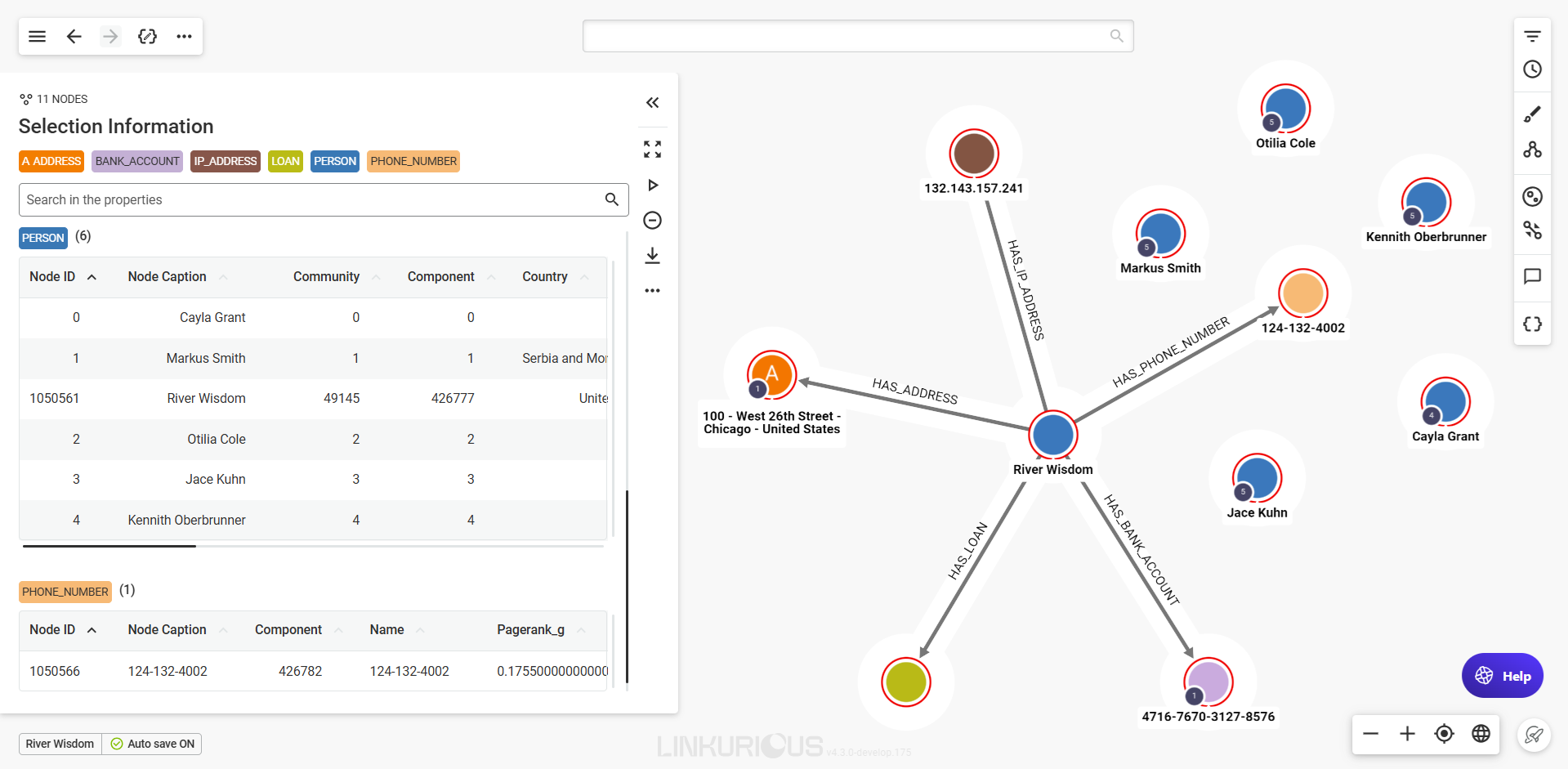
If your selection includes multiple node categories or edge types, each will be displayed in its own table. You can scroll through the tables in the panel, or click a category label at the top of the panel to jump directly to the one you’re interested in.

Use the page buttons to easily navigate through the table's pages.
For a more comfortable reading experience during your investigation, you can expand property panel by draging it from its edge.
If you're looking for a specific value, simply type it into the search bar. Matching results will be filtered and highlighted, making it easy to spot what you need.
You can also sort the values by any property available, in ascending or descending order.
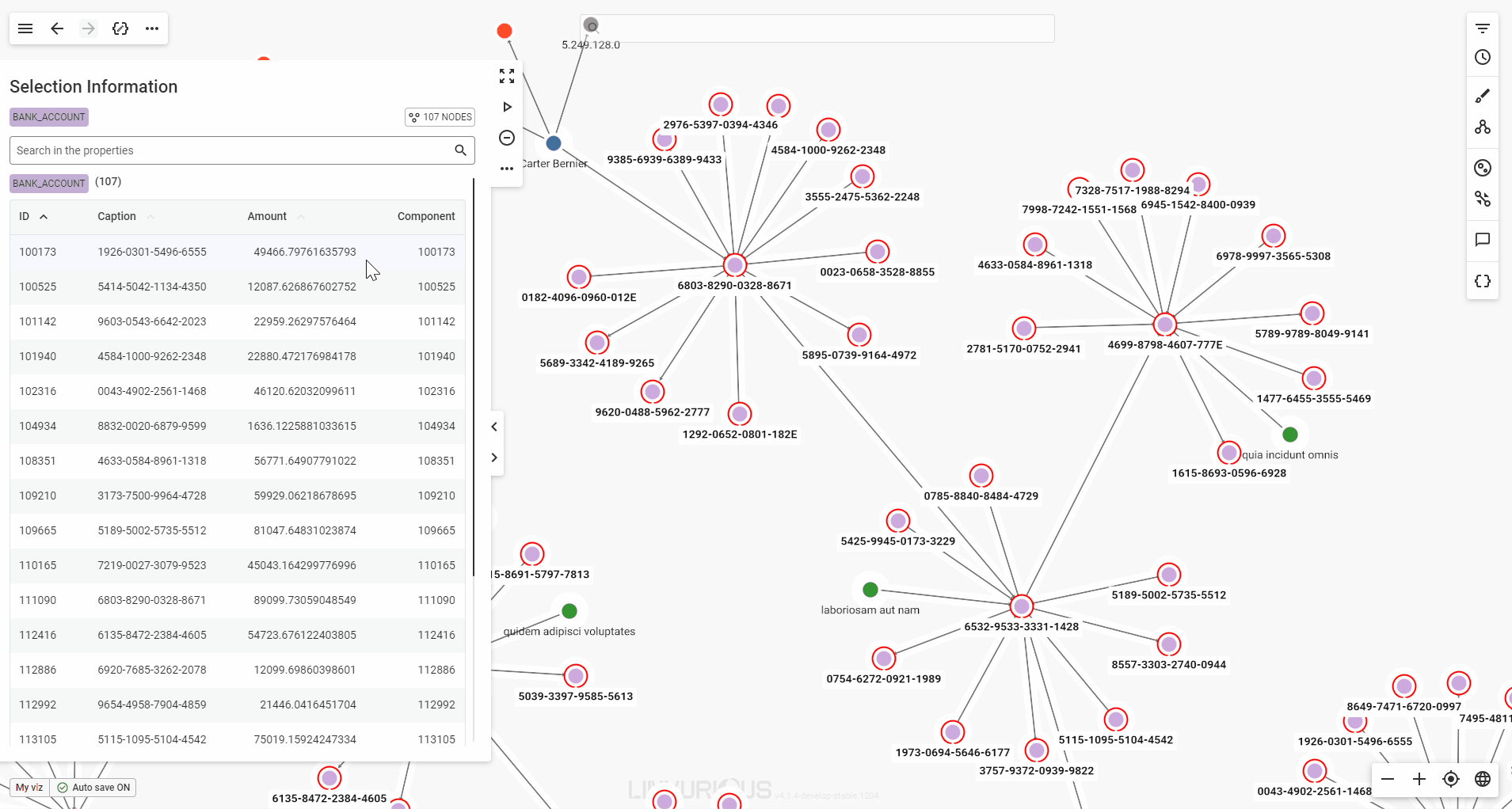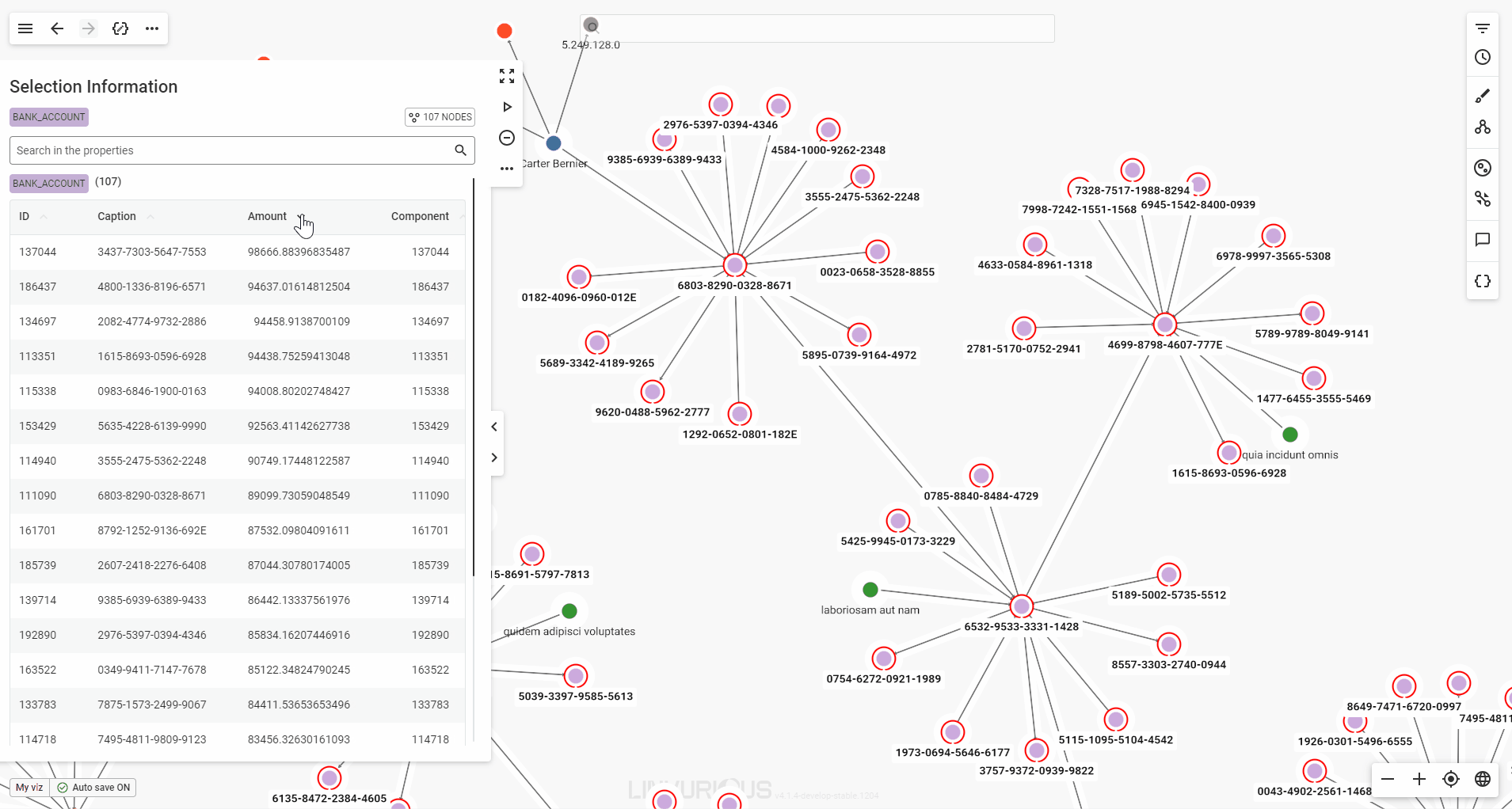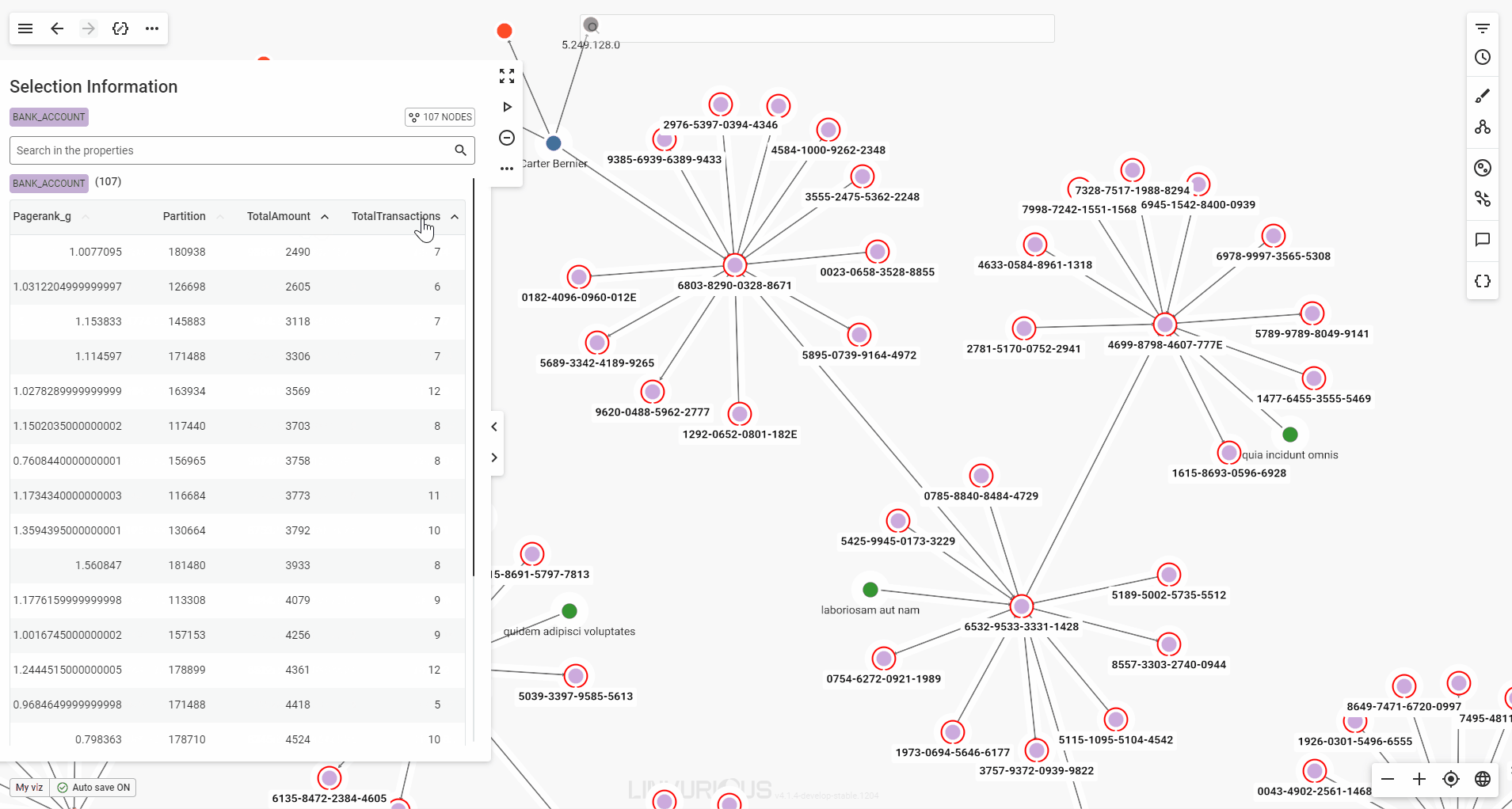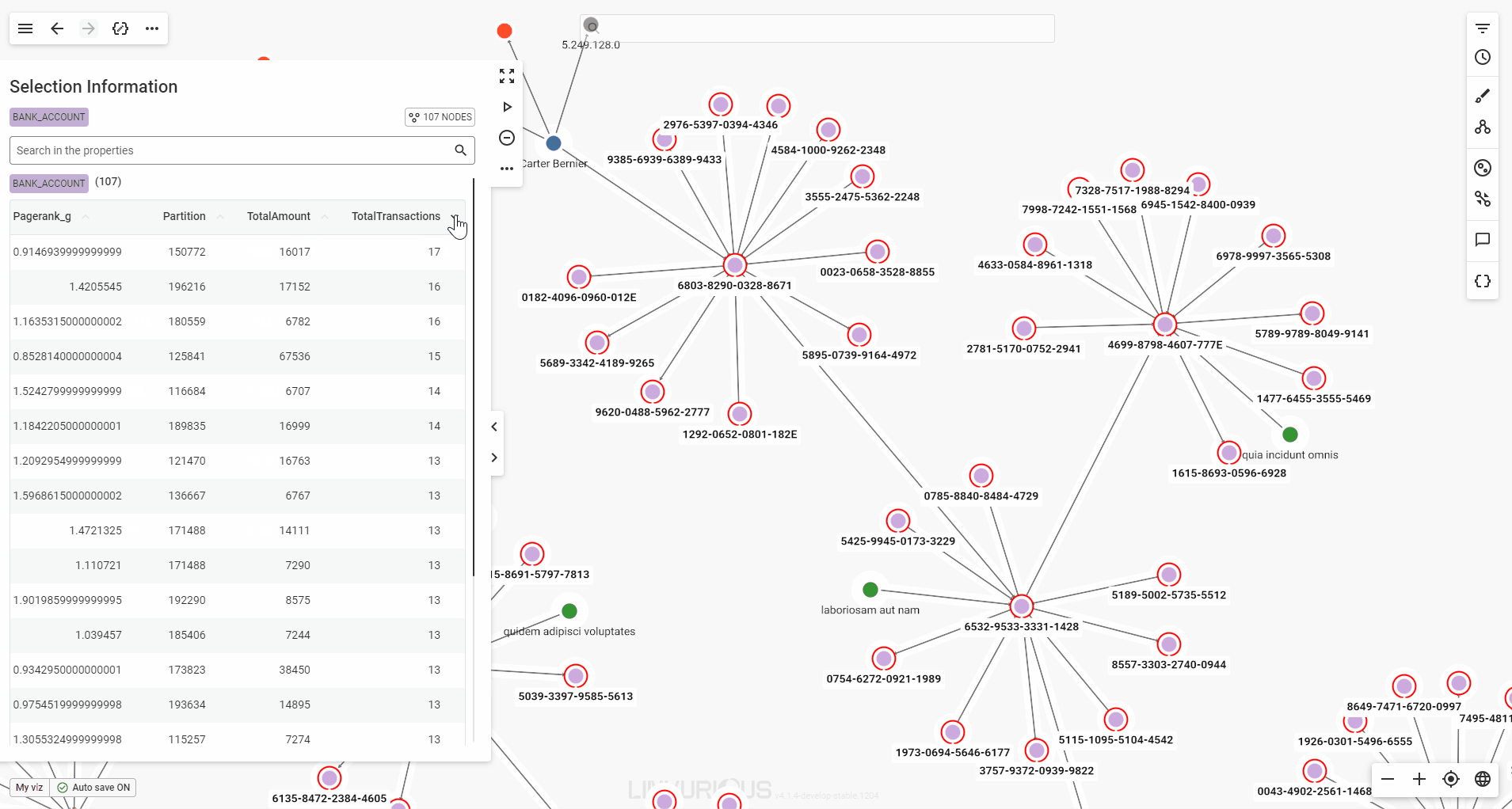
Finally, a single click on a node in the table highlights it with a pulsing halo on the graph, while a double click lets you focus on it without losing your selection.
You can learn more about selecting multiple nodes or edges in the Select nodes and edges section of this documentation.
In this chapter, we'll learn how to manage visualisations created with Linkurious Enterprise from a space. You can open, share, move, rename, duplicate and delete visualisations by right clicking on each visualization.
Visualizations are added to the space's homepage by default.
From the space, you can search for and manage your visualizations. You can open, share, move, rename, duplicate, or delete them, and switch between a thumbnail card view and a list view.
Visualizations can be opened by right clicking on a visualization to open the context menu and then clicking on the Open button or by double clicking on the visualization's card. Once opened, you will be redirected to the workspace!
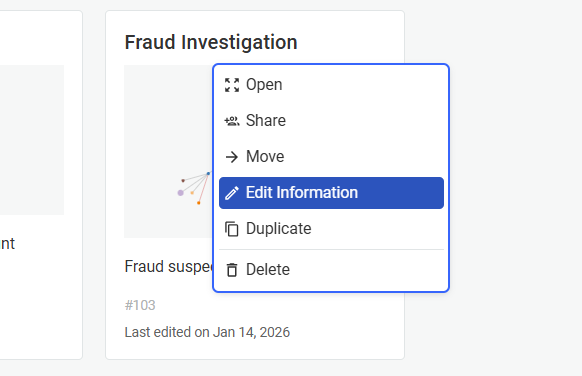
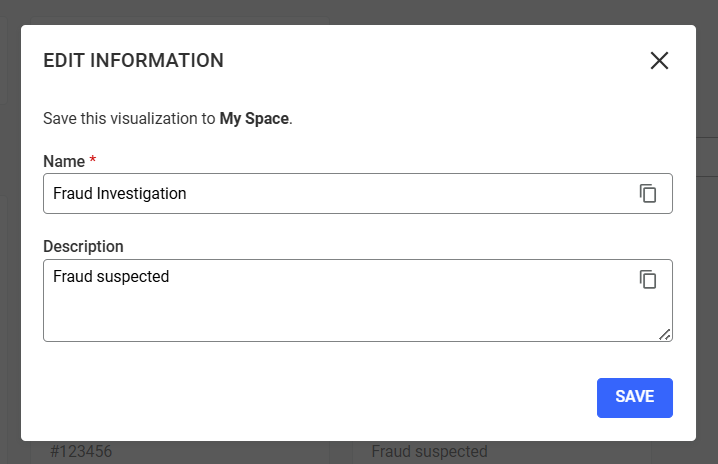
Visualizations basic information like name and description can be edited by right clicking on a visualization to open the context menu and then clicking on Edit Information.
You can then enter the new name you wish to have for your visualization, and edit the description, then save.
Deleting a visualization is only possible through the dashboard:
Delete button.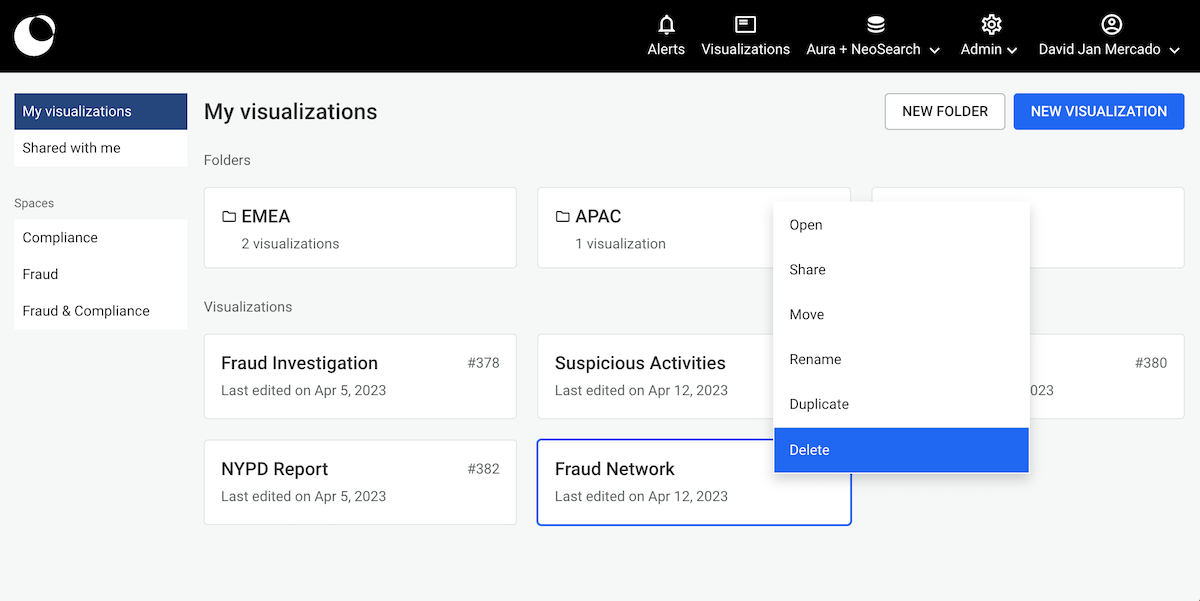
The visualization is deleted after confirmation.
In order to quickly find the visualization you want to work on, you can search, order and change the way they are displayed in the dashboard.
These features are limited to the actual space you are working from, and do not work across spaces.
Click in the search bar on the right hand side and type some text. You can search the name or description content. Visualizations will be filtered based on your search.
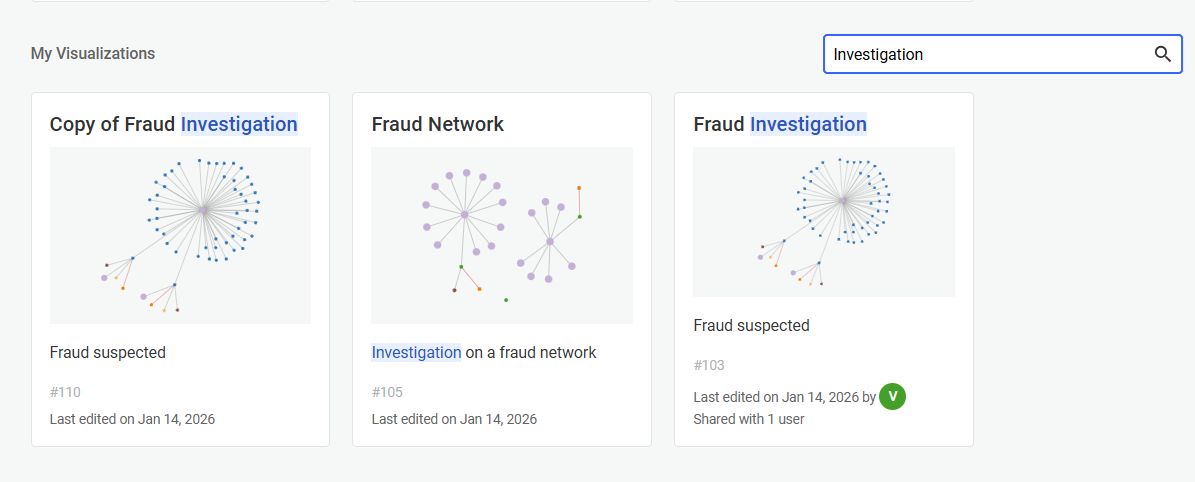
Select the visualisation display order from the dropdown menu next to the search bar. You can choose to order your visualizations by Name, Last edition date, or Creation Date.
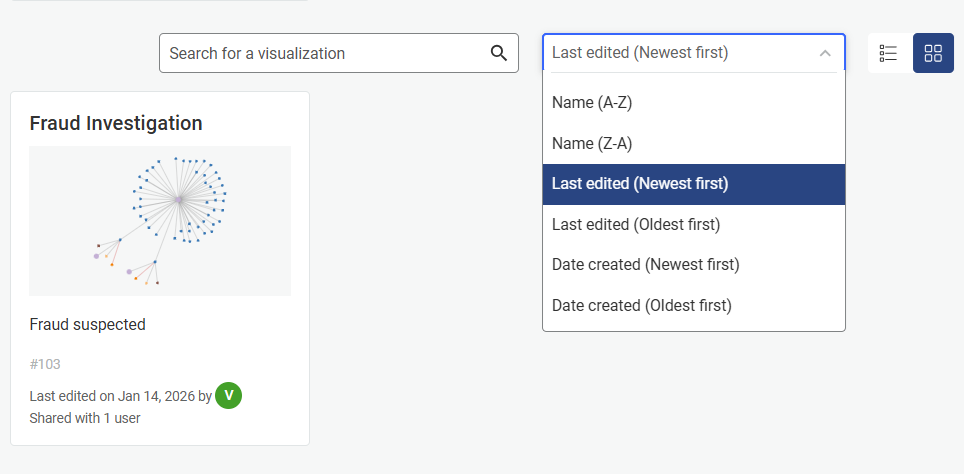
By default, visualizations are displayed in the Card view with thumbnails indicating the last saved state of the visualization.
Click on the List view button right next to the order menu to switch to a list view.
Come back to Card viewby clicking on the other button.

From the dashboard, you can move a visualization within a space by right clicking on it and from the context menu clicking on Move. Furthermore, from your private space My visualizations , you can move any of your visualizations to a public space again by right clicking on it and from the context menu clicking on Move. Both use cases are thoroughly explained below.
To create a folder, you can click the NEW FOLDER button in the upper right corner of the dashboard.
Enter the name of your folder.
Hit Create. The folder is now created.
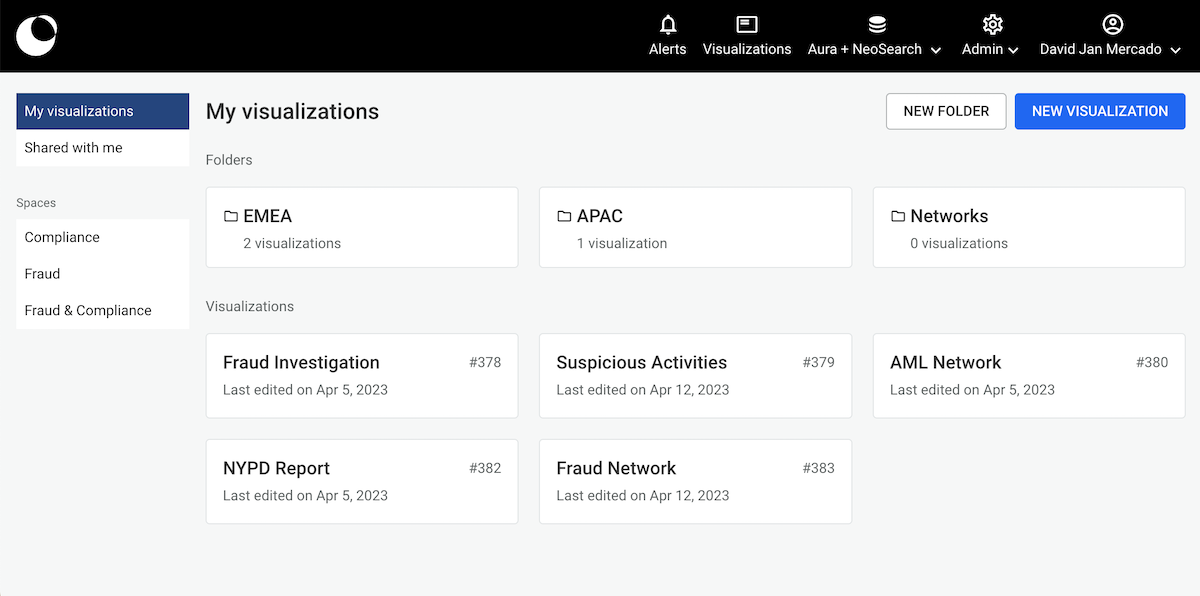
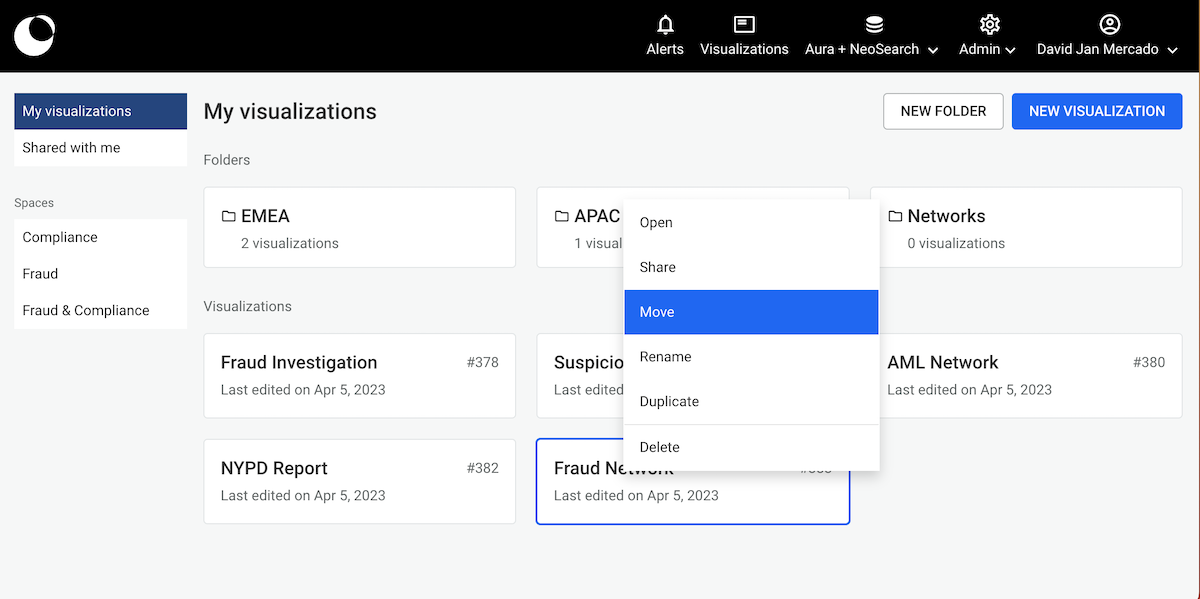
You can open the folder by either double clicking on it or right clicking to open the context menu. If you want to move a visualization into the folder, right-click on your visualization and hit Move.
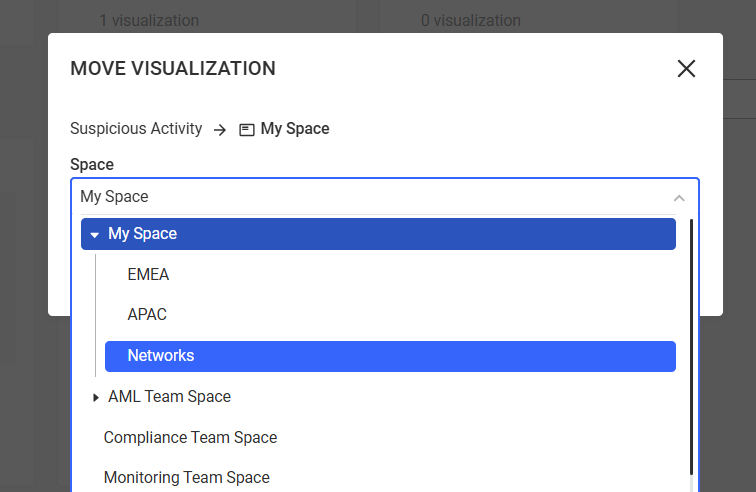
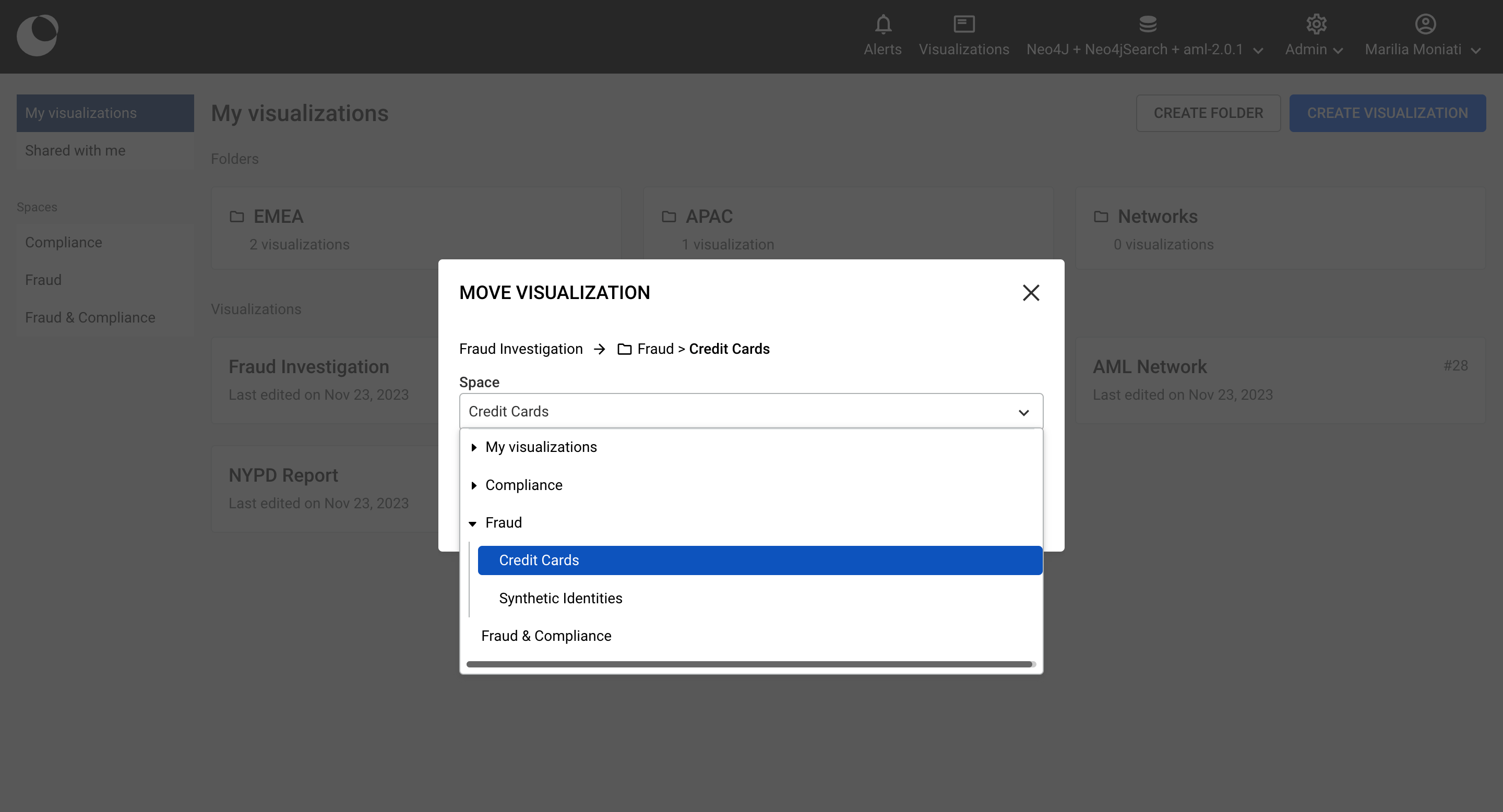
You can select the folder you want to move your visualization to.
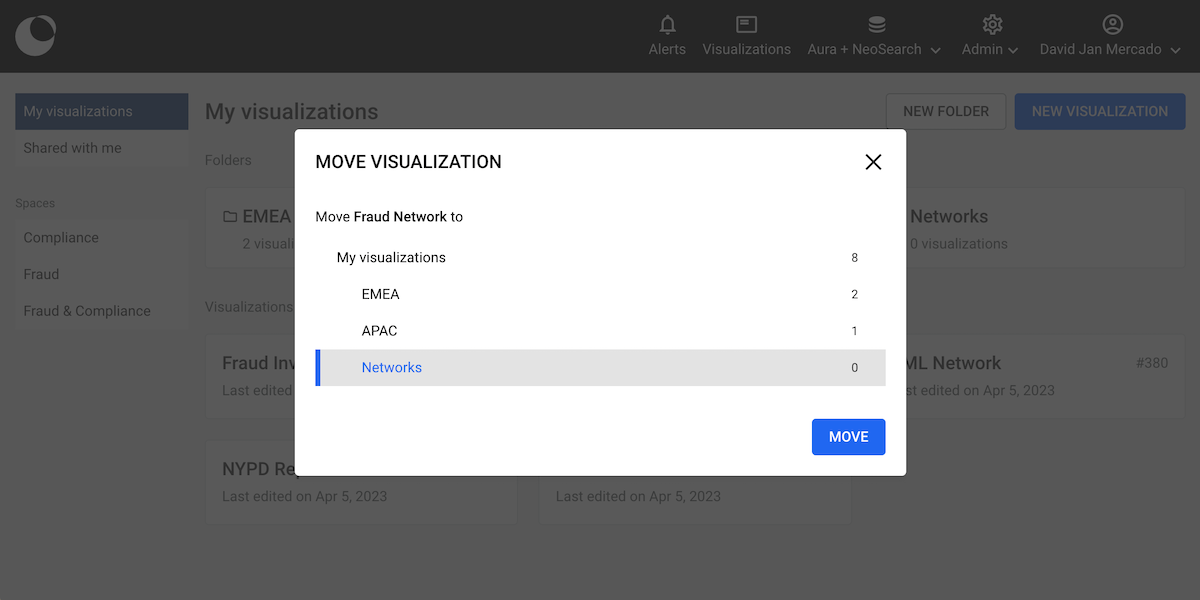
The visualization has been moved to the folder. There is a breadcrumb under the main title to show where you are at in the folder hierarchy.
You can move private visualizations, which are visualizations that are currently in your private space 'My Visualizations', to a public space you have access to. To do that, you can right click on the visualization you want to move and from the context menu click on Move.
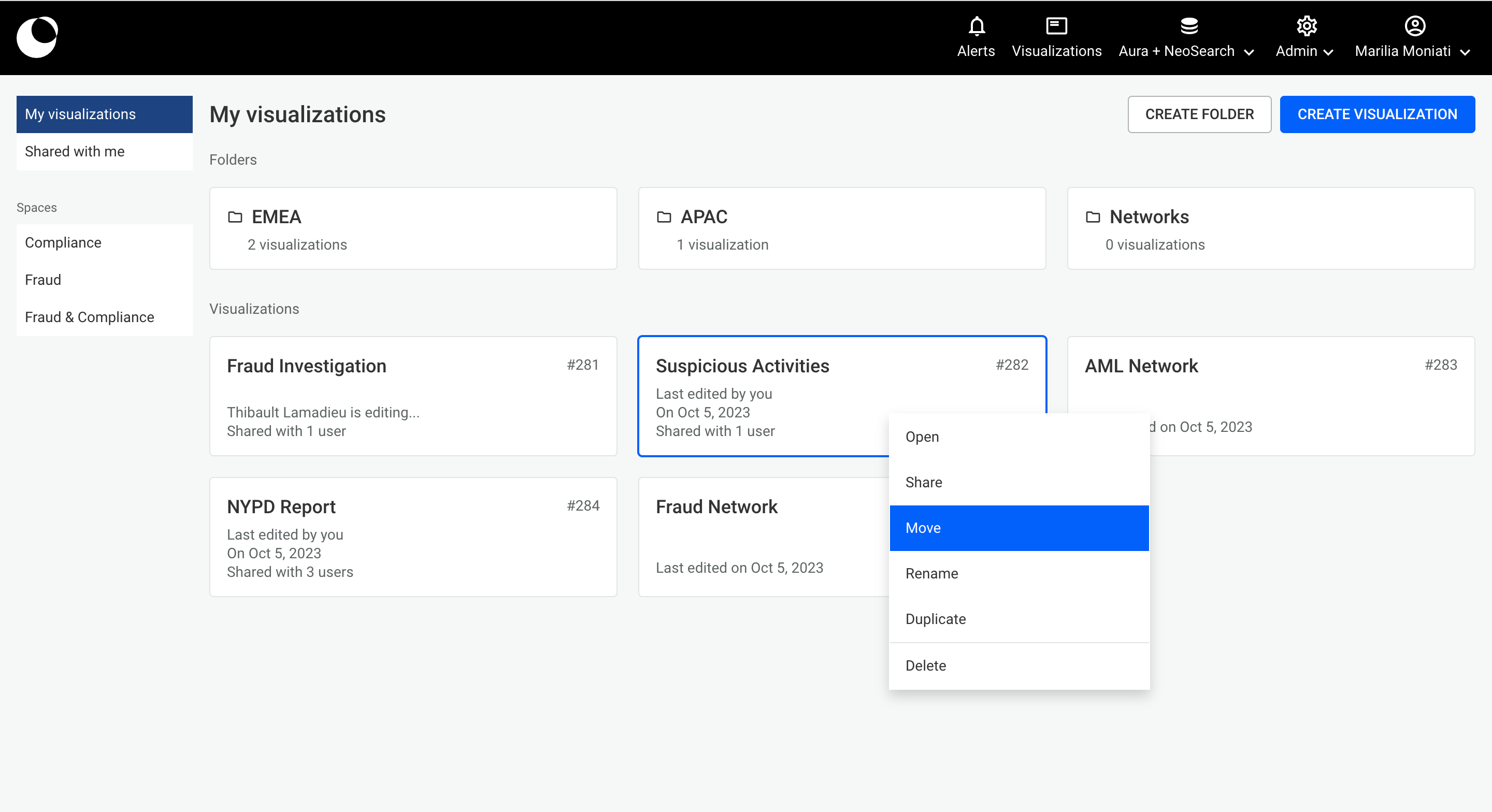
A visualization that is being edited by another user cannot be moved.
After clicking on Move you will be prompted to a modal similar to the one shown below. There, you will be able to find all the possible folders within your private space as well as all the public spaces and their folders that you can move your visualization to.
Once you have selected which space you want to move your visualization to you will be able to see who has access to it, in order to make sure that everyone you intended to share your visualization to is present in the selected space.
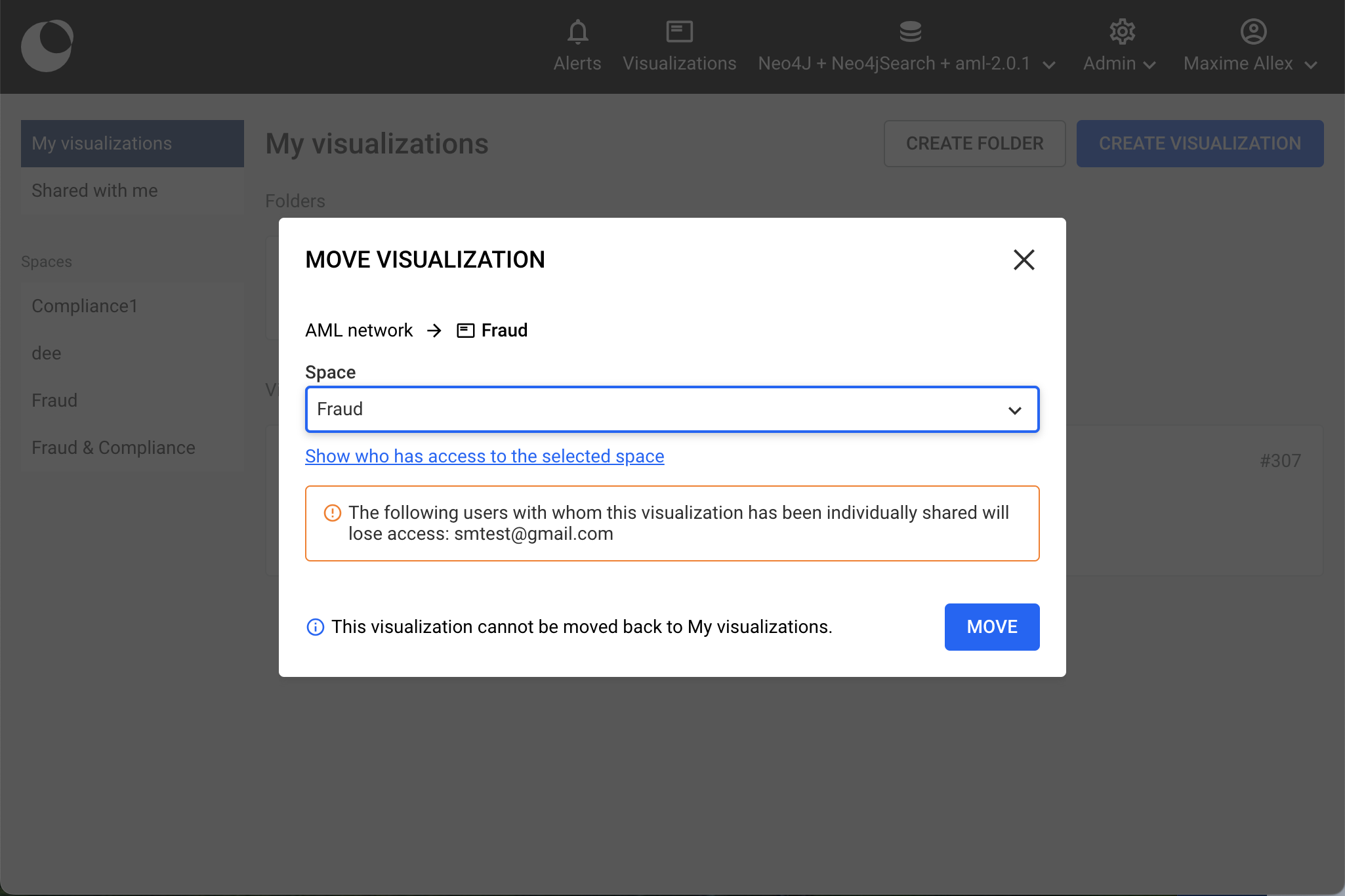
The move to a public space is final and can not be reverted.
After clicking on move, your visualization will be moved to the selected space, in our case to the Fraud space. Everyone who has access to the Fraud space will be able to access the visualization. All the filters, styles, comments, layouts and publications of the visualization will remain untouched when it's moved to the new space.
Users who the visualization was shared with but do not have access to the public space it has moved to, will lose access to it.
It is possible to share a visualization with another Linkurious Enterprise user. People we share a visualization with will be able to access it through the interface. If we right-click on a visualization, we can share it as follows:
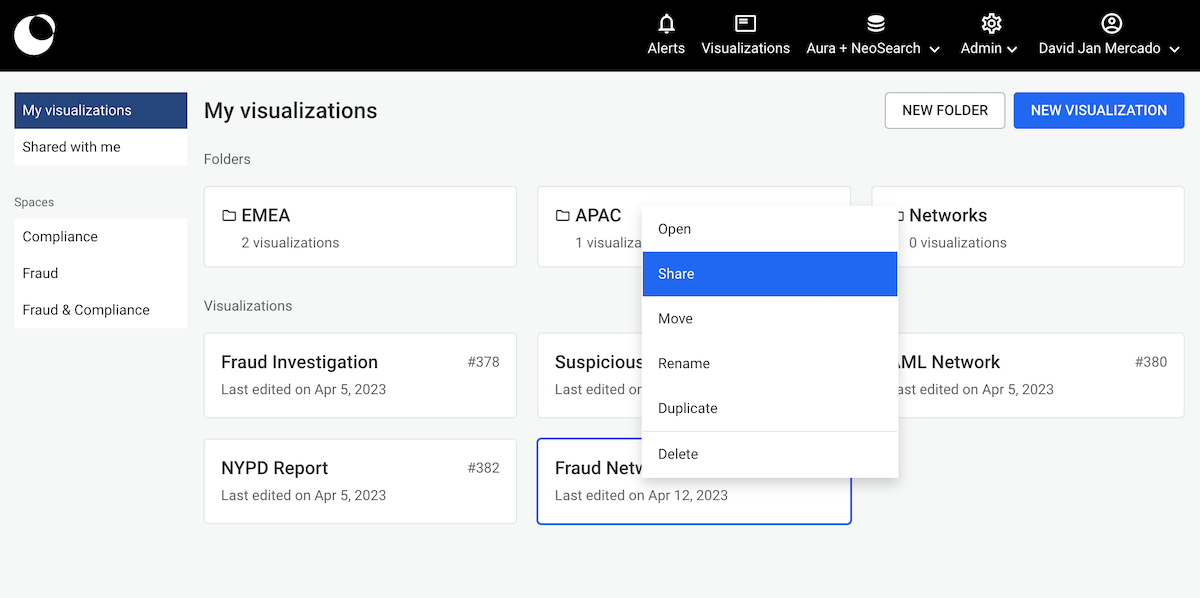
We click on the Share menu and type the username or email of the
person we want to share the visualization with.
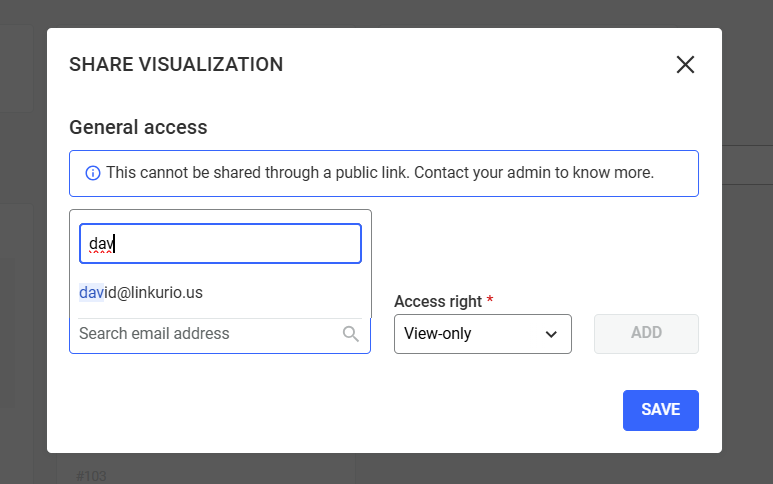
Then choose the access right for that person: View-only, Edit, or Edit and share.
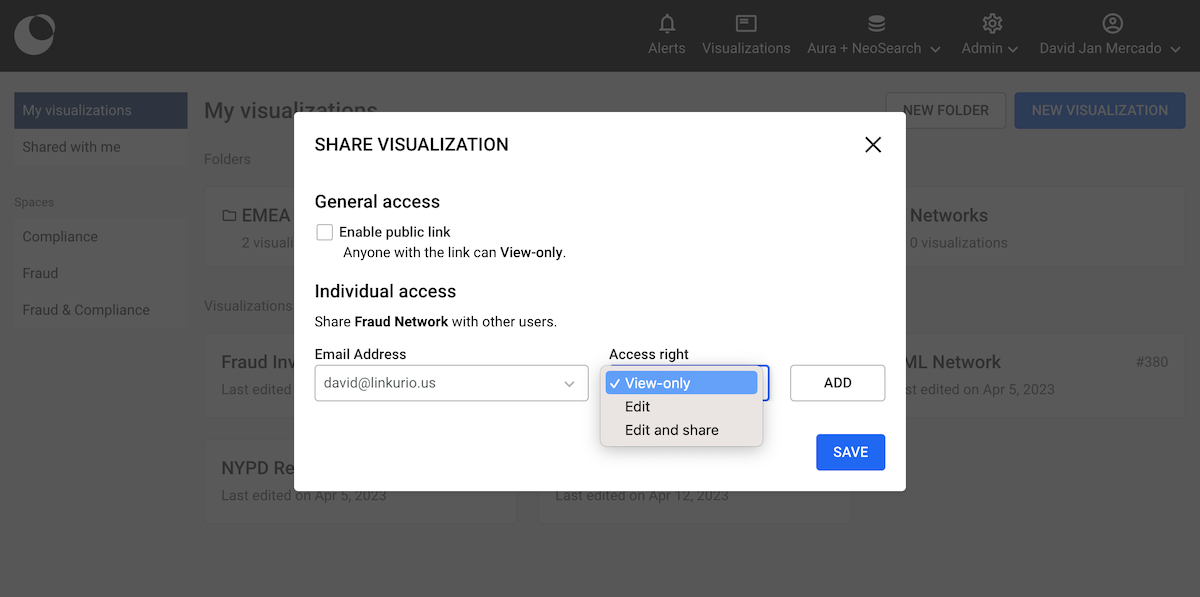
Then click Add, and finally Save to complete the share.
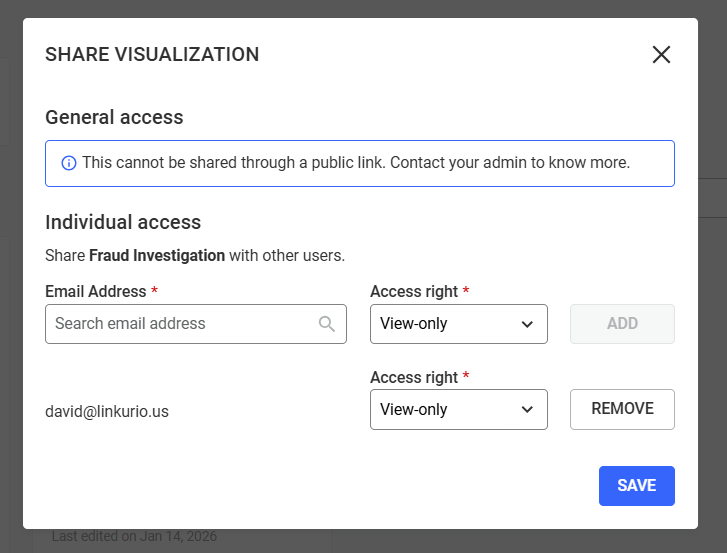
Your visualization is now shared with one user.
It is possible to duplicate a visualization. This feature might be useful when we want to try new things in our visualization and keep a record of the last version, this way the duplicate is used as a draft.
It is possible to duplicate a saved visualization from the dashboard as follows:
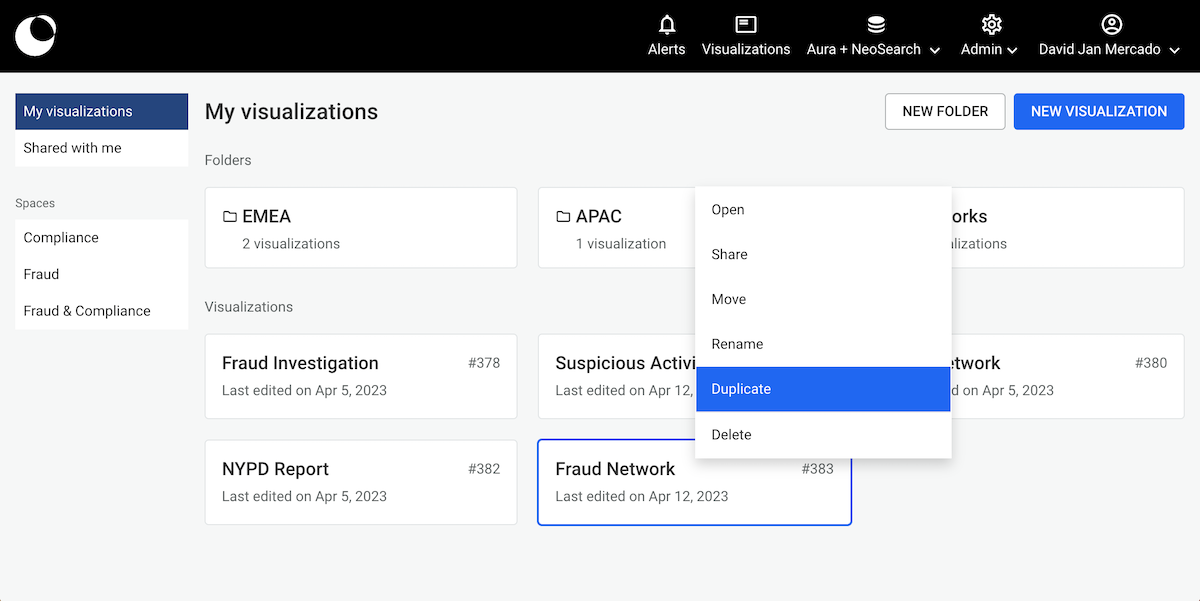
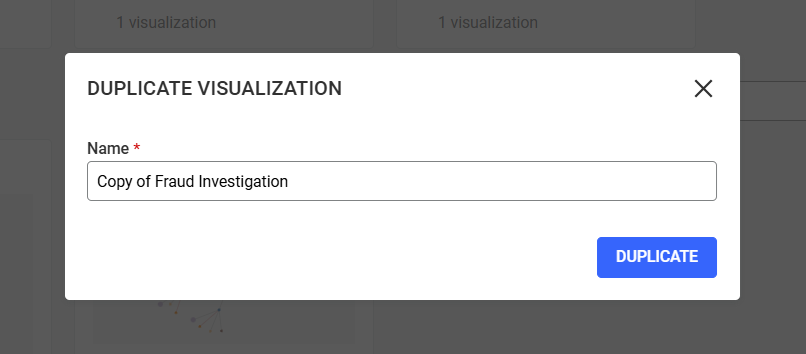
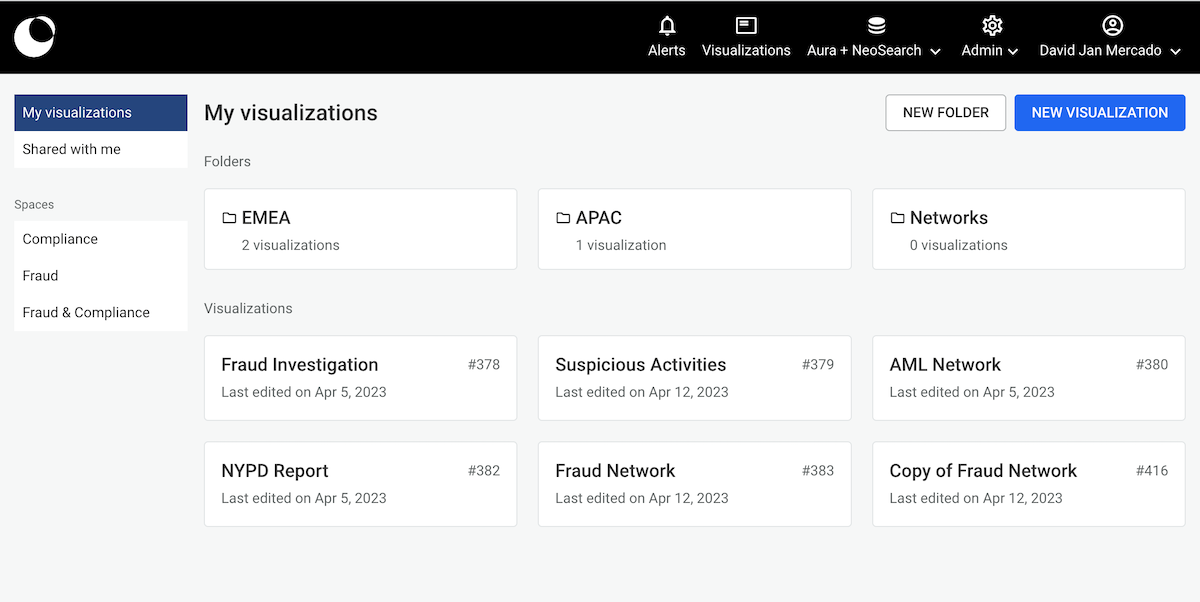
We then click on Duplicate and a copy of our visualization is
displayed and directly accessible on the dashboard:
It is also possible to duplicate a saved visualization from the workspace via the "Duplicate" function in the Menu:
The copy is then accessible from the dashboard.
Note that after duplicating from the workspace, the document we are then working on is the copy of the visualization.
It is possible to duplicate a visualization shared with you by another user.
If a user has shared a visualization with you but you are not allowed to modify it, duplicate this visualization. You will be able to modify the copy.
If the duplicate is done in a space, the copy remains in that space and inside a folder if created within a specific folder.
In this chapter, we will learn how to create, manage and use queries! Queries are a powerful tool which helps users transform the way they work by accelerating and automating their investigation process. With the use of queries, a multi-step process can be shortened to a one-click one!
By eliminating the need for manual coding, the No-Code Query Builder is a powerful tool that empowers all users to access the insights they need faster and more efficiently.
It allows you to create custom queries without writing a single line of code. Whether you're a seasoned data analyst or new to data exploration, the No-Code Query Builder makes it easy to access and manipulate data with just a few clicks. Benefits of the No-Code Query Builder
The No-Code Query Builder is accessible from the visualization workspace.
 Follow these steps to access it:
Follow these steps to access it:
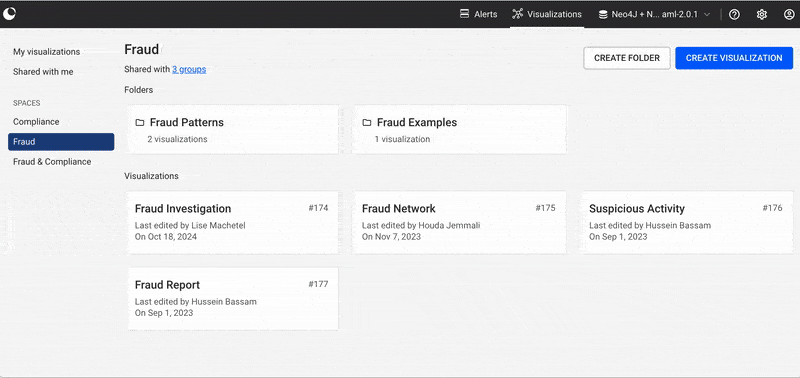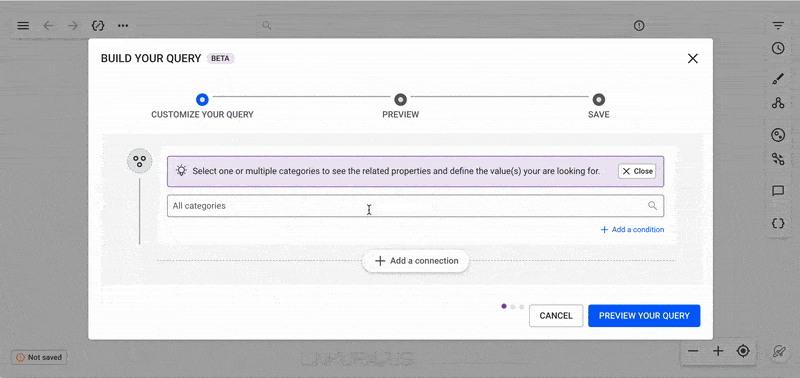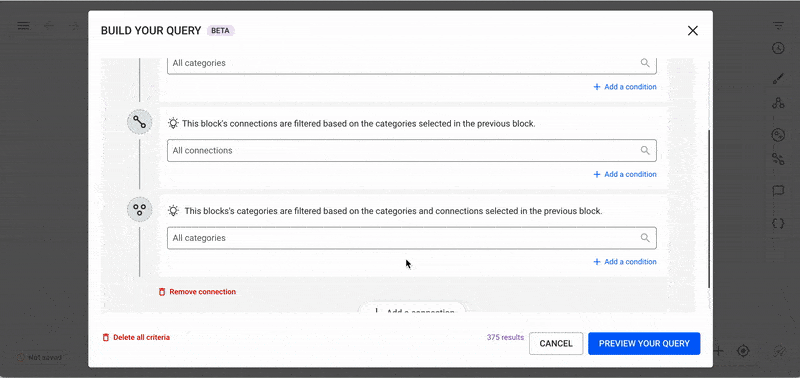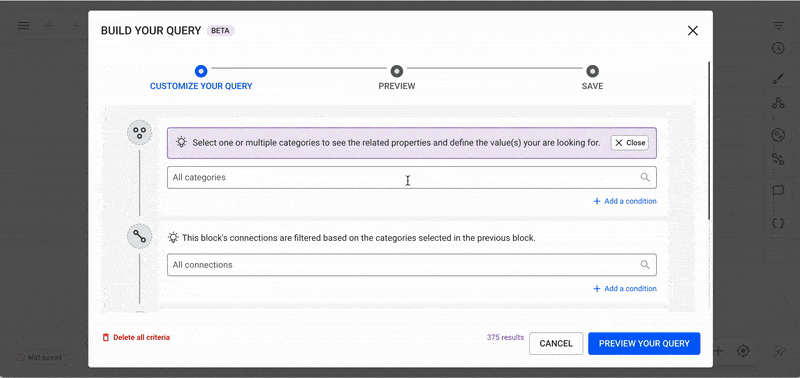
When you open the No-Code Query Builder, you will see the following interface, which includes the first node block of your query.
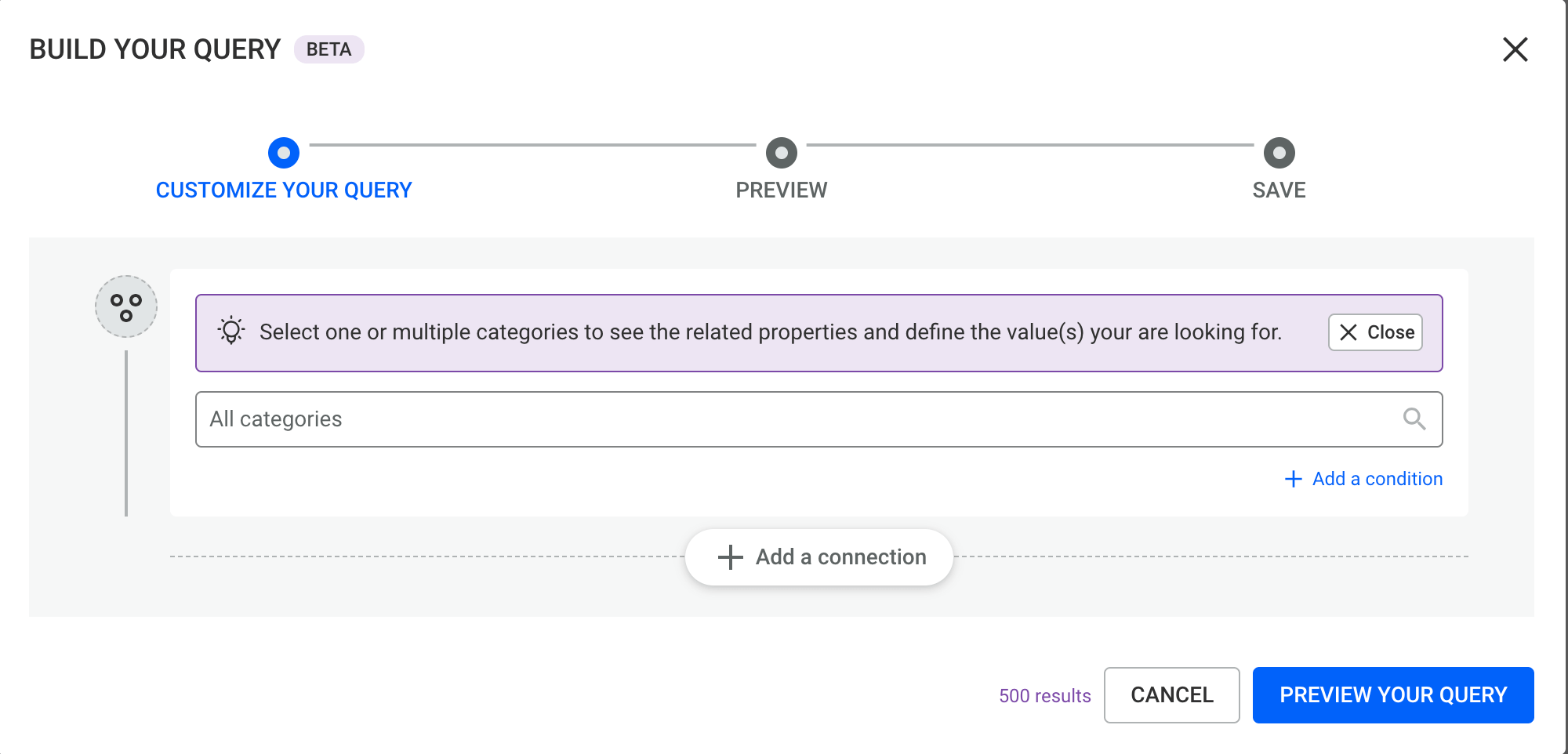
The first block represents a node, where you can filter by one, multiple, or all node categories.
Once node categories are selected, refine your query further by clicking "Add a condition" to filter by property values.
Available operators and values depend on the property type.
To build more complex queries that return sub-graphs rather than isolated nodes:
Click "+ Add a connection" to create relationships between nodes.
This action generates:
You can continue adding as many connections as needed while monitoring the estimated result count.
Find All Mortgage Loans in Miami with a Duration of 5+ Years
Filters:
MortgageLoan (city = Miami, duration >= 5 years)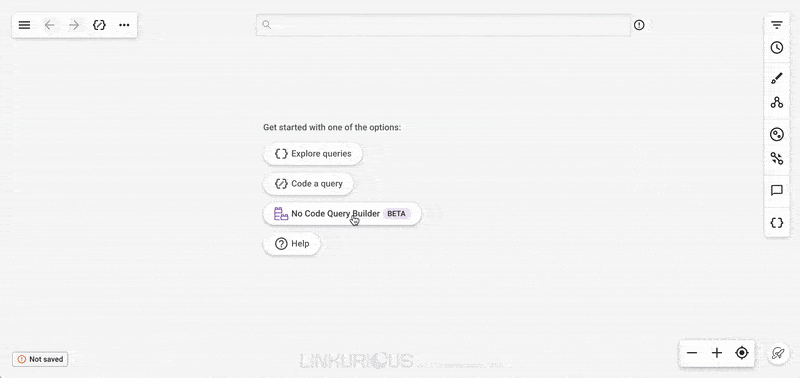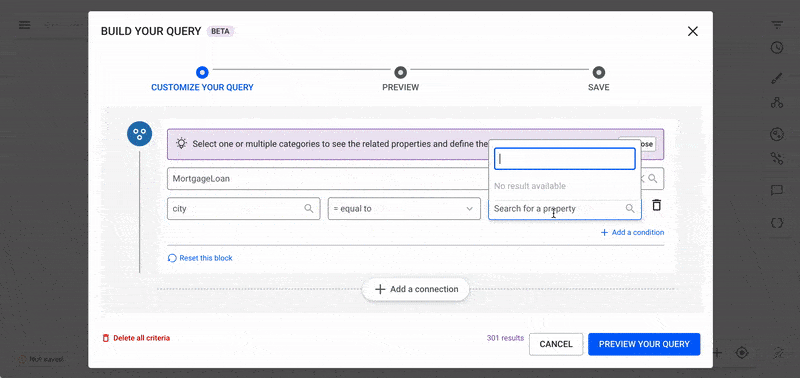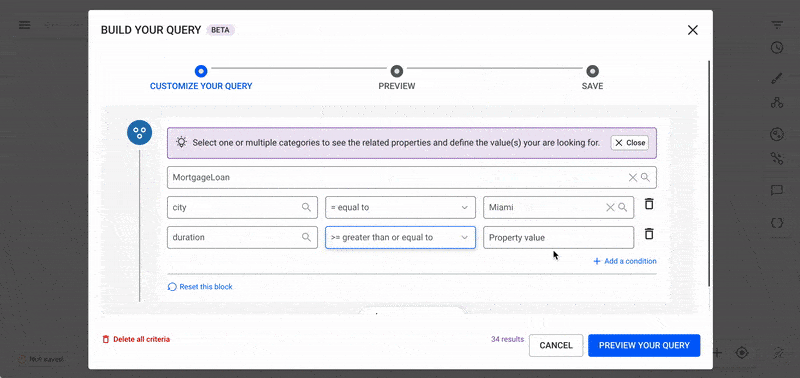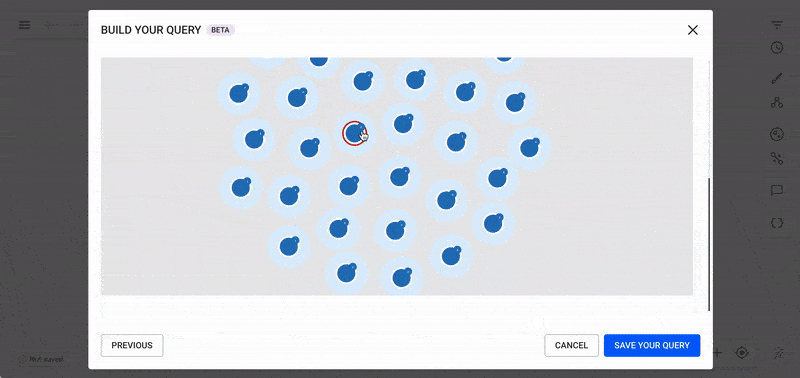
Find People with Annual Revenues > 100k Controlling Companies with Annual Turnover > 1M
Filter:
PERSON (annual_revenues > 100,000) HAS_CONTROL COMPANY (annual_turnover > 1,000,000)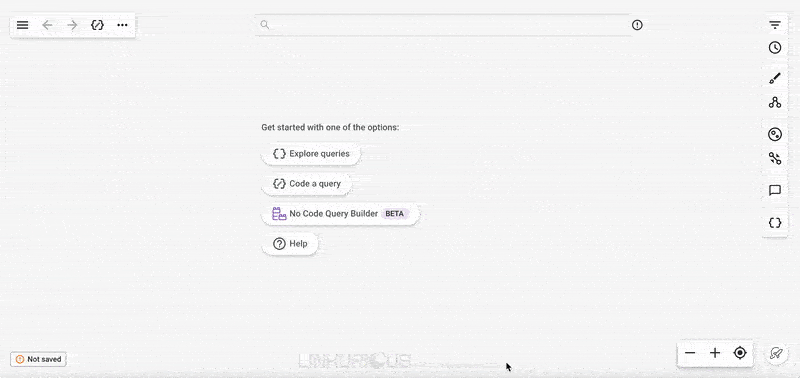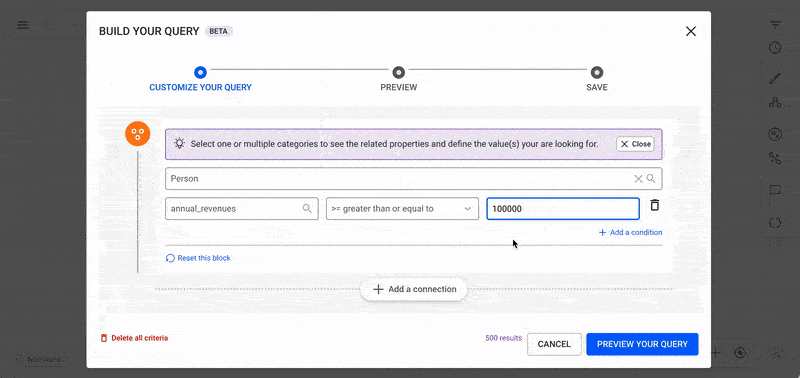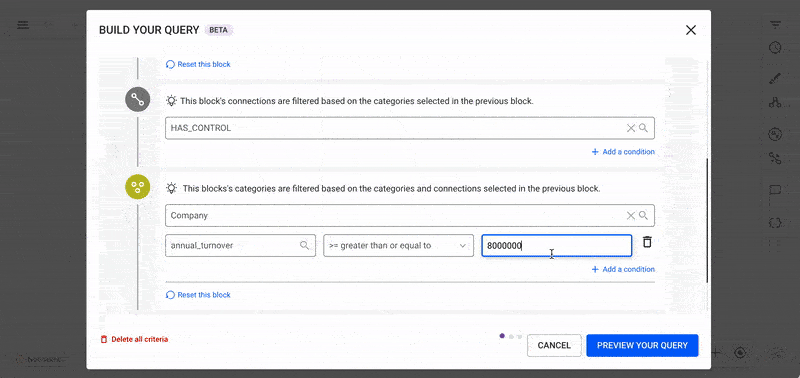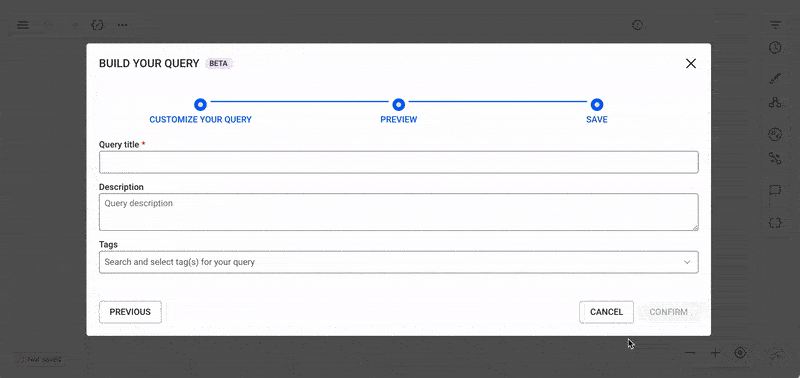
Find the first and last child birth of the 20th century.
Filters:
person (DoB is between 1999-12-31 AND 2000-01-01)
Useful Tips
Reset this block. Given that query blocks are inter-connected, make sure that your query is still correct when resetting blocks.Delete all criteriaRemove connection.After creating your query, you can click on PREVIEW YOUR QUERY, where you can view the cypher code produced and by clicking on Preview Results you can view the graph elements which your query will be returning.
Once you have built, tested and perfected your query, you can save it for later use in the next step by selecting NEXT.
When saving a query, the user is prompted for a Query title, a Description and Tags.
Query tags make queries easier to find after creation. When saving a query, you can add one or more existing tags to it and create new ones.

Queries built with the No-Code Query Builder are private and accessible only by their creator.
Saved queries can be accessed from the right panel of the workspace. From there, you can run, edit and delete your queries. Learn more about it in here.
Queries in Linkurious Enterprise are written using a graph query language. Linkurious Enterprise supports several graph databases: Neo4j, Memgraph, Neptune and Cosmos DB. Neo4j and Memgraph support the Cypher query language while Cosmos DB support the Gremlin query language.
Neptune now supports both Gremlin and Cypher, giving you the flexibility to choose the query language that best fits your needs. When querying Neptune, you can easily select which query language to use based on your preferences. Below is a screenshot showing how to pick the query language when querying Neptune:

The Cypher query language is similar to SQL, it can be learned from Neo4j's online documentation.
There are four levels of access rights associated with queries in Linkurious Enterprise.
| Access Right Level | Description |
|---|---|
| Cannot run queries | User can not create or run queries |
| Can run existing queries | User can execute any existing query that has been shared with them. User can not create new queries. |
| Can create read-only queries and run existing queries | User can execute any existing query that has been shared with them. User can not create queries that will alter the data (a.k.a. write-queries). |
| Can create read/write queries and run existing queries | User can execute any existing query that has been shared with them. User can create queries. |
| Can manage, create read/write queries and run queries | User can execute, edit and delete any existing query that has been shared with as least 1 group. This includes hidden queries. |
The above access rights are applied to groups. The group a user belongs to defines their query access rights.
A query can have dynamic inputs (e.g. {{"Country":string:["France","Germany"]}}) that
are used to parameterize the query. When a query has dynamic input, it will require the
input to be provided to run. Query inputs can be of different types, such as nodes, edges,
text, numbers, etc.
If a query creates, deletes or updates the graph, it is called a write-query. Creating a write-queries is subject to the user's access rights.
A query must return nodes and edges. Any other value return by the query (numbers, text) will be ignored.
The query creator is where users can create, test and save new queries.
It can be accessed by clicking on the {🖊} icon in the top-left of a visualization.
The Query creator menu is split in two parts:

The query editor helps you create queries using the autocompletion for the Cypher query language. The Cypher autocompletion is aware of the schema and depending on the user's action suggests node categories, edge types or Cypher keywords.
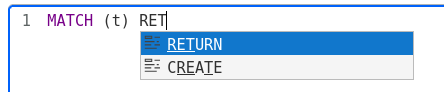
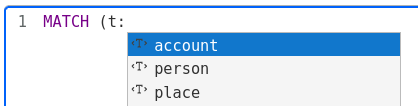

When users have written, tested and perfected a query, they can save it for later use in the next step by selecting NEXT.
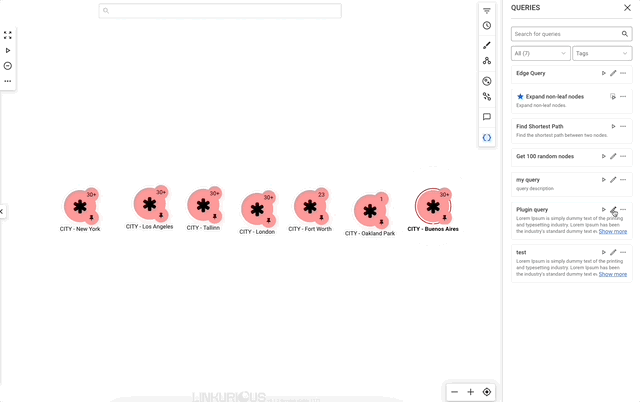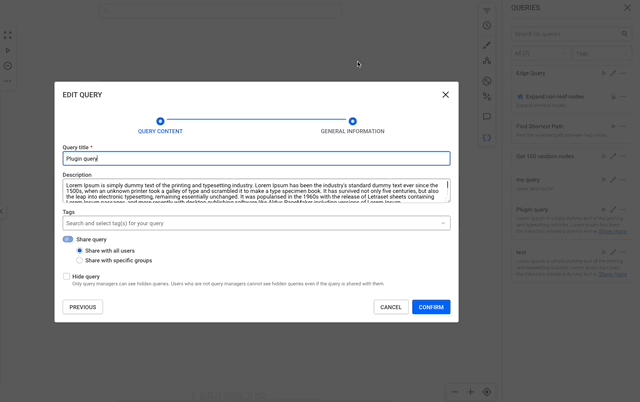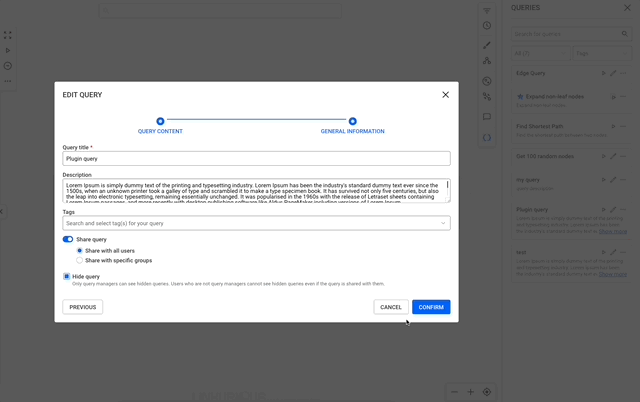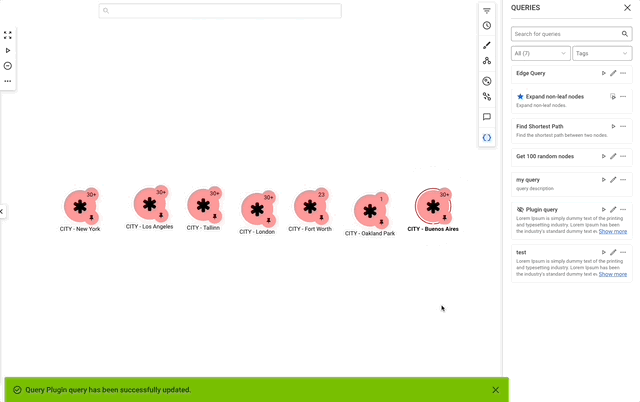
When saving a query, the user is prompted for a Query title, a Description, Tags and Sharing settings.
Query tags make queries easier to find after creation. When saving a query, you can add one or more existing tags to it and create new ones.
Queries can be kept private, shared with everybody or shared specific user groups. Some important information on shared queries:
Saved queries can be consulted from the right panel of the workspace.
The section below provides examples of different types of queries that users can create and use.
The following query returns all City nodes that have between 3 and 100 Company nodes
connected to them via HAS_CITY edges:
MATCH (city:City)<-[hasCity:HAS_CITY]-(company:Company)
WITH
city,
count(company) as score,
collect(company) as companies,
collect(hasCity) as hasCities
WHERE score > 3 AND score < 100
RETURN city, companies, hasCities

The following query changes the profession of a person and adds some change logs in a property:
MATCH (n)
WHERE ID(n) = {{"Suspicious entity":node:["Person"]}}
WITH
n,
apoc.date.currentTimestamp() AS currentTimestamp
SET n.change_log =
"Modification done by: " + {{"User":env:"email"}} +
" on: " + toString(datetime({epochMillis: currentTimestamp})) +
". Previous value: " + n.profession +
". Comment: " + {{"Comment":string:{"placeholder": "Add a note..."}}}
SET n.profession = {{"Profession":string}}
RETURN n;
Queries that write in the database can be shared with any user group, including those that were not granted "Write" permissions on any node category. Be considerate as to who you share queries with, and who has the right to share queries (see "Access Right" section in administration manual).
The following query returns up to max nodes of type COMPANY that are neighbours of the
input node:
MATCH (n)-[edge]-(company:Company)
WHERE id(n) = {{"Node":node}}
RETURN edge, company
LIMIT {{"max":number:10}}

Single-node queries can be run on multiple nodes at once, the same way it is possible to expand multiple nodes at once.
The following query is a built-in query that finds the shortest path between two nodes:
MATCH (a), (b), p = allShortestPaths((a)-[*..{{"Maximum path length":number:{"default": 4, "min": 1, "max": 10}}}]-(b))
WHERE id(a) = {{"Source":node}} AND id(b) = {{"Target":node}}
RETURN p LIMIT {{"Maximum number of paths":number:{"default": 5, "min": 1, "max": 50}}}

The following query returns only the nodes that are shared neighbours to each and every node of the input nodeset:
MATCH (n) WHERE id(n) IN {{"My nodes":nodeset}}
MATCH (n)-[e]-(m)
WITH m, collect(e) AS edges, count(distinct n) AS sharedNeighborCount
WHERE sharedNeighborCount = size({{"My nodes":nodeset}})
RETURN m, edges

The following query returns all the parallel edges of the selected node:
MATCH (a)-[e]->(b) WHERE id(e) in {{"edge":edge}}
MATCH (a)-[e2]->(b)
RETURN a, e2, b
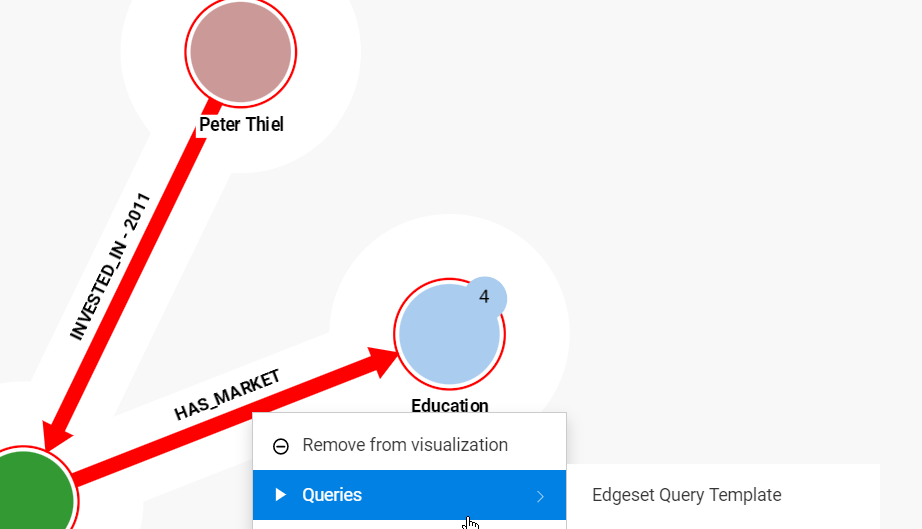
The following query returns only the edges that share a node with the edgeset input:
MATCH (n)-[e:INVESTED_IN]-() WHERE id(e) IN {{"My edges":edgeset}}
MATCH (n)-[e2:INVESTED_IN]-(m)
RETURN e, e2, n, m
This section provides a deep-dive into the different types of input variables can be used in queries.
To declare inputs in a query, use double curly braces to mark the start and end of input, for example:
MATCH (n)-[e]-(m) WHERE id(n) = {{"My node":node}} RETURN e, m
An input variable is made of 3 terms separated by a colon (:), the first 2 being mandatory:
node, nodeset, edge, edgeset, string, number, date, datetime, enum, env, list.A Query requiring input can take both graph and non-graph input:
node or nodeset)edge or edgeset)number, string, etc.)node variableUsed to inject a single node ID in a graph query:
node.categories (optional): string or array of strings restricting the availability
of input to the specified categories (as a consequence, the query will show in the context
menu only if the selected node has one of the specified categories).Examples:
{{"my node":node:"COMPANY"}} {{"my node":node:["COMPANY","SUPPLIER"]}}{{"my node":node:{"categories": ["COMPANY","SUPPLIER"]}}}nodeset variableUsed to inject a list of node IDs in a graph query:
nodesetcategories (optional): Same as for node type.Examples:
{{"my nodes":nodeset:"COMPANY"}}{{"my nodes":nodeset:["COMPANY","SUPPLIER"]}}{{"my nodes":nodeset:{"categories": ["COMPANY","SUPPLIER"]}}}edge variableUsed to inject a single edge ID in a graph query:
edge.types (optional): string restricting the availability of the input to the specified
categories (as a consequence, the query will show in the context menu only if the selected
edge has the specified type).Examples:
{{"My edge":edge:["INVESTED_IN"]}}{{"My edge":edge:{"types": ["INVESTED_IN"]}}}edgeset variableUsed to inject a list of edge IDs in a graph query:
edgesettypes (optional): Same as for edge type.Examples:
{{"My edges":edgeset:["INVESTED_IN"]}}{{"My edges":edgeset:{"types": ["INVESTED_IN"]}}}enum variableUsed to inject a string, numerical or boolean value in a graph query, from a list of choices:
enumvalues (required): An array of values to choose from or an array of value + label.default (optional): A default value, must be one of the valuesExamples:
{{"my enum":enum:["FR", "EN", "US"]}}{{"my enum":enum:[1, 2, 3]}}{{"my enum":enum:[true, false]}}{{"my enum":enum:{"values": ["FR", "EN", "US"], "default": "EN"}}}{{"my enum":enum:{"values": [{"label": "France", "value": "FR"}, {"label": "U.S.A", "value": "US"}]}}}boolean variableUsed to inject a true/false value in a graph query:
booleandefault (optional): A default valueExamples:
{{"my choice":boolean}}{{"my choice":boolean:true}}{{"my choice":boolean:{"default": true}}}date variableUsed to inject a date-time in a graph query:
dateformat (required): The serialization format of the date in the query, must be one of:native: serialized as a native Date database objecttimestamp: serialized as a numerical Unix timestamp in secondstimestamps-ms: serialized as a numerical Unix timestamp in millisecondsiso: serialized as a "yyyy-mm-dd" string (same as yyyy-mm-dd)yyyy-mm-dd: serialized as a "yyyy-mm-dd" string (same as iso)dd/mm/yyyy: serialized as a "dd/mm/yyyy" stringmm/dd/yyyy: serialized as a "mm/dd/yyyy" stringdefault (optional): A default value (expressed in "yyyy-mm-dd" format)min (optional): The minimum accepted value (expressed in "yyyy-mm-dd" format)max (optional): The maximum accepted value (expressed in "yyyy-mm-dd" format)Examples:
{{"my date":date:"yyyy-mm-dd"}}{{"my date":date:{"format": "yyyy-mm-dd"}}}{{"my date":date:{"format: "timestamp-ms", "min": "2018-01-02"}}}{{"my date":date:{"format": "yyyy-mm-dd", "default": "2018-01-01"}}}{{"my date":date:{"format": "native", "min": "1990-12-31", "max": "2018-12-31"}}}datetime variableUsed to inject a date-time in a graph query:
datetimeformat (required): The serialization format of the date-time in the query, must be one of:native: serialized as a native DateTime database objecttimestamp: serialized as a numerical Unix timestamp in secondstimestamps-ms: serialized as a numerical Unix timestamp in millisecondsiso: serialized as a "yyyy-mm-ddThh:mm:ss" stringtimezone (optional): A string in +HH:MM or -HH:MM format. If omitted and the format is "native', a LocalDateTime object is created.default (optional): A default value (expressed in "yyyy-mm-ddThh:mm:ss" format)min (optional): The minimum accepted value (expressed in "yyyy-mm-ddThh:mm:ss" format)max (optional): The maximum accepted value (expressed in "yyyy-mm-ddThh:mm:ss" format)Examples:
{{"my date-time":datetime:"native"}}{{"my date-time":datetime:{"format": "native"}}}{{"my date-time":datetime:{"format": "iso"}}}{{"my date-time":datetime:{"format":"native", "min": "2017-01-02T10:10:10"}}}{{"my date-time":datetime:{"format":"native", "min": "1940-01-01T00:00:00", "max": "2020-01-01T00:00:00", "default": "2000-01-01T00:00:00", "timezone":"+02:00"}}}number variableUsed to inject a numerical value in a graph query:
numberdefault (optional): A default valueplaceholder (optional): The placeholder text to use in the form.min (optional): The minimum accepted valuemax (optional): The maximum accepted valueExamples:
{{"my number":number}}{{"my number":number:12}}{{"my number":number:{"default": 12}}}{{"my number":number:{"min": 0}}}{{"my number":number:{"min": 0, "max": 15.5, "default": 12}}}string variableUsed to inject a string of text in a graph query:
stringdefault (optional): A default valueplaceholder (optional): The placeholder text to use in the form.Examples:
{{"my string":string}}{{"my string":string:"paris"}}{{"my string":string:{"default": "paris"}}}{{"my string":string:{"placeholder": "Enter a city"}}}env variableUsed to inject information about the user who runs the query into a graph query:
envvalue: The type of value that will be injected into a graph query.email: Used to inject email address of the user who runs the query.Examples:
{{"User":env:{"value":"email"}}}{{"User":env:"email"}}list variableUsed to inject a string or numerical array in a graph query, from a list of choices with the possibility of making multiple choices:
listvalues (required): An array of values to choose from or an array of value + label.default (optional): A default value array, must be a subset of the list elements.Examples:
{{"my list":list:["FR", "EN", "TR"]}} {{"my list":list:[1, 2, 3]}} {{"my list":list:{"values": ["FR", "EN", "TR"], "default": ["EN"]}}}Once users are satisfied with their query, they can preview the results of their query by clicking on the PREVIEW YOUR QUERY button. The preview allows users to visualize the results of their query and:
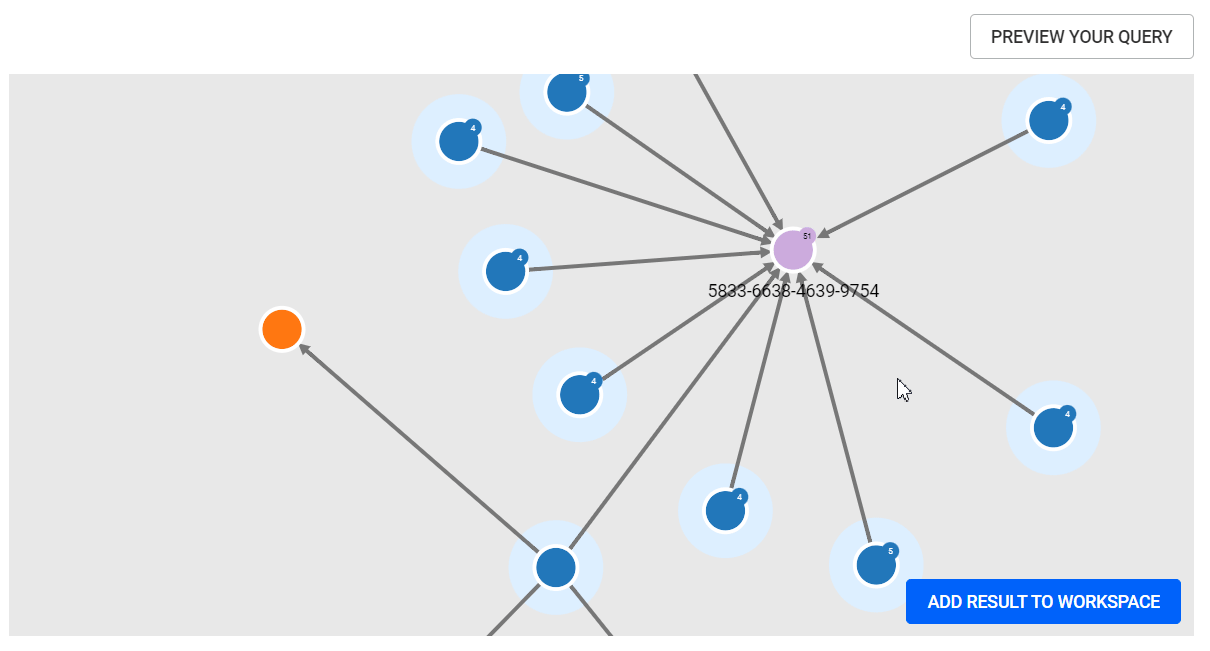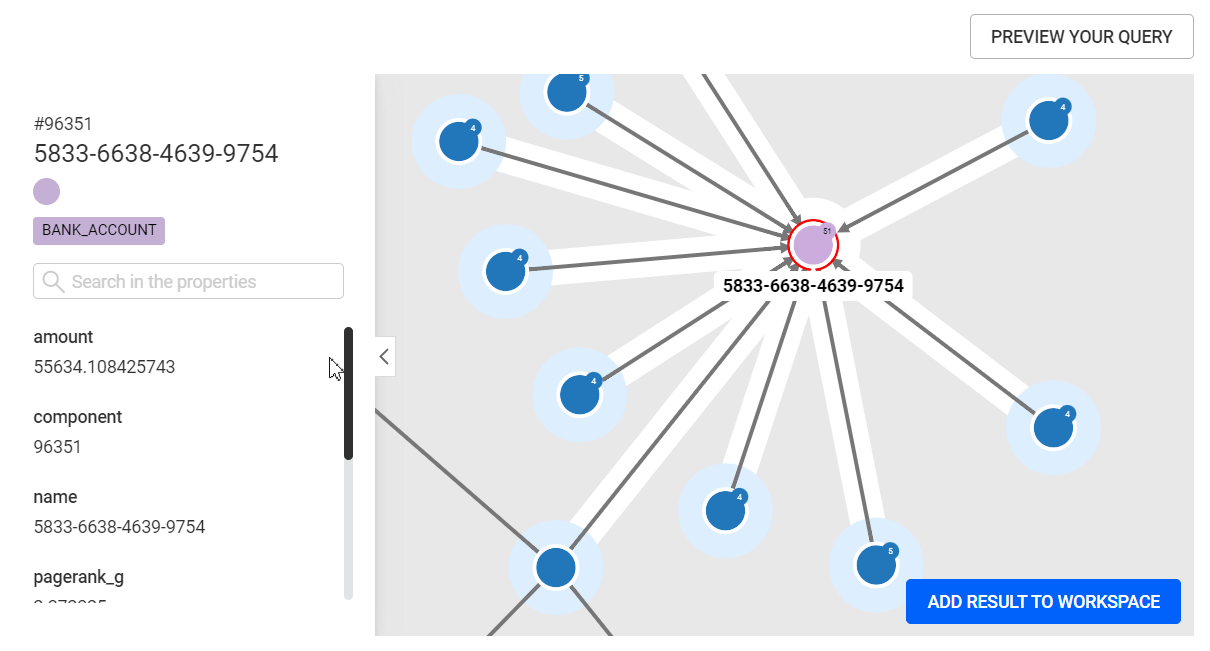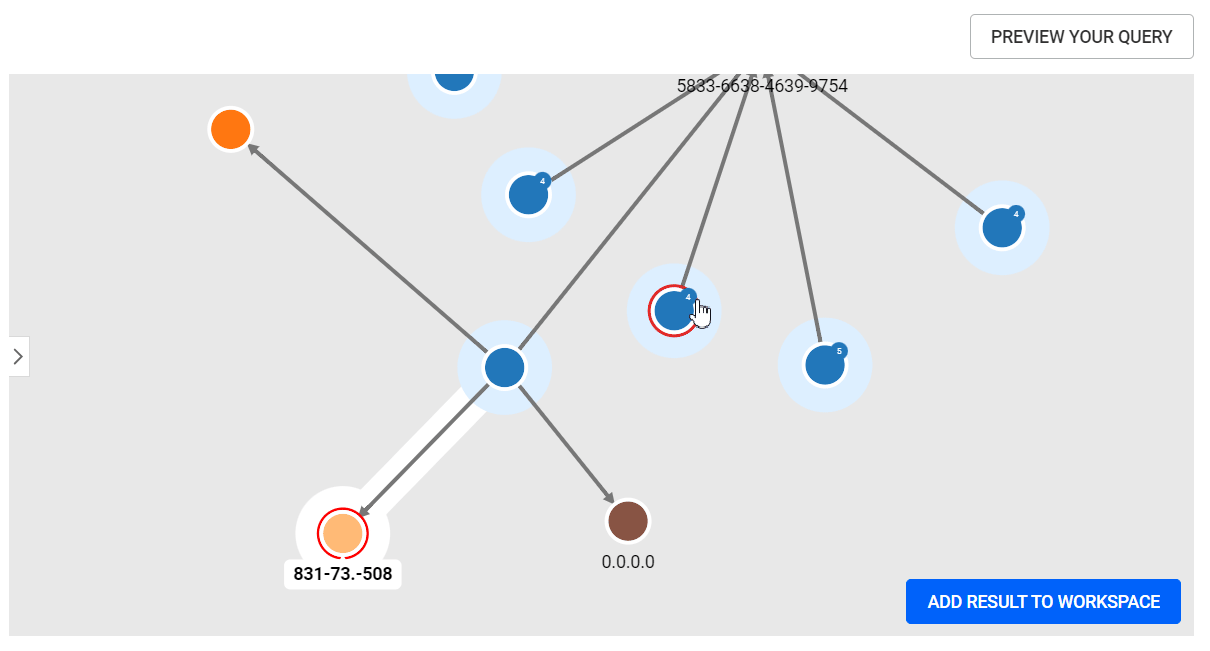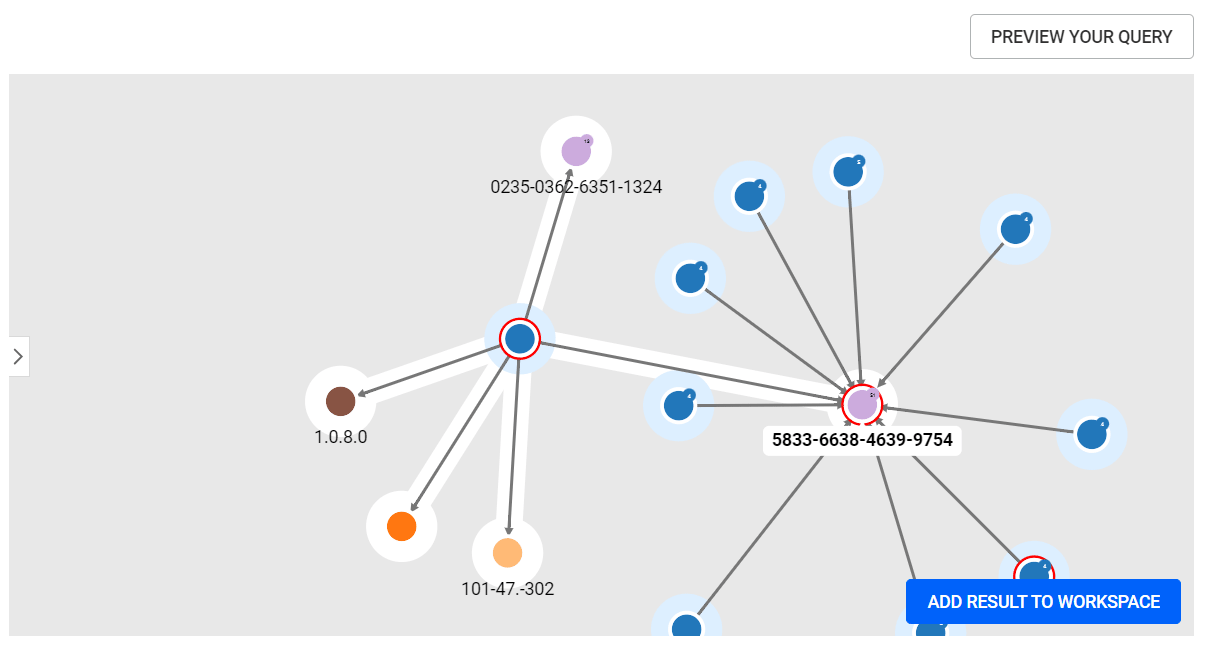
When a query contains input variables, a form is generated and displayed to the right of the query editor, allowing the query to be tested.
Write queries can not be tested.
MATCH (n:PERSON)-[:HAS_ACCOUNT]->(b:BANK {name: {{"name":string}} })
RETURN n, b
CALL statement will be
evaluated based on the access mode (for more info, refer to Neo4j documentation) of called procedure.
The query will either be allowed or denied, depending on the access mode of the query and
the access right of the user.DEFAULT and READ are
considered READ queries in Linkurious Enterprise.DBMS, WRITE,
SCHEMA are considered WRITE queries in Linkurious Enterprise.If your query is returning graph entities (nodes/edges), these entities will have to be wrapped inside the function SAFE_TO_JSON()
Example:
MATCH (p:Person)-[a:HAS_ACCOUNT]->[b:Bank]
RETURN SAFE_TO_JSON(p) AS accountOwner
For more details, please check the following urls:
When using graph elements as dynamic inputs (i.e. node, nodeset, edge, edgeset), you can filter by node ID via the id(n) custom Linkurious Enterprise syntax.
You can filter by a single element (node / edge) with:
MATCH (p:Person)
WHERE id(p) = {{"Person":node}}
RETURN SAFE_TO_JSON(p) AS person
You can filter by a list of elements (nodeset / edgeset) with:
MATCH (p:Person)
WHERE id(p) IN {{"People":nodeset}}
RETURN SAFE_TO_JSON(p) AS person
When filtering by node ID, you cannot also filter the matched nodes by category in the same MATCH clause due to a technical limitation.
For example, this query might fail:
MATCH (p:Person)
WHERE id(p) IN {{"list":nodeset}}
RETURN p.ssn AS ssn
To resolve this, you must filter the node by category after it has been matched.
MATCH (n)
WHERE
id(n) IN {{"target":nodeset}}
AND ARRAY_INCLUDES(LABELS(n), "Person")
RETURN n.ssn AS ssn
When returning non-graph values (for example, node or edge properties) that are defined as INT64 in Spanner, values larger or equal to 2^53 will be skipped. If you want to avoid that, return them as strings using the CAST() function.
This is necessary due to a technical limitation in our platform, which cannot safely represent integers larger than or equal to 2^53. As a consequence, very large INT64 values cannot be represented and are skipped from results.
For example, instead of:
MATCH (p:Person)
RETURN p.accountNumber AS accountNumber
Cast the INT64 property to a string to preserve the full value:
MATCH (p:Person)
RETURN CAST(p.accountNumber AS STRING) AS accountNumber
If your administrator enabled it, it is possible to query the graph using natural language queries thanks to the Query AI feature.
Query AI is a Linkurious Enterprise plugin that allows analysts to query the graph using natural language.
Example:
User: Show me bank accounts owned by more than one person
Query AI:
MATCH (p:PERSON)-[r:HAS_BANK_ACCOUNT]->(b:BANK_ACCOUNT) WITH b, COUNT(p) AS personCount WHERE personCount > 1 RETURN b
Get started:
After a short wait, a graph query is generated and displayed. Once a graph query is generated, several options are available:
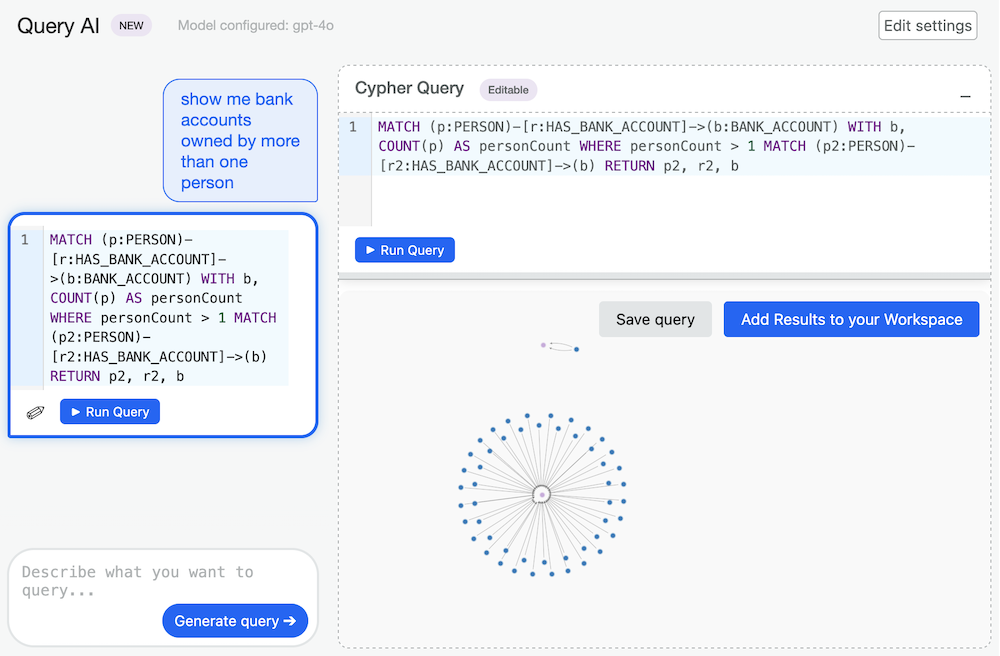
Once a query has been run, you can add the results to your workspace.
Tags are created and associated to queries upon saving queries. Tags can then be viewed and managed in the tags tab of the Resource Management page.
You can find the extensive list of distinct query tags in Resources Management > Tags.
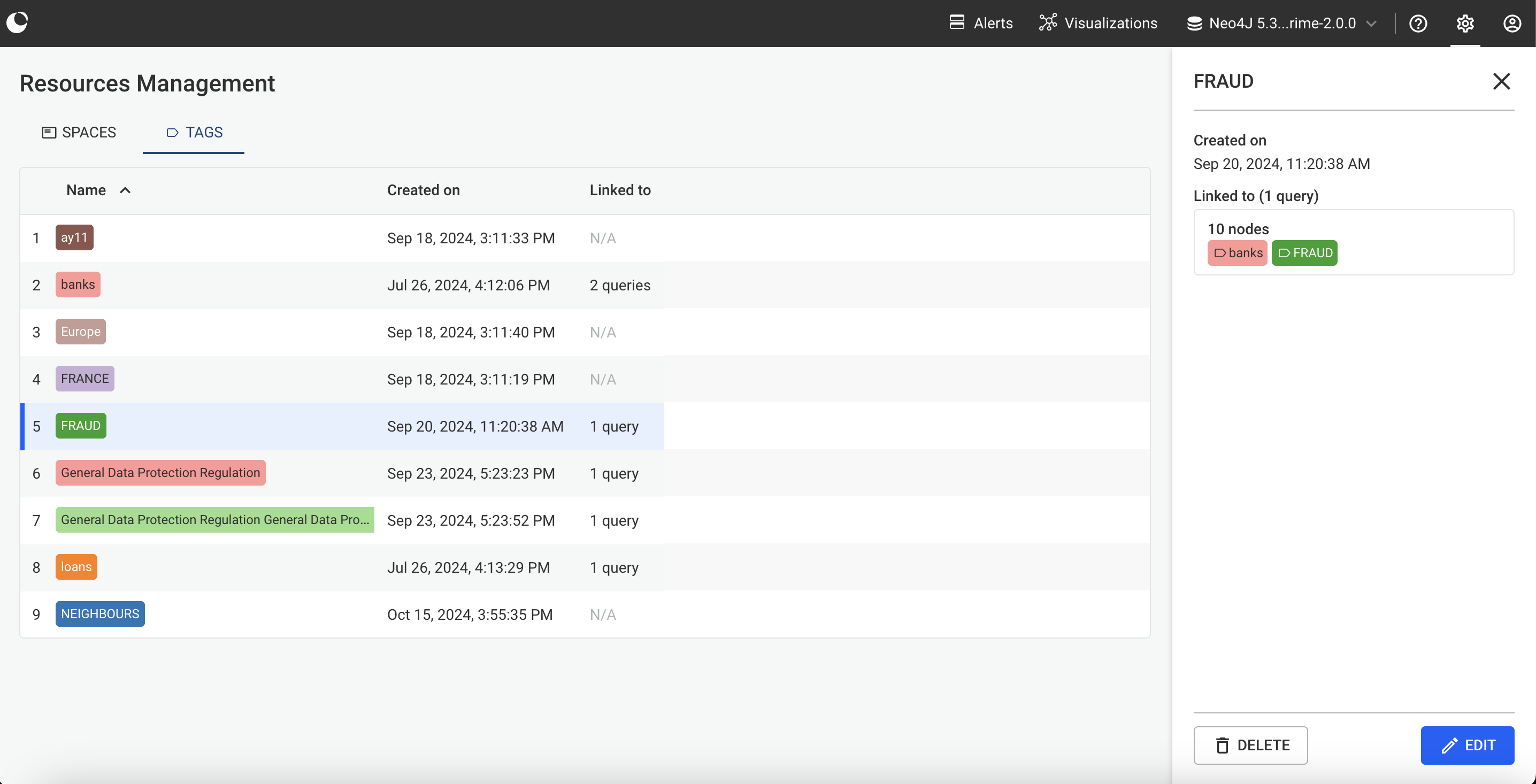
Clicking on a tag's name displays a panel that appears on the right. Tag's panel displays tags creation date and lists all the queries associated with the selected tag.
You can edit a tag by clicking on the "Edit" button at the bottom of the tag's right panel.
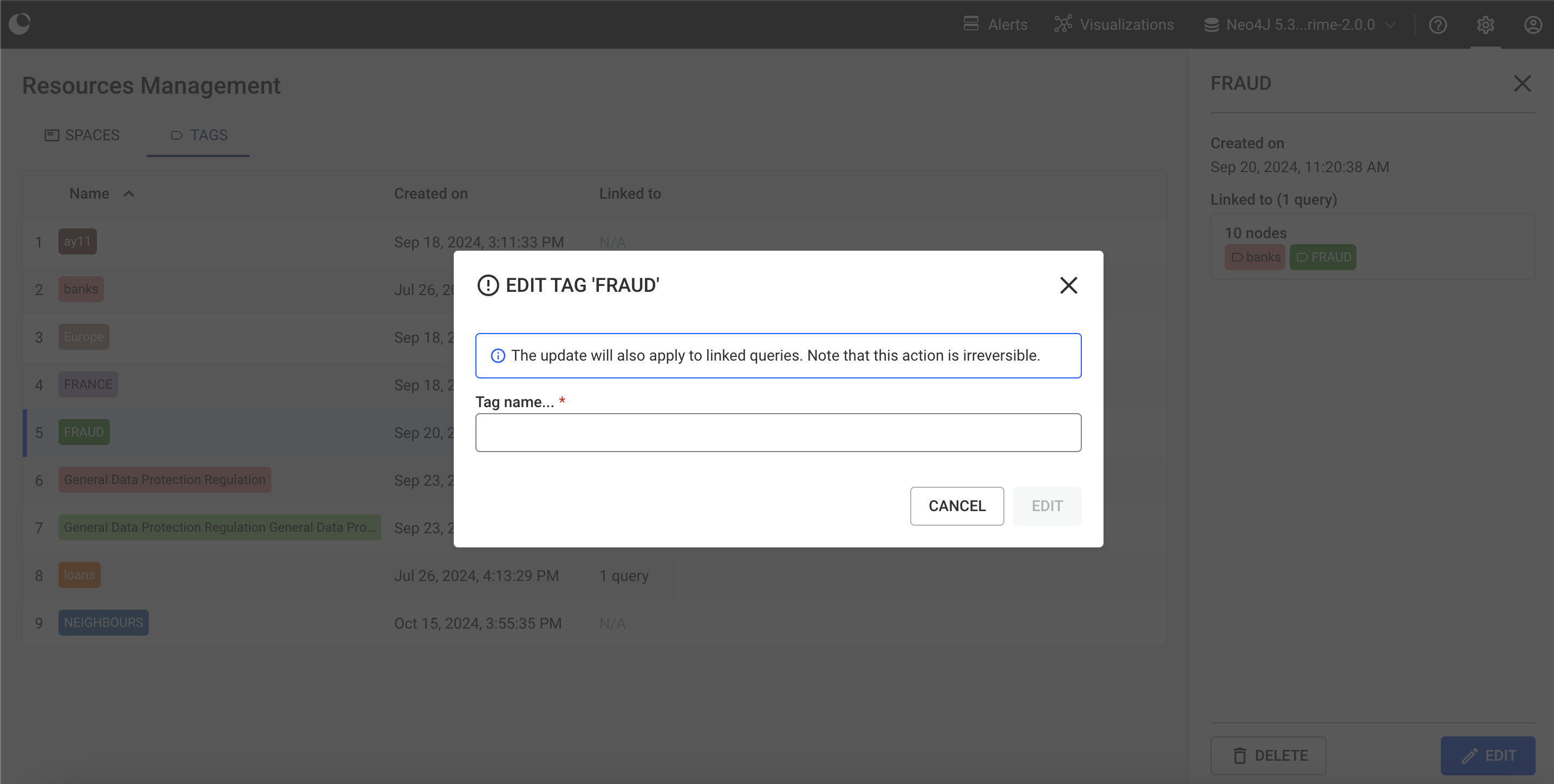
You can delete a tag by clicking on the "Delete" button at the bottom of the tag's right panel. Confirmation will be asked to prevent accidental clicks.
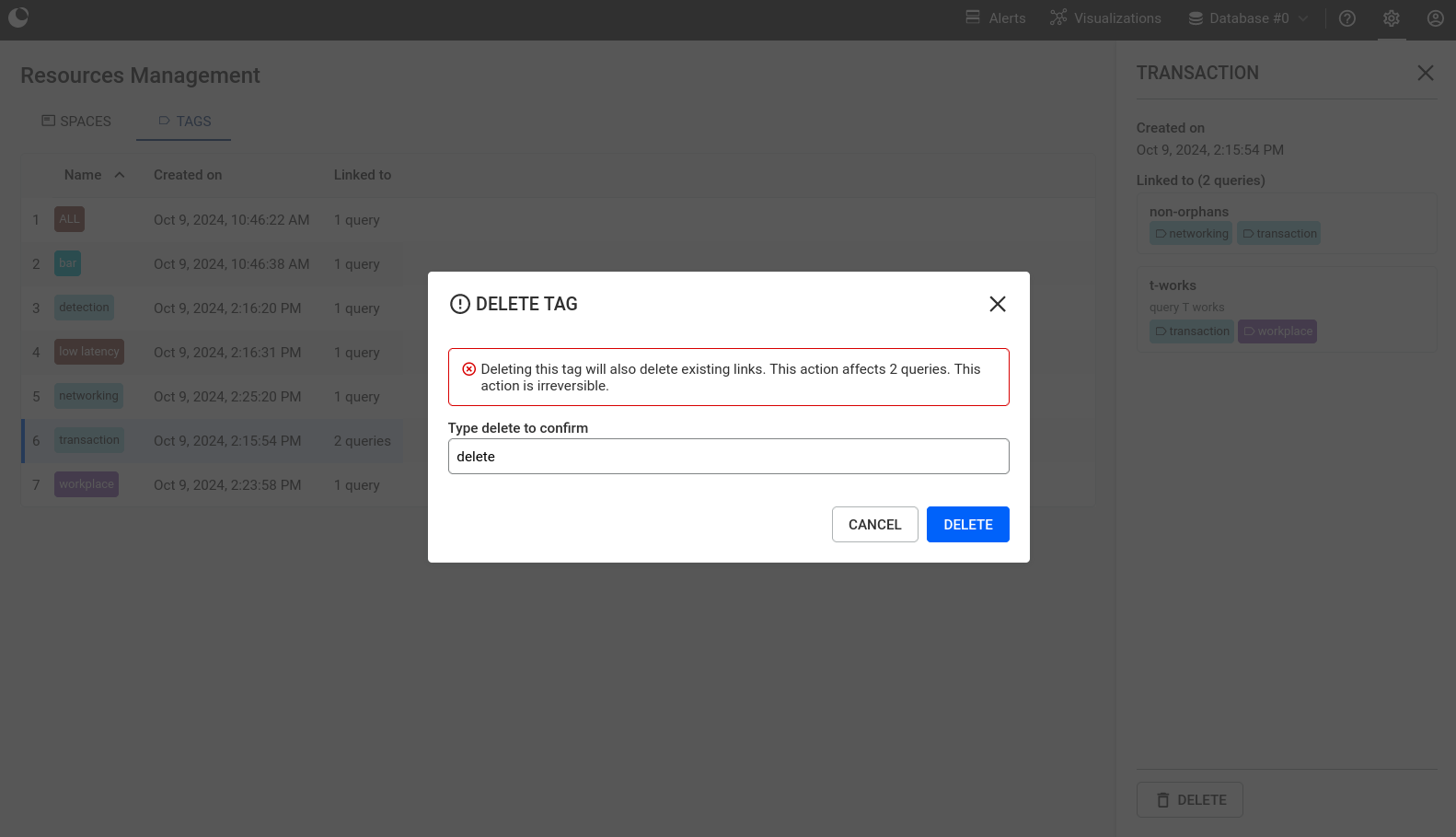
Warning To delete or edit a tag you either need to be the tag's creator OR to have "Can manage, create read/write queries and run queries" access rights.
In this section we will learn how to manage, run and optimise the usage of queries in order to save as much time as possible with the use of this feature!
All queries which users have access to can be reached from the right toolbar on the workspace.
Upon clicking on the {} button, users can view the list of all their queries sorted by name in
alphabetical order.
If a node is selected before opening the query panel, suggested queries will be displayed. Changing that to "All" will show all queries accessible to the user.
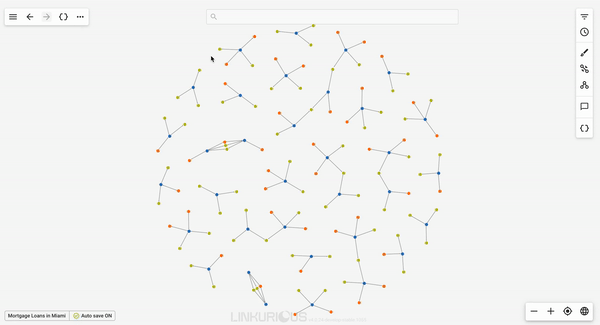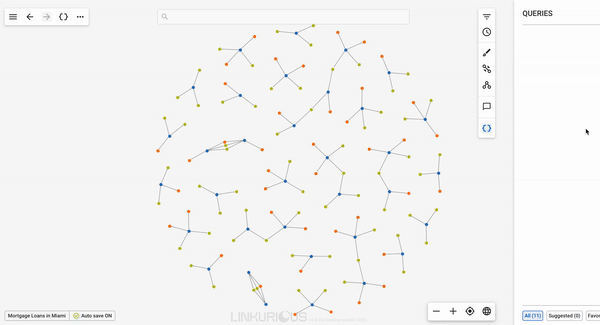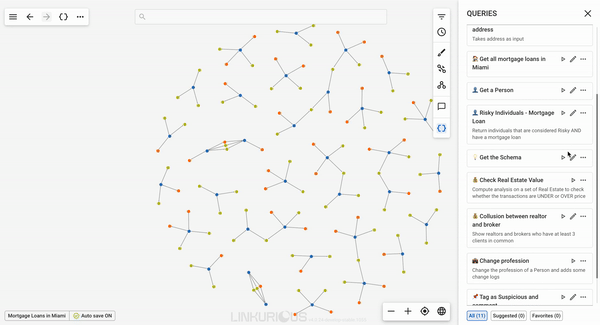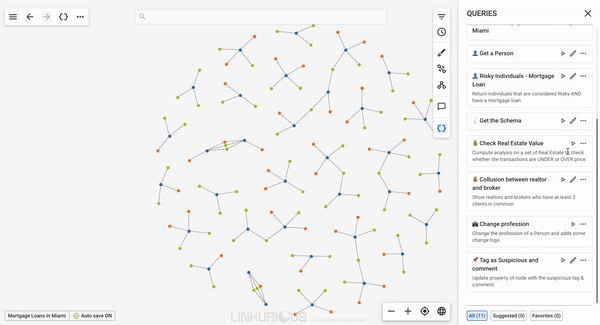
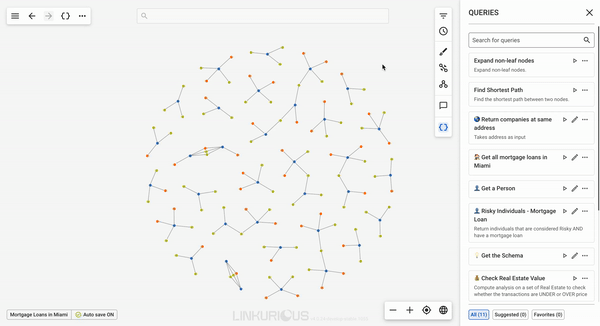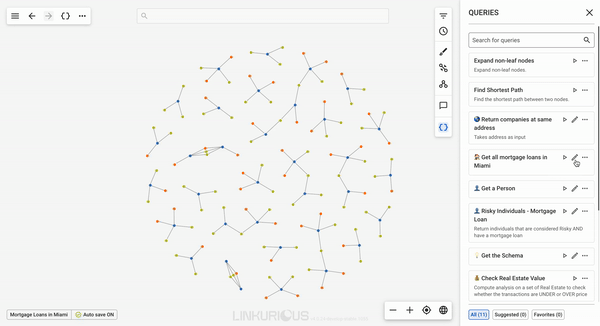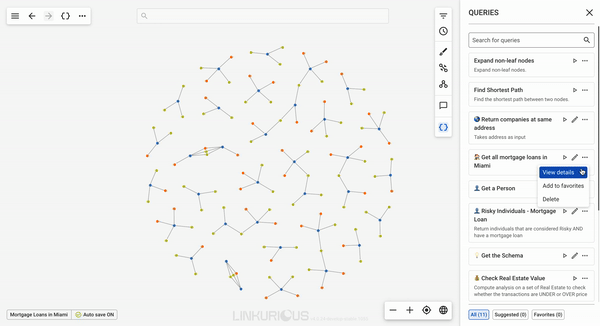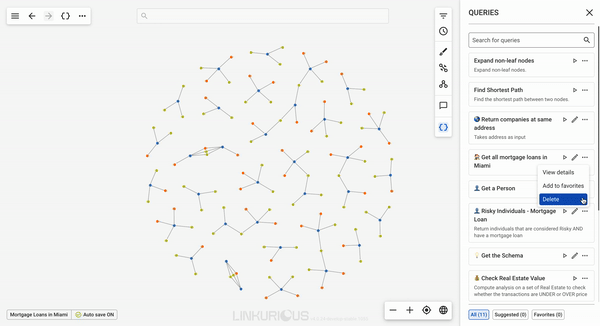
From the query panel, users can do several things with the queries accessible to them. They can run, view details and add their queries to Favorites.
You can also access and run queries directly from the graph visualization.
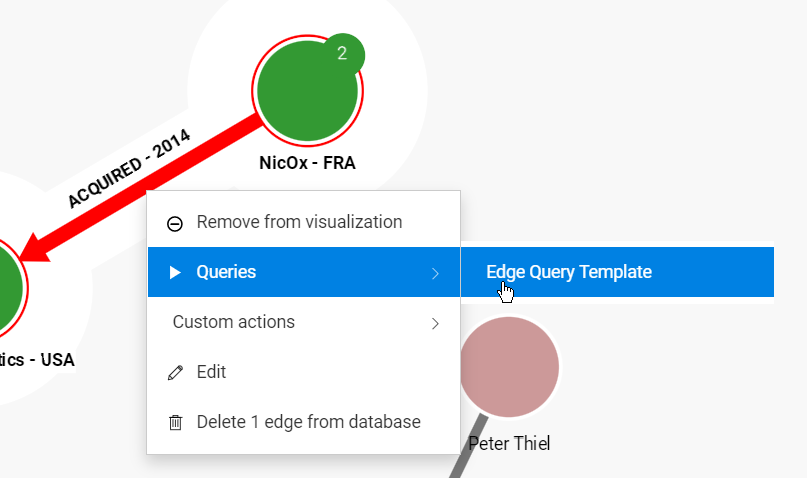
Right-click on a node, select Queries (when available). The context menu displays available queries:
Click a query to open and run it with the selected node as input.
A maximum of 7 queries are displayed. Click Open Query panel to open the Query panel and access the full list of queries.
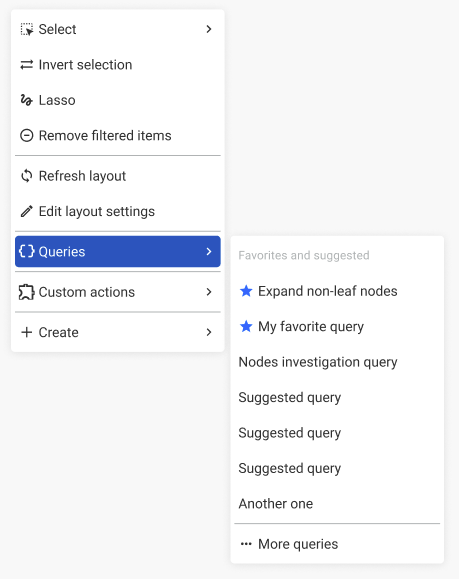
Using the search bar on top of the query panel, the user can search for words in the query's name or description. The query list can also be filtered by using query tags or by selecting favorite or suggested queries.
From the query panel users can edit, delete and view details of queries they created. They can do that by clicking on "More options" (...) on each query.
Only the creator of a query can edit and delete it.
When clicking on edit query, users are redirected to the query editor where they can perform changes to their query.
When deleting a query, the system will ask for a confirmation from the user to delete the query. Deleted queries will no longer be accessible to any of the users who had access to them and the action is irreversible.
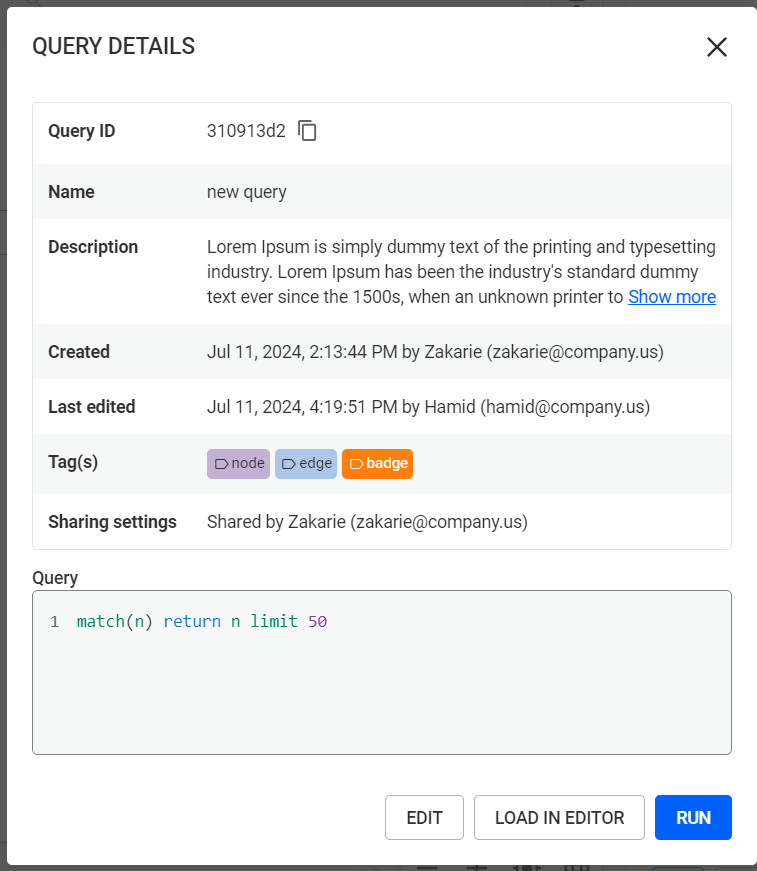
When users view the details of a query, they can view the query's ID, name, description, creation information, edition information, tags, share settings as well as the raw graph query code. Moreover, users can load the query in the editor from the dedicated button which will redirect them to the query editor.
Users can set queries as their favorite. They can do that by clicking on the three dots on a query's card and adding them to favorites. The benefit of having favorite queries is that they can be accessed much quicker.
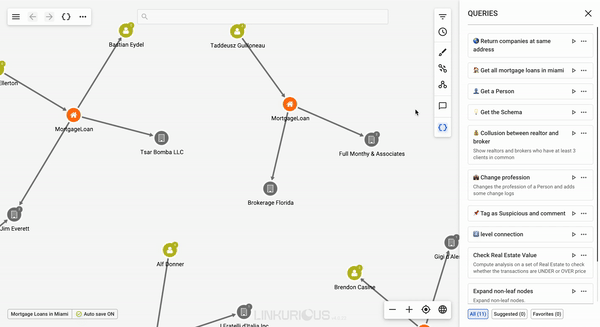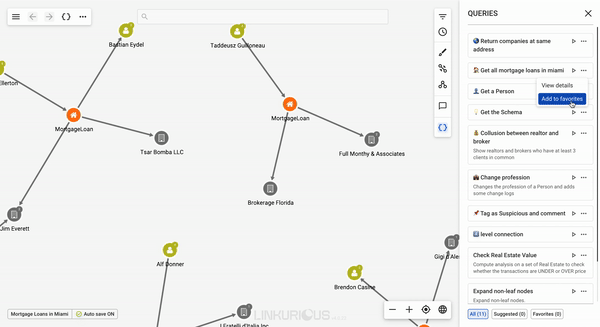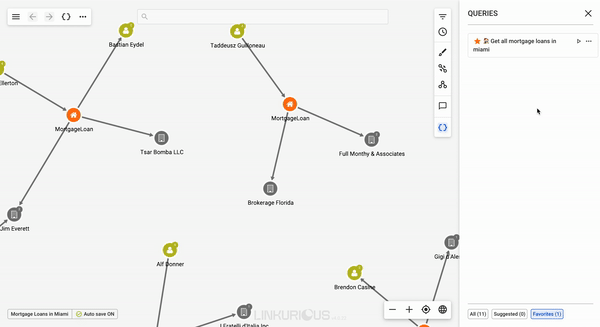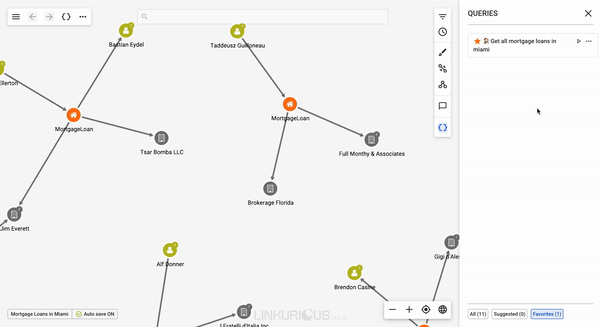
All the user's favorite queries can be accessed at once via clicking on the Favorites tab at the bottom of the query panel.
Favorite queries are individual to each user.
Hidden queries help you declutter the user interface by concealing technical queries that are essential for running custom actions but unnecessary for end-user interaction. Those queries are usually referenced by ID in custom action and plugins, their visibility in the UI can lead to user confusion and unintended misuse.
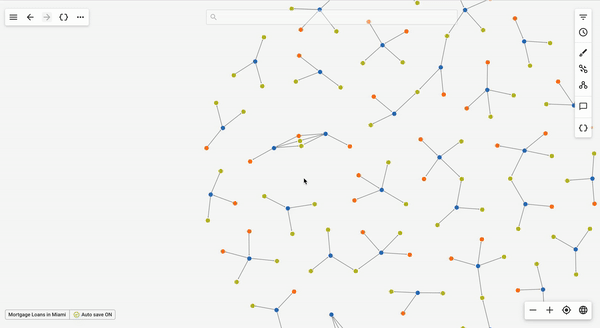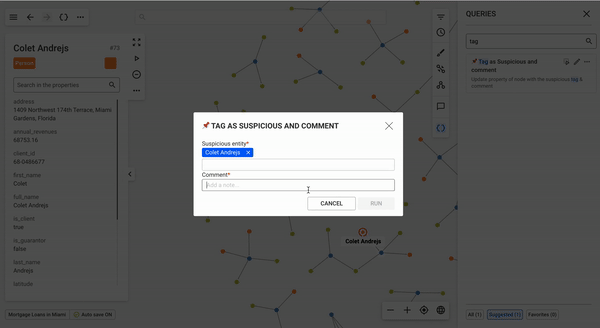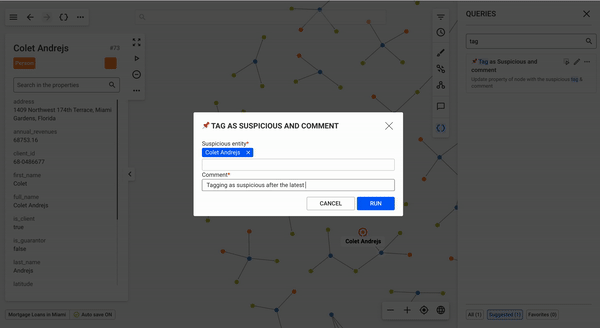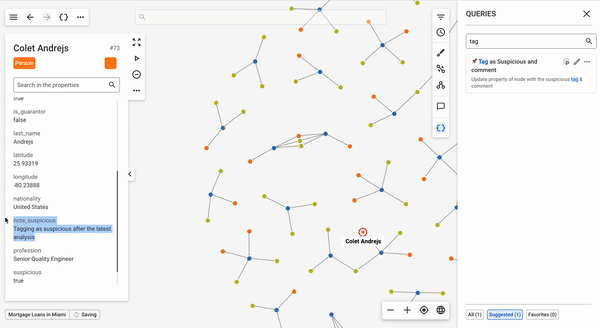
Depending on the nodes or edges that users have selected, the suggested queries tab of the queries panel will show queries that can be run with the current graph selection as input.
A query can return nodes and edges. When running a query, Linkurious Enterprise will have a different behavior depending on whether the query returns some edges or node.
If the query does not return any edges, the system will add all mutual edges between the nodes in the result to the query result. For example, if the query returns nodes A and B but no edges, then running the query will actually return A, B and all edges between A and B.
Example:
MATCH (a:Person)--(b:Person)
WHERE a.name = 'John'
RETURN a, b
The system will add all edges between
aandbto the result automatically.
If a query does return some edges, the system will not try to add any edges to the result automatically.
Example:
MATCH (a:Person)-[edge]-(b:Person)
WHERE a.name = 'John'
RETURN a, edge, b
The system will only return the edges explicitly returned by the query.
In addition to the automatically added edges, when adding the results of a query to a visualization, the system will always also add to the visualization the mutual edges between the nodes in the result and the nodes that were already in the visualization.
Example:
In this chapter we cover the following topics:
Custom actions allow to open URLs that can be customized using data from the graph.
Custom actions allows a scenario such as:
Company node, the user right-clicks on a node and navigates to Custom actions in the context menu.Open in Salesforce.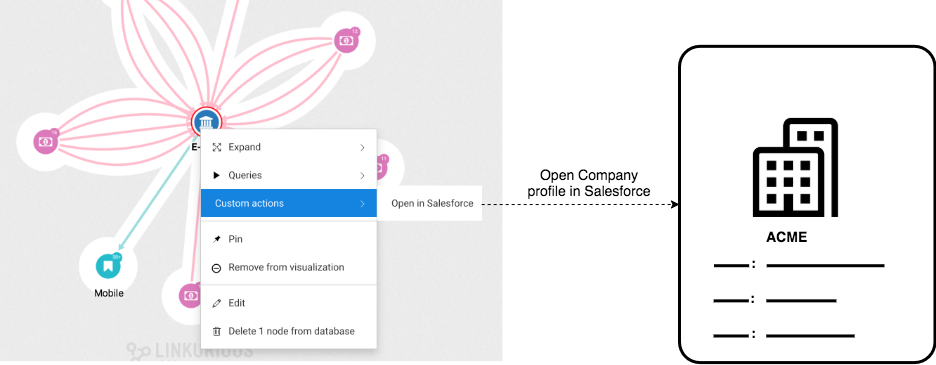
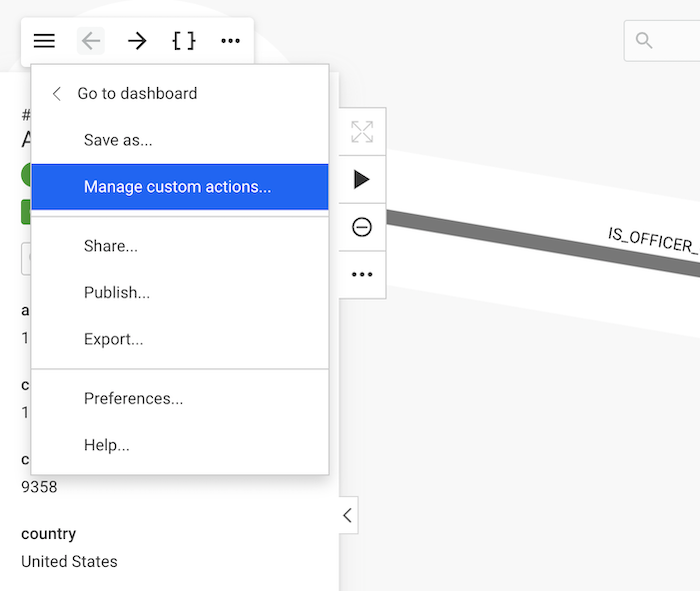
The panel can be accessed through the workspace, by opening the main menu and selecting "Manage custom actions ...".
The panel is available only to users who are authorized to create and manage Custom actions.
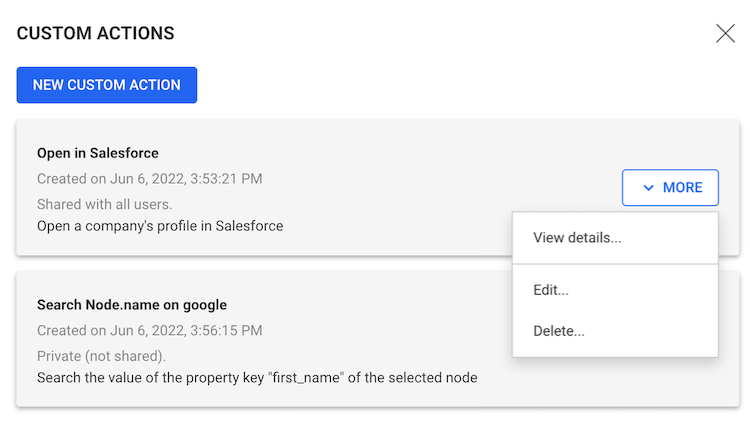
From the Custom actions panel, a user may:
In order to create a custom action a user:
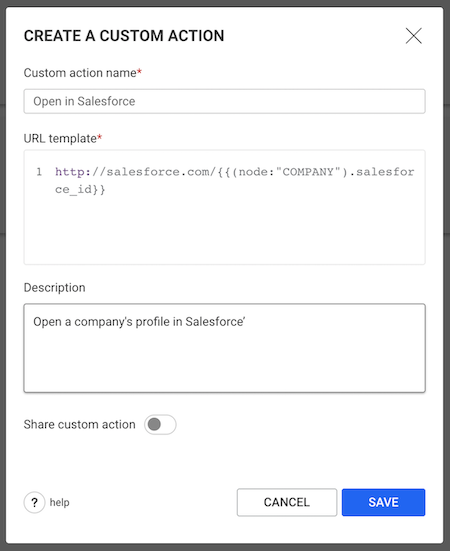
A Custom action contains a URL template with one of more variables that are replaced by actual values provided by the context.
Example:
https://google.com/?q={{node.first_name}}{{node.first_name}} variable will be replaced by the first_name property of the selected node.The following variables can be used in a URL template:
{{node}}){{node.first_name}}){{edge}}){{edge.amount}}){{visualization}}){{alert}}){{case}}){{page}}){{sourceKey}}){{baseURL}}){{nodeset}}){{edgeset}}){{nodeset.country}}){{edgeset.currency}})Several variables can be used in the same template
(e.g. https://google.com/search?q={{node.city}}+{{node.country}}),
with the constraint that "node" and "edge" variables cannot be mixed.
{{node}}By default, a custom action with a {{node}} variable will be
available on all nodes. To make this custom action available only
for Company nodes, use the following syntax: {{node:"Company"}}.
If multiple "Node ID" variables (or "Node property" variables) are used in a single custom action, they need to all have the same node-category constraint (see example 3).
Examples:
https://example.com/details?node={{node}}https://example.com/details?node={{node:"Person"}}https://example.com/node?id={{node:"Person"}}&name={{(node:"Person").name}}{{node.property_name}} or {{node."property name"}} (if the property name contains spaces of special characters).By default, a custom action with a {{node.property_name}} variable
will be available on all nodes. To make this custom action available
only for Account nodes, use the following syntax:
{{(node:"Account").property_name}}.
If multiple "Node property" variables (or "Node ID" variables) are used in a single custom action, they need to all have the same node-category constraint (see example 4).
Examples:
https://google.com/search?q={{node.firstName}}https://google.com/search?q={{node.firstName}}+{{node.lastName}}https://google.com/search?q={{(node:"Person")."First name"}}https://google.com/search?q={{(node:"Company").name}}+{{(node:"Company").city}}{{edge}}By default, a custom action with a {{edge}} variable will be
available on all edge. To make this custom action available only for
Transaction edge, use the following syntax: {{edge:"Transaction"}}.
If multiple "Edge ID" variables (or "Edge property" variables) are used in a single custom action, they need to all have the same edge-type constraint (see example 3).
Examples:
https://example.com/edge_details?id={{edge}}https://example.com/edge_details?id={{edge:"Transaction"}}https://example.com/edge?id={{edge:"Transaction"}}&amount={{(edge:"Transaction").amount}}{{edge.property_name}} or {{edge."property name"}} (if the property name contains spaces of special characters).By default, a custom action with a {{edge.property_name}} variable
will be available on all edge. To make this custom action available only
for Transaction edge, use the following syntax:
{{(edge:"Transaction").property_name}}.
If multiple "Edge property" variables (or "Edge ID" variables) are used in a single custom action, they need to all have the same edge-type constraint (see example 5).
Examples:
https://google.com/search?q={{edge.amount}}https://google.com/search?q={{edge.amount}}+{{edge.date}}https://google.com/search?q={{(edge:"Transaction")."credit card"}}https://google.com/search?q={{(edge:"Transaction").country}}+{{(edge:"Transaction").amount}}{{visualization}}A custom action with a {{visualization}} variable will only be available in regular
visualizations (and not in the visualizations of alert's cases).
Examples:
https://example.com/details?viz={{visualization}}https://example.com/details?viz={{visualization}}&node_id={{node}}{{alert}}A custom action with an {{alert}} variable will only be available in the visualizations of
alert's cases (and not in regular visualizations).
Examples:
https://example.com/details?alert={{alert}}https://example.com/details?alert={{alert}}&node_id={{node}}{{case}}A custom action with a {{case}} variable will only be available in the visualizations of
alert's cases (and not in regular visualizations).
Examples:
https://example.com/details?case={{case}}https://example.com/details?case={{case}}&alert={{alert}}&node_id={{node}}{{page}}When the custom action is executed, this variable is replaced by a URL-encoded JSON object with the following format:
{source:"visualization", visualizationId:739}{source:"alert", alertId:93, caseId:207}Examples:
https://example.com/details?page={{page}}https://example.com/details?page={{page}}&source={{sourceKey}}{{sourceKey}}Examples:
https://example.com/details?source={{sourceKey}}https://example.com/{{sourceKey}}/{{node:"Company"}}{{baseURL}}/.Examples:
{{baseURL}}workspace/new?key={{sourceKey}}&populate=edgeId&item_id={{edge}}{{baseURL}}workspace/new?key={{sourceKey}}&populate=nodeId&item_id={{node}}{{baseURL}}plugins/my-plugin/show?key={{sourceKey}}&node={{node}}{{nodeset}}55,4,128,12By default, a custom action with a {{nodeset}} variable will be available on all nodes.
To make this custom action available only for Account nodes, use the following syntax: {{nodeset:"Account"}}.
Example:
http://example.com/nodes?ids={{nodeset}}{{baseURL}}plugins/my-plugin/show?nodes={{nodeset:"Company"}}{{edgeset}}55,4,128,12By default, a custom action with a {{edgeset}} variable will be available on all edges.
To make this custom action available only for HAS_ACCOUNT edge, use the following syntax: {{edgeset:"HAS_ACCOUNT"}}.
Example:
http://example.com/edges?ids={{edgeset}}{{baseURL}}plugins/my-plugin/show?edges={{edgeset:"HAS_ACCOUNT"}}{{nodeset.property_name}}france,germany,uk{{nodeset}} variables can be used in a template with different property and category constraintsBy default, a custom action with a {{nodeset.property_name}} variable will be available on all nodes.
To make this custom action available only for Account nodes, use the following syntax: {{(nodeset:Account).property_name}}.
Example:
http://example.com/nodes?countries={{nodeset.country}}{{baseURL}}plugins/my-plugin/show?ssn_list={{(nodeset:"PERSON").ssn}}http://google.com/search?q={{(nodeset:PERSON).name}}+{{(nodeset:PHONE).number}}{{edgeset.property_name}}55,4,128,12{{edgeset}} variables can be used in a template with different property and type constraintsBy default, a custom action with an {{edgeset.property_name}} variable will be available on all edges.
To make this custom action available only for TRANSACTION edges, use the following syntax: {{(edgeset:TRANSACTION).property_name}}.
Example:
http://example.com/edges?amounts={{edgeset.amount}}{{baseURL}}plugins/my-plugin/show_transactions?numbers={{(edgeset:"TRANSACTION").number}}http://google.com/search?q={{(edgeset:HAS_ACCOUNT).reference}}+{{(edgeset:TRANSACTION).device}}In this chapter, we will learn how to search nodes and edges with Linkurious Enterprise.
We will first look at how to search nodes and edges then we will be looking at different advanced search options Linkurious Enterprise provides.
We may have millions of nodes in our graph. What if we want to look at a specific node?
We can use the search bar in the Workspace once we have created a new visualization.

We can look for a node by typing the name of any of its properties.
Here, for example, we look for the property Instagram.
We see the list of suggestions that match our search.

The search can be applied to all the nodes in the database or to all
the nodes in the visualization simply by switching from ALL to LOCAL
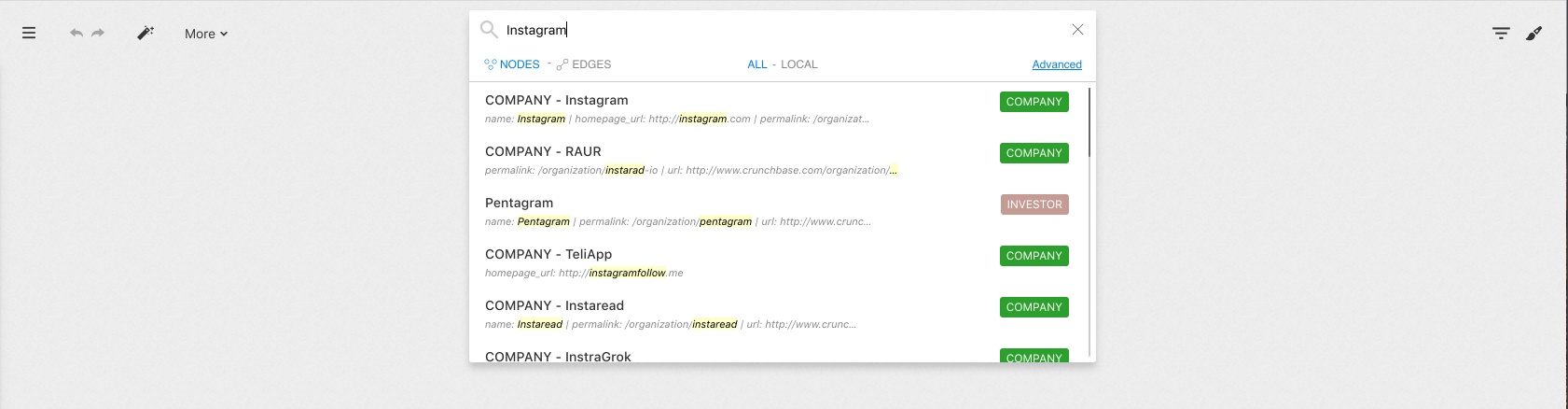
All the entries in the database containing the word Instagram will
appear. These results are sorted by relevance.
For each result we can see:
Instagram)Instagram contains the text Instagram
that matched our search)When we click on the result of our choice, it will be added to the workspace. Now we can visualize it.
How it works : by default, Linkurious Enterprise indexes all the properties of your graph. If any property of a node matches your search, it will be returned.
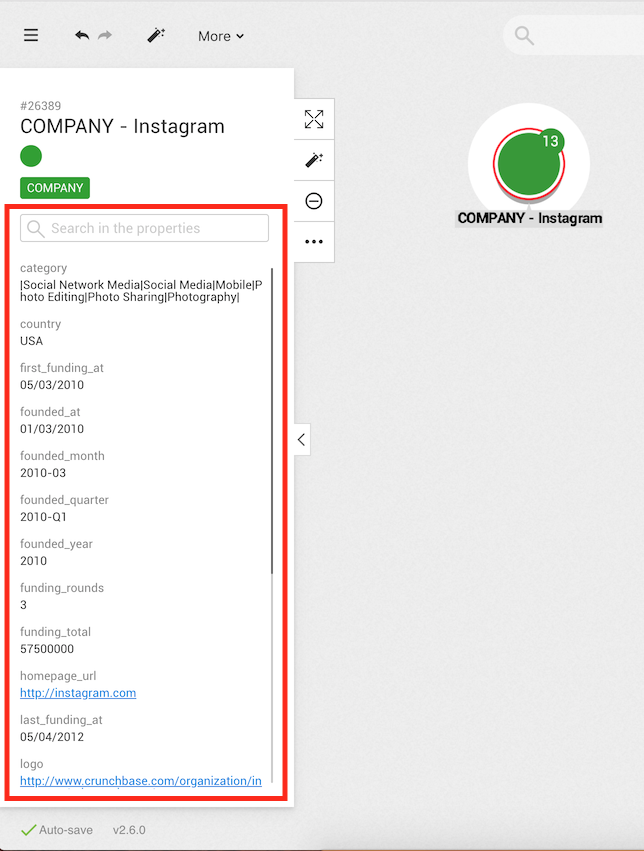
For example, you could find the
USAor2010-03.
The search bar in the Workspace provides an Advanced Search option not available through the Quick Search Bar of the Visualizations Dashboard. We can thus reduce the results to the category we are interested in. Those options are described in the Advanced search section.
We may have millions of edges in our graph. What if we want to look at a specific edge?
The fastest way is to use the search bar in the Linkurious Enterprise interface after we have have created a new visualization.
By default the finder will be set to find all nodes in the database.
To search an edge, we click on the Edges button after typing the search value.
To search only the edges present in the visualization, we click on the LOCAL button.

The search for edges works exactly like the search for nodes.
We simply type what we are looking for. We see the list of suggestions that match our search.
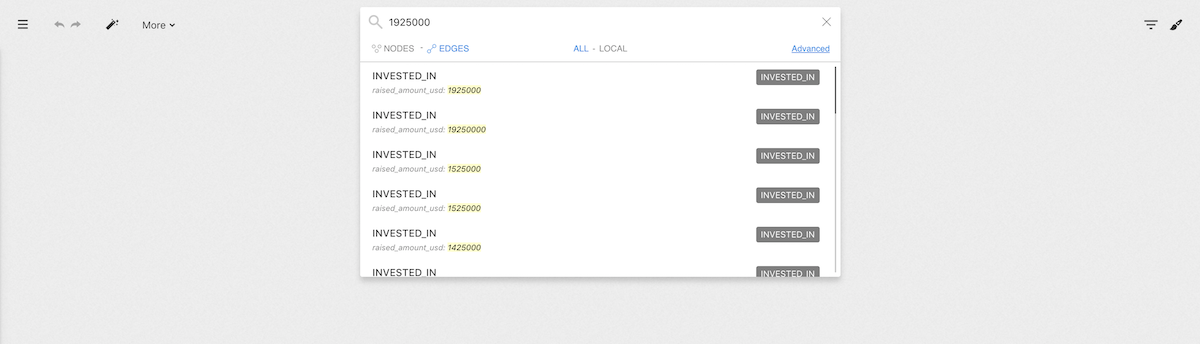
In the search result, we can see that there is an edge that has the value
1925000 for the property raised_amount_usd.
We choose the result we are interested in by clicking on it. It is immediately added to the workspace where we can visualize it.

You're looking for a specific node or edge, and the search bar has returned too many results?
This usually means that your search query is not specific enough. You may want to narrow down your search by specifying a particular node-category or edge-type to search on, and by adding conditions on specific properties.
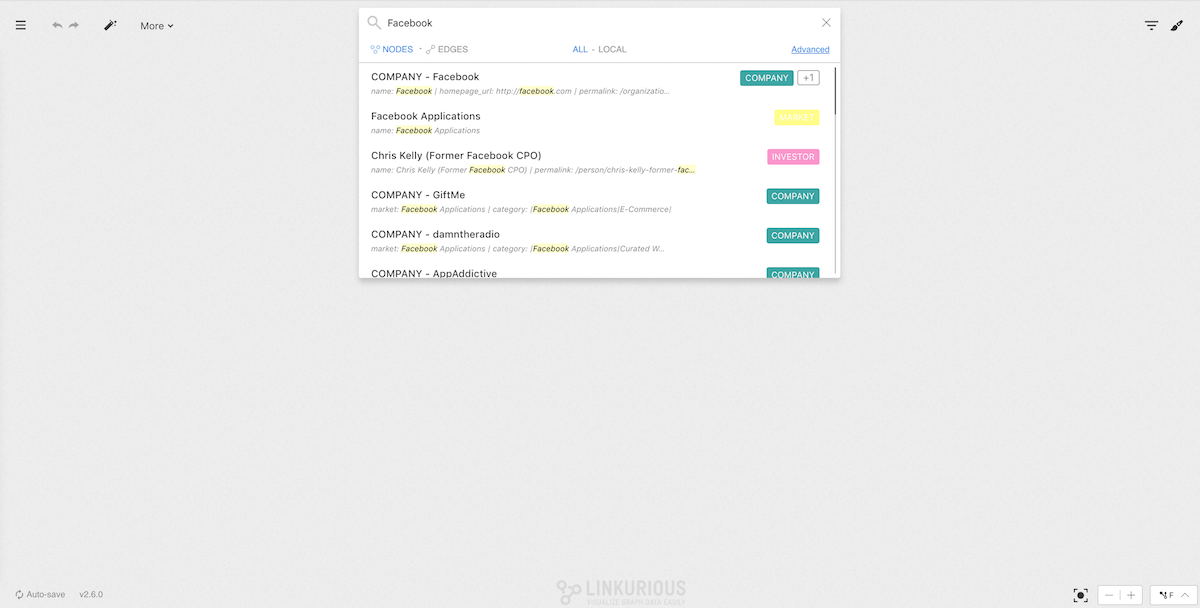
Searching for a company that contains the string facebook in any of
its properties returns a large number of results.
Let's try to narrow it down.
When we click on the Advanced link, a new menu appears:

In the footer of the advanced search screen, we see the number of nodes
whose properties contain facebook (353), and we're able to review them
by clicking through the result pages.
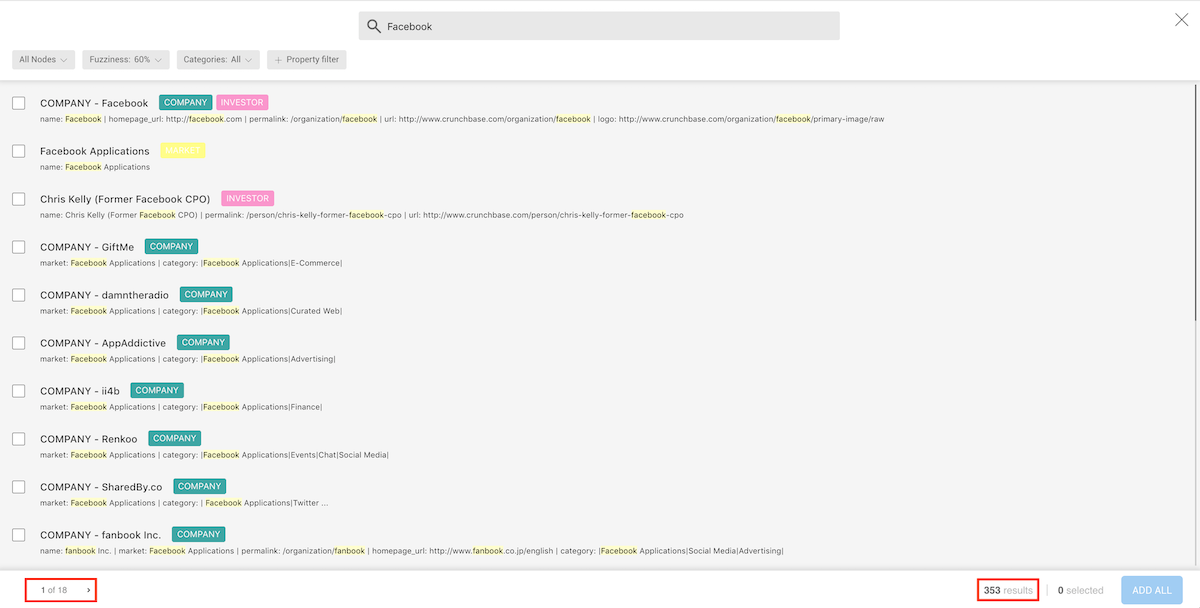
In the header, in addition to having the search text, we have the followings options:


In our graph, facebook is categorized as a Company.
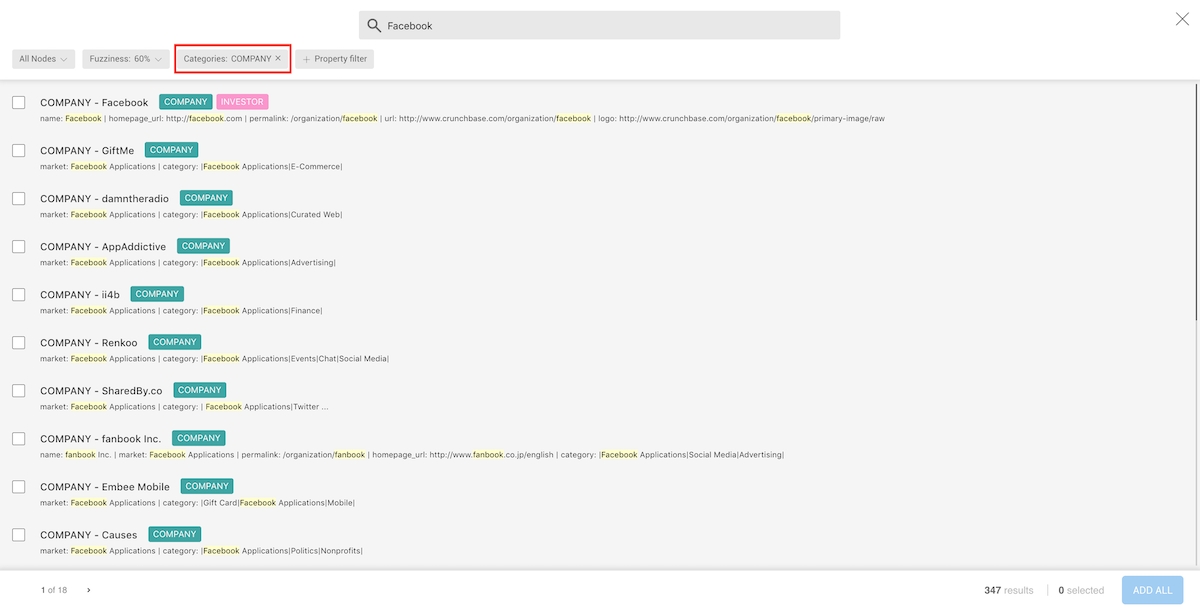
We are going to click and type Company on the category filter button
to restrict our search to the nodes that have the category Company.
We can now see the different results.
In our graph, a Company can have properties like category,
country, first_funding_at or founded_at and more.
Not all the nodes categorised as a Company will have all the
properties, though.
In order to narrow down our results, we are going to search multiple
properties at once.
To find Facebook, we are going to look for a company that uses
"facebook.com" as its homepage url.
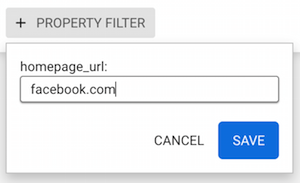
Now when we type facebook, the results are filtered to show only the
nodes that have the category Company and the value facebook.com for
the property homepage_url.
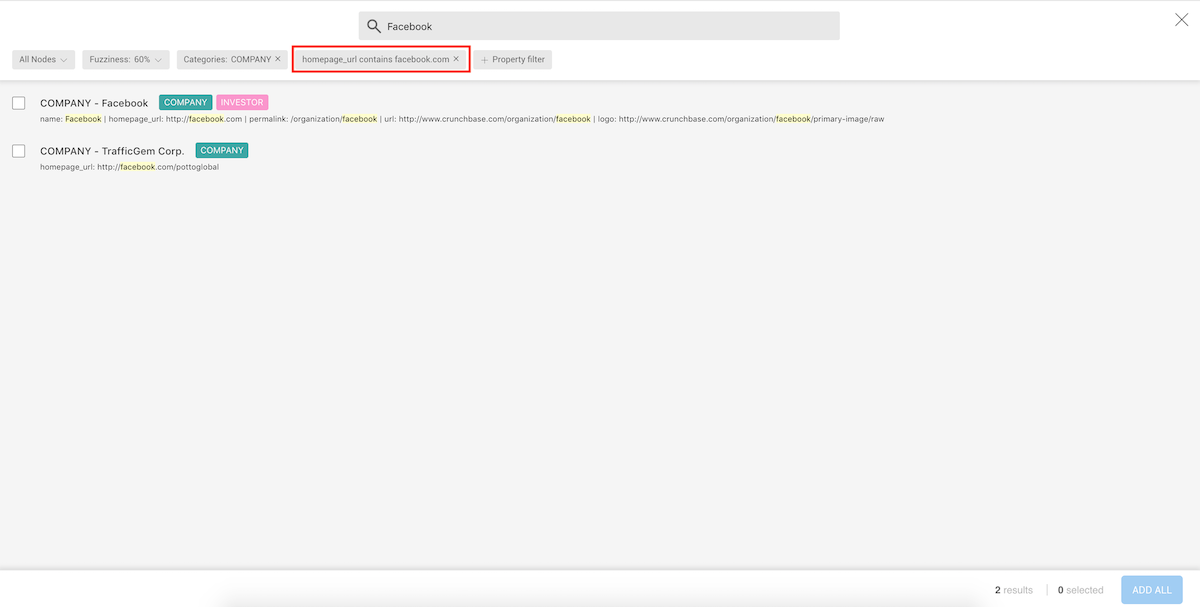
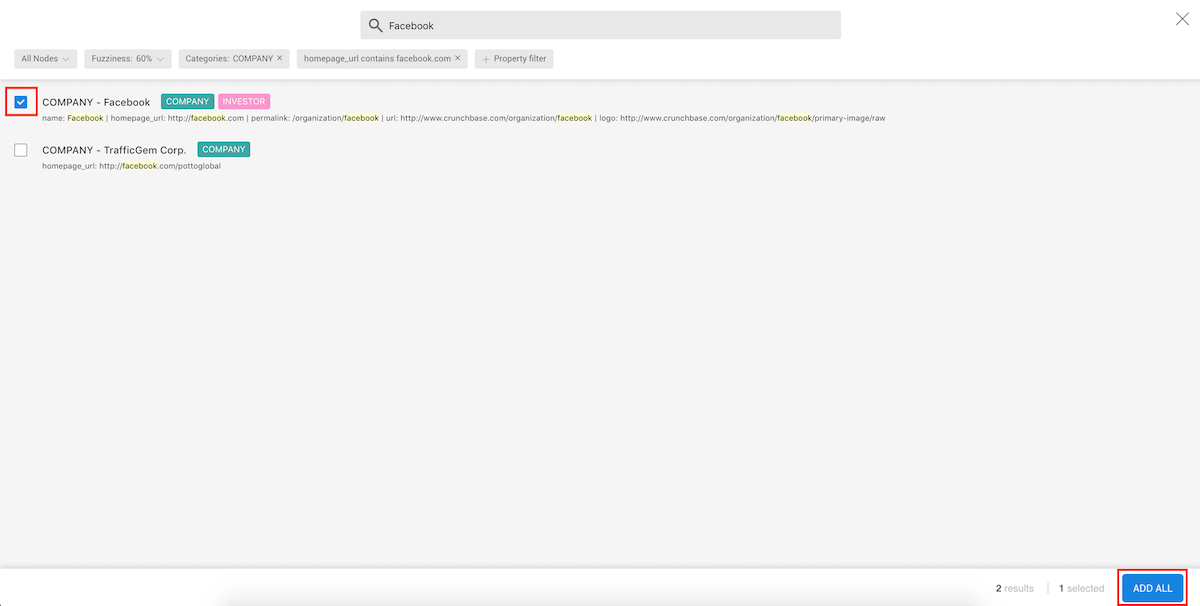
We can see that the results are now filtered.
We can now select the result we are interested in by clicking on the select box
on the left side of the result, then on the ADD ALL button.
The same approach can be applied to searching for edges.
Linkurious Enterprise will look for exact matches for the values you enter in the search options menu.
Linkurious Enterprise offers a native user interface to do advanced search in the graph.
For advanced users, it is possible to directly use the search syntax in the search bar:
The search syntax accepts 3 expression types:
john"john" is searched against all indexed properties."john".john doe"john" and "doe" are searched against all indexed
properties, without consideration for order or distance between
the terms."john" and "doe"."john doe""john doe" is searched against all indexed
properties.type:type:Person: search on nodes of category "Person"type:"Big Customer": double-quotes are mandatory for a
category/type containing special characters, such as a space.$property-key: where $property-key is the name of the property.name:john"john" is searched against property name."john".name:(john doe)"john" and "doe" are searched against property
name, without consideration for order or distance between the
terms."john" and "doe".name:"john doe"name.paris type:City search for "City" nodes with any property containing
the term "paris"name:john doe search for all nodes for which there is:name containing "john"."doe"."serial number":"T3492E" search for all nodes with property
serial number matching exactly "T3492E".Numerical and date search only works with Elasticsearch on properties declared as "Number" or "Date" in the graph schema. To learn more please check how to configure numerical/date search.
Authorized operators:
><[x y]These operators must be followed by a number or an
ISO date string (i.e. yyyy-mm-dd).
Examples:
age:>20age:[10 to 100]age:[1.2 to 5,4]dateOfBirth:[1980-01-01 2000-12-31]In this chapter, we'll learn how to manipulate a graph, and more precisely the different options Linkurious Enterprise provides to explore and work on a visualization.
We will see how to select nodes and edges we are interested in and how to expand. Then we will learn how to hide them, how to apply a layout to the graph, how to pin nodes, how to undo/redo all actions and some useful shortcuts.
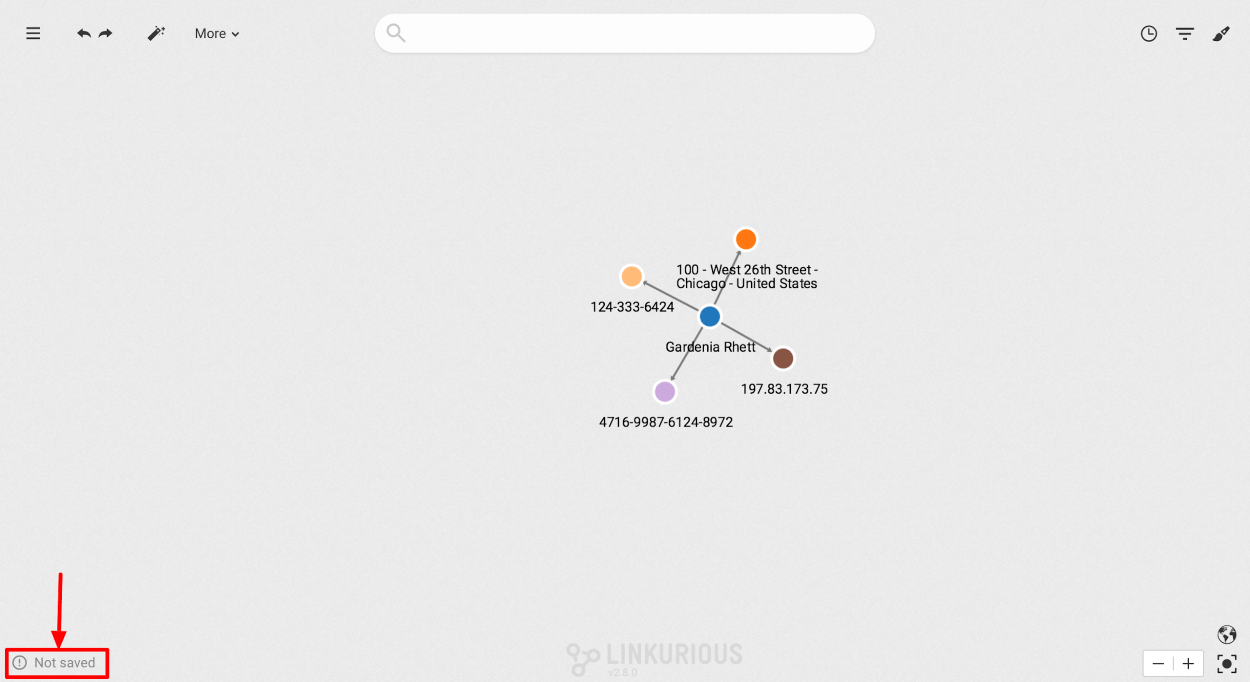
The auto-save status is displayed in the bottom left corner of the workspace. There are 3 possible statuses:



New visualizations are not automatically saved. In order to save a visualization, click on the Menu and then "Save...". Once saved, the Auto-save is switched on.

At the bottom left of the screen click on "Auto-save ON":
Switch auto-save off in the confirmation popup (see below). Auto-save is now switched off: modifications are not saved.
Warning
If you close the visualization and open it again, Auto-save will be ON again.
You can duplicate a visualization by clicking "Save as..." in the main menu. The new visualization is open in the current window, and Auto-save is enabled.
Warning
If Auto-save is OFF in the original visualization, any unsaved changes will be lost
The easiest way to select a node or an edge is to simply left click on it. Each left click on a node is a new selection.
It is also possible to select multiple nodes at once from various ways.
Click on the ... in the top menu, or right-click on the background.
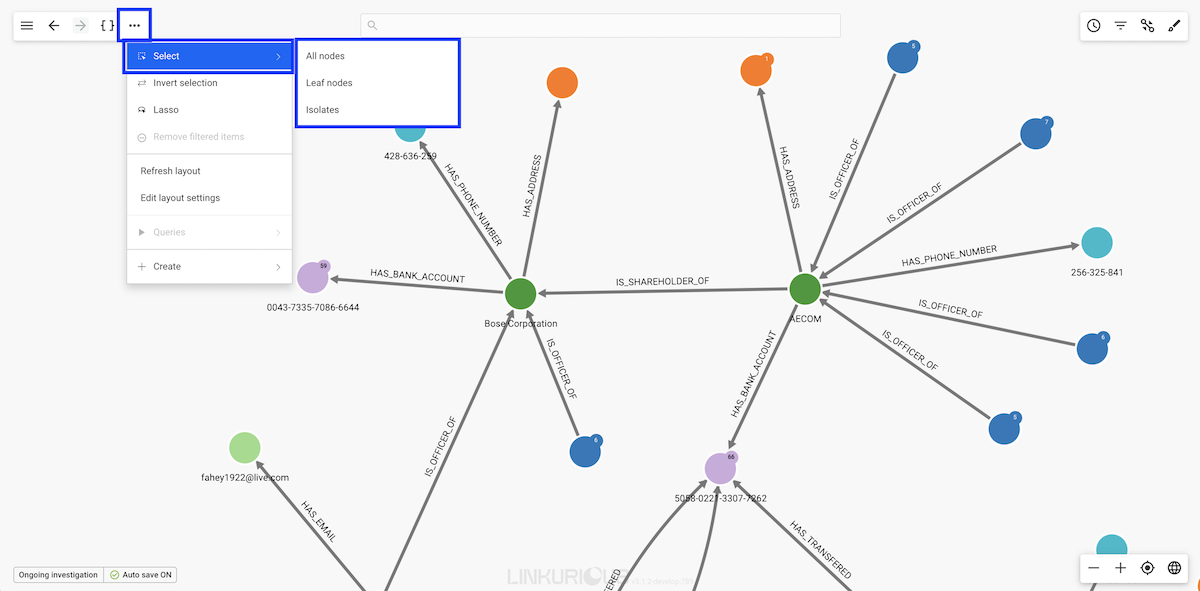
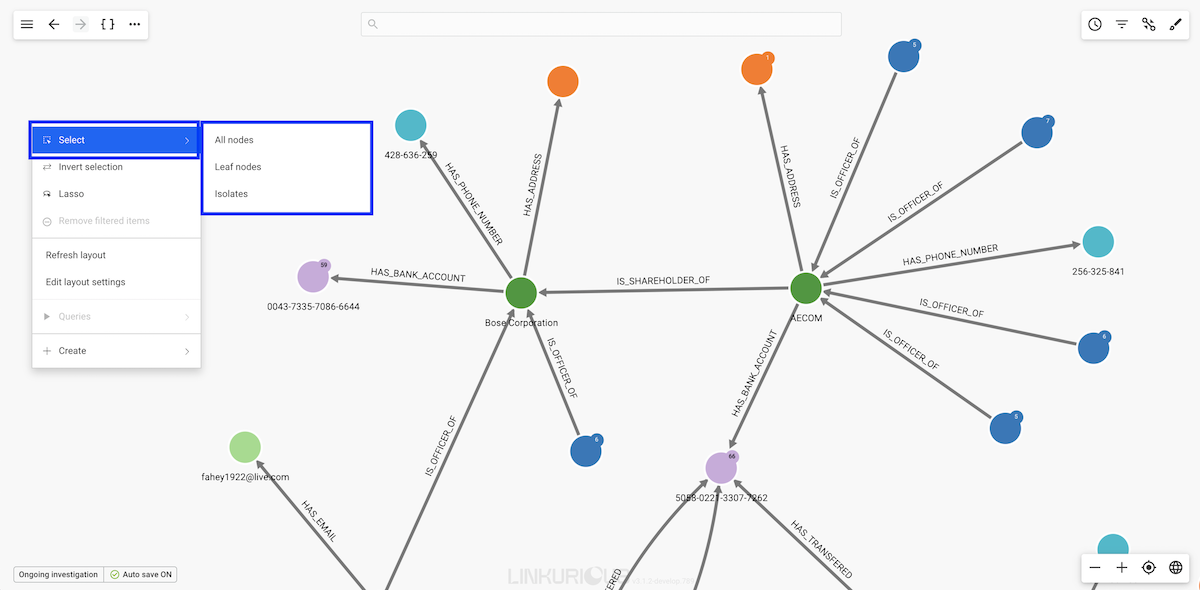
Choose the sub-menu Select to access the following options:
All nodes: select all the nodes in your current
visualization,Leaf nodes: select the nodes in your visualization that have
only one edge,Isolates: select the nodes in your visualization that have no
edges.Node Categories: select the nodes in your visualization by categoriesThe following options are also available in addition to the sub-menu Select:
Inverse selection : invert your current selection,Toggle lasso: manually select the nodes you are interested in by drawing a path around themTips : Use this neighbor selection to quickly extract a cluster from a dense network instead of using the
lasso.
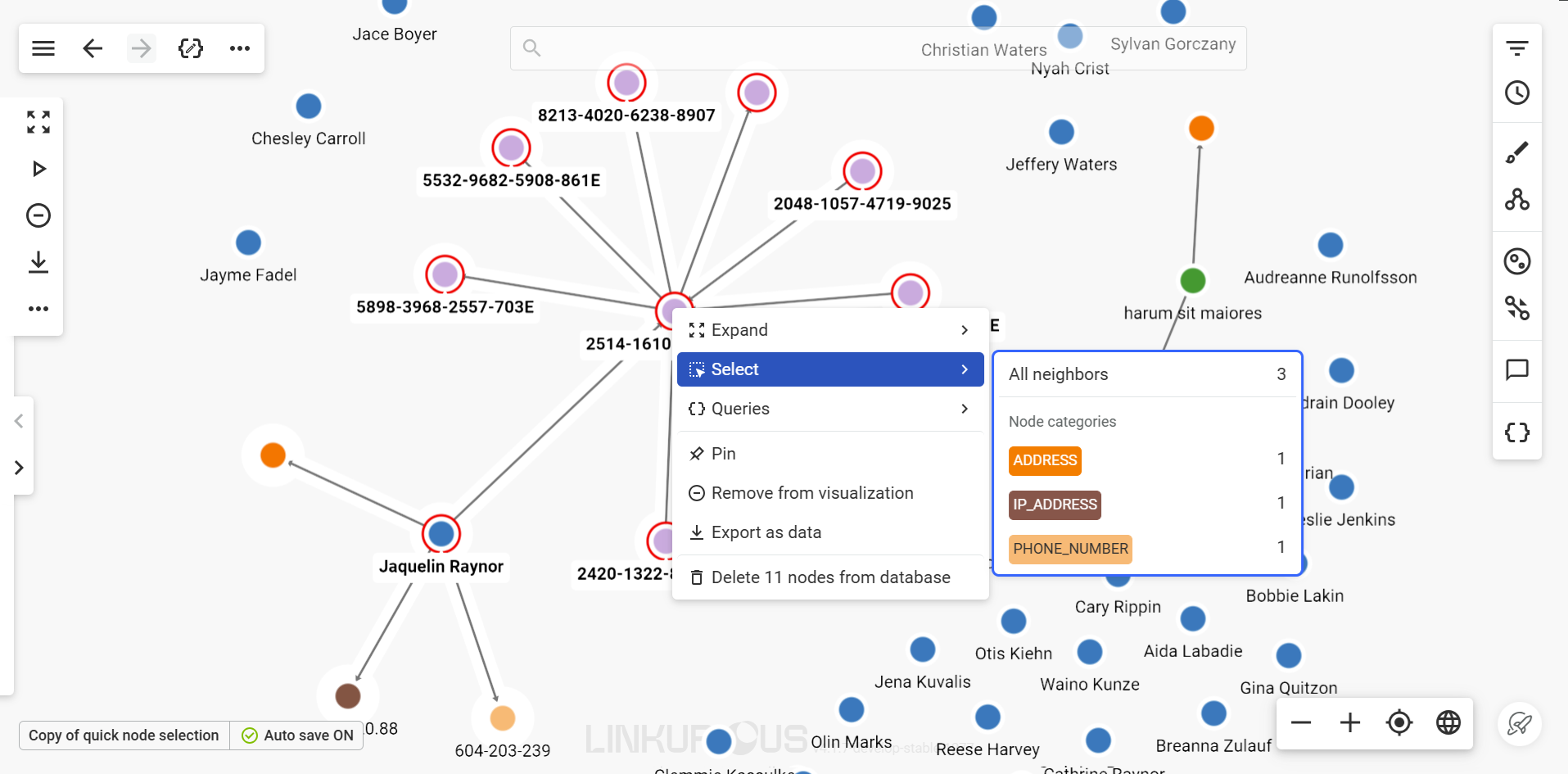
Right click on a node, choose the submenu Select to access the following options:
All neighbors: select all direct neighbors of the node,Node categories: select all direct neighbors of a specific node category.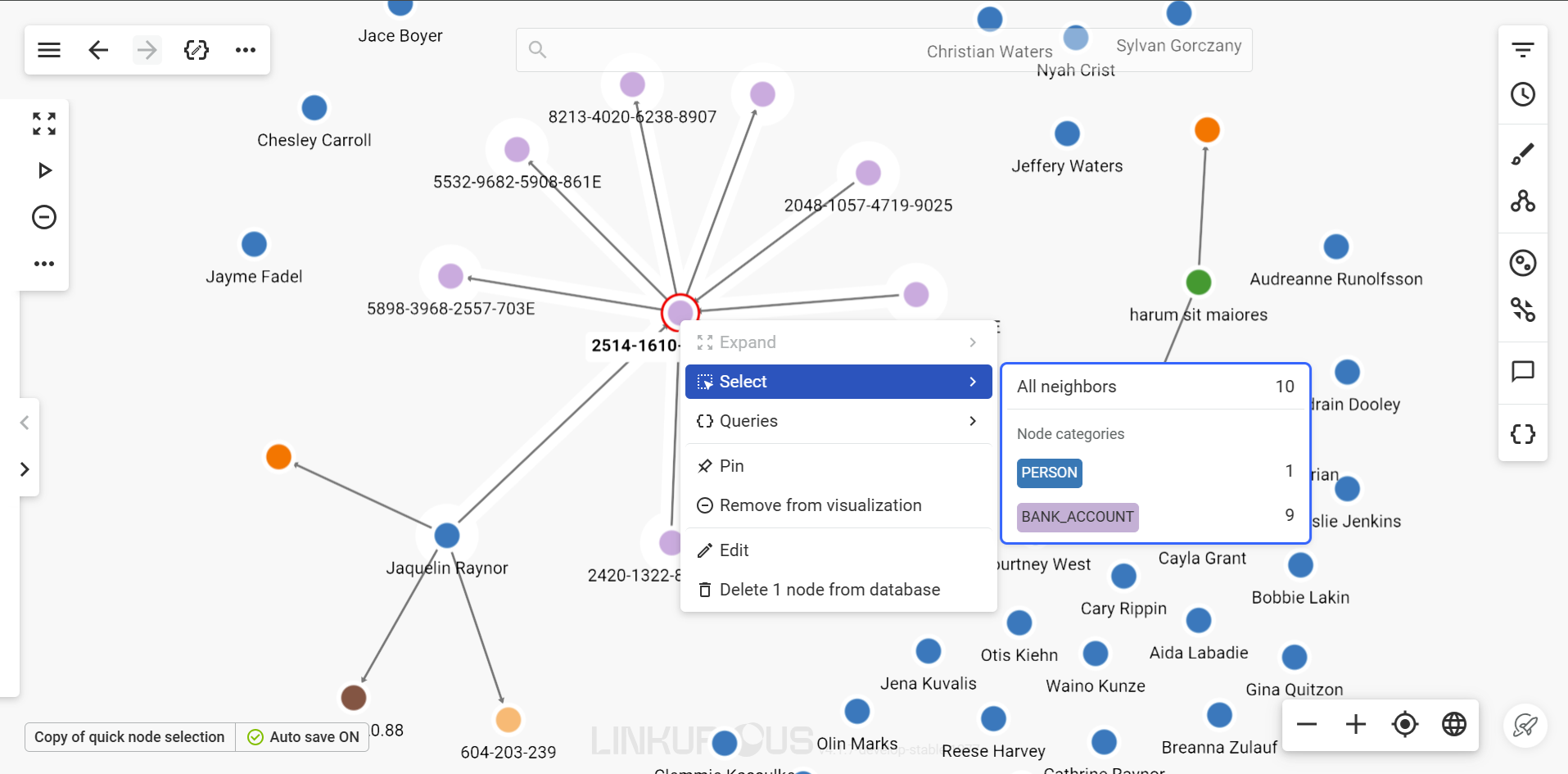
Expand your selection to the next level of relationship by selecting neighbors another time from the previous selection
Shortcuts are also available for this actions. See the list of Workspace shortcuts.
It is possible to move graph elements from a visualization to a new or exisitng visualization.
In order to do so, you can select one or multiple nodes. Once the graph elements have been selected, you can right click on the selected elements. From the menu, select the Open selection in option.
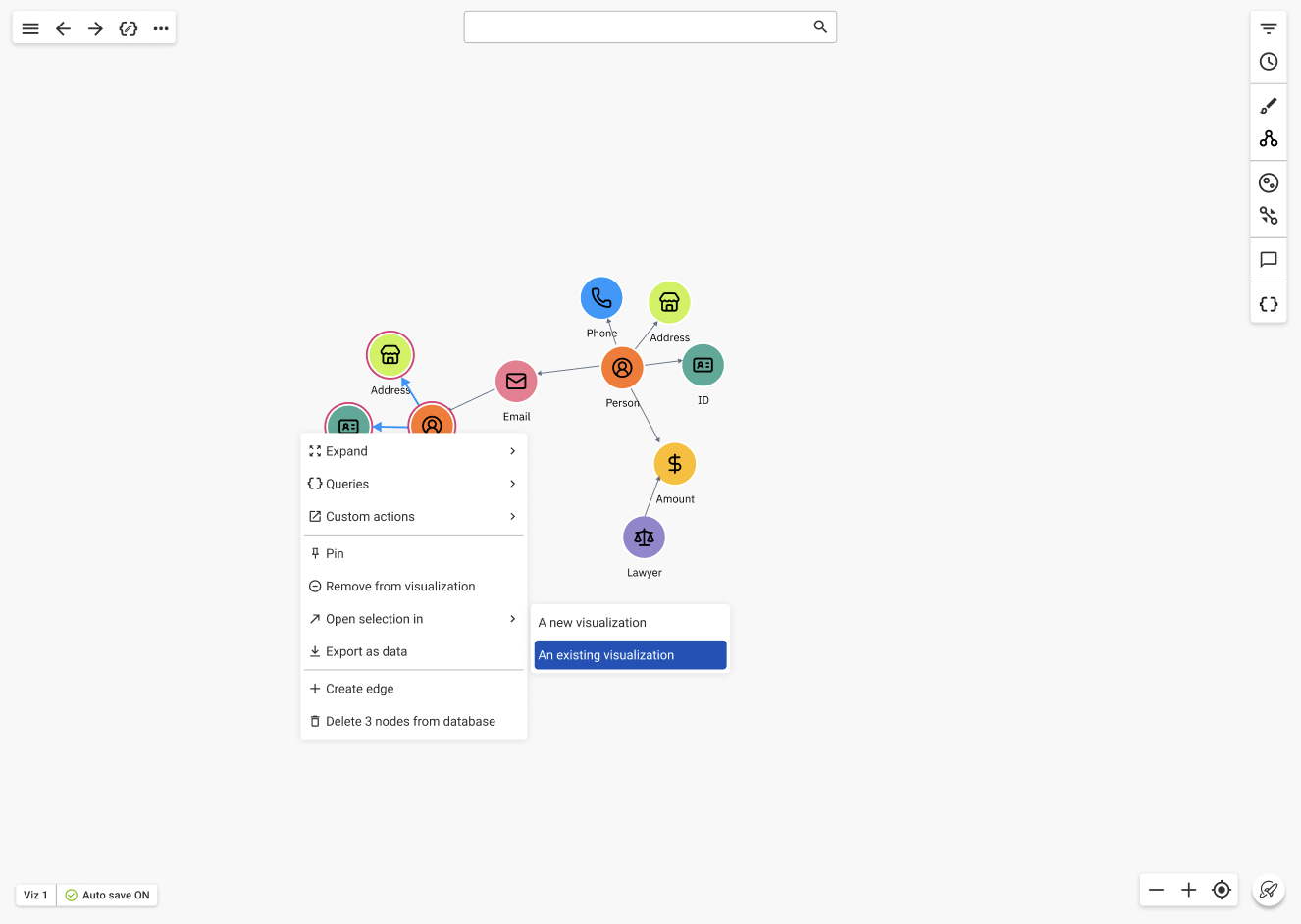
You can copy the selected nodes and/or edges to a new visualization. Moreover, you can open a new visualization including the selection and graph data from an existing visualization.
You can use standard keyboard shortcuts (
ctrl/cmd+c&&ctrl/cmd+v) to copy and paste graph elements between visualizations.
Enabled from Layouts Settings, Node Snapping option helps positioning and evenly spacing nodes when you move them in your visualization.
Expanding a node displays all the nodes connected to it.
Generally, you can do it in three different ways:


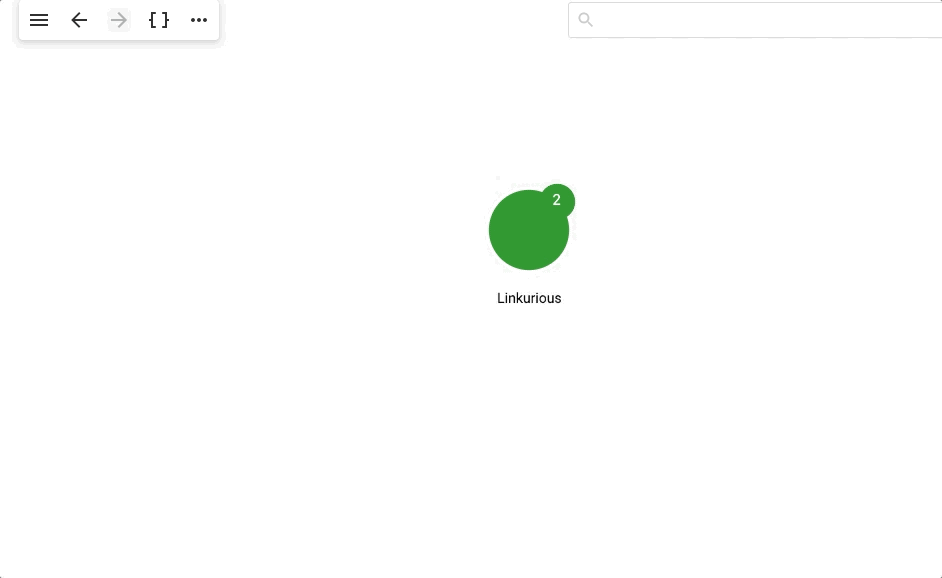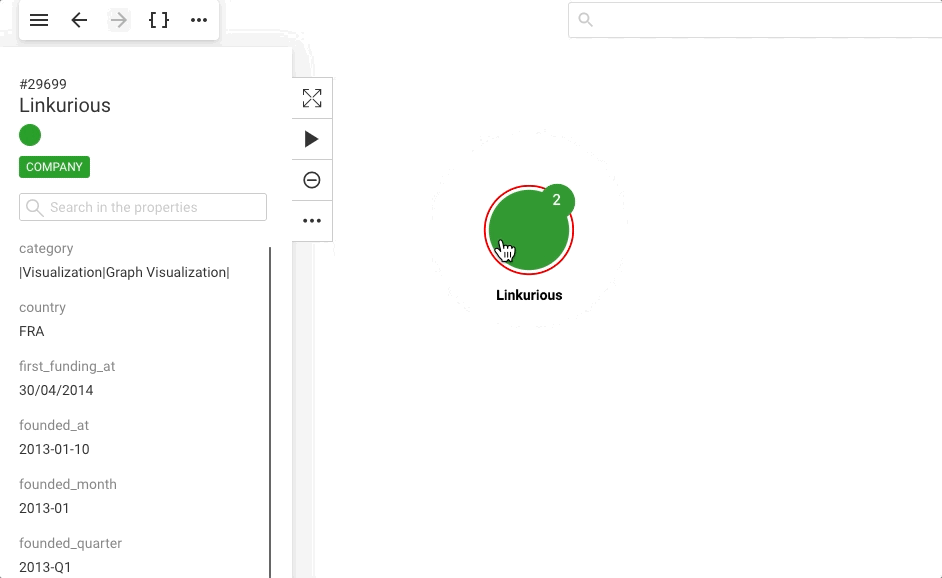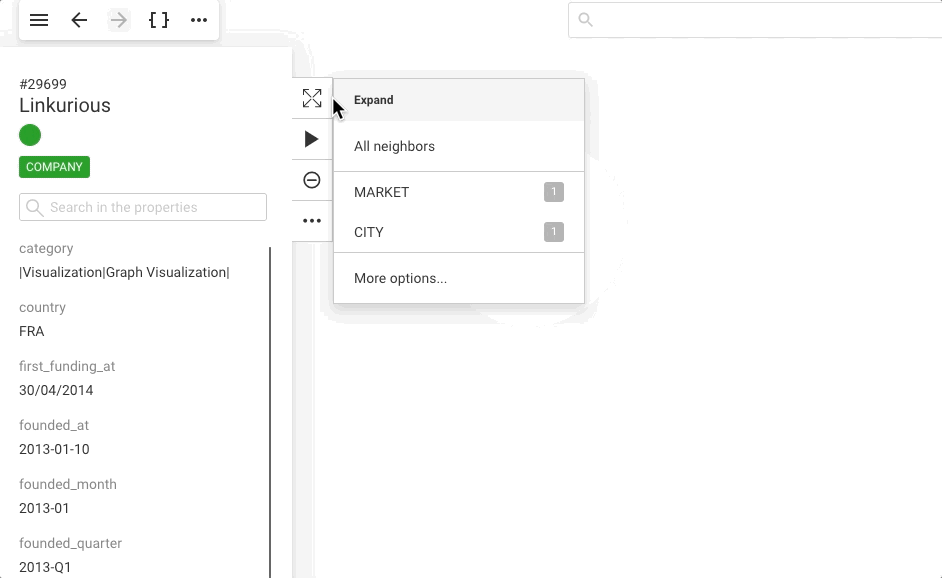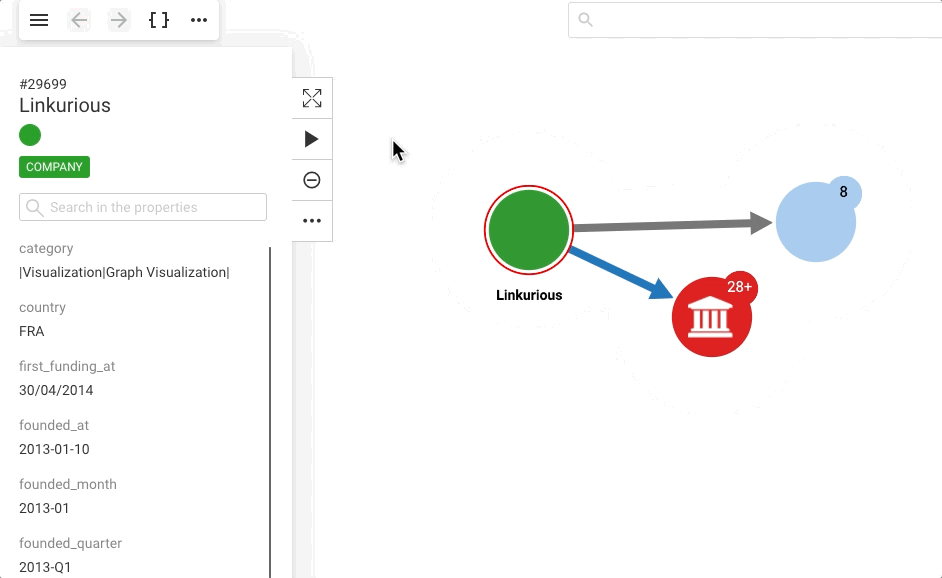
The Expand button in the context menu and property panel shows the following options:
advanced.expandThreshold or advanced.supernodeThreshold, expand all connected nodes of the selected category. If not, the Selective Expand popin is opened.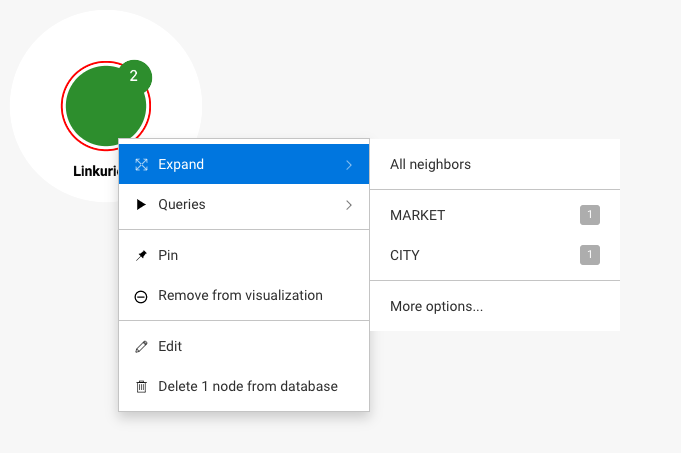
The Selective Expand feature prevents adding too many neighbors at once. The popin provides options to:
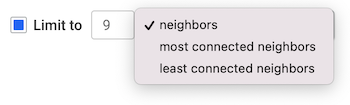
When expanding nodes that have more edges connected to it than advanced.expandThreshold but less than advanced.superNodeThreshold, you see the following Selective Expand popin:
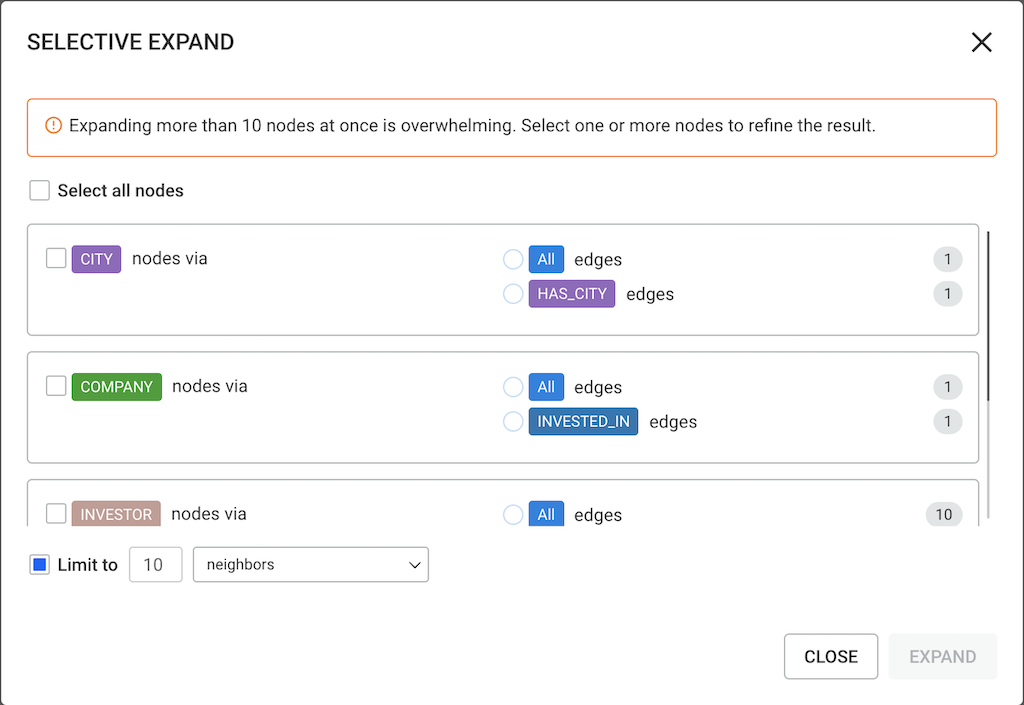
Selecting only one category allows you to expand nodes of that category and select a specific edge type it is connected to. In the example below, we select node CITY and edge type INVESTED_IN:

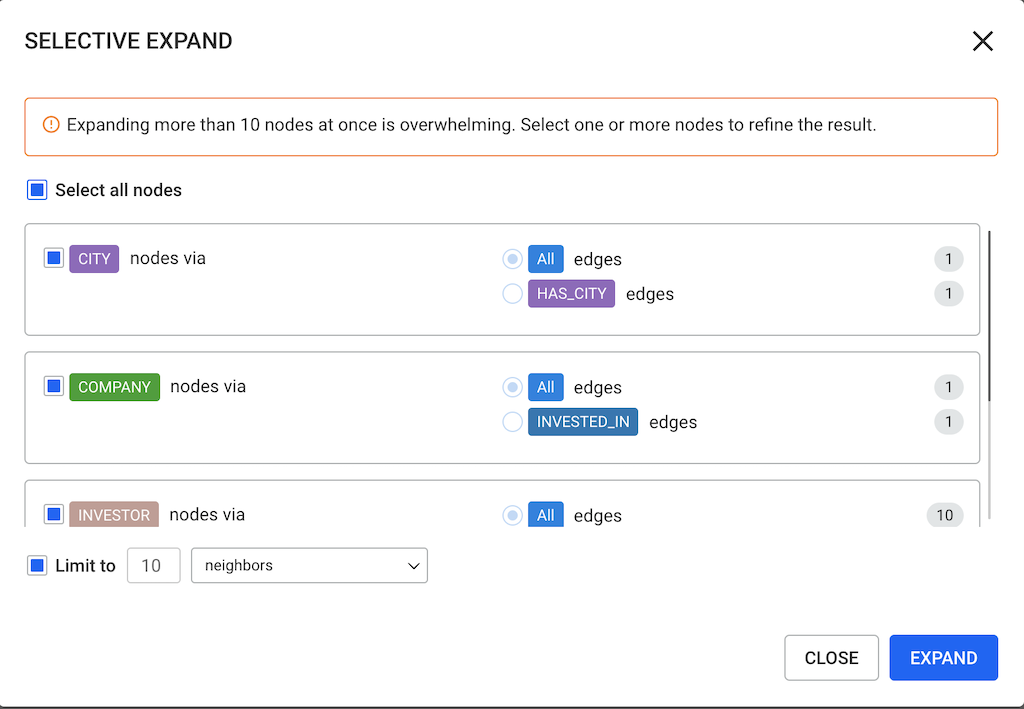
Selecting multiple categories allows you to expand nodes of those categories without the option of selecting the edge types. By default, all edges are selected.
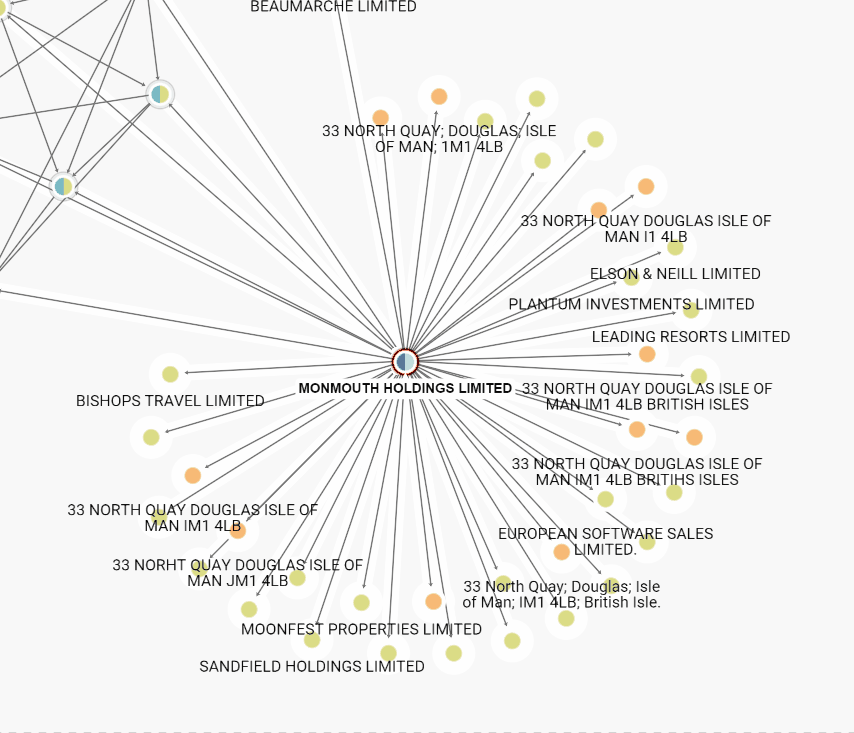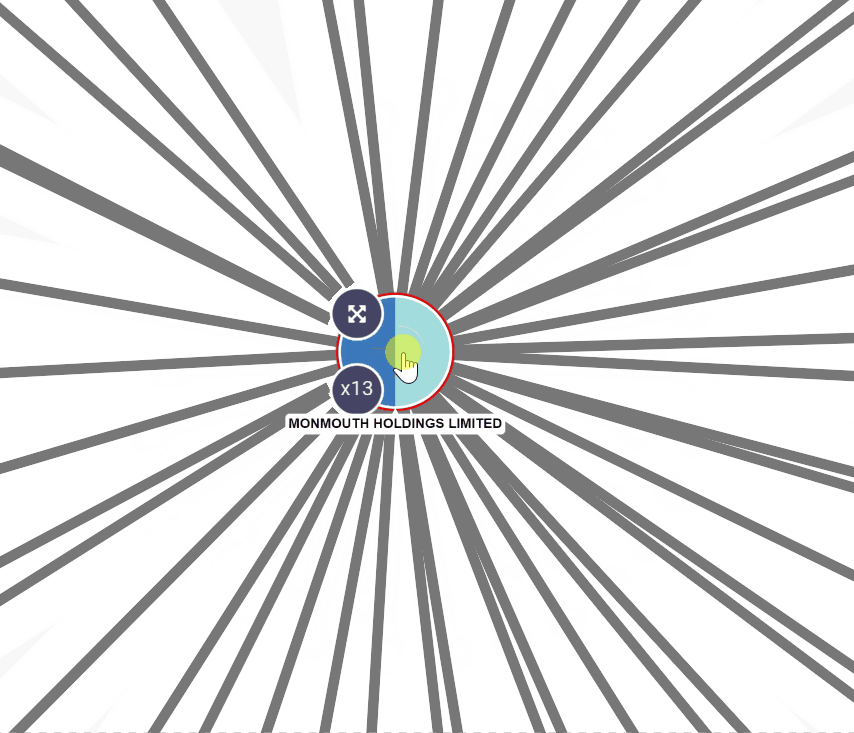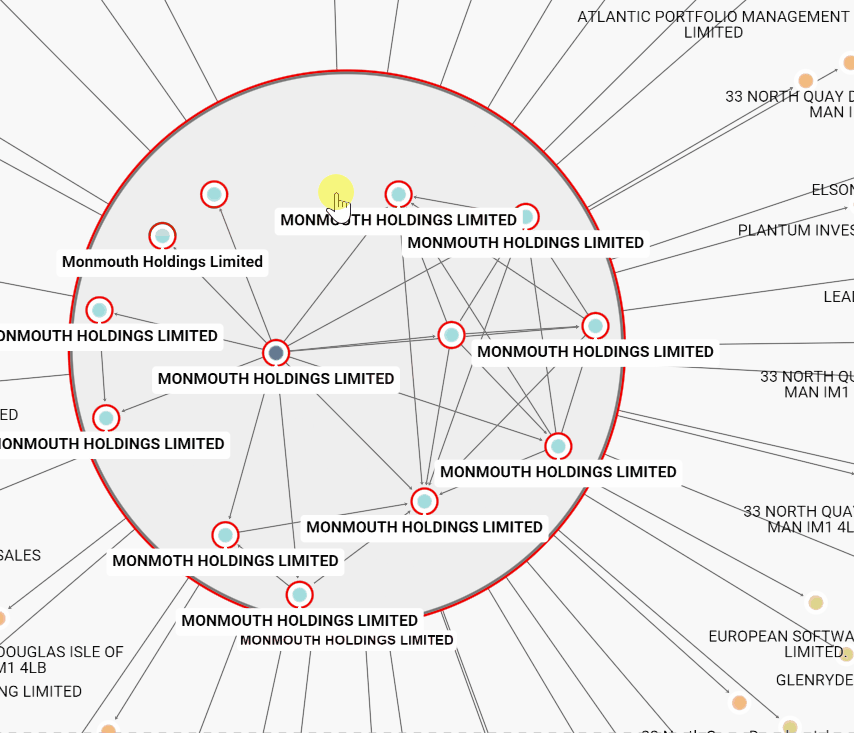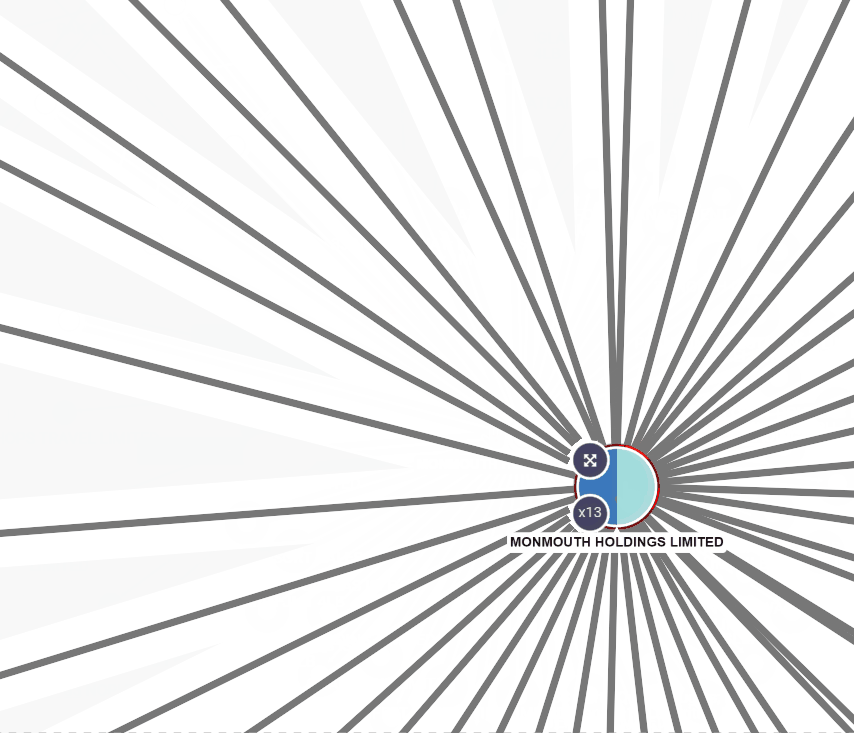
In the visualization, a super node is marked with a plus badge along with the number of connections it has.
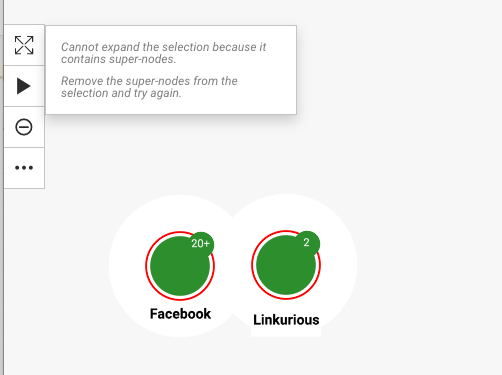
When expanding nodes that have more node neighbors than advanced.superNodeThreshold, you see the following Selective Expand popin. Here the popin has the full list of relationships and categories to expand:

Note however that it is not possible to expand multiple nodes at the same time when at least one of the selected nodes is a super node.
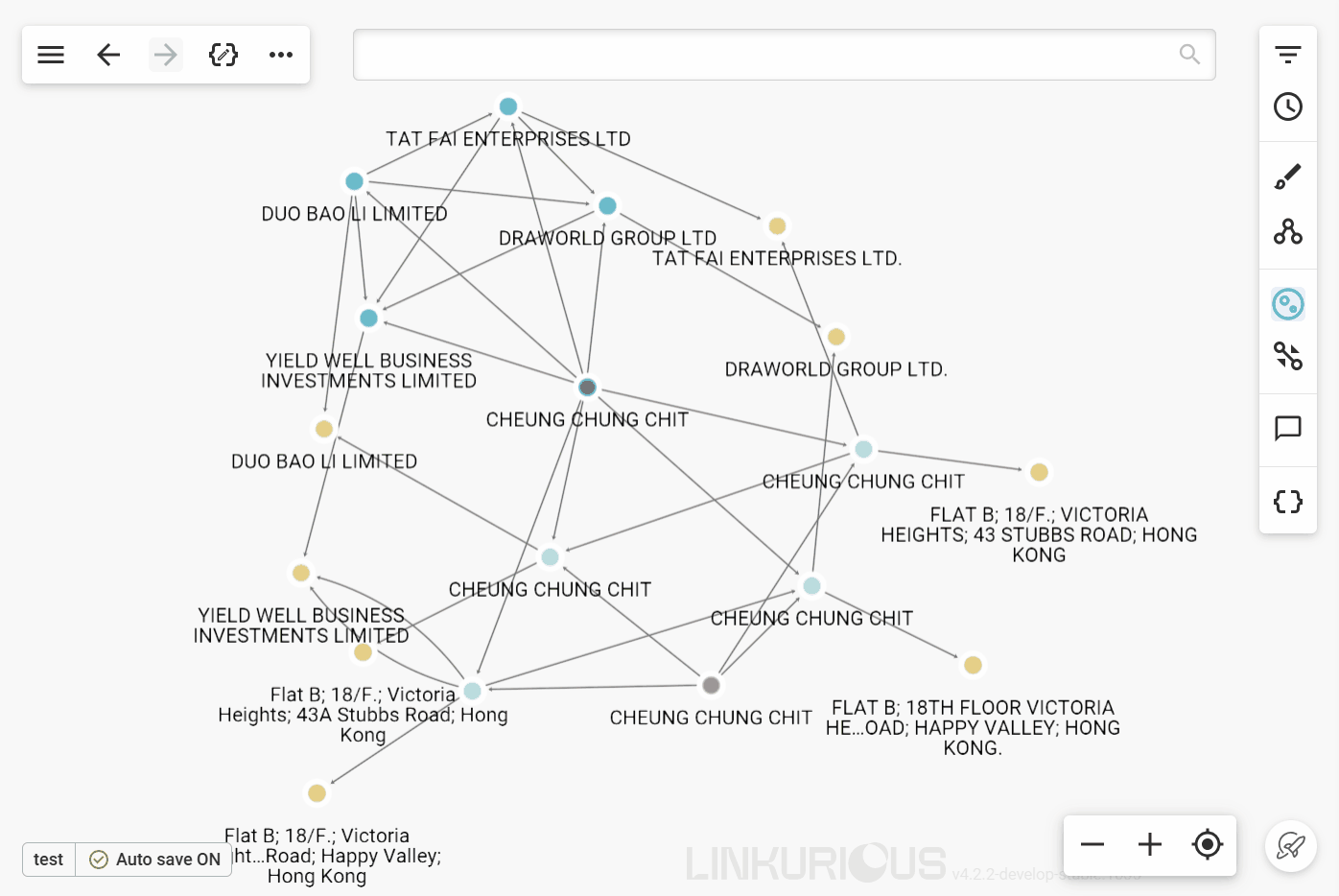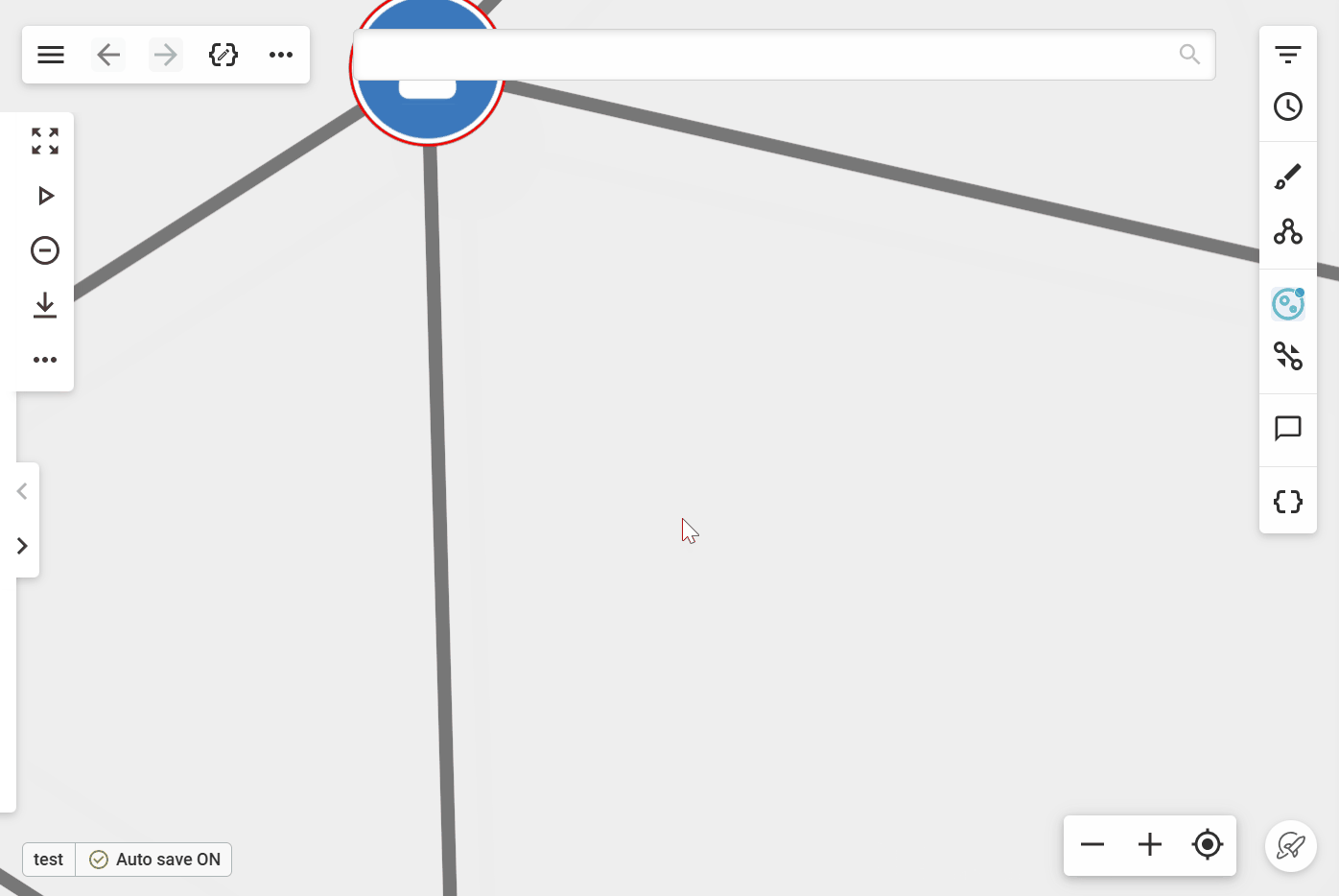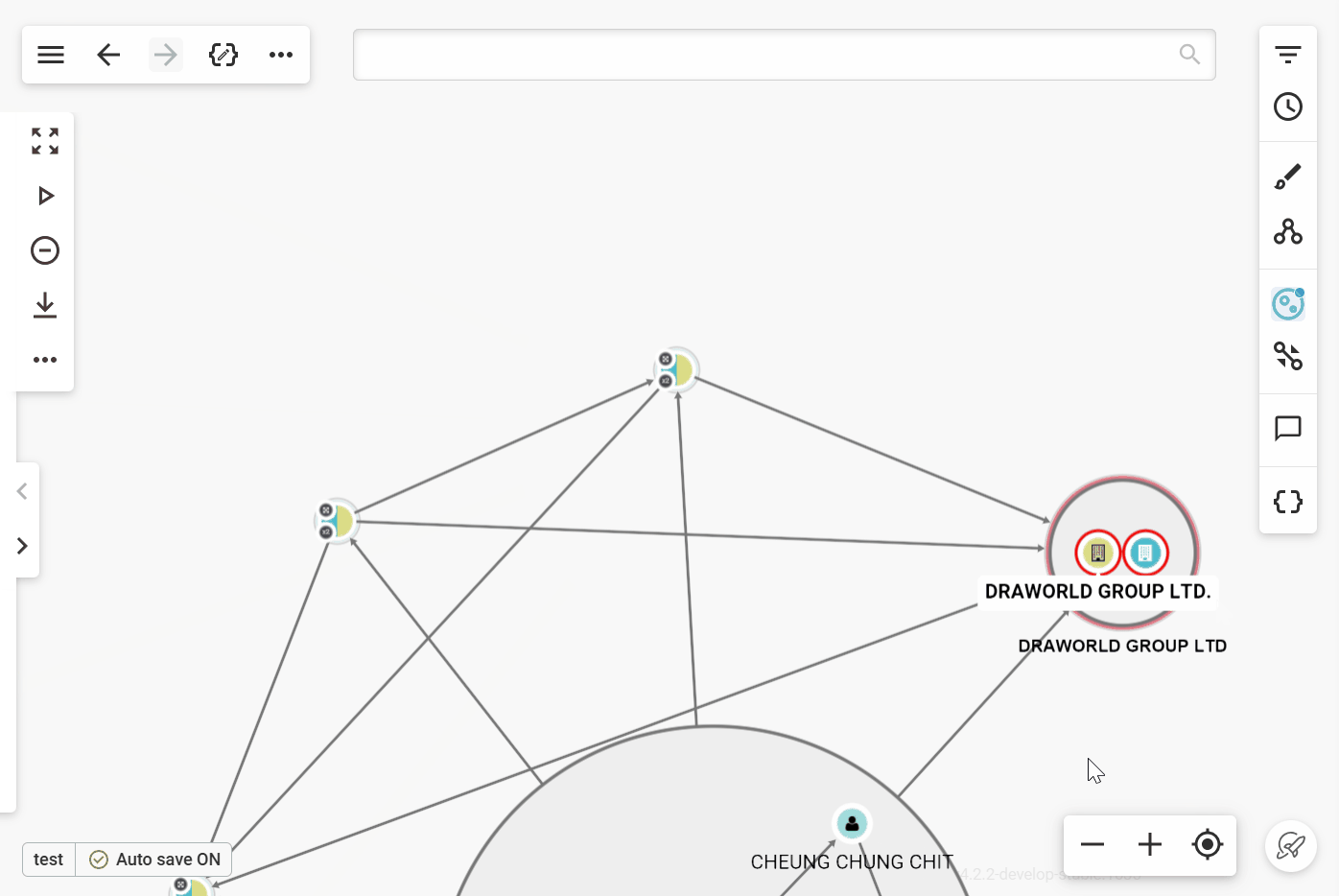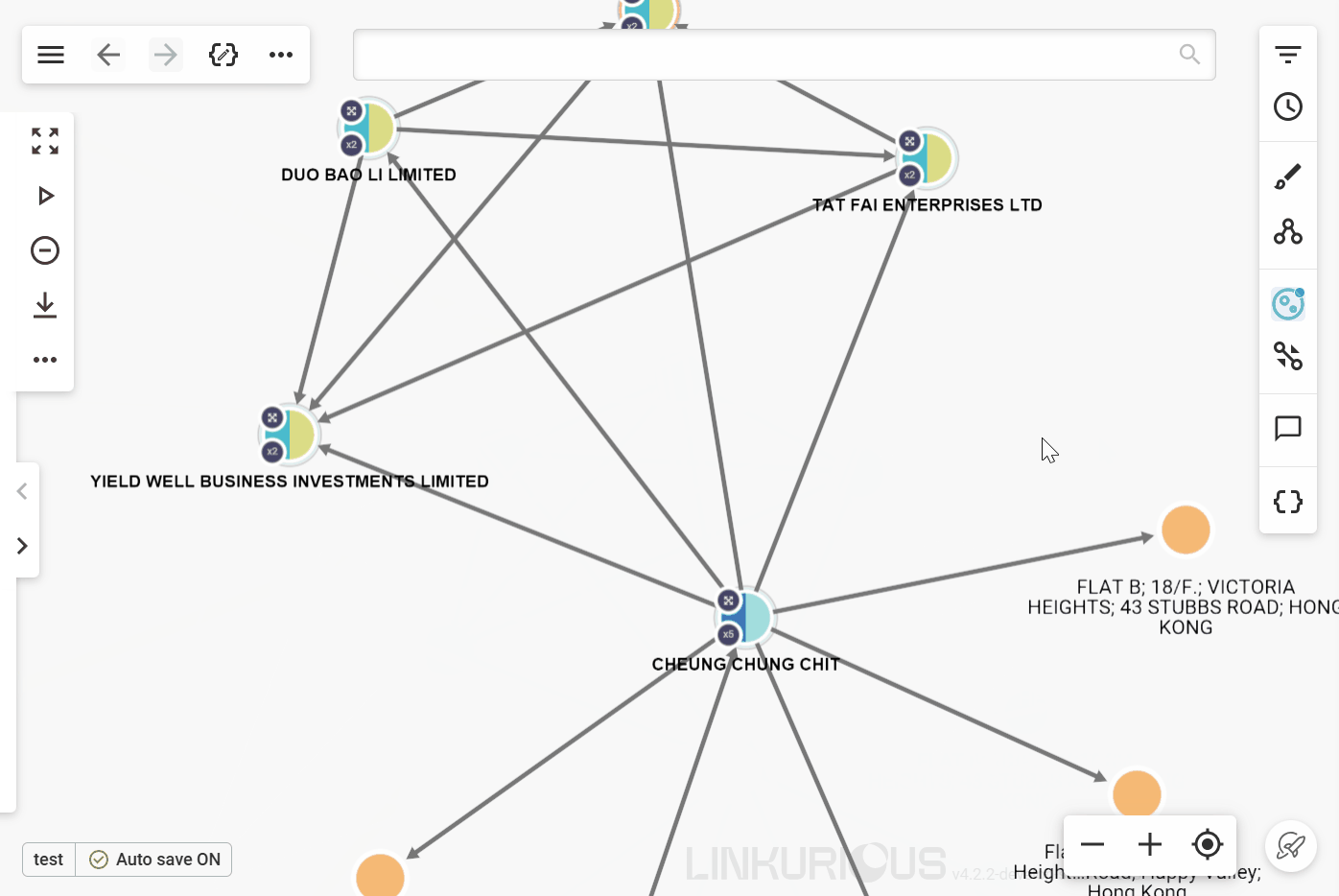
Node grouping enhances network exploration, accelerating the analysis workflow. It simplifies the understanding of complex networks by grouping together nodes that share the same information.
To be able to group nodes, you first need to create a node grouping rule, which will then enable users to activate grouping in their own investigations.
The node grouping panel is accessible by clicking on the following icon in the toolbar at the top right of the screen.
![]()
The node grouping panel will then open, listing the available grouping rules.
If no grouping rule exists, a button will allow to create a first grouping rule.
To create a grouping rule, click on the "Create rule" button at the bottom of the node grouping panel.
Clicking on this button opens a modal with the node grouping rule creation form.
To create a rule, you need first to choose a title. This title will be visible in the group caption. Next, you'll need to select the property on which the grouping will be based.
Nodes can be grouped by one property value. In the example below, we want to group all nodes that belong to the "RealEstateValue" category and belong to the same city (share the same value in their "city" property).
The grouping rule is based on the schema of your database. Therefore, once you've selected a property by which to group nodes, you'll need to choose the categories which this property belongs that you want to group. In this way, you can create a group comprising nodes belonging to one or more different categories. By default, all the categories which the property belongs to are selected.

Once you've created a grouping rule, you'll find it in the list of available rules (in the right panel).
A grouping rule is available to all users of the same datasource. Only the rule creator or an administrator can delete it. Some grouping rules can be built in and not modified by users, such as Entity Resolution grouping rules. To learn more about it, visit admin doc Entity resolution.
You can activate and deactivate grouping rules in your visualization to change its appearance and discover new information more easily.
You can only activate one grouping rule at a time. Activating a second rule will automatically deactivate the previously activated one.
In the example above, we want to focus our investigation on people with a nationality that has been flagged as suspicious by relevant authorities. Rather than looking at each “Person” node to check each one's nationality, we can activate the "Nationality" rule.
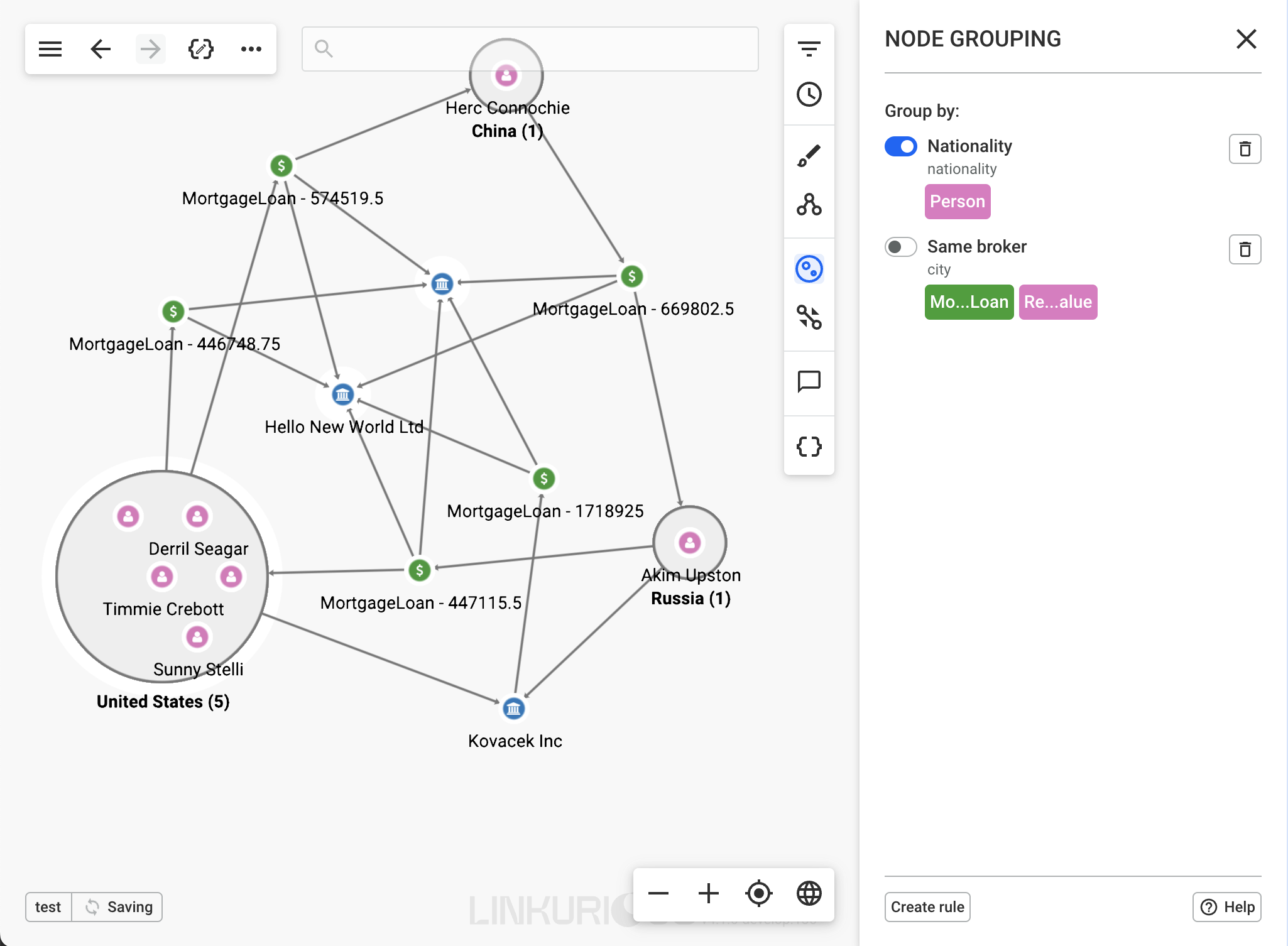
After activating the grouping rule we can see three groups of nodes in this visualization. The first one groups all those whose nationality is "America", the second “China”, and finally the third "Russia". We can then decide to begin our investigation by focusing on the nationality we're interested in. All grouped nodes remain accessible, and all associated functionalities (such as expand, queries, and custom actions) remain available.
For a better analysis experience, grouping will change where nodes are positioned in the visualization. Because of that, the pinned nodes belonging to groups will be automatically unpinned.
To reduce visual noise, you can collapse or expand grouped nodes.
By default, when enabling a grouping rule, node groups appear as collapsed.
Double-click on a node-group to collapse or expand it.
You can also choose to "Collapse all groups" or "Expand all groups" via right-click in an empty space of the visualization.
x4)⚠️ Collapsed groups do not allow expansion of connections (edges) via double-click. Use the right-click menu to expand connections instead.

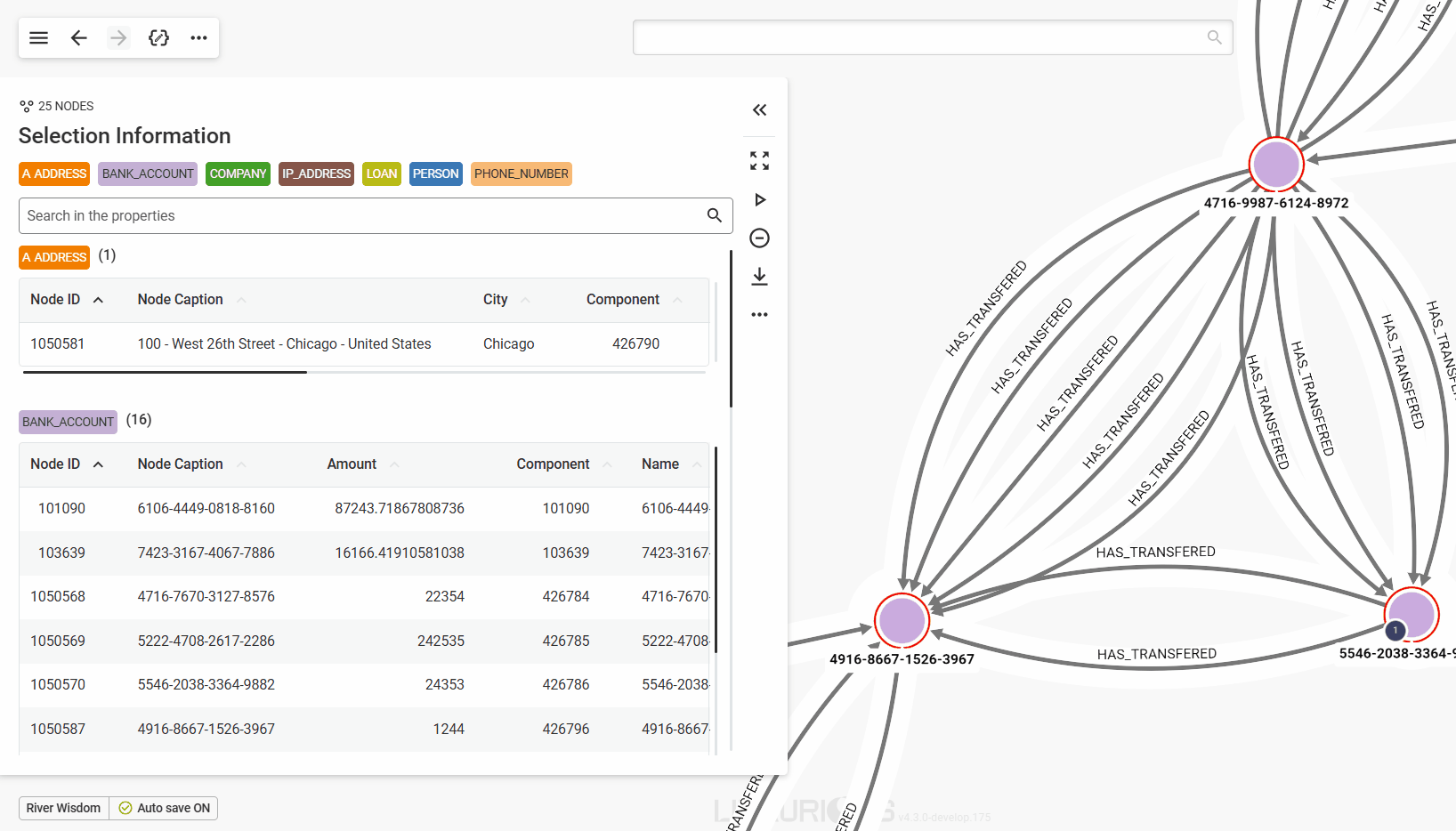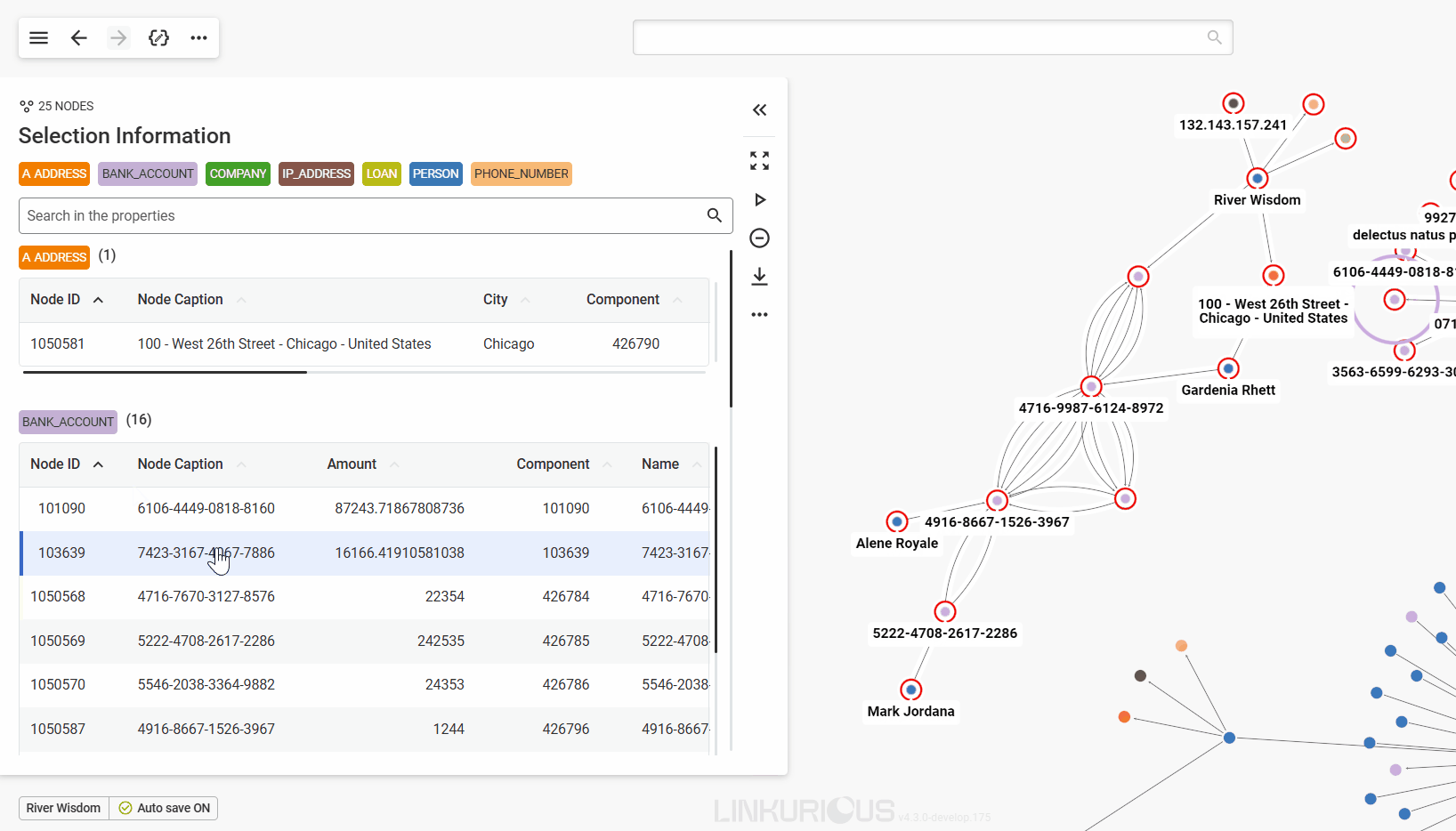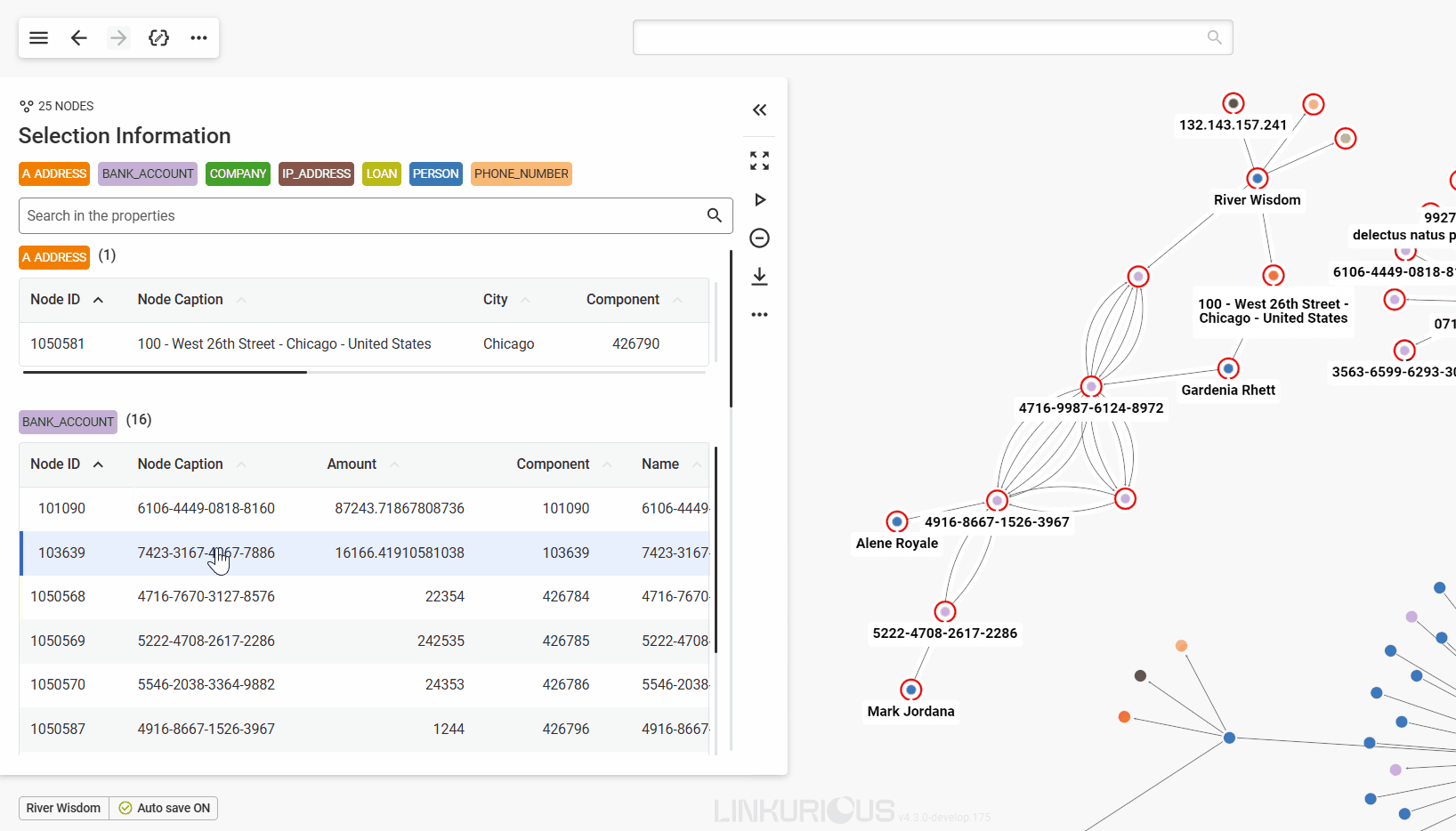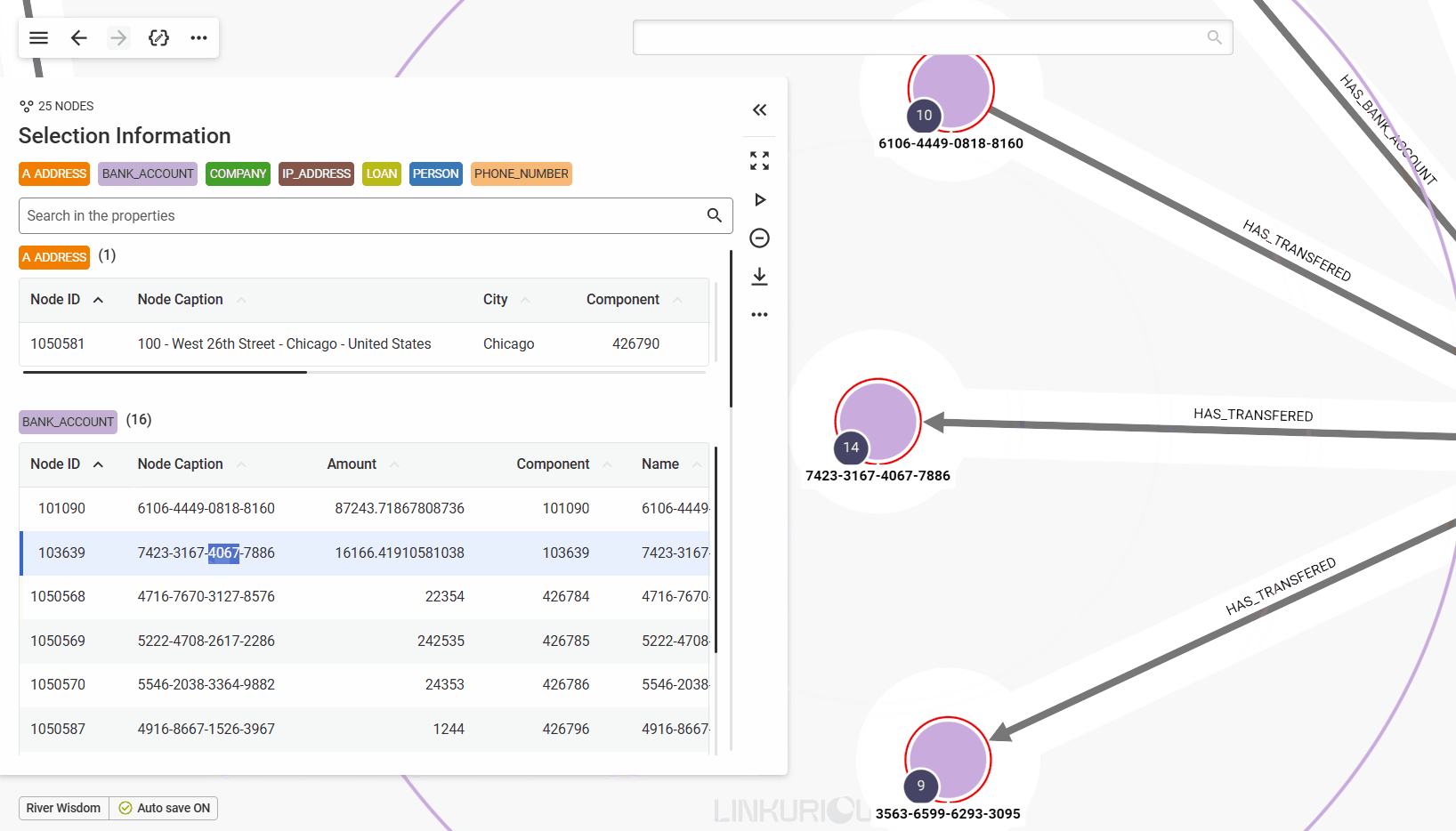
Edge grouping is a feature that allows users to group parallel edges sharing the same type to make visualisations more readable.
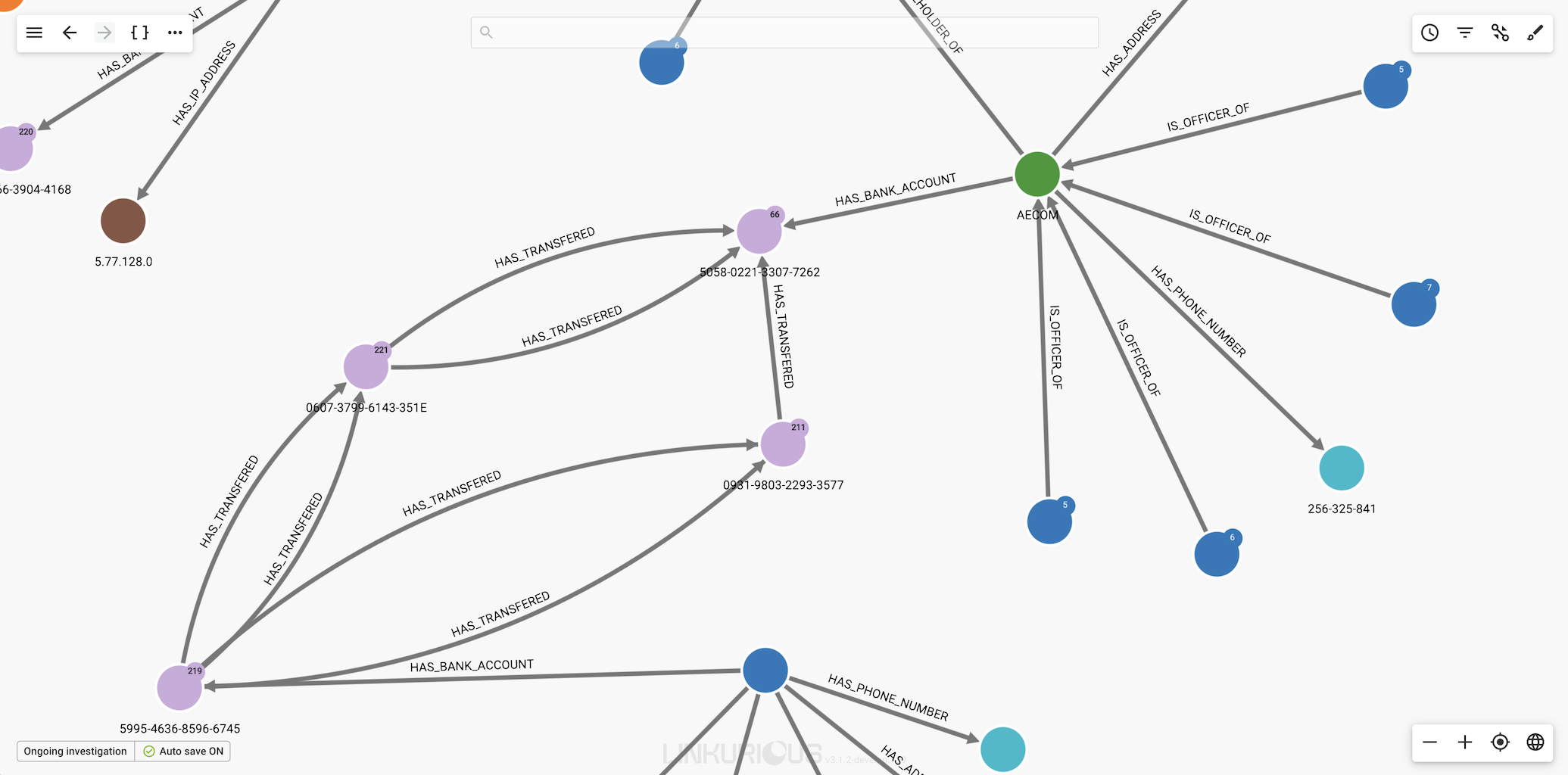
Example: Consider the following visualisation, we would like to group all the edges which has the type HAS_TRANSFERED.
The Edge grouping panel can be accessed by clicking on the following Icon on the right top of the screen.
![]()
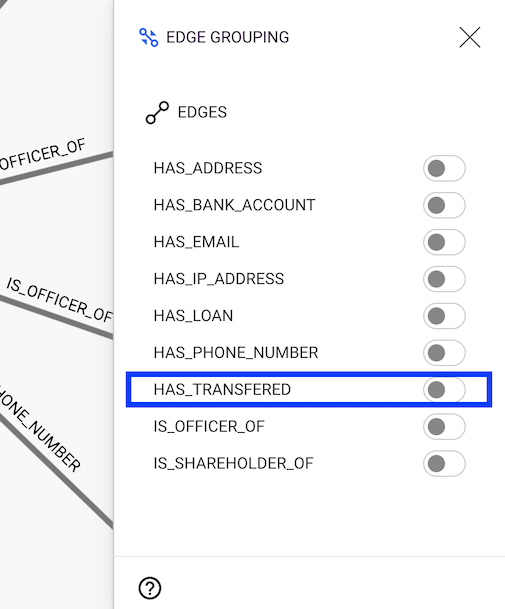
The Edge grouping panel will open with the different edge types to group, in our example HAS_TRANSFERED, HAS_ADDRESS, etc.
By clicking (enabling) the HAS_TRANSFERED button we will see that all the parallel edges with the same direction of that type are grouped in the visualisation as in the following figure.
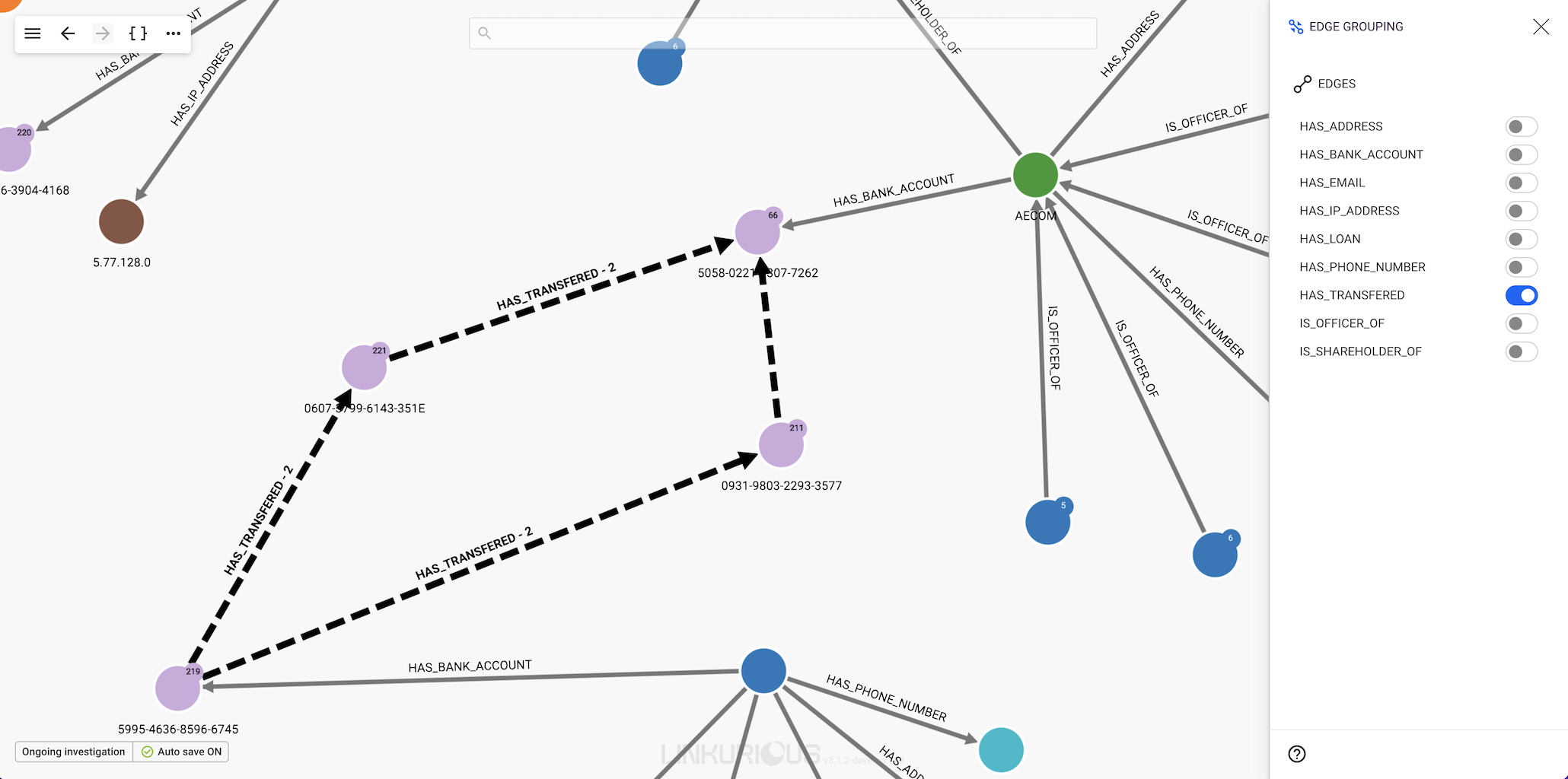
Please note that the number in the caption appearing next to the edge type indicates the number of edges within that group.
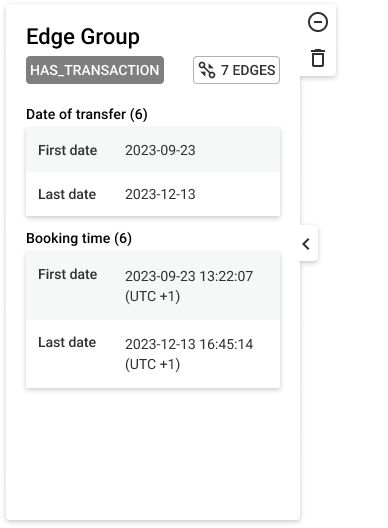
By selecting the edge group, a panel is opened on the left that displays information about the grouped edges.

At the top of this panel, you'll find basic information, including the type and the count of the grouped edges. Then right below, you will see the list of aggregated properties related to the grouped edges.
If the properties are totally or partially invalid, an information message will be displayed in the aforementioned left panel to warn you.
For numerical properties within a given edge group, aggregation will be performed using the following numerical operators: Sum, Average, Minimum, and Maximum. The count of valid properties that have been used to compute the mentioned operators can be found before the operators.
Properties that are set as currency in the schema will inherit the currency format and symbol.
If a given edge group contains a date or date-time property, the left panel will display:
Date or date-time properties will inherit the formatting set in the schema.
It is possible to select the nodes within a particular area of your visualization. For that, Linkurious Enterprise provides a lasso.
To do so, click on the ... in the top menu or right-click on the background.
Select Lasso.
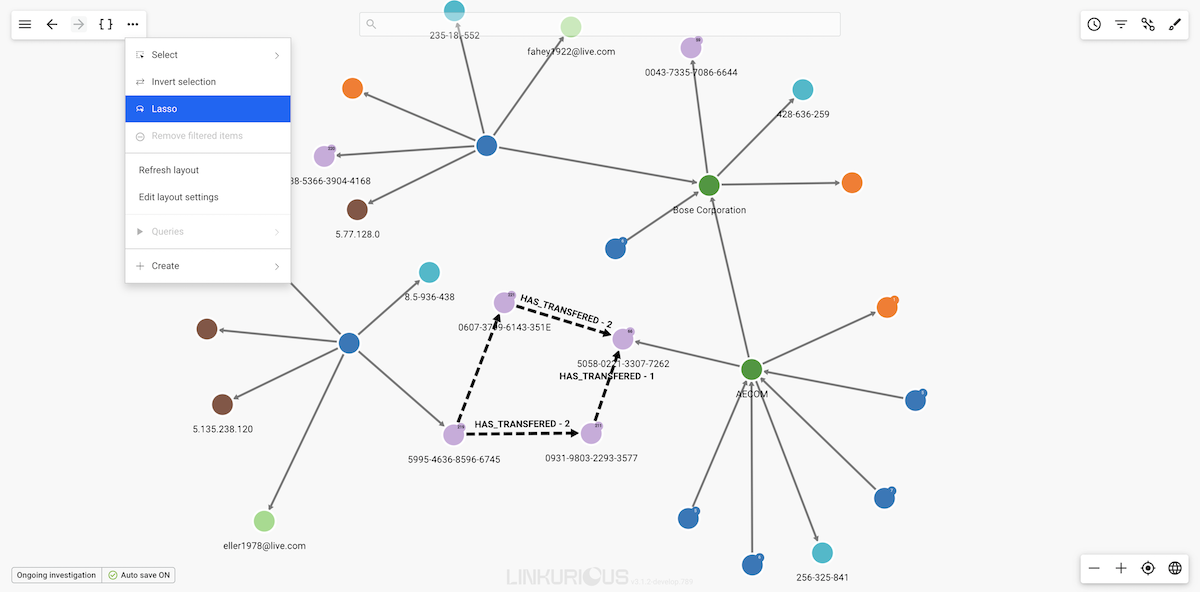
Move the lasso around the nodes you are interested in selecting to select them.
You can also use the lasso by pressing the
ctrlkey (cmdon MacOS) while dragging with the mouse to draw the outline of the desired selection.
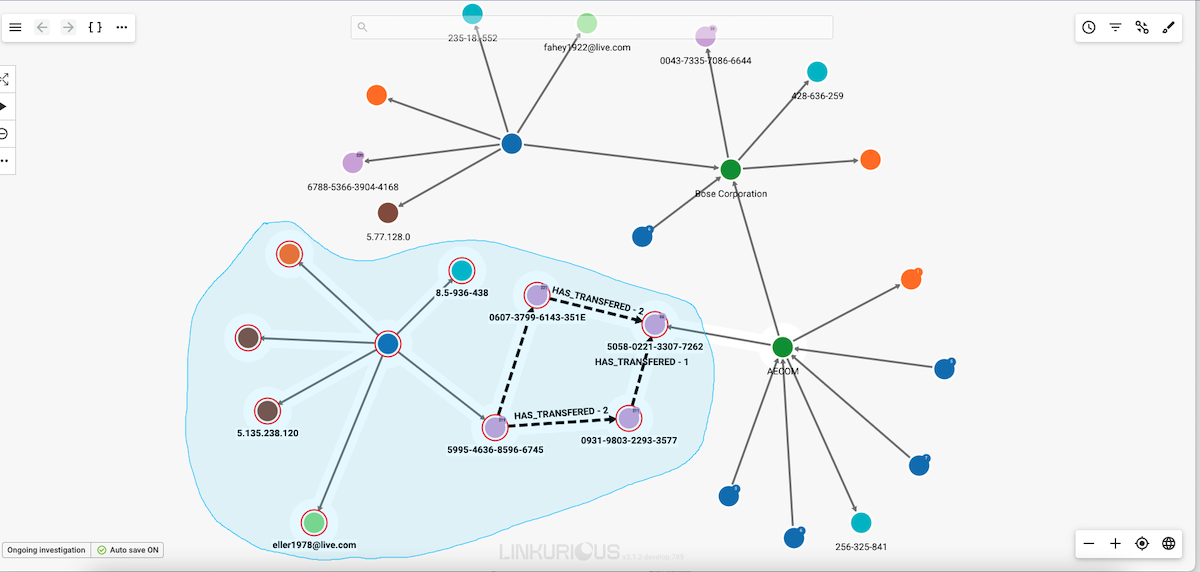
Release the mouse when you are finished and your selection is activated.
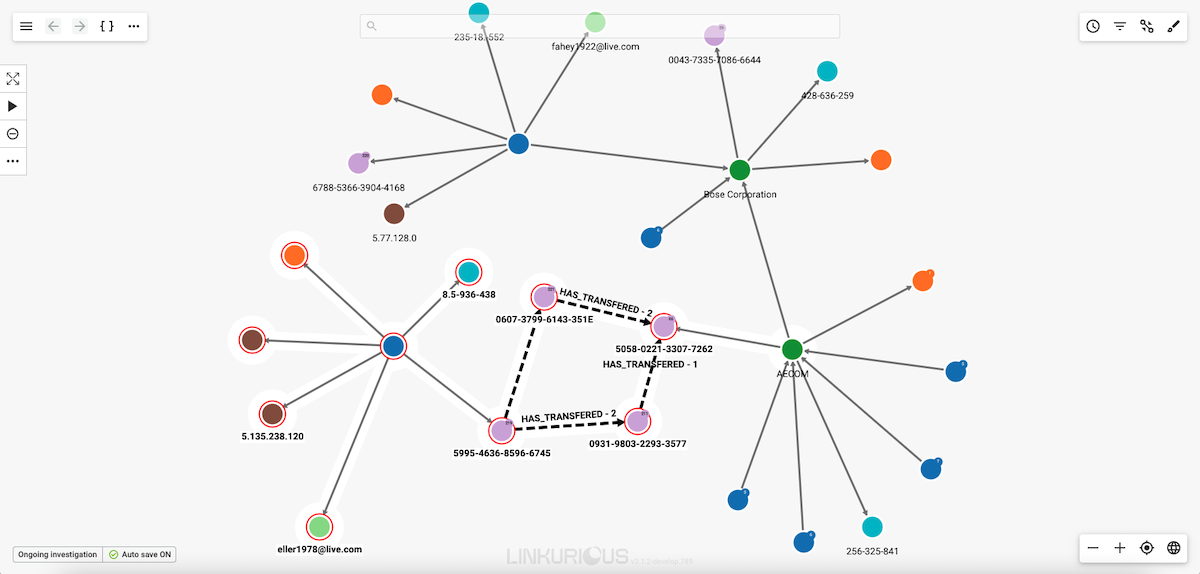
Your visualization is getting too complex and you may want to remove from a visualization (i.e. hide) a few nodes or edges from a visualization to make it easier to understand. Notice that hidden nodes an edges are not deleted from the database.
In the picture below, three nodes are selected.
Simply click on the Remove icon to remove them from the visualization.
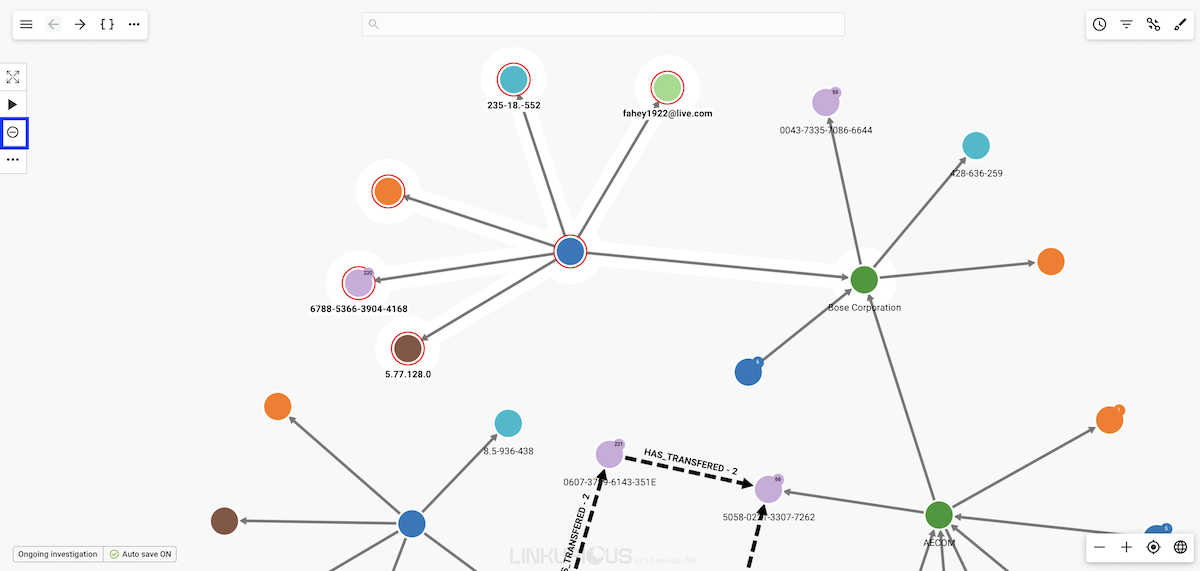
The six nodes are now removed from the visualization.
The Toggle Lasso option can be used to select the nodes we want to hide. We need to make sure the central node is not selected, otherwise all the edges connected to this node will also be hidden.
At the bottom right of the workspace there are controls allowing to "Zoom in", "Zoom out", and "Locate", i.e. center the screen on the current selection.
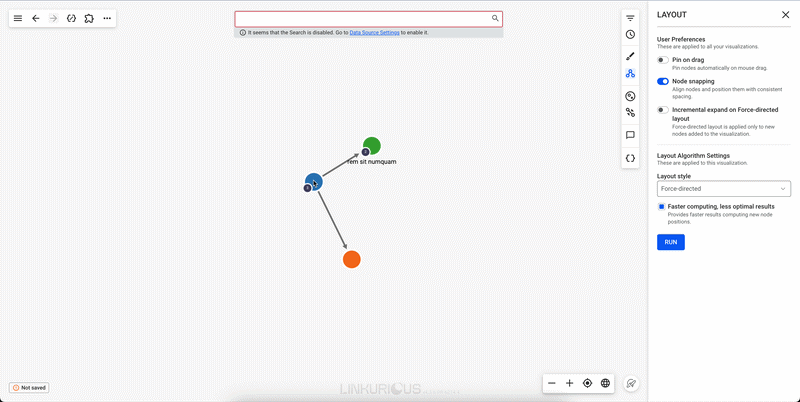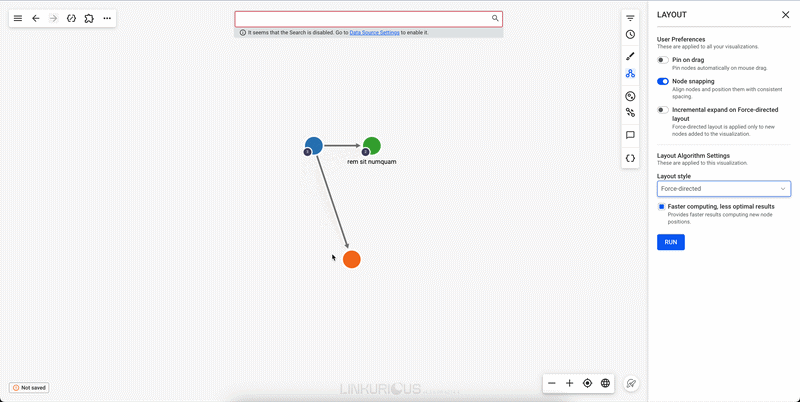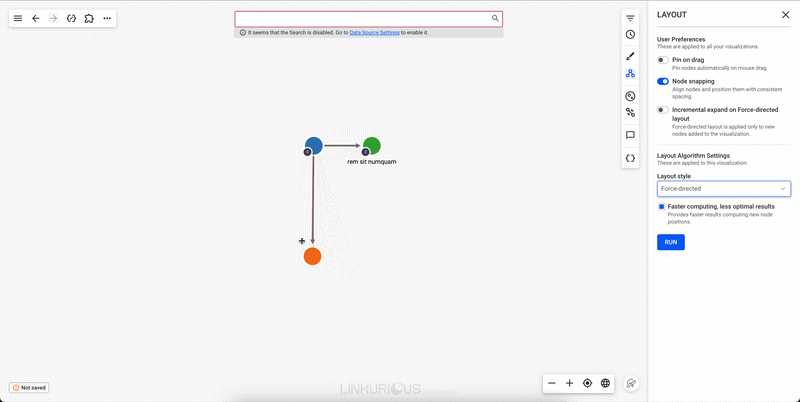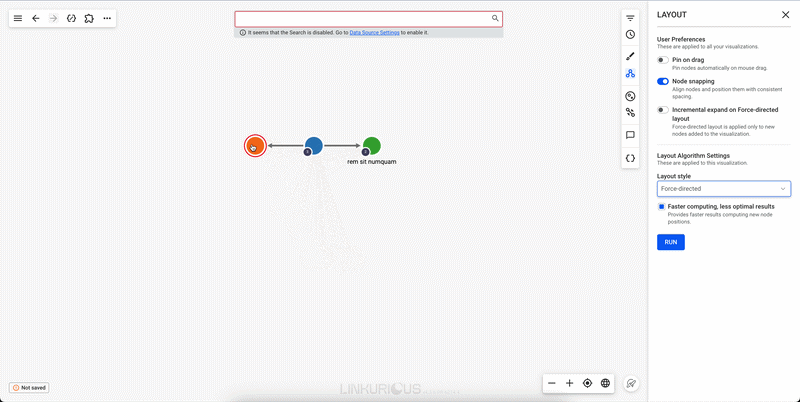
Using a layout on the graph brings clarity. To refresh the current layout, right-click on the background, or click on the "More" menu at the top of the workspace, and choose "Refresh layout" in the context menu.
To apply another layout, you can follow the same steps and choose "Layout settings", or you can do it by clicking on the layout setting icon on the right.
![]()
By default the layout is run automatically on the whole graph in some conditions, such as when an expand is performed. It is possible to switch to an "Incremental expand" mode in the Layout settings.

Note that "Incremental expand" and "Pin on drag" are user preferences which are going to be applied to all your visualizations.
This is the default layout, enabled in "fast mode" option. You may turn this option OFF for better looking but slower results.
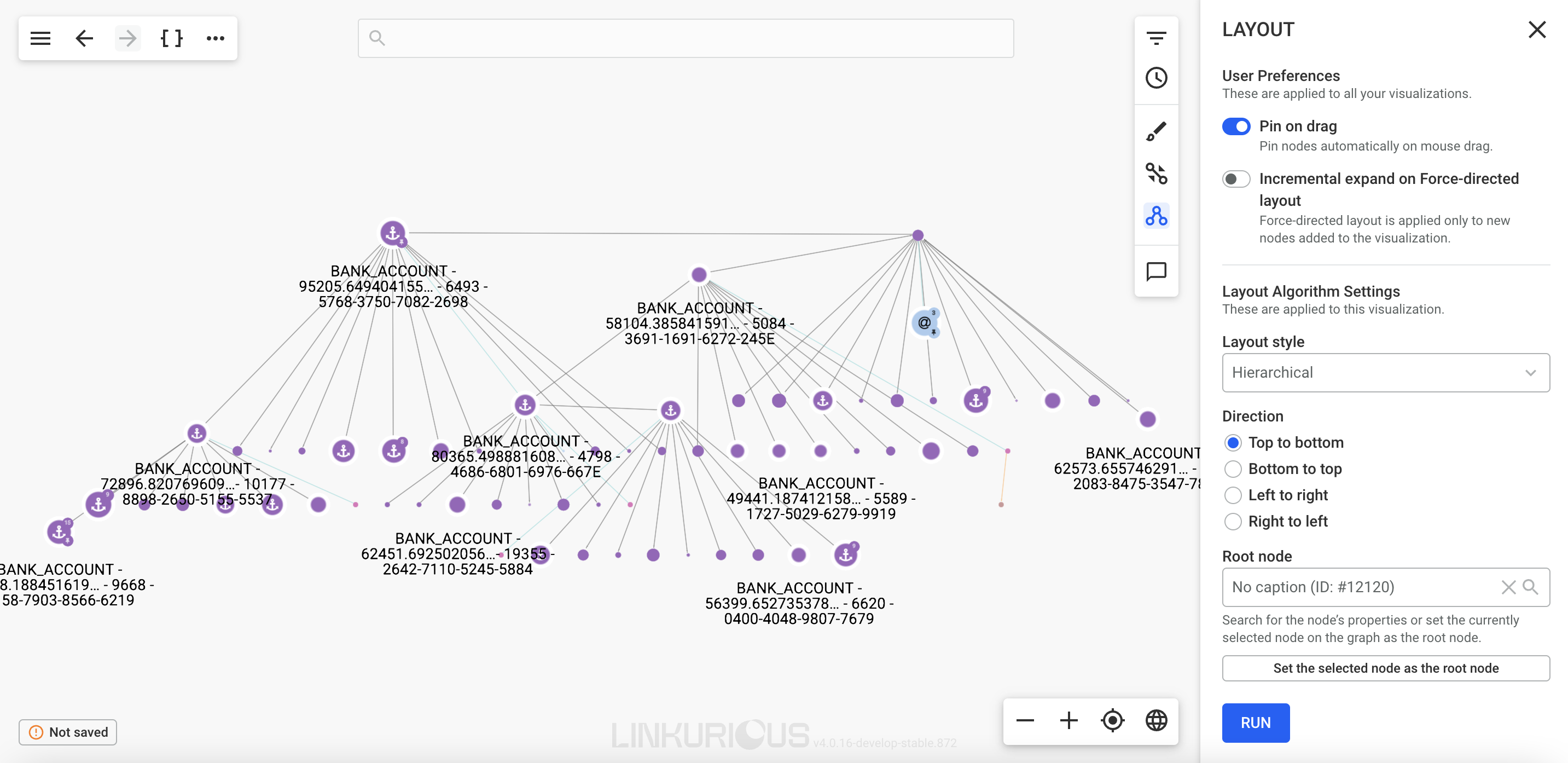
The hierarchical layout organize nodes in different layers by aligning nodes of each layer vertically or horizontally. It produces a tree-like structure if there is a single root node (the node at the top of the tree):
You may choose a root node, by using the search or selecting a node from the graph and clicking "Set the selected node as the root node" button".
You may choose the orientation, for instance "Top to bottom" places the root node at the top.
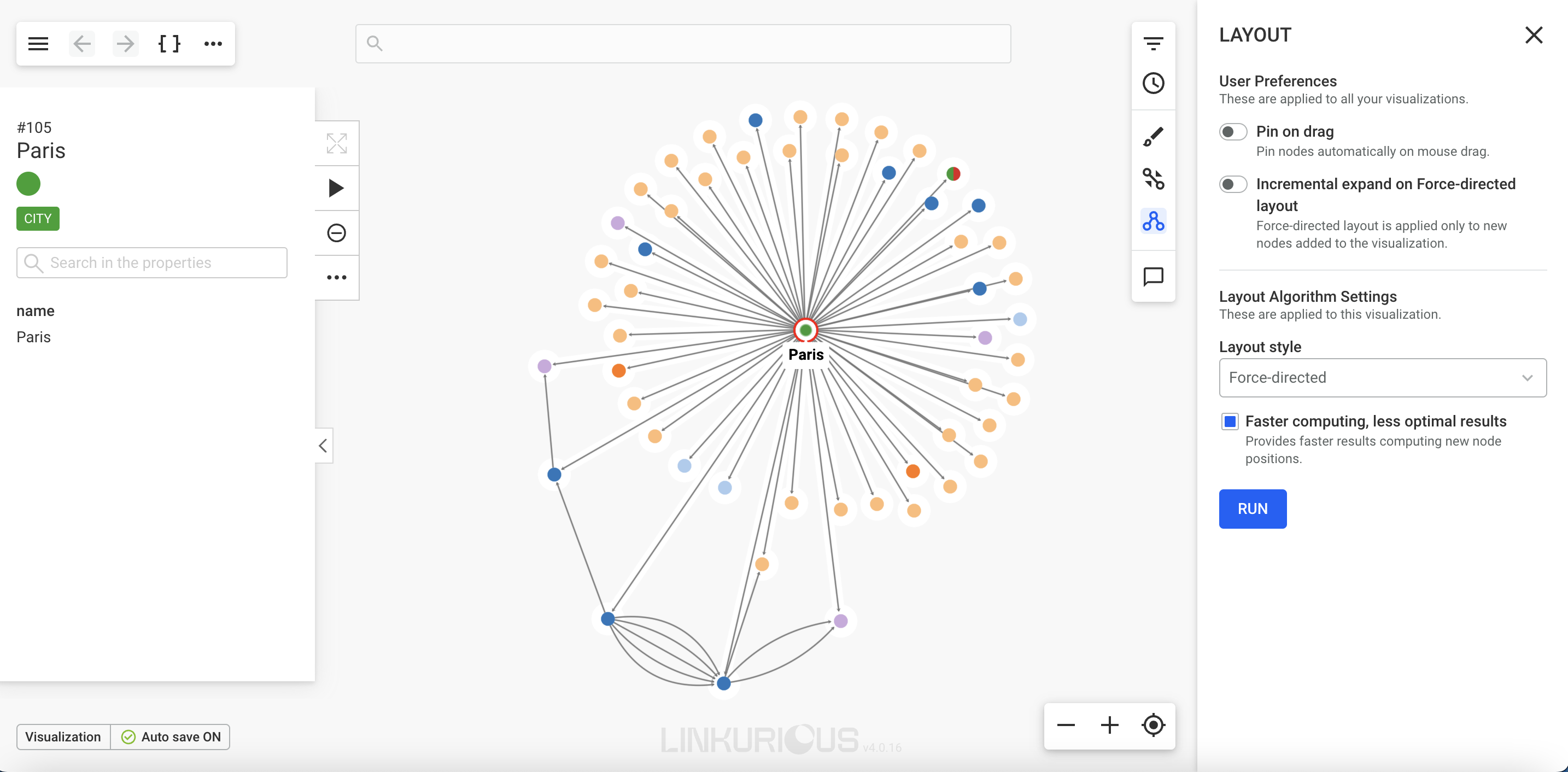
Radial layouts position nodes around the currently selected node (used as center of the layout) based on their graph-theoretical distance (shortest path in the graph). This is useful for revealing layers in data and for drawing the rest of the graph in its relation to the pre-defined focus node.
You must choose a root node, by using the search or selecting a node from the graph and clicking "Set the selected node as the root node" button".
Example:
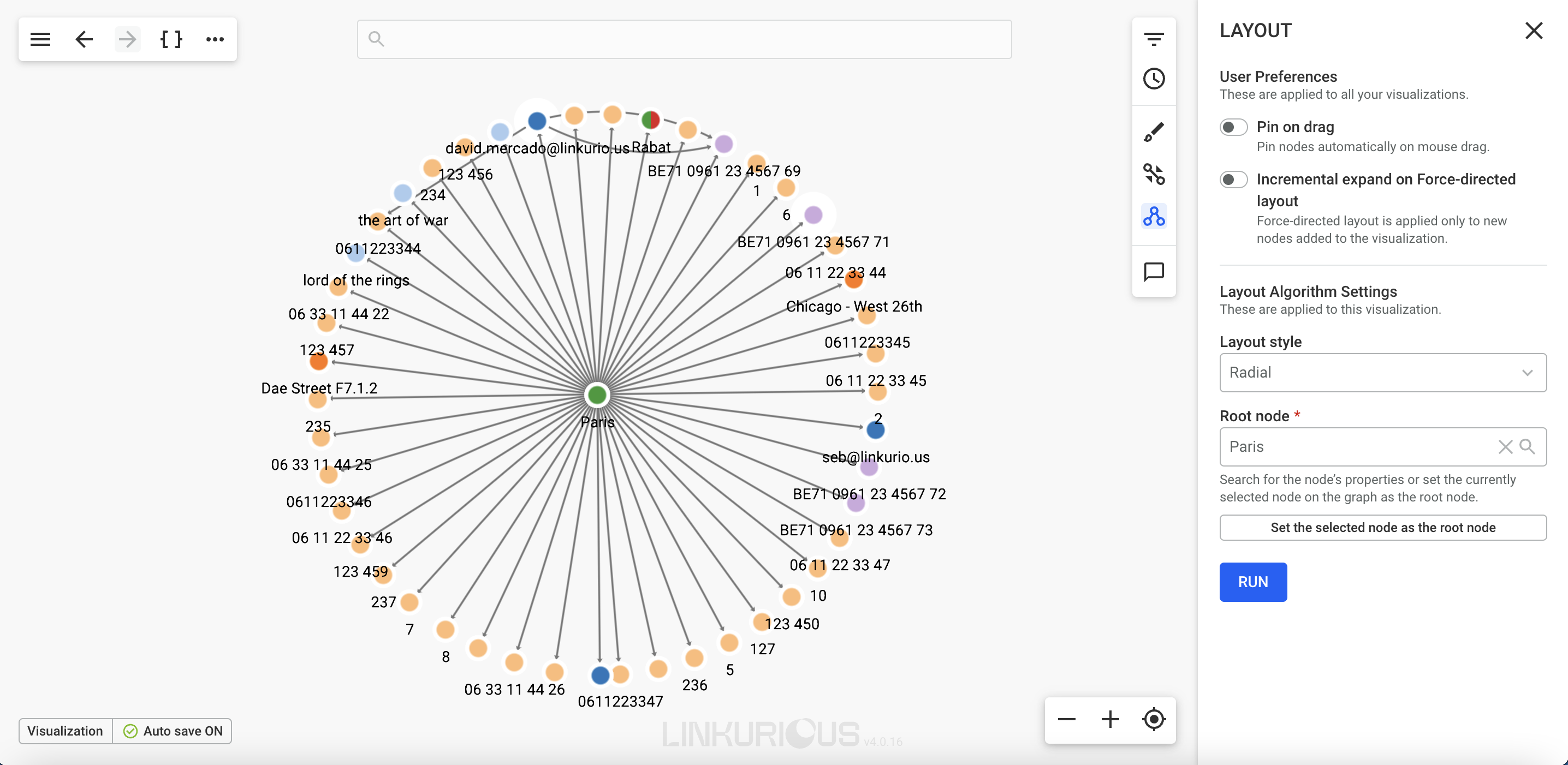
Note that you will not be able to apply the radial layout for visualizations with more than 1500 nodes.
It is possible to pin the nodes on your graph visualization. Pinning a node allows to fix it at a specific place on the graph.
To pin a node, we can either select Pin on the tooltip opened by right-clicking,
or click on the ... in the actions menu.
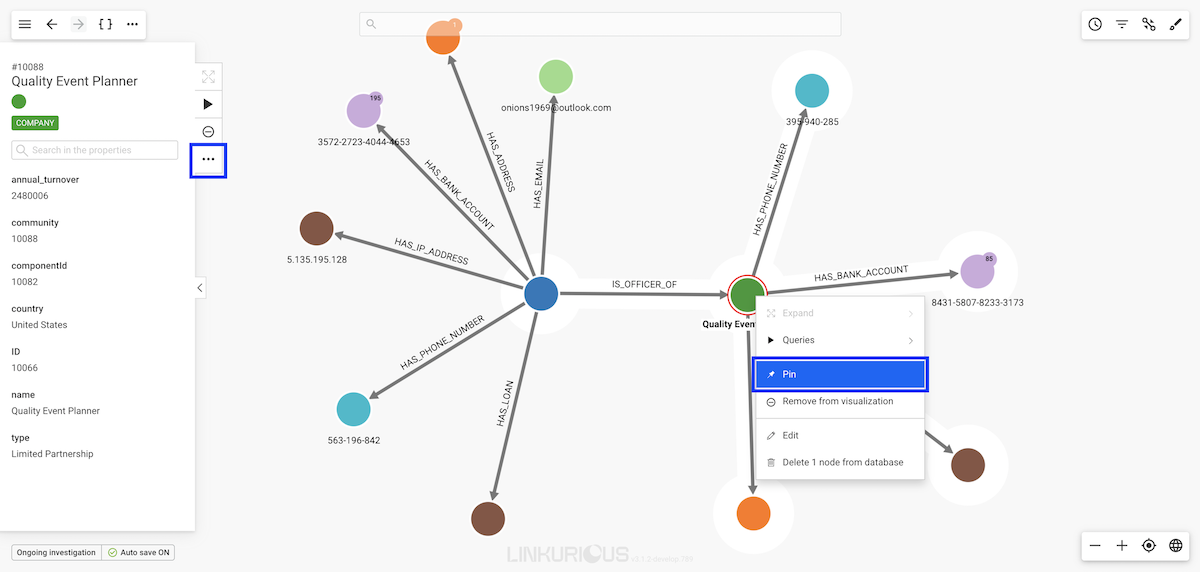
A pin symbol appears on the node.
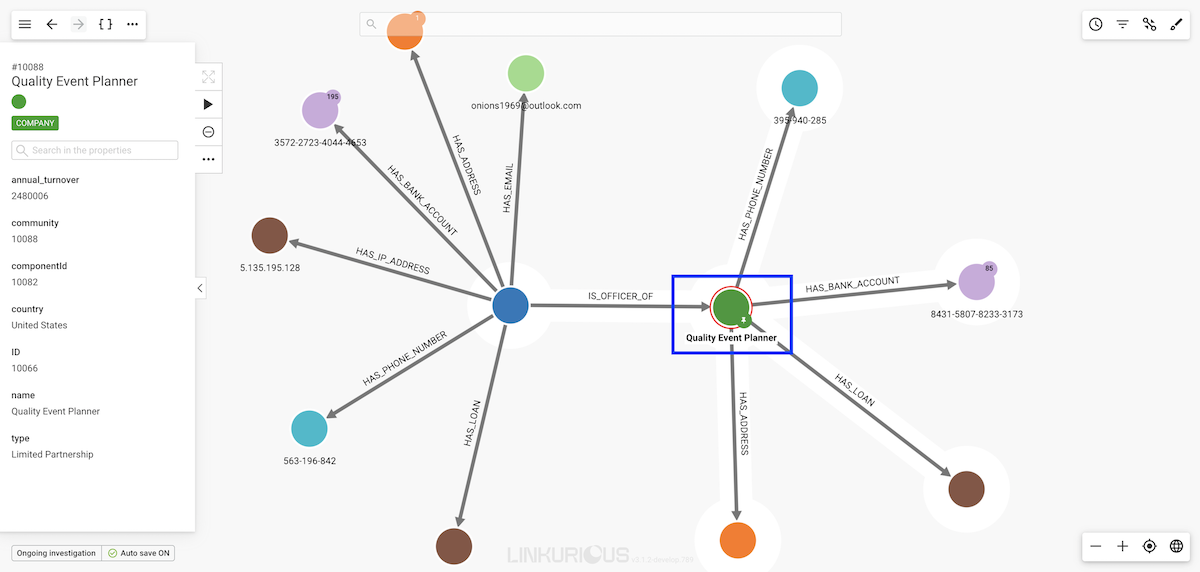
If we pin a node, this node will stay at the same place when we move the rest of the graph, for example using the force-directed layout option:
We have the ability to pin nodes automatically on mouse drag, that could be done from the layout settings.

You now have the possibility to revert your last action on a visualization.
You can revert only the last action you do in the visualization.
For example, after expanding a node, clicking the undo button
(or using the shortcut ctrl-z or cmd-z on MacOS) will revert the expand by returning the graph to its previous state.
After reverting the expand, you can go back and re-run it by clicking on the redo button (or using the shortcut ctrl-y or cmd-y on MacOS).
We have now the same nodes in the same positions as before.
Some actions cannot currently be undone :
Depending of your operating system, you will have to use the ctrl key (Windows, Linux) or the cmd one (MacOS) to trigger actions.
← Move camera left↑ Move camera up→ Move camera right↓ Move camera down+ Zoom in- Zoom outctrl/cmd + click Add/remove nodes or edges to the selectionctrl/cmd + a Select/deselect all nodesctrl/cmd + backspace Hide selected nodes or edgesctrl/cmd + drag Use lassoshift + click Select all direct neighbors of a node (or a selection of nodes)ctrl/cmd + c Copy selected nodesctrl/cmd + v Paste copied nodesctrl/cmd + e Edit selected node or edgectrl/cmd + z Undoctrl/cmd + y RedoLinkurious Enterprise offers the possibility to publish interactive visualizations online. Published visualizations can be accessed with an URL or embedded in a Web page à la Google Maps. They contain a snapshot of graph data at the time the visualization is published. The visualization author can update or un-publish his visualizations anytime. Anyone can explore these visualizations interactively, enabling easier collaboration around graph data.
We can publish a visualization from the Workspace via the left menu:
Before publishing a visualization, we can choose various options to customize the interface:
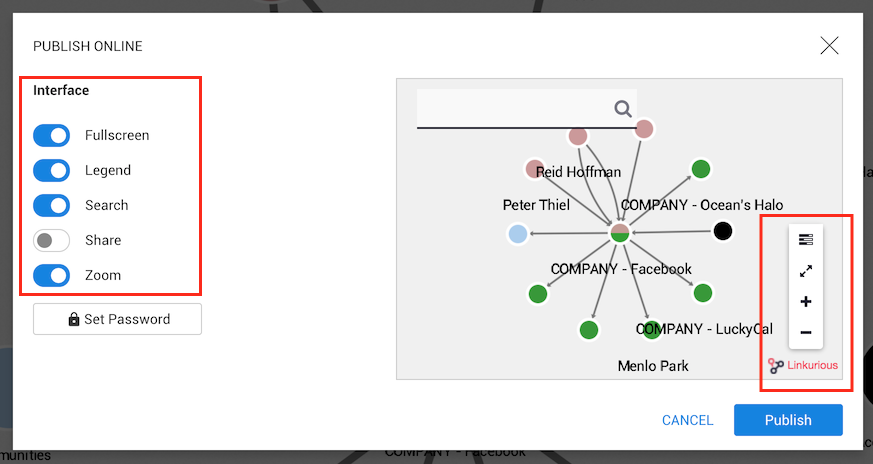
The options are:
In the screenshot above, we have disabled the share option.
We can see that the Share button on the right of the screen
disappeared.
Finally, we can publish it:
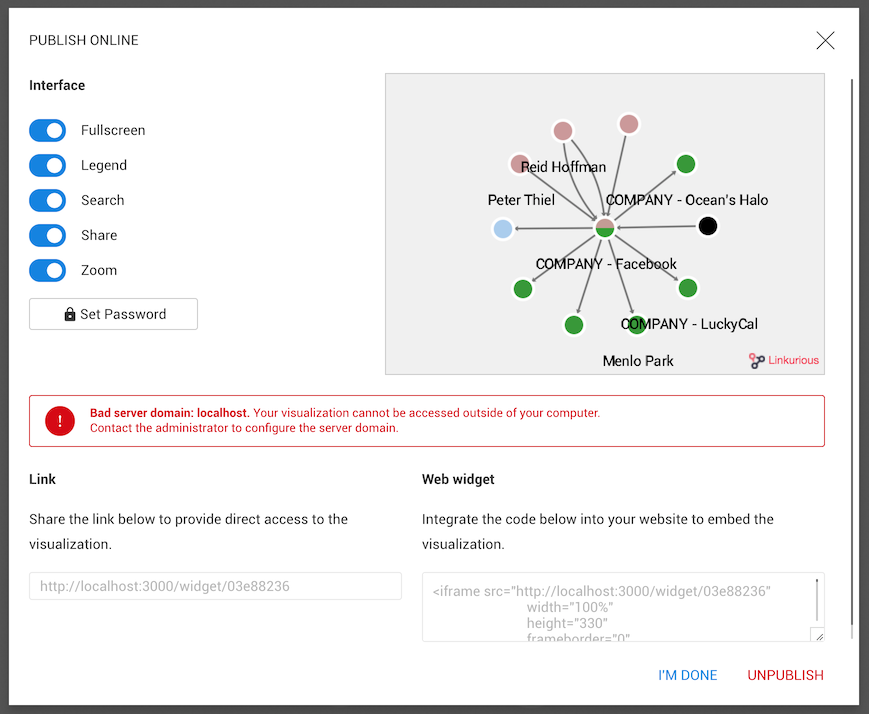
The visualization is now available online! We can share the link or integrate it into a web page by adding the script of the web widget into the source code of a web page.
If the server that hosts Linkurious Enterprise is accessible via intranet only, published visualizations will be available within the organization and won’t be available outside.
The export feature allows you to export visualizations either as images or data, supporting various formats and customizable settings.
This feature is available :
anytime from the Top Left Menu
when selecting multiple entities via Right-click on a selected entity, or from the selection panel.
Note : Only data export is available from selection.
Admin: The export feature can be disabled for all users from the global configuration settings.

You can choose to export either "All visible data" loaded in your visualisation, or the "Selected data only" (entities you've selected). The following formats are supported:
Note: The tool exports only the raw data, and visual properties (e.g., colors, positions) are not included in data exports.
Note 2: when you export from a selection, the "Selected data only" option is already selected.
There are no specific limits on the number of entities that can be exported, even for "selection only" exports. However, exporting larger datasets may take more time, with progress indicated via the browser's download status.
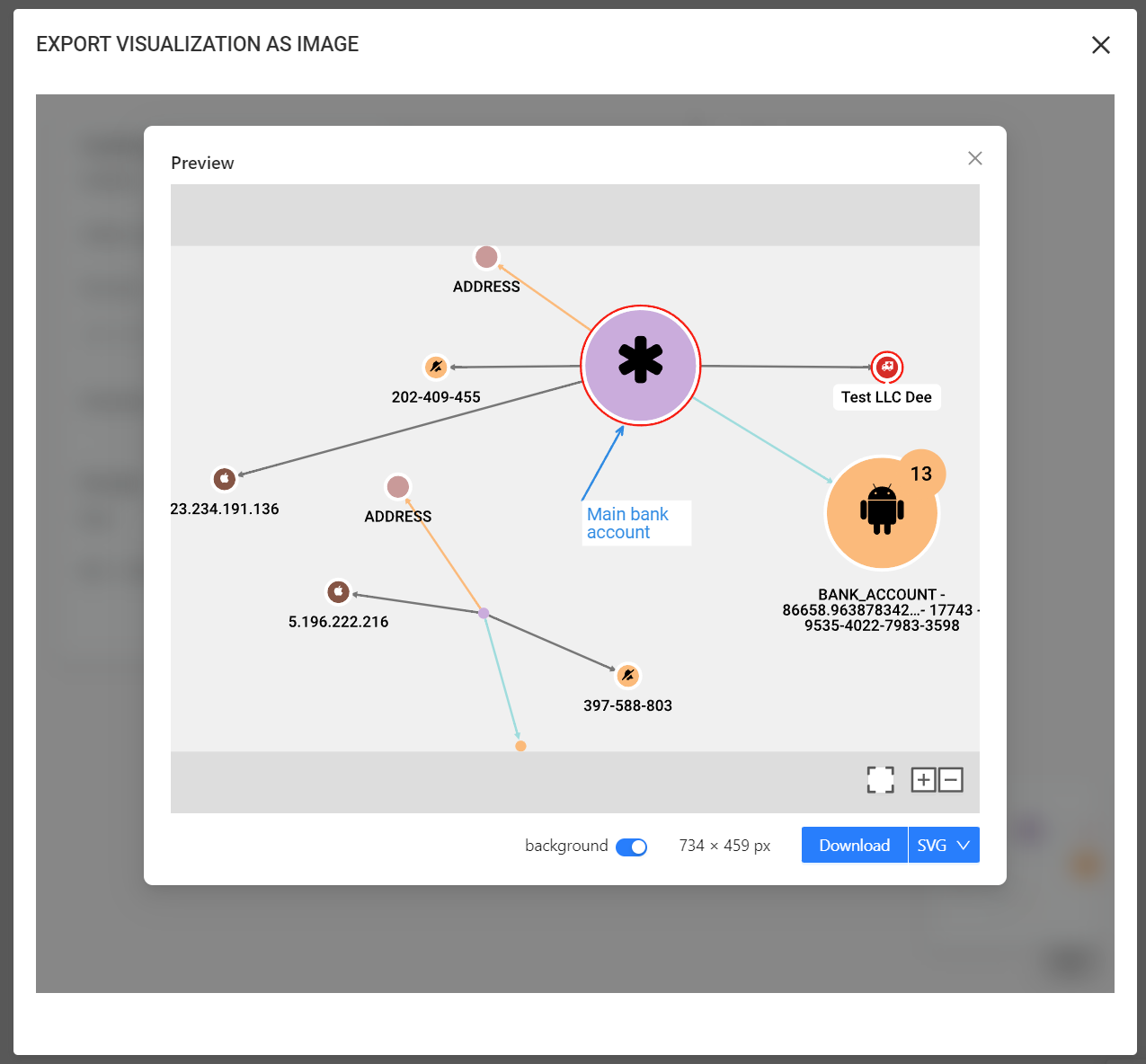
When exporting a visualization as an image, users can reposition nodes, add annotations (text and arrows) and adjust the resolution size to get the best image to present for reporting. The export interface offers a preview, ensuring you can fine-tune settings before finalizing the export.
Note: any node or edge selected and highlighted in your visualization will appear as such in the export window.
Drag Entities: While preparing the image, you can drag entities within the visualization to enhance your presentation.
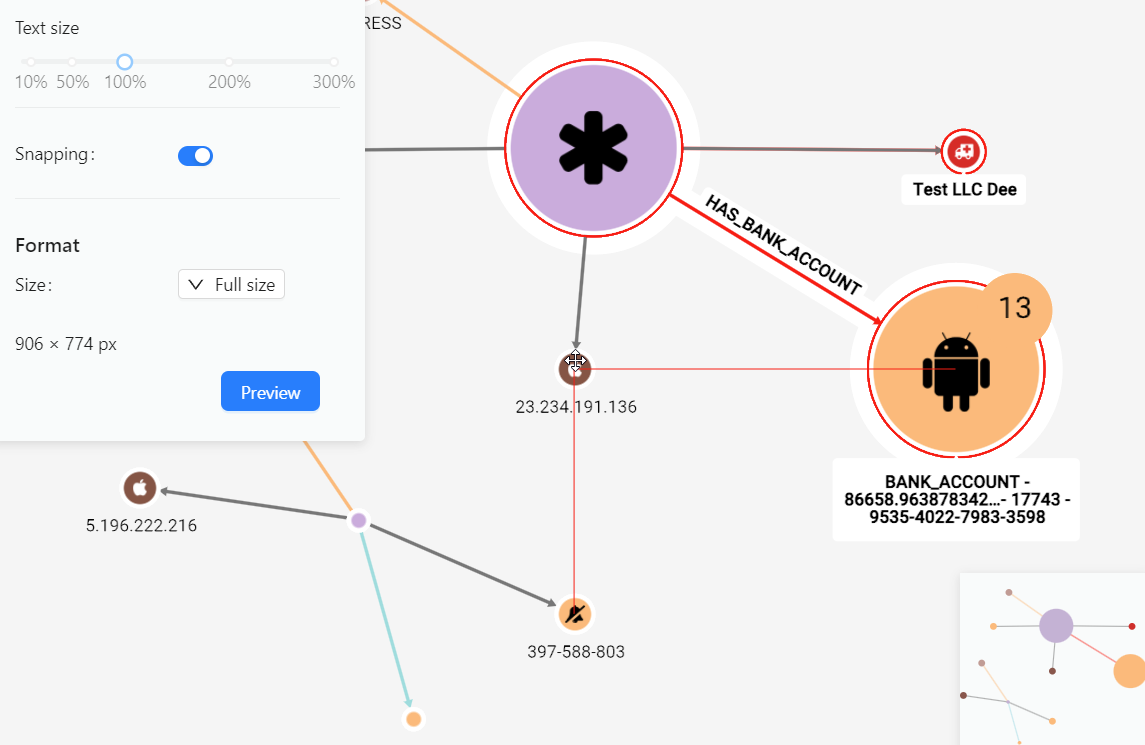
Snapping: This setting helps you line up nodes with each other by displaying grid lines and snapping the node you are moving to the closest position. This can help with the visual clarity of the export.
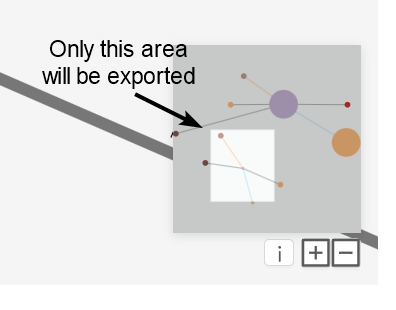
Zoom: You can zoom in and move the visualization in order to export only what is visible on screen. You can preview the section that will be exported by observing the map on the bottom right.
Change the style of the nodes and edges captions according to your needs.
Size: This allows you to set the export to a specific size for printing. You can choose from predefined sizes such as Full Size (ensures no cropping), Square, 16:9, 4:3, A4, etc.
Text: You can add text annotations to the export by selecting the text tool (T) on top of the export window and then placing your cursor where you want your text box to be within the graph in the export window. By selecting the downward arrow next to it, you can customize text font, size, color and background, before or after you add a comment.
Arrows: You can add arrows to the export by selecting the annotation tool on top of the export window (➡) and then dragging your mouse to draw an arrow. By selecting the downward arrow next to it, you can customize the arrow head, thickness and color.
![]()
To move or resize a text box, select the comment by clicking on the comment box outline and drag them to the desired position or drag the corners to adjust the comment box size. To move or resize an arrow, select the arrow by clicking on it and drag it. Arrows can also be attached to a comment box by dragging one end of the arrow to the edge of the comment box.
![]()
Text boxes and arrows can be deleted by selecting them and pressing the "delete" key on your keyboard.
After adding annotations or adjusting resolution, you can preview the image and return to editing if needed. The preview is a close representation of the final export. Export is possible from the preview screen to finalize and download the image.
You can select if the visualization background should be enabled (visible) or disabled (transparent) in the export as well as choose the export format. The following formats are available:
In this chapter, we'll learn how to adjust the captions, the colors and the sizes of nodes and edges. This will help you make your visualizations more meaningful.
All these features are available on the Design panel that can be open by clicking on the following icon on the right top of the screen:
![]()
The Design panel will open with the Styles and Nodes tabs pre-selected:
Styles set in a new visualization are automatically re-applied to newly created visualizations. Users can reset their styles to default styles at any time from the gear icon at the bottom-rigth part of the Styles or Captions panel.
Default styles may be defined by an Administrator of Linkurious Enterprise. Users can then change these styles after creating or opening a visualization.
By default, every node category has a pre-assigned color.
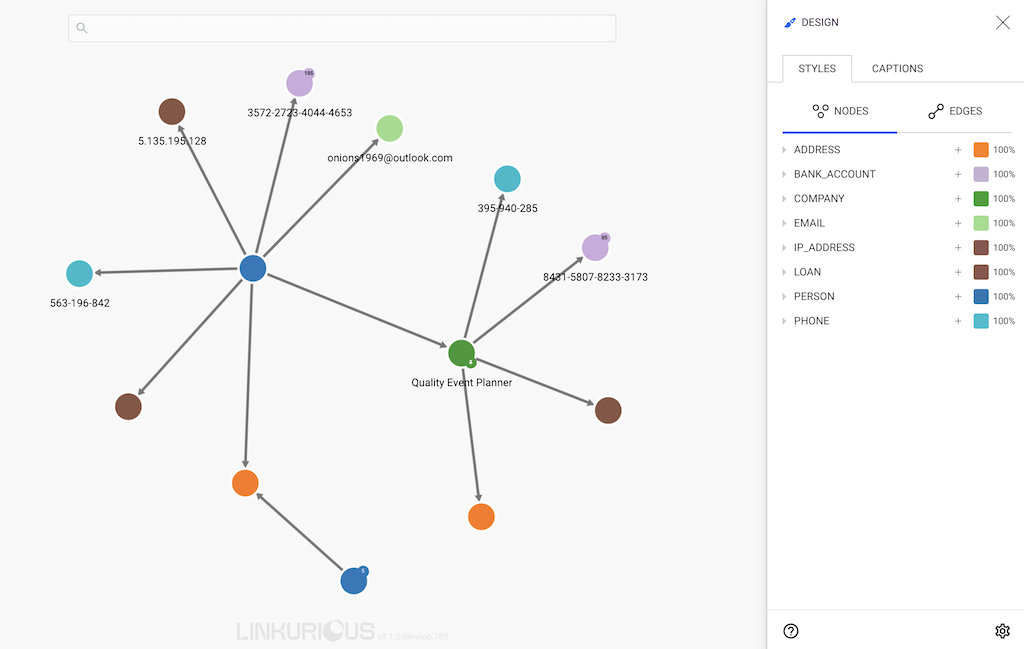
Linkurious Enterprise lets you choose which properties should be displayed on the workspace next to every node and edge.
On the example below, only the names of the nodes are displayed by
Linkurious Enterprise.
In order to customize this, we need to open the Design panel and select the Captions tab.
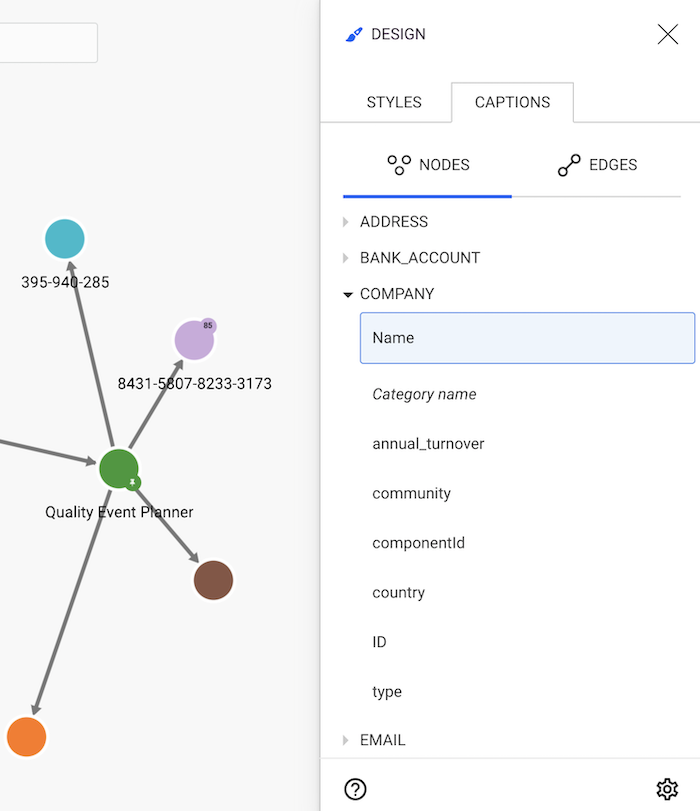
On the Captions tab, we can see the different properties of the nodes
in our graph. The Name property is currently the only one shown. Let's add then the Country to the visualization;
to do so, we click on Country. This property is now added to the displayed
properties listed in the red area.
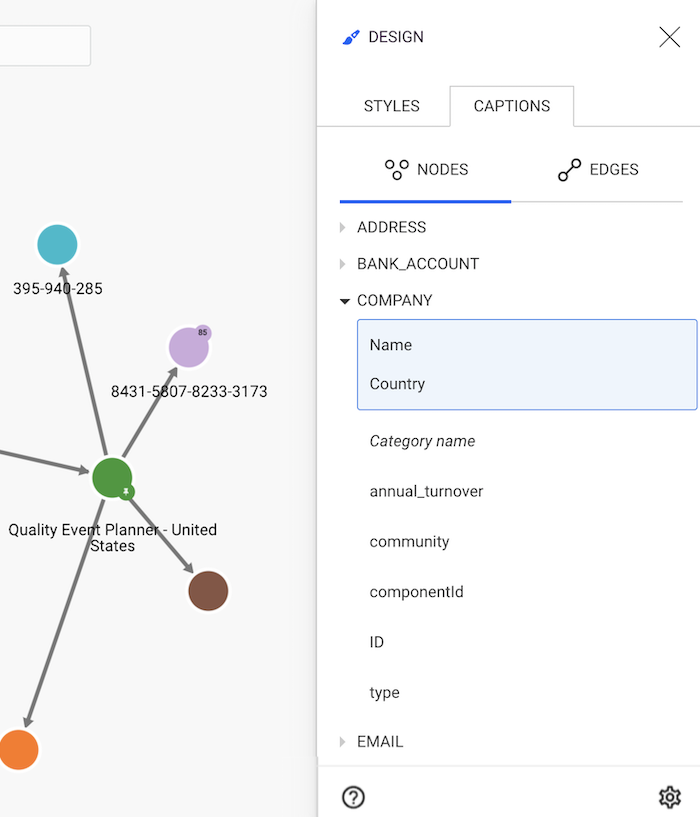
The text displayed next to the nodes is now different:
instead of Quality Event Planner we can see Quality Event Planner - United States.
The same approach can be used for the edges, whose list is available on the Edges tab.
Linkurious Enterprise will use the properties in the order they appear in the list. By placing the cursor on one property already in the caption list, we have the possibility to change the order or to remove properties.
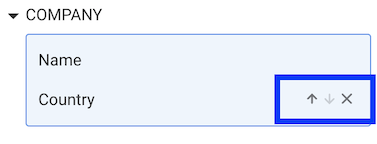
If a node doesn't have a property, Linkurious Enterprise won't show a caption for that property for that node.
If all your nodes or edges have the same color, it is difficult to distinguish them without looking at their individual properties. A great way to solve this is to color the nodes according to a certain category or property.
For example, our nodes with category LOAN may have a type property that we would like
to highlight; Linkurious Enterprise enables us to color the nodes according to a particular property, here type.
This way, a condo and a house loan will have different colors despite having the same category; it will be easier to distinguish them visually.
In the picture below, we see that company Hello New World Ltd is connected to many loans. At first glance we have no idea where these loans are for.
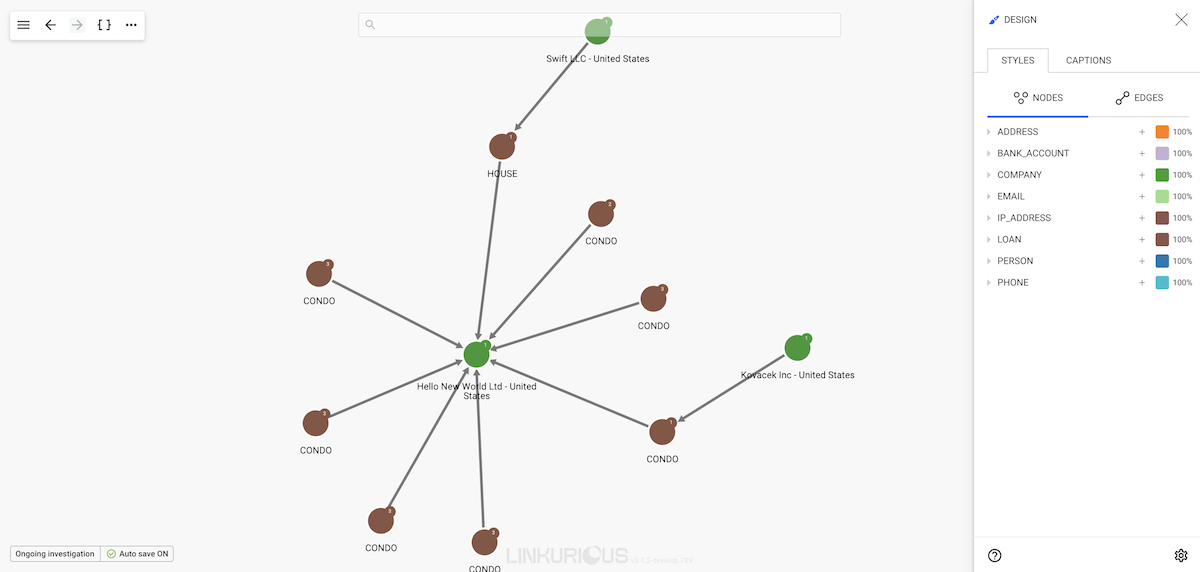
Let's open the Design panel on the right corner of the screen and hit the Styles tab.
We can see all the node categories and, clicking on them, we can see their properties and property values.
Clicking on the desire property we can see all the values from the nodes in the visualization; from here, in two steps, we can change the color based on a value:
![]()
blue), its hexadecimal color code (e.g. #0000FF)
or its rgb, rgba (e.g. rgb(0, 0, 255), rgba(0, 0, 255, 1))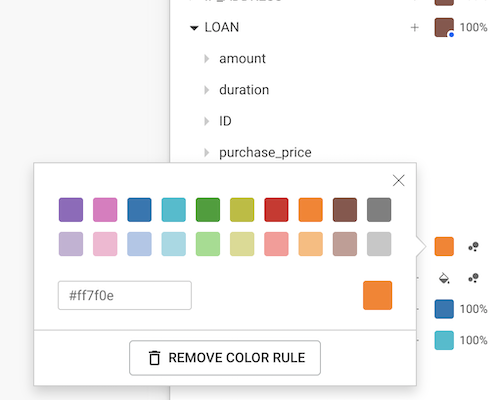
We repeat the process until we have a new color for each value:
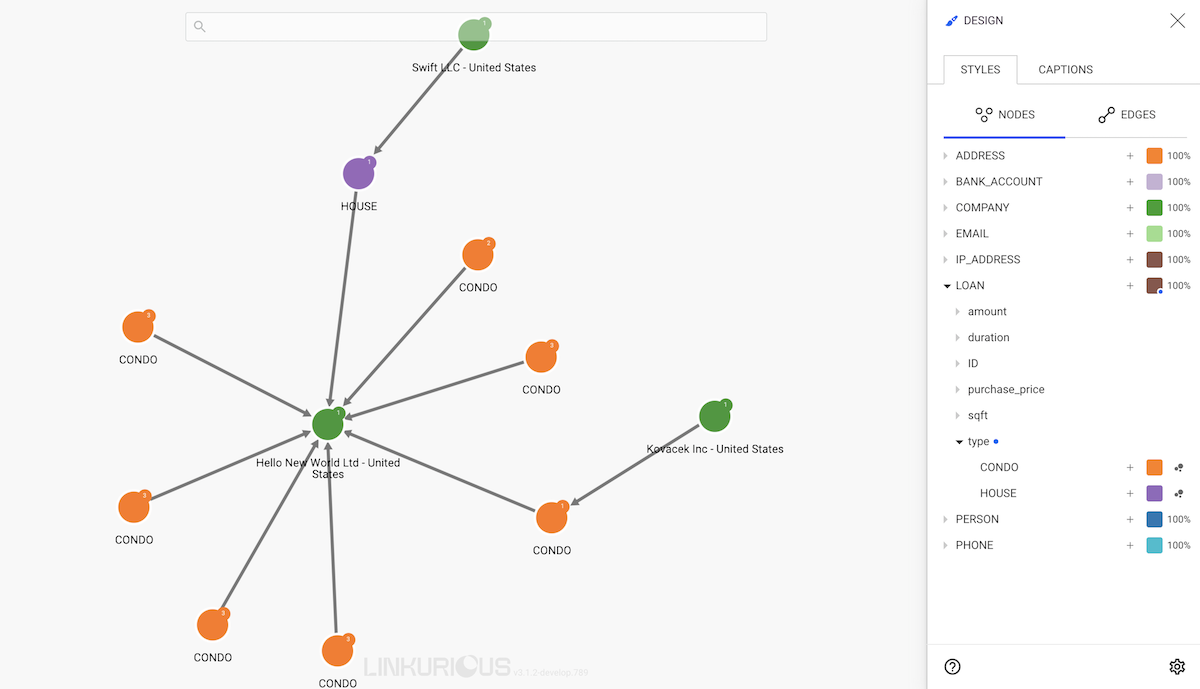
All the nodes that do not have the property or none of the values for which we applied a rule will remain with the color of their category.
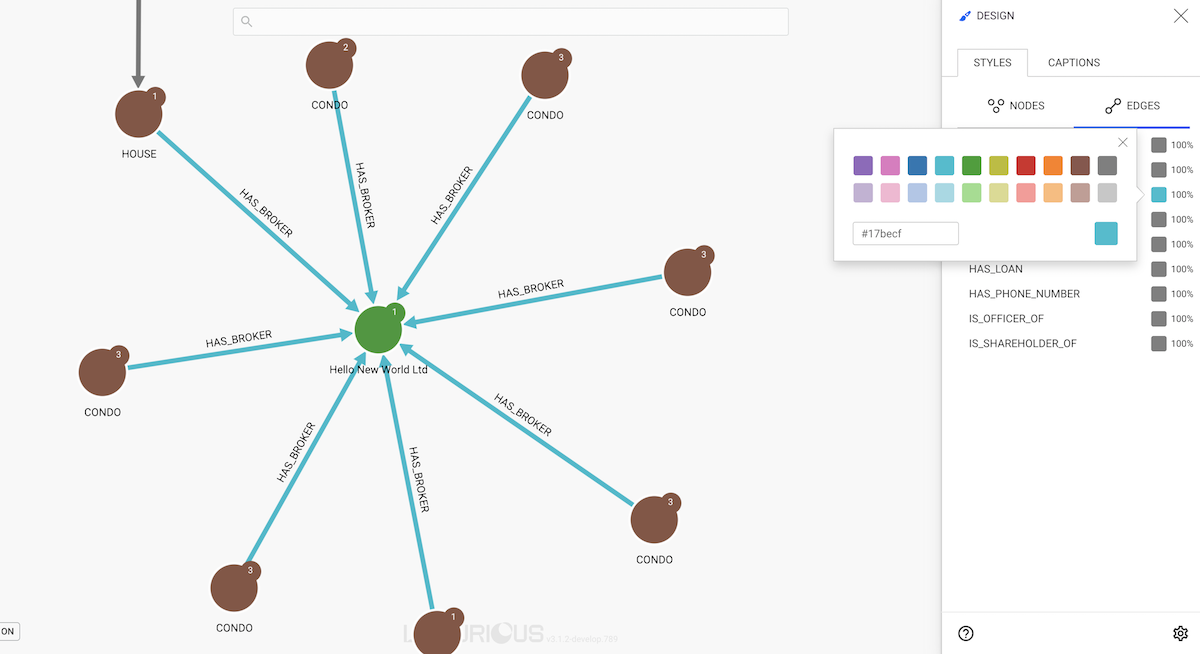
Coloring edges works exactly the same as coloring nodes.
We only need to click on the Edges tab of the Design panel and choose a given color based on the type of an edge or the value of an edge property:
By default, all the nodes have the same size.
It is possible to apply different sizes to nodes depending on their categories and/or property values. This makes it possible to differentiate nodes with a specific category and/or property.
There are two ways of applying a style for the size: Static and Dynamic:
Static sizing works similarly to the coloring functionality of Linkurious Enterprise.Dynamic sizing allows the analyst to visualize the graph using a scaling function, which helps in immediately distinguishing important values.⚠️ Note that when dynamic sizing is enabled, the layout is recomputed every time a visualization is opened (except if you have "incremental expand" enabled in layout user settings).
For example, the following visualization represents 140 companies that received funding from Acme Corp VC firm. Which companies received the biggest funding? Hard to know by simply looking at this graph:
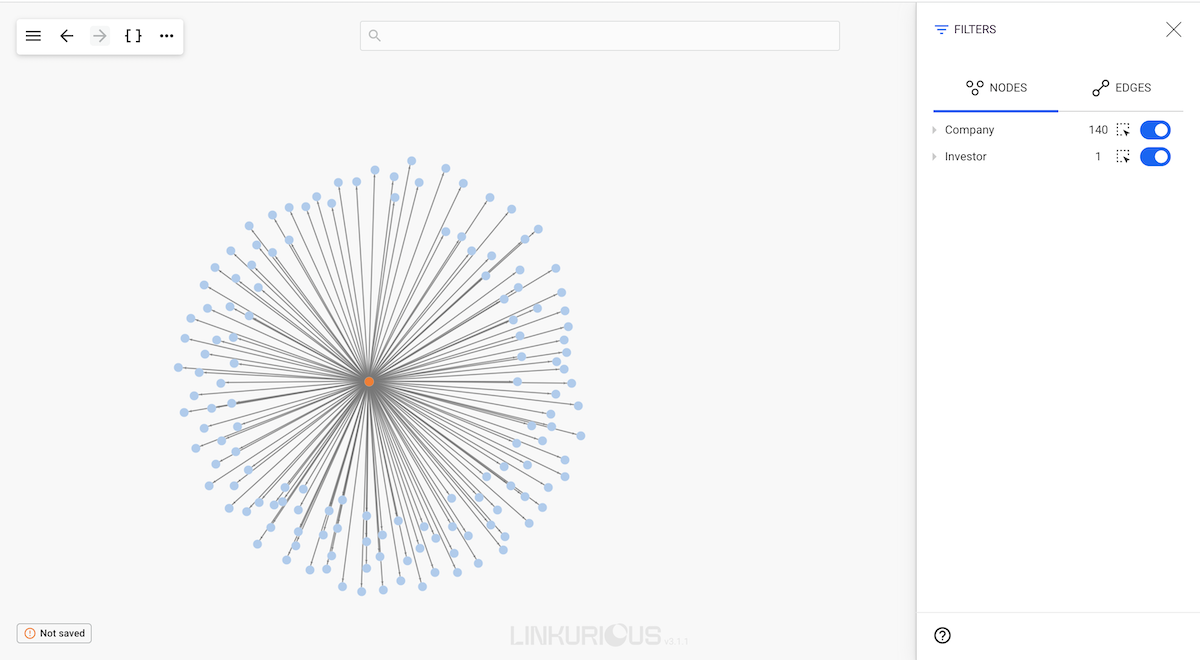
We are going to dynamically size the different companies according to their
funding_total property in order to visualize which ones are the most
successful. For that, let's use the Linear scale function.
Company.Linear option then select Logarithmic.funding_total property.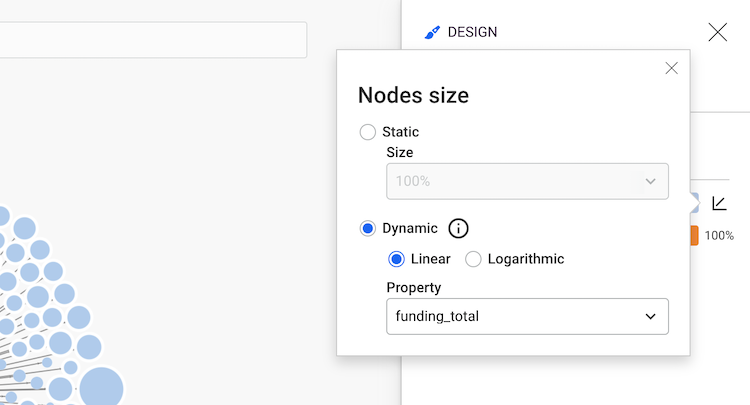
Now we can see that the size of the nodes with the category Company has changed – the larger the size of the node
is, the bigger the funding total value is.
We can quickly identify the most successful investment of investor "Acme Corp".
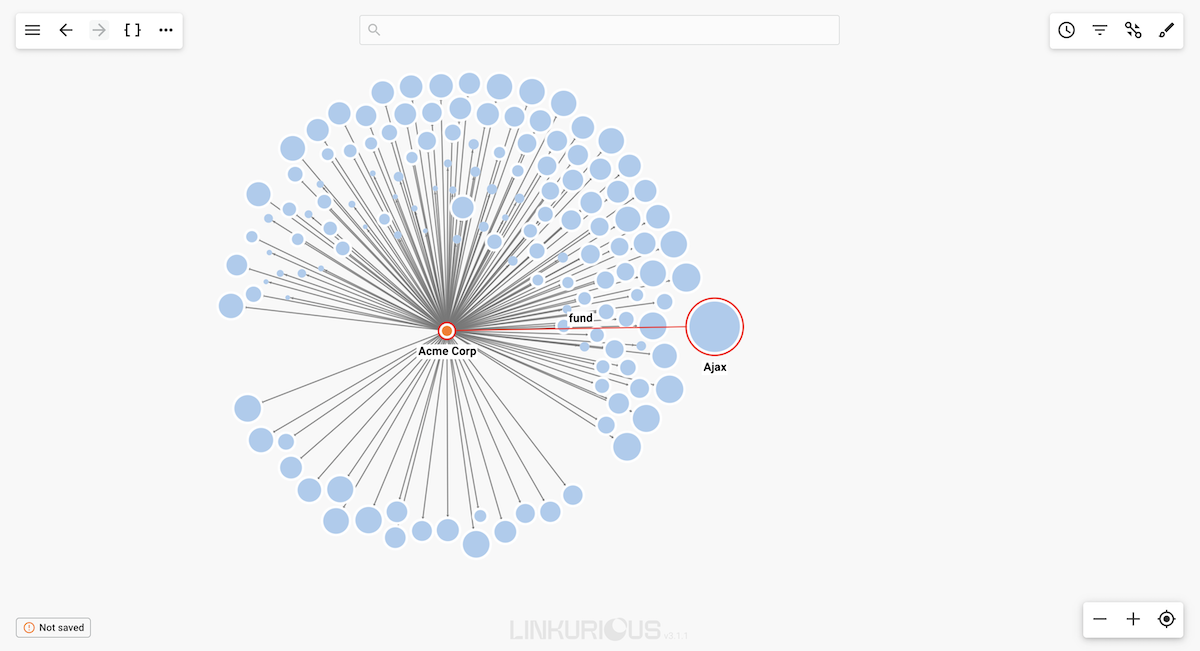
By default, all the edges have the same size (width).
It is possible to apply different sizes to edge width depending on their property values. This makes it easier to differentiate edges.
There are two ways of applying a style based on edge size: Static and Dynamic:
Static sizing works similarly to the coloring functionality of Linkurious Enterprise.Dynamic sizing allows the analyst to visualize the graph using a scaling function, which helps in immediately distinguishing important values.For example, the following visualization represents 14 bank accounts that have either sent to or received funds from the account in the center. Which accounts have sent or received the largest transfers? Hard to know by simply looking at this graph:

We are going to dynamically size the different bank transfers according to their
amount property in order to visualize the largest ones. For that, let's use the Linear scale function.
HAS_TRANSFERED.Dynamic option then select Linear.Amount property.
Now we can see that the size of the edges with the type HAS_TRANSFERED has changed – the larger the size of the edge, the bigger the amount transfered.

Linkurious Enterprise allows you to change the appearance of nodes by adding icons, letters or numbers.
We open the Design panel and choose the Styles and Nodes tab:
![]()
We can now see all the node categories and apply an Linkurious Enterprise icon, letter, number or custom icon to each one of them in three steps:
![]()
![]()
![]()
![]()
![]()
See how to add custom icons on our administrator manual. After adding the desired images they will be visible on the custom icons section and can be applied like a regular icon.
![]()
It is also possible to apply icons based on node property values.
In the example above, we have chosen 4 different icons to differentiate the nodes according to their category:
Cities are represented with a Home iconCompanies are represented with a Rocket iconInvestors are represented with a Diamond iconMarkets are represented with an Institution iconIn this chapter, we will learn how to filter the nodes and edges within a visualization according to their category/type or property values.
This technique will help you to focus on the relevant information in your graph and avoid information overload.
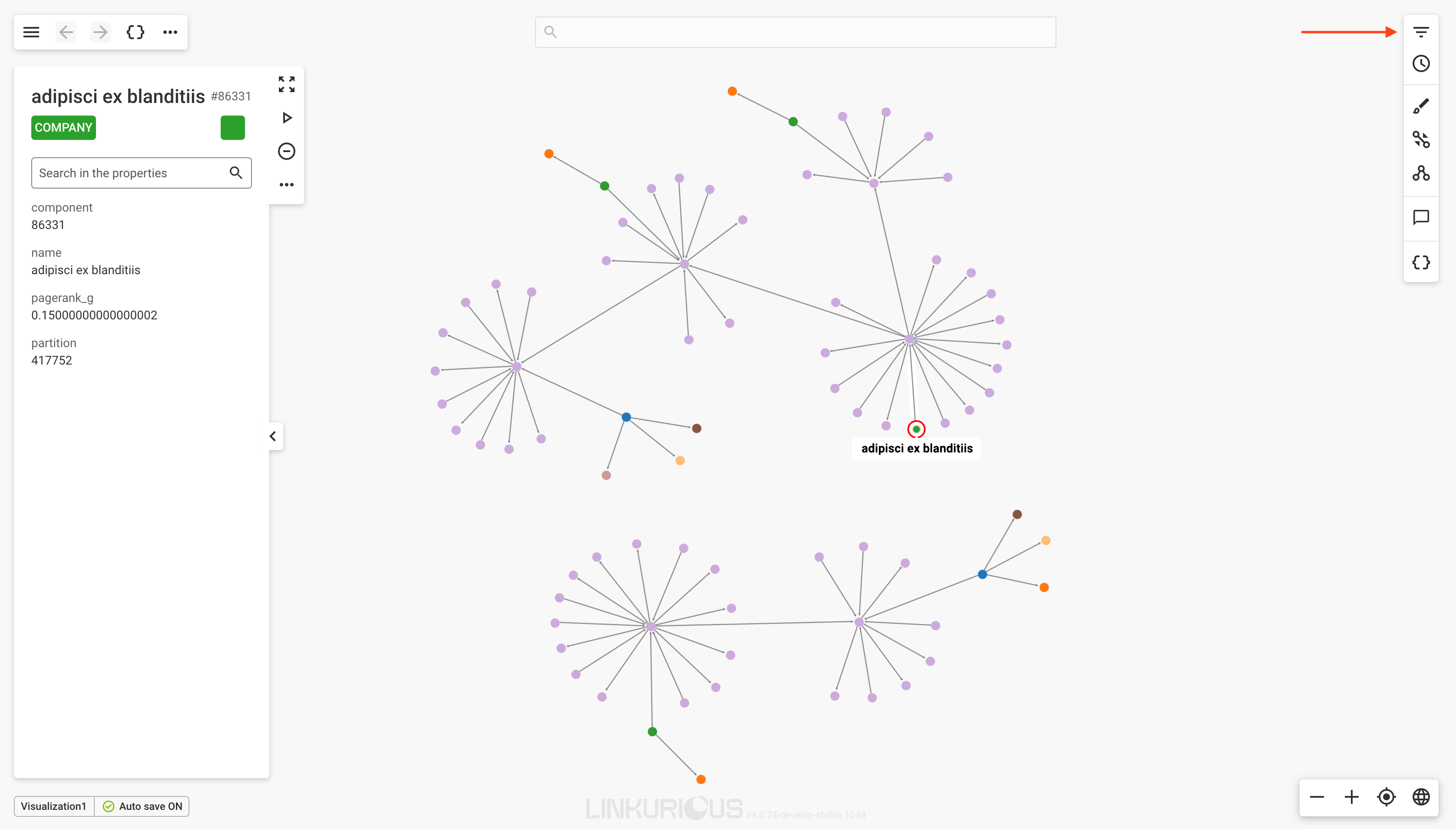
Open the Filter panel using the funnel icon in the top-right corner. It contains:
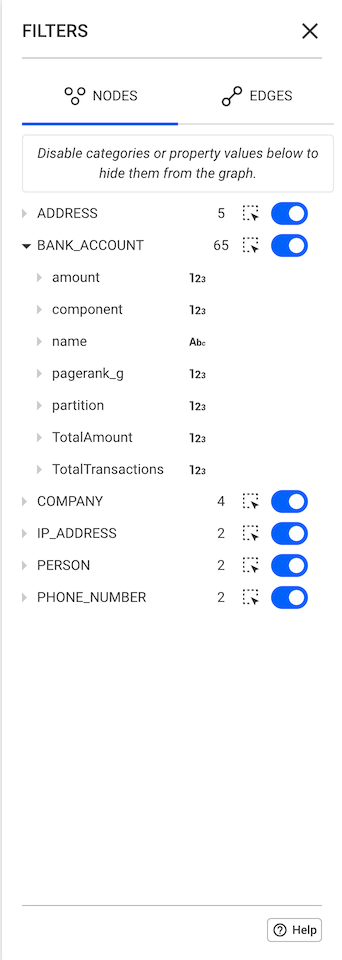
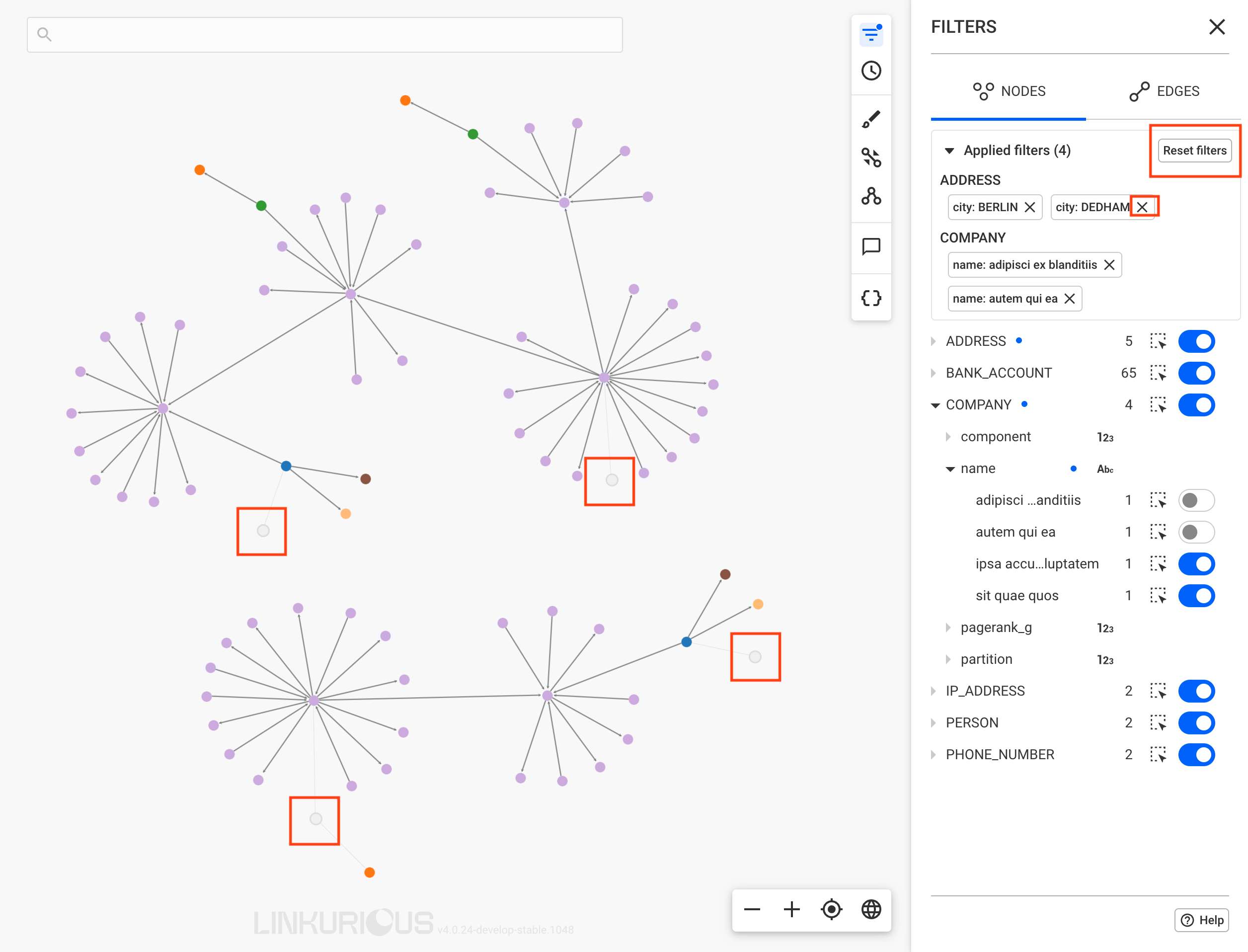
The type of a property is represented with the icon next to the property name.

There are 5 possible types:


If the property type was not set in the Schema, it was automatically detected by the visualization as a "String" or a "Number" property.
If it is not detected as the correct type, you may change it by clicking on the type icon.
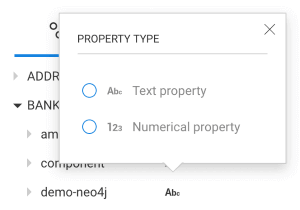
Click on the toggle button next to a category to hide all the nodes matching that category.
All "hidden" nodes are displayed in light grey in the visualization.
Click the toggle again to show those nodes again in the visualization.
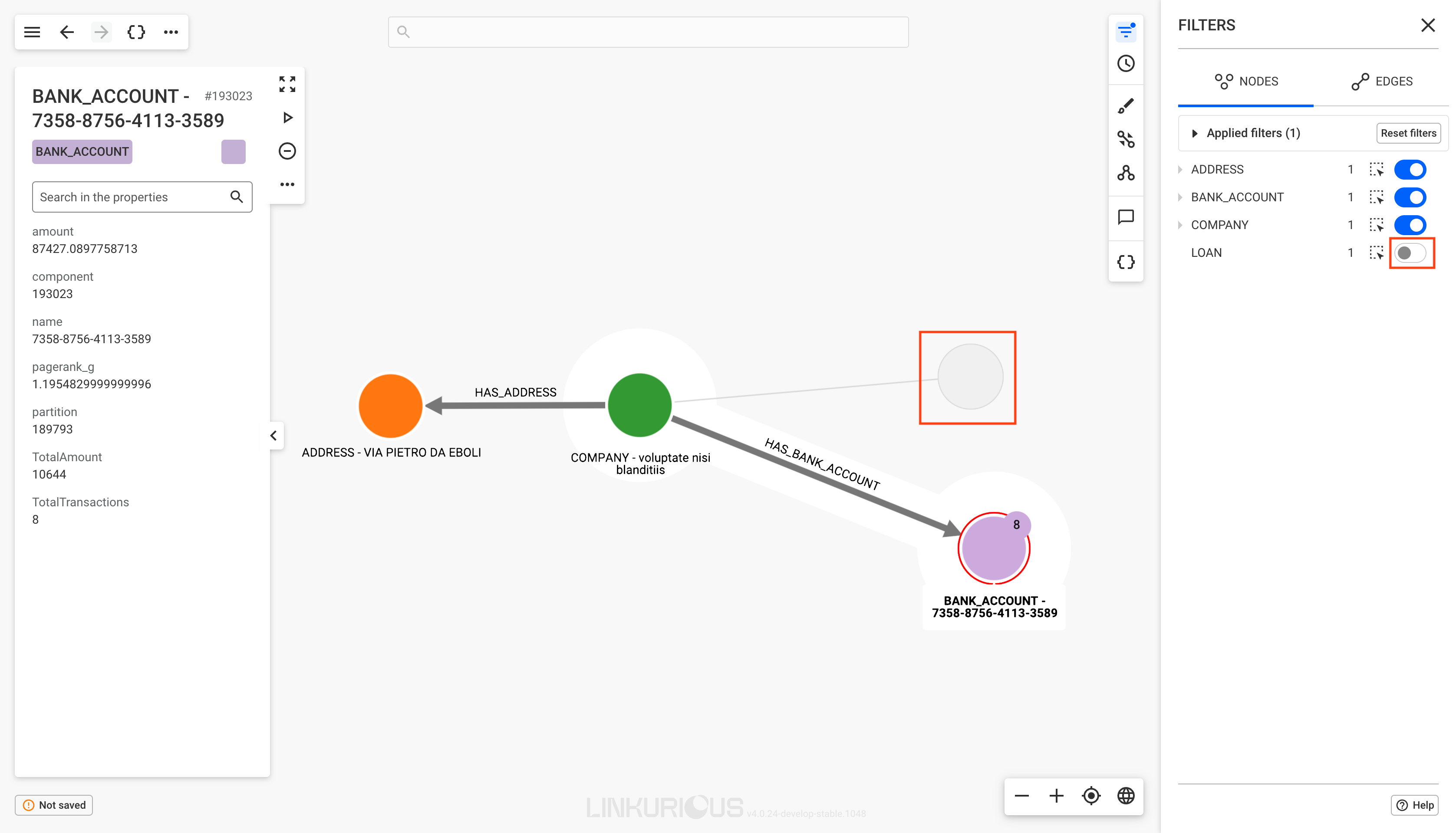
To filter on properties, unfold a property in the category tree. Filtering options depend on the property type.
For a String property, all values found in the visualization are listed. For each value:
Also a "Missing values" row is displayed when some nodes don't have that property.
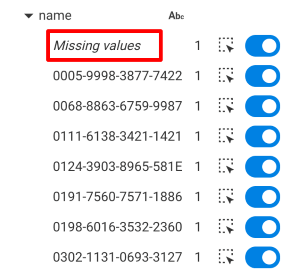
Enumerations accept only the authorized values declared in the Schema. All other values are considered as "invalid". Nodes that don't have the property are considered as "missing values".
True/False accept only "true" and "false" values. All other values are considered as "invalid". Nodes that don't have the property are considered as "missing values".
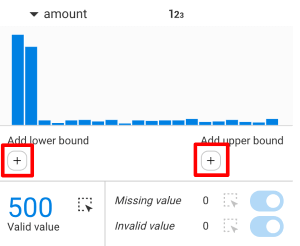
The chart displays all the property values taken by the nodes that hold a value for that property.
By clicking on the "+" icons, you can filter based on the property value by adding a lower bound and/or an upper bound:
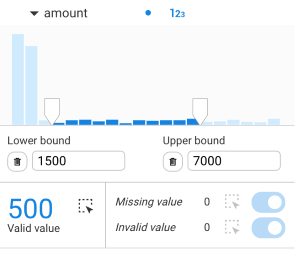
It is possible to:
Nodes in the visualization:
It is possible to hide all nodes that have a missing value or an invalid value. They are displayed by default.
Date and Datetime properties can only be filtered using the Timeline.

The Timeline is available if at least one property has been set as Date or Datetime property by the administrator in the schema.
The Timeline panel can be open through the "clock" icon in the upper right corner of the workspace.
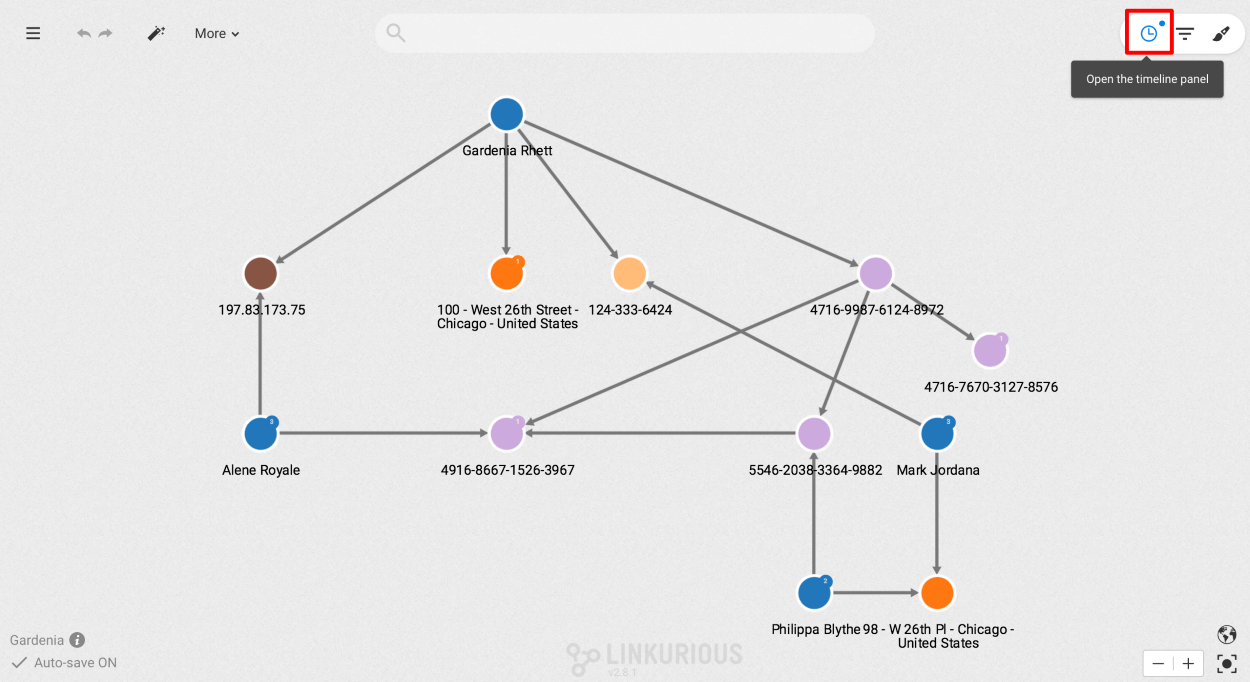
The Timeline displays the distribution of values of one or multiple properties at once.
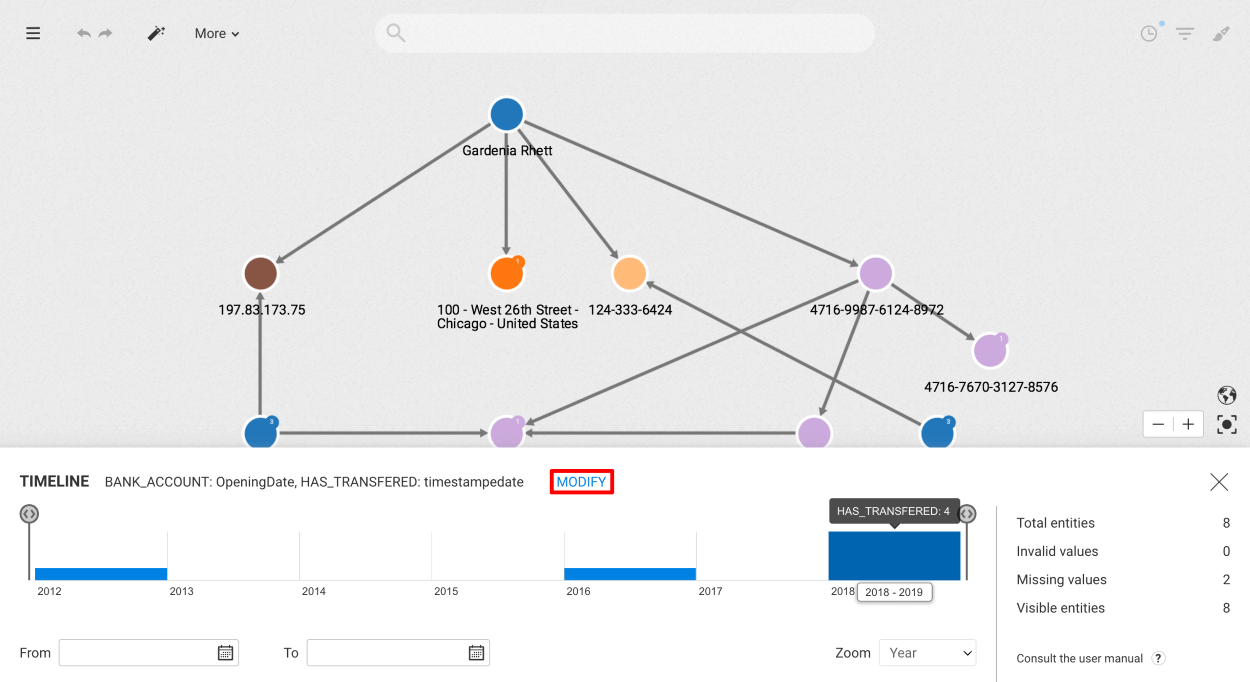
In the top left corner of the panel is displayed the list of properties being plotted in the Timeline. You may change the list of selected properties by clicking on the "Modify" button next to that list.
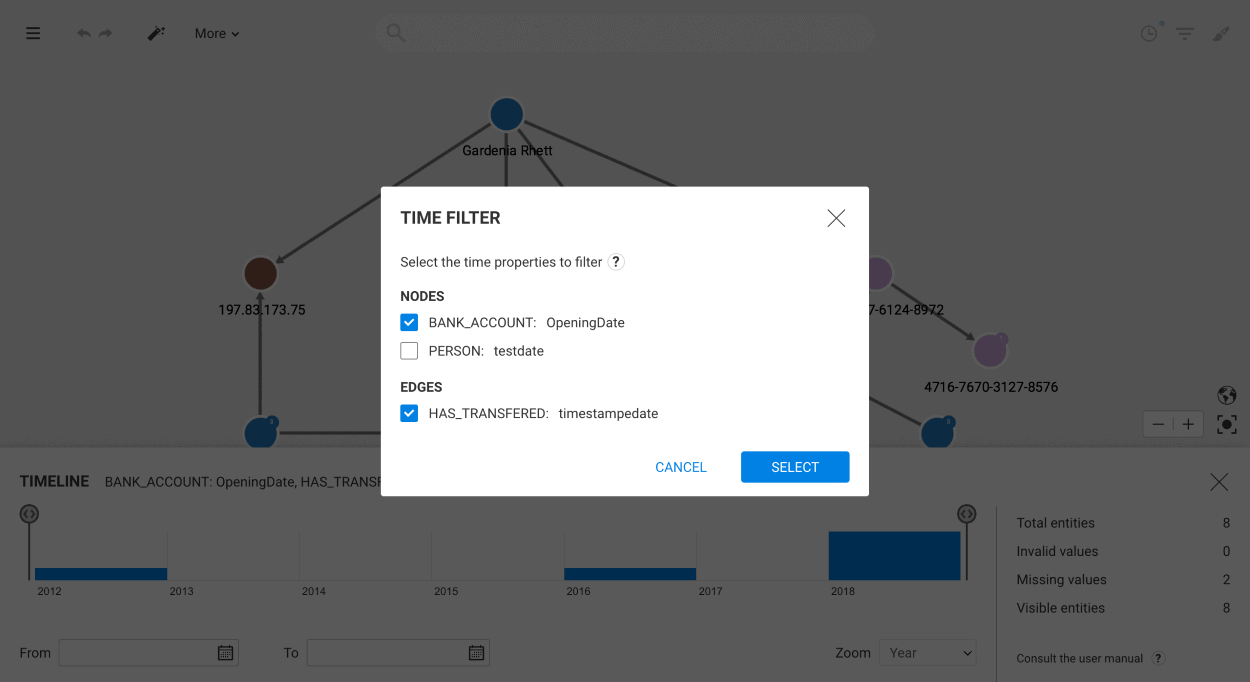
At the bottom right, the zoom level allows to change the step of the histogram.
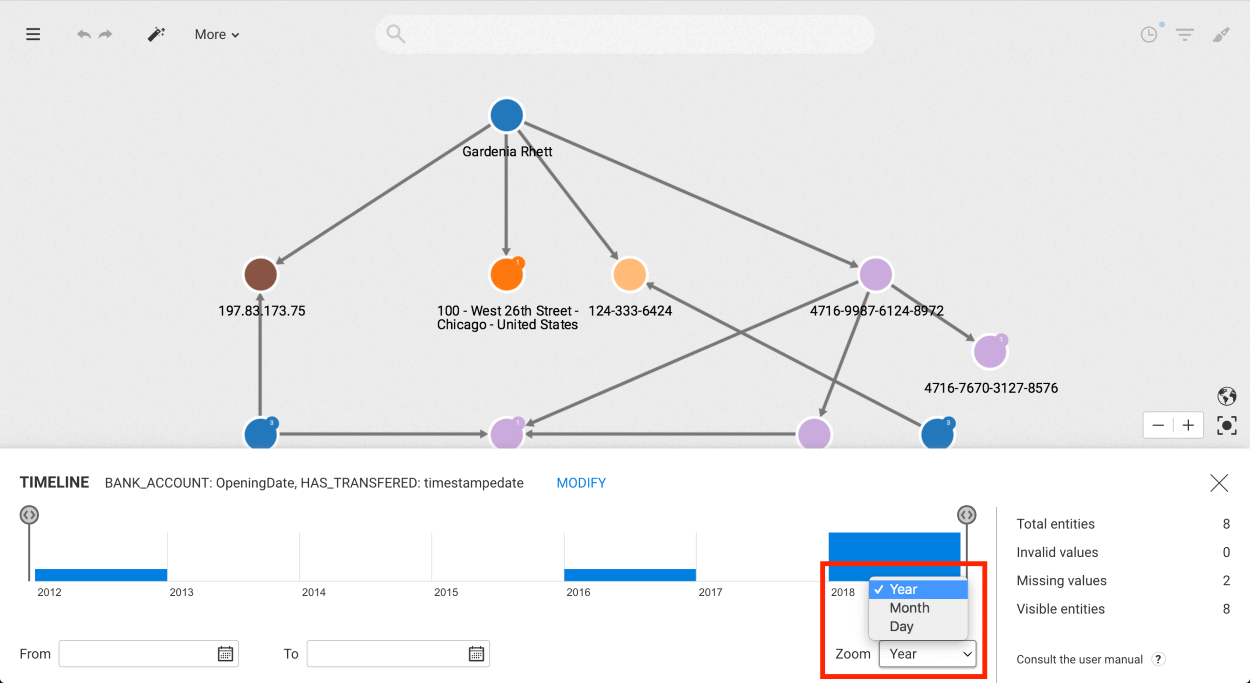
It is possible to filter nodes and edges holding the properties selected in the Timeline by adding a lower bound and/or upper bound using:
To remove a bound, clear the corresponding date picker.
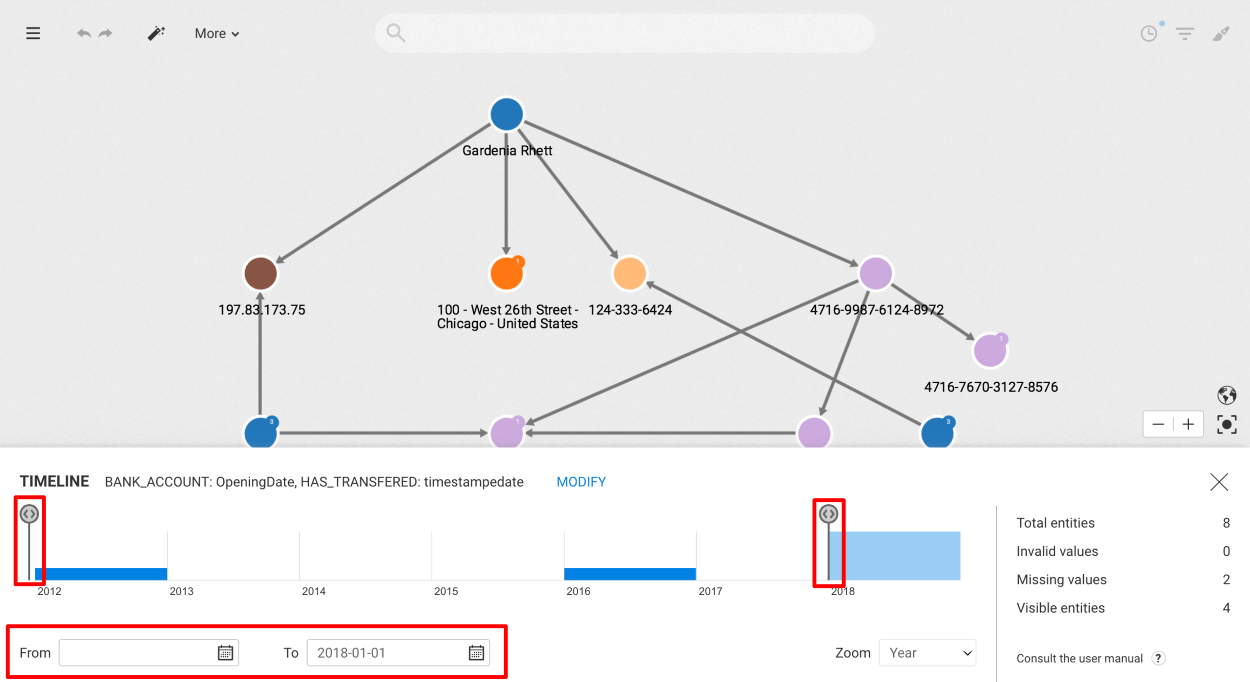
Some statistics are displayed on the right-hand side of the panel:
Some zoom levels might not be available depending on the date range among the data in your visualization: we can't display more than 100 000 steps. A few examples:
- Days will be disabled for dates spanning over about 274 years (dummy dates such as
9999-12-31will hit this limit)- Hours will be disabled for dates spanning over about 11 years
- Minutes will be disabled for dates spanning over about 2.5 months
- Seconds will be disabled for dates spanning over about 1 day
In this chapter, we will learn how to add comments on visualizations.
Comments help you share information with any other member of your team that has access to a visualization.
You can make your visualization available to other members of your team either via individual sharing or spaces.
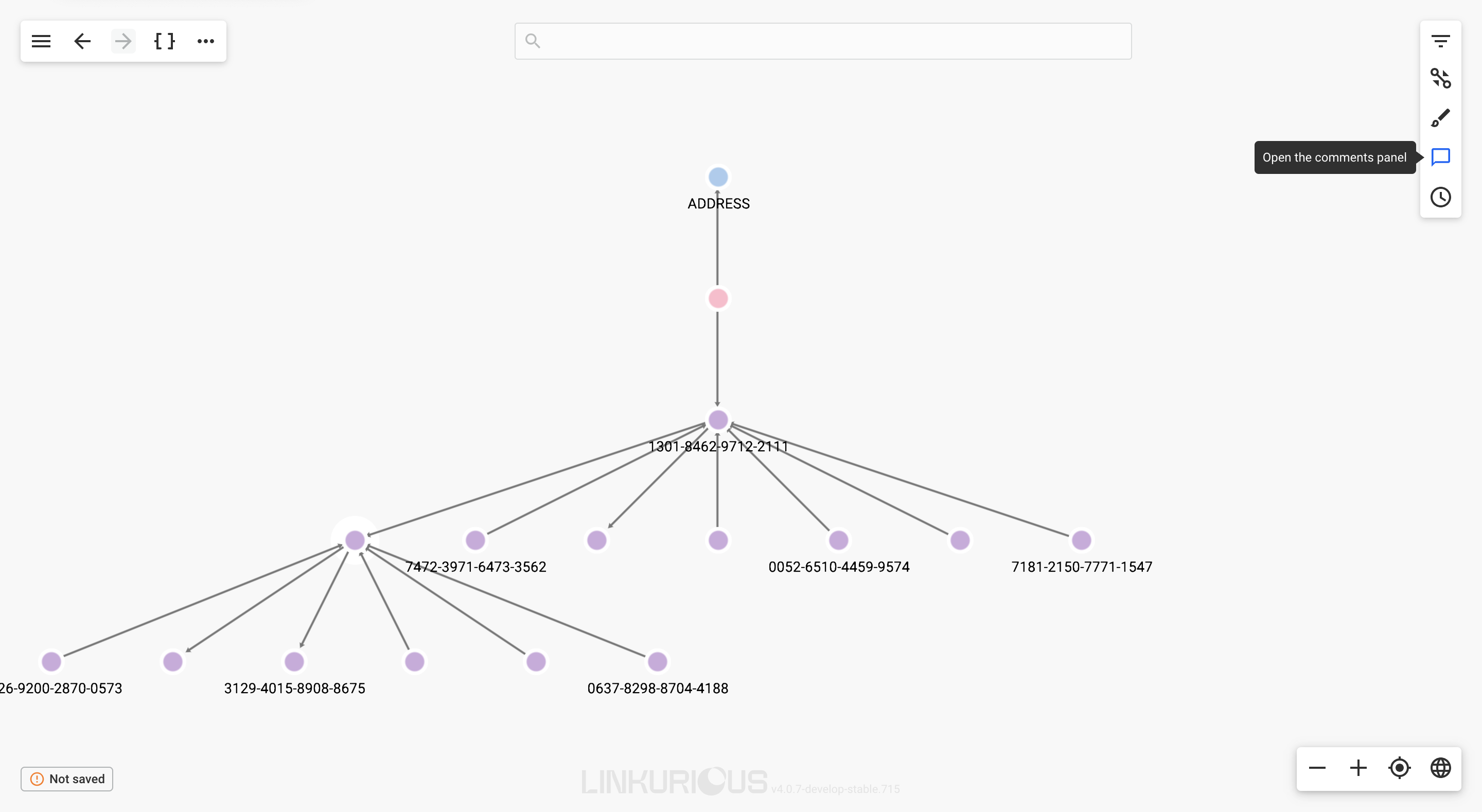
The comments panel is available on every visualization, to open it, click on the comment icon in the top right toolbar.
Note that the visualization should be saved before you can add a comment.
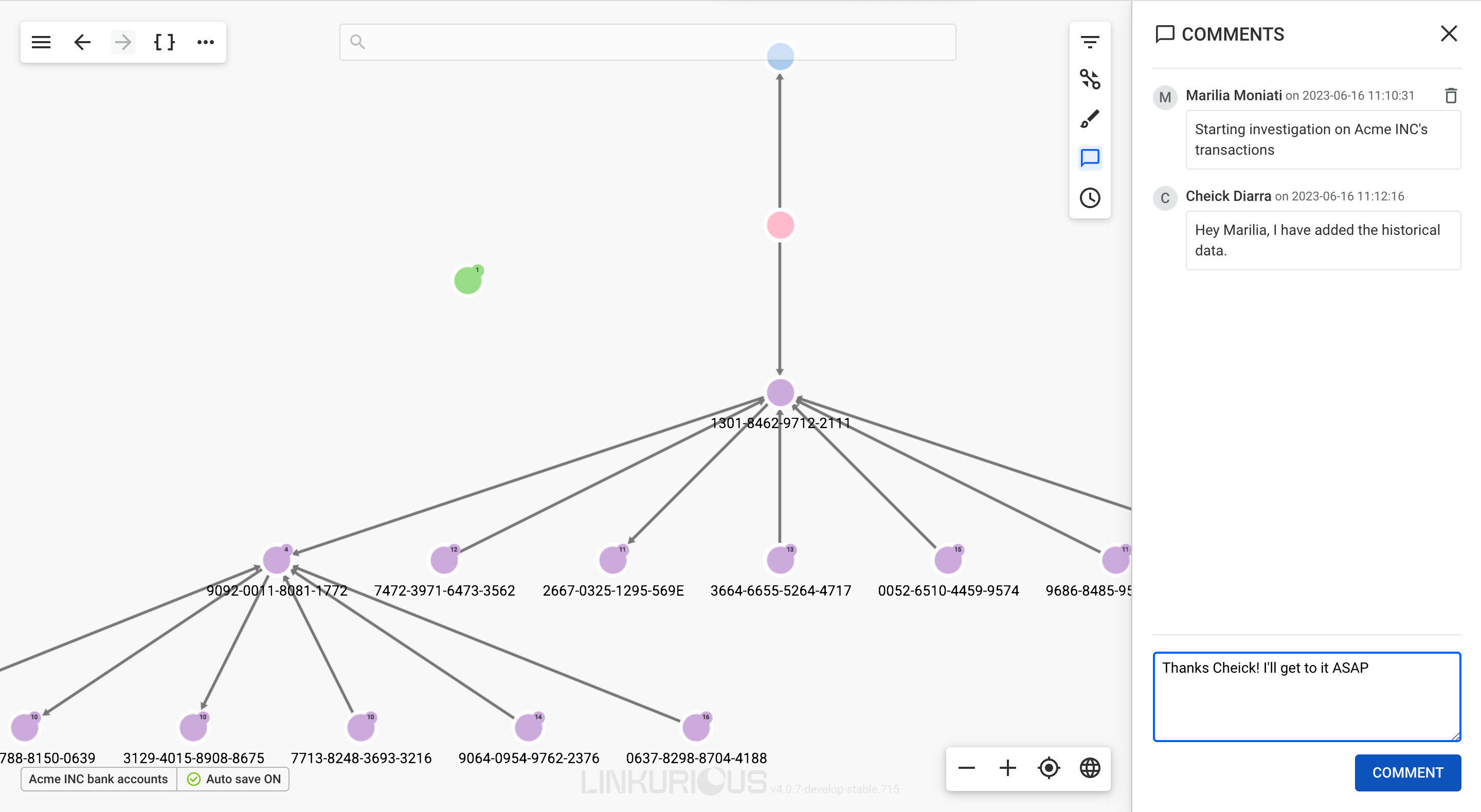
To save your comment, just click on the comment button after typing the information you want to share.
The comments are visible to anyone who has access to the visualization.
It is possible to delete your own comments. Only you are allowed to do so.
Comments added by users who have been deleted or no longer have access to the visualization will still be visible.
From the comments panel, you can mention any user who has access to the datasource, by typing @. After typing @, a list of suggested users according to what you type will appear. Users can be searched for by their email and username. When you have found the user you would like to mention, you can click on them or press enter. Mentioned users will then be notified via email.
In order to receive notifications, confirm with your admin that your email notifications are correctly configured.
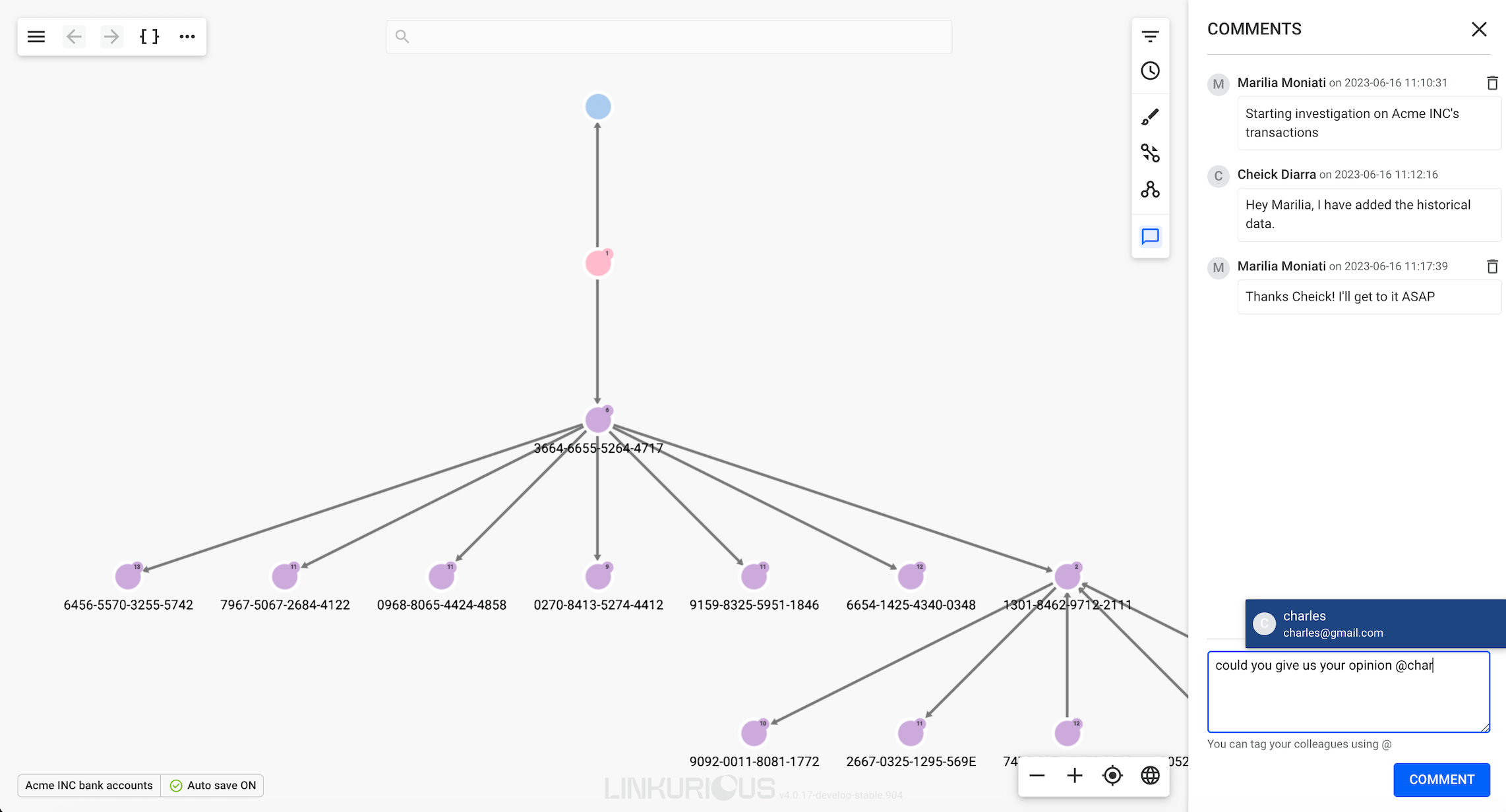
In this chapter, we will learn to edit, add and remove nodes or edges to our graph.
Important note :
The Linkurious Enterprise team recommends, as a best practice, not to go beyond the following :
- Maximum number of properties per node/edge : 300
- Maximum property key length : 500 chars
- Maximum property length : 200kB (200k characters)
Linkurious Enterprise best performances are not guaranteed beyond these limits.
Nodes are made of one (or multiple) categories, and a set of properties. Edges are made of one type, and a set of properties.
Properties are simple key-value pairs (e.g. name: "James", age: 31).
Node categories are used to tag a node (e.g. Company). Some graph databases (e.g. Neo4j) support multiple node categories.
Edge types are used to define the nature of an edge (e.g. FRIEND_OF).
Editing a node (resp. edge) allows for 3 kinds of actions:
Editing permissions are related to the configuration of Access Rights. If you are not able to edit a node (resp. an edge), see a specific property, or perform one of the above actions, please get in touch with your administrator.
It is a limitation of most graph databases that the type of an edge cannot be edited once the edge has been created.
If we select a node or an edge, we can edit it by right-clicking on it or clicking on
the More option in the Selection panel.
An Edit option is displayed in the context menu unless you are not authorized to edit that node (resp. edge).
Next, we click on Edit, which will open the node or edge edit modal.
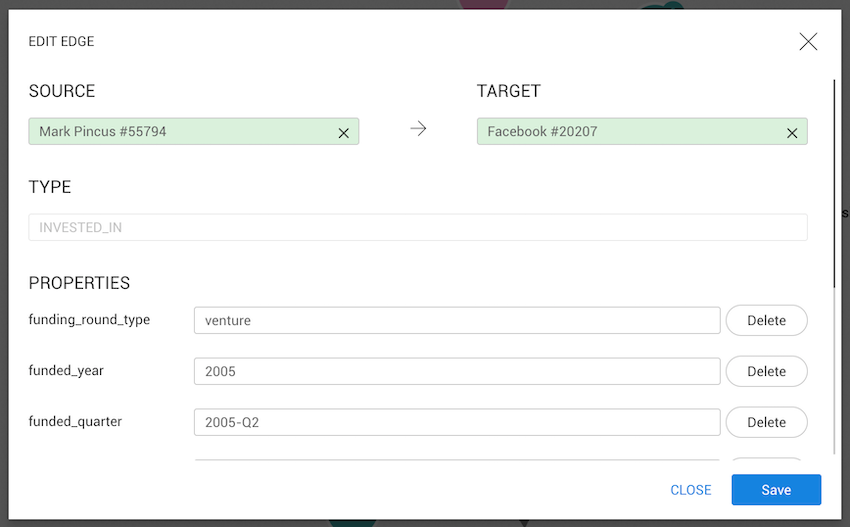
Only available on nodes
To add a category to a node we need to type the desired category. After typing the first character, categories already present in the database that match will be shown. The first option on the list is to create a new category with that name.
A node needs at least one category. It's impossible to create a node without one.
To select one category (even new), we need to click on the list. If the input changes
its color to green, your choice has been accepted. Next, we click on the Add button and, if we
want to save the changes, on the Save button.
To remove a category, we need to click on the cross on the right side of the category.
If a node only has one category, it cannot be removed.
These changes will only be saved after clicking on the Save button.
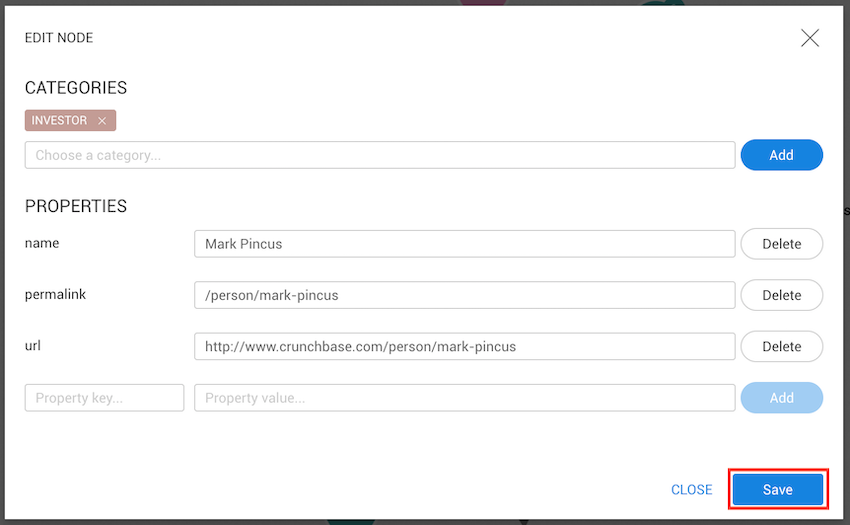
Note: edges can only have one type, therefore it is not possible to either add, remove or replace an edge type.
To edit an existing property, we only need to change its value. An administrator has the ability to configure the type of a property:
Text property can be edited through a text input.Number property can be edited through a number input.Enum (a limited list of authorized values) can be edited through a select list.Date or Date & time can be edited through a date picker.boolean) value can be edited through a toggle switch.If no type was configured for the property, it's considered as a Text property.
When editing a property, failure to input a value corresponding to the property type results in an error when trying to save.
Once a valid value is input, click on the Save button.
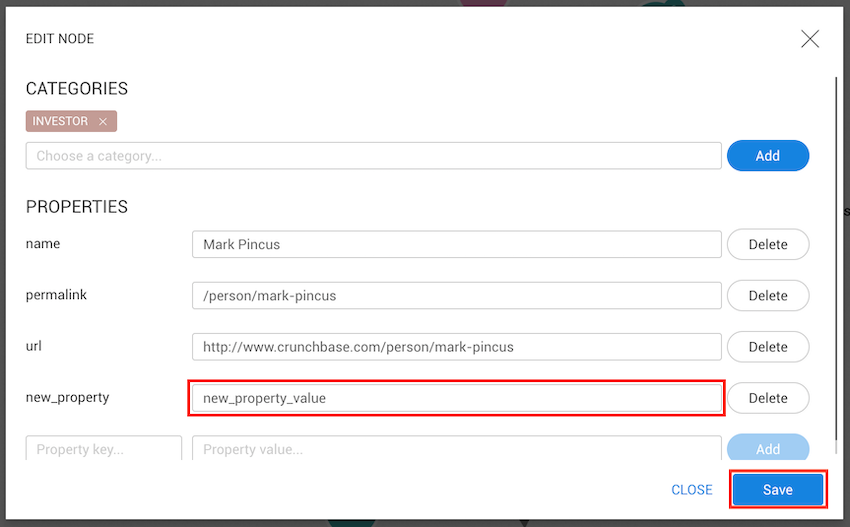
When the value saved in a property is inconsistent with the type declared by the administrator, a warning is displayed. In order to edit this value:
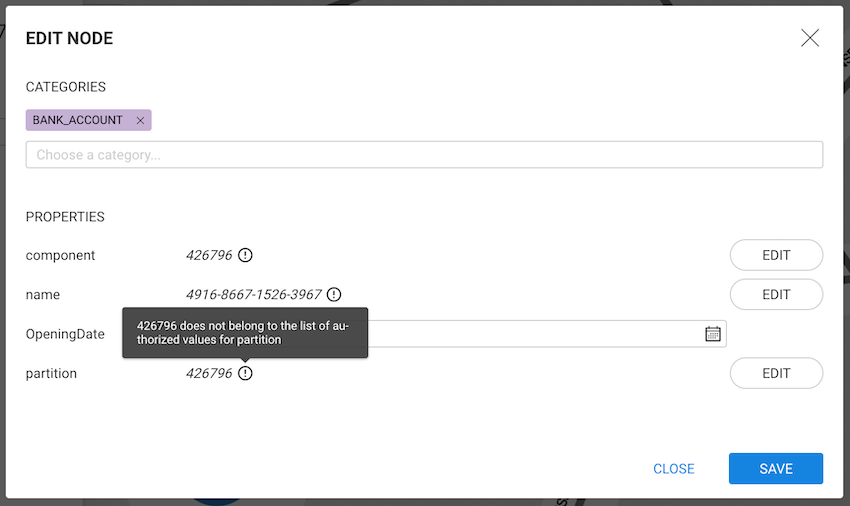
When nodes have multiple categories, properties might be configured so that a single property has 2 conflicting types. For example if the administrator configured:
In such as case, a warning is displayed and the user is not able to edit the property until the administrator resolves the conflict.
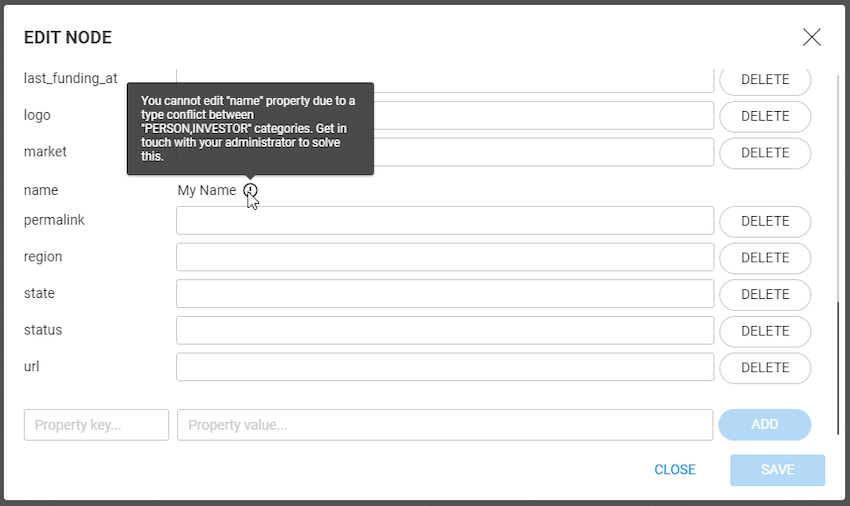
To add a new property, we need to fill in the name of the property and provide a value new_property,
and new_property_value, for example--and click on the Add button.
This property does not have a type yet and so will be considered to have the Text type.
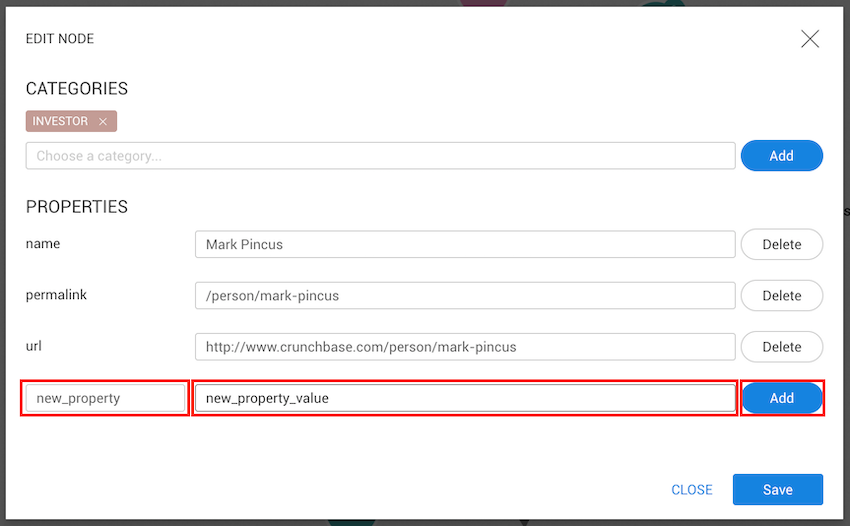
To remove a property, we only need to click on the Delete button. You cannot delete properties that have been marked as mandatory by an administrator. Mandatory properties have a red asterisk.
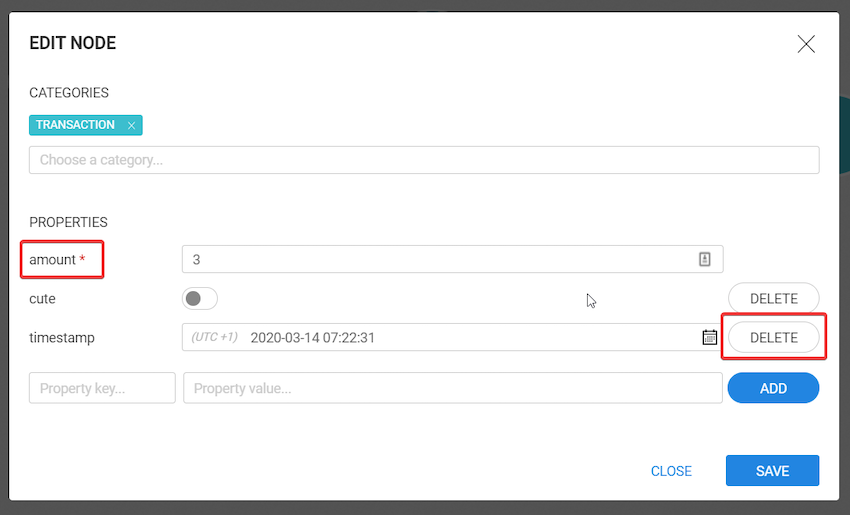
The edge edit modal works exactly the same way
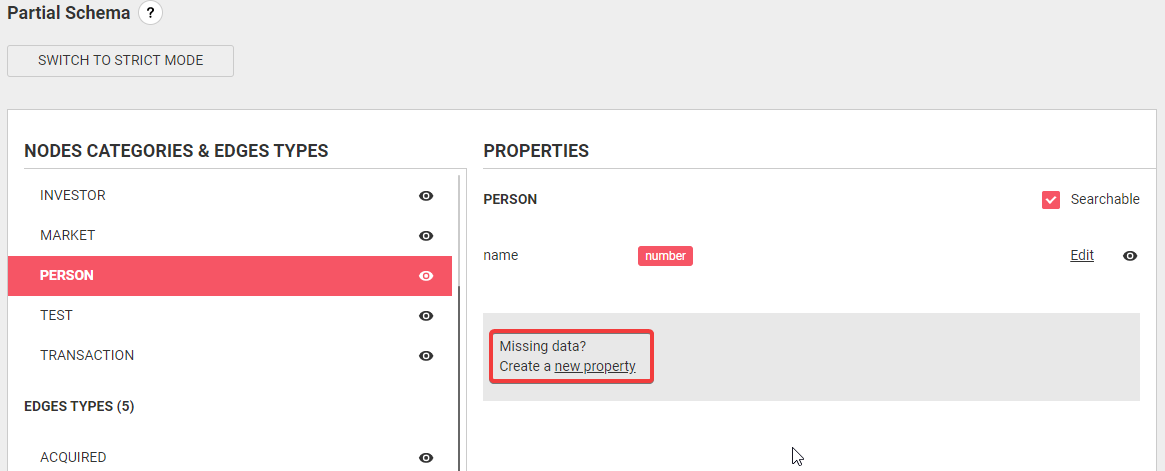
The easiest way to create a node or an edge is to right-click on the background or click on the
More option in the top menu.
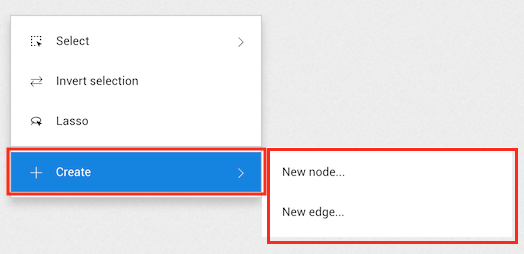
For edge creation, we can select one or two nodes and right-click on one of them to automatically use the selected nodes as source and target.
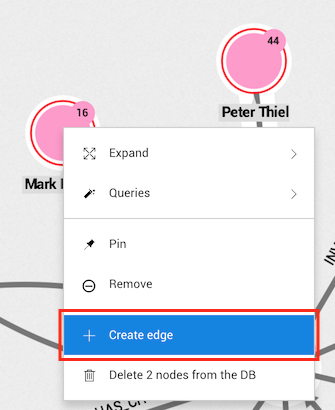
First we need to select or create a new category for the node using the marked input.
When we begin typing compa the category Company appears on the list along with the
option to create a new category named compa.
Let's select Company and click on the Add button. The company is then added, and since a category
is already present in the database, the properties list will be filled with those properties
already on Company nodes.
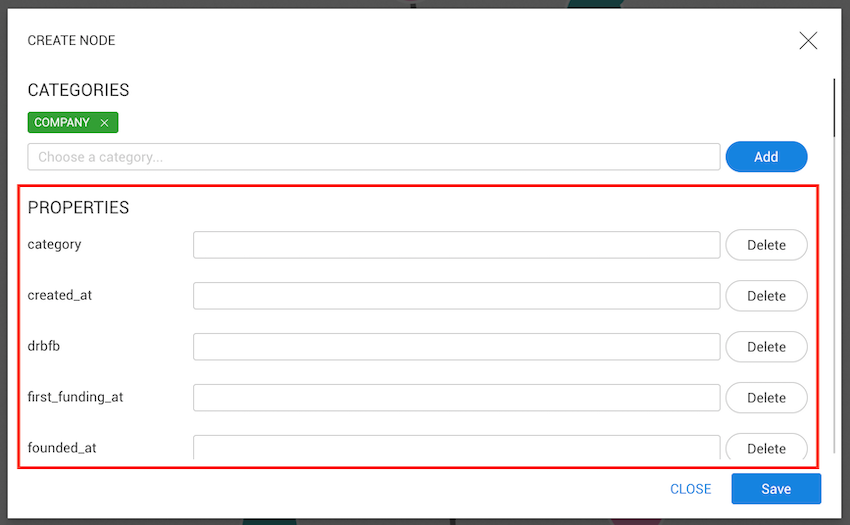
We can now fill the desired properties or create new ones at the end of the list and click the Save
button to add the new node to the visualization.
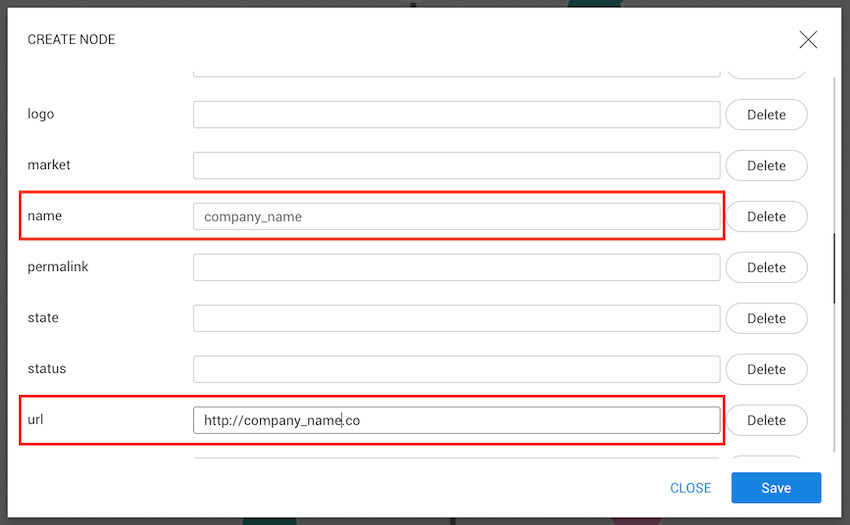
The new node is now saved and added with the inserted data. The node is also automatically selected.
The easiest way to create an edge between two nodes is to select them and then right-click on one
of them or on the More option in the selection panel.
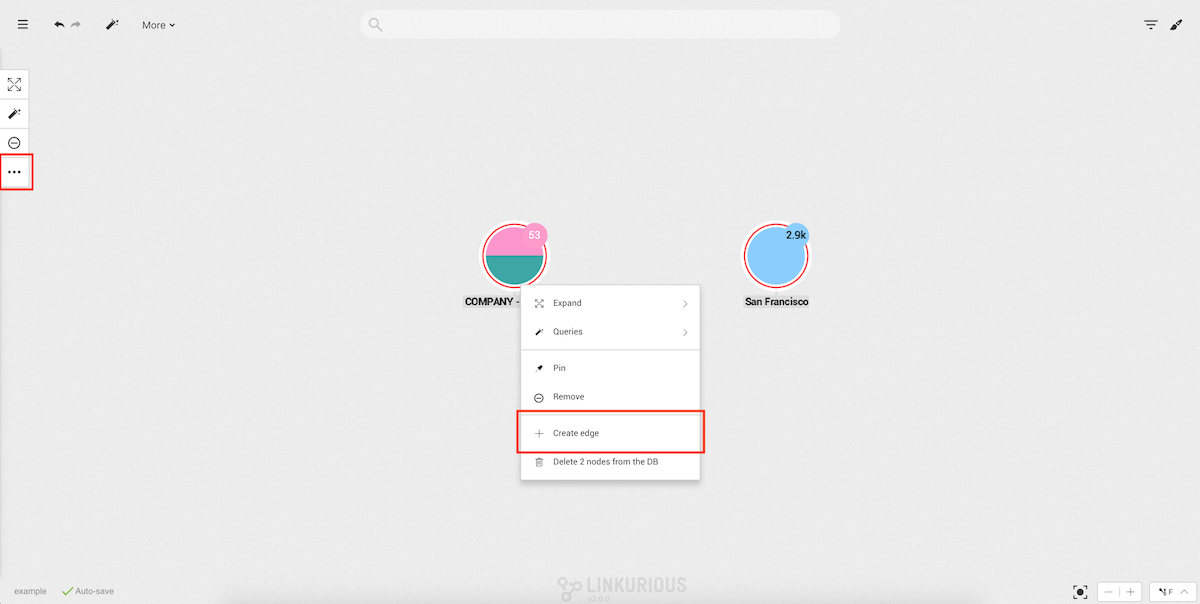
After clicking on Create Edge the edge creation modal will open with three important fields:
Type: the type of edge;Source: the source of the edge;Target: the destination of the edge.Since we already selected two nodes, the target and the source are automatically filled. Using the opposite arrows on top, it is possible to switch between source and target. If we open the edge creation modal without any node selected, we can use the source or target inputs to search for nodes present in the visualization.
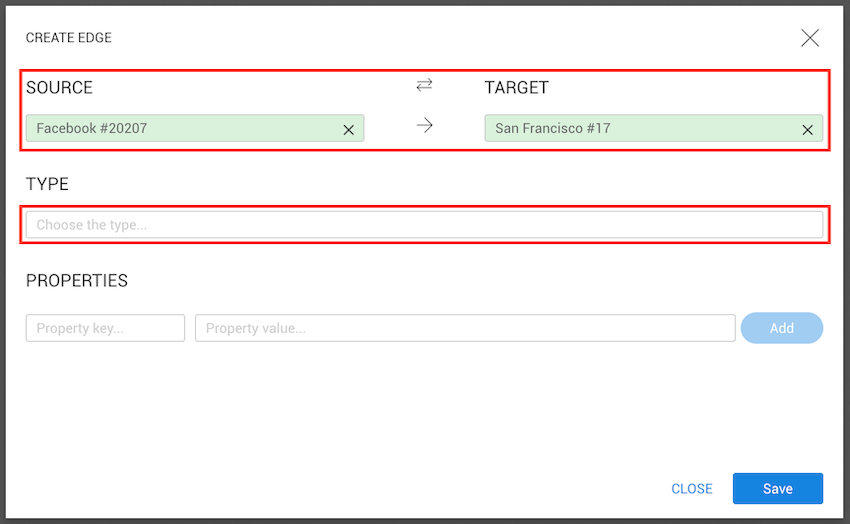
Next, we need to select a type for the edge (unlike with node creation, in edge creation
type is required). Clicking on the type input will show all types present in the database.
Let's select HAS_CITY
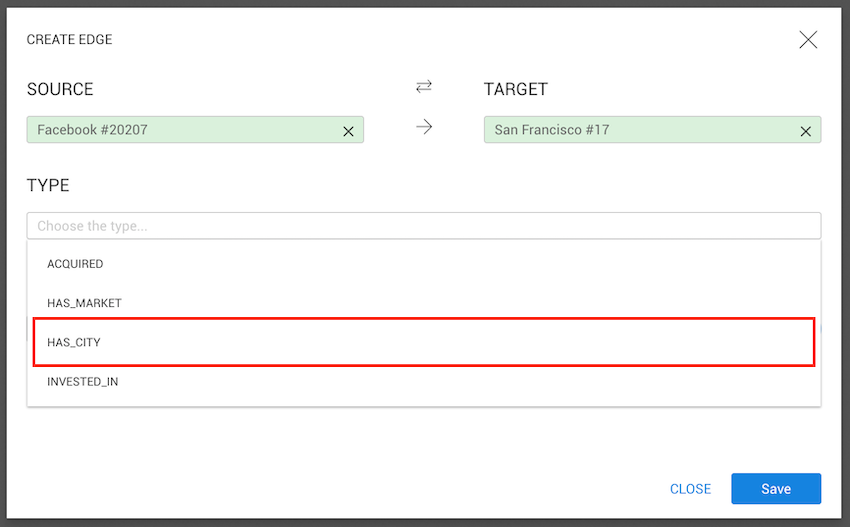
As with nodes, we can add as many properties as we want to an edge.
When we are done, we click on the Save button.
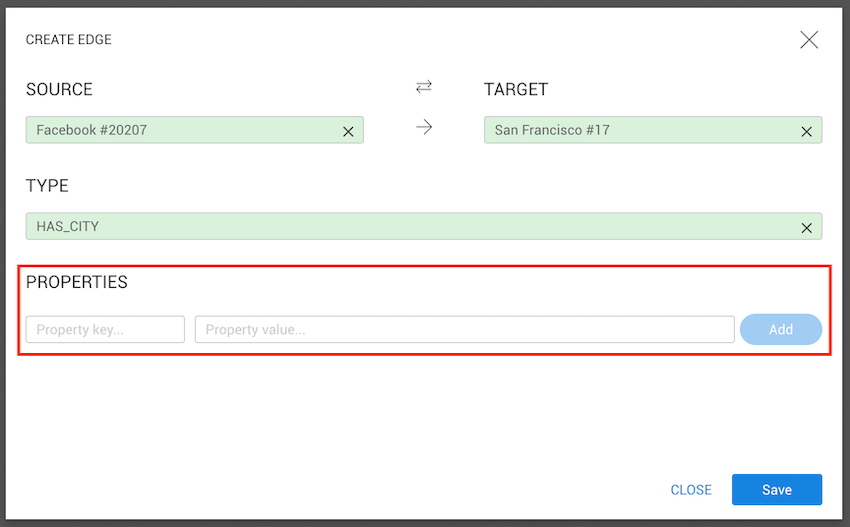
Finally, we can see in our graph our new edge:
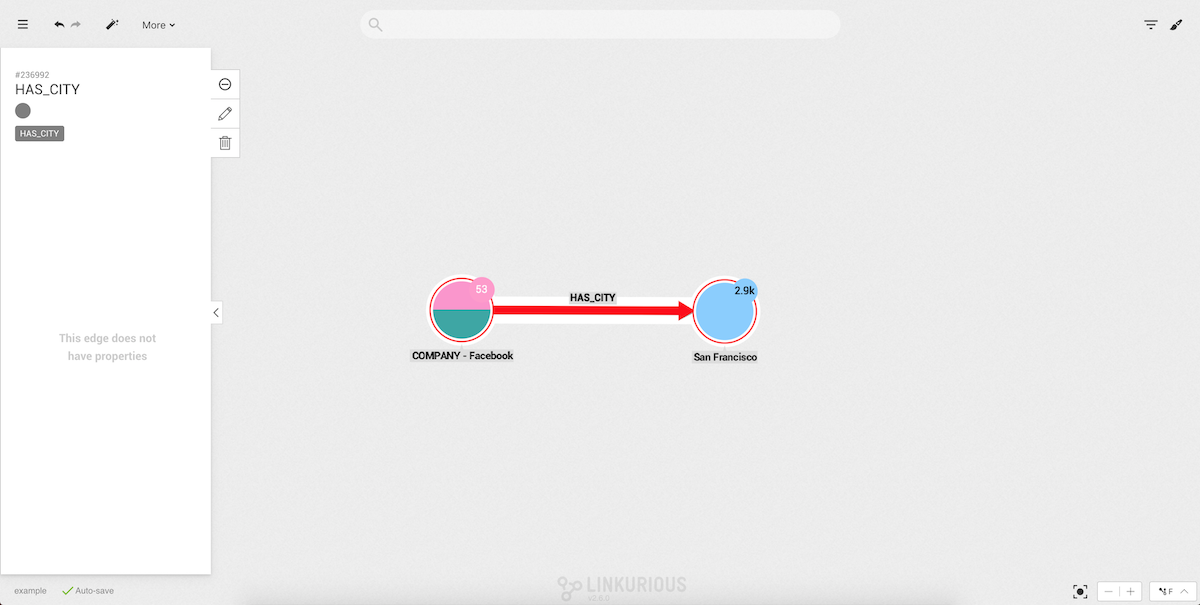
It is also possible to create a new edge without selecting any node by right-clicking on the background or by clicking the
Morebutton in the top menu.
If we want to delete one or more nodes from our database, we need to select the nodes we
want to delete and right-click on one of them or on the More option in the selection panel.
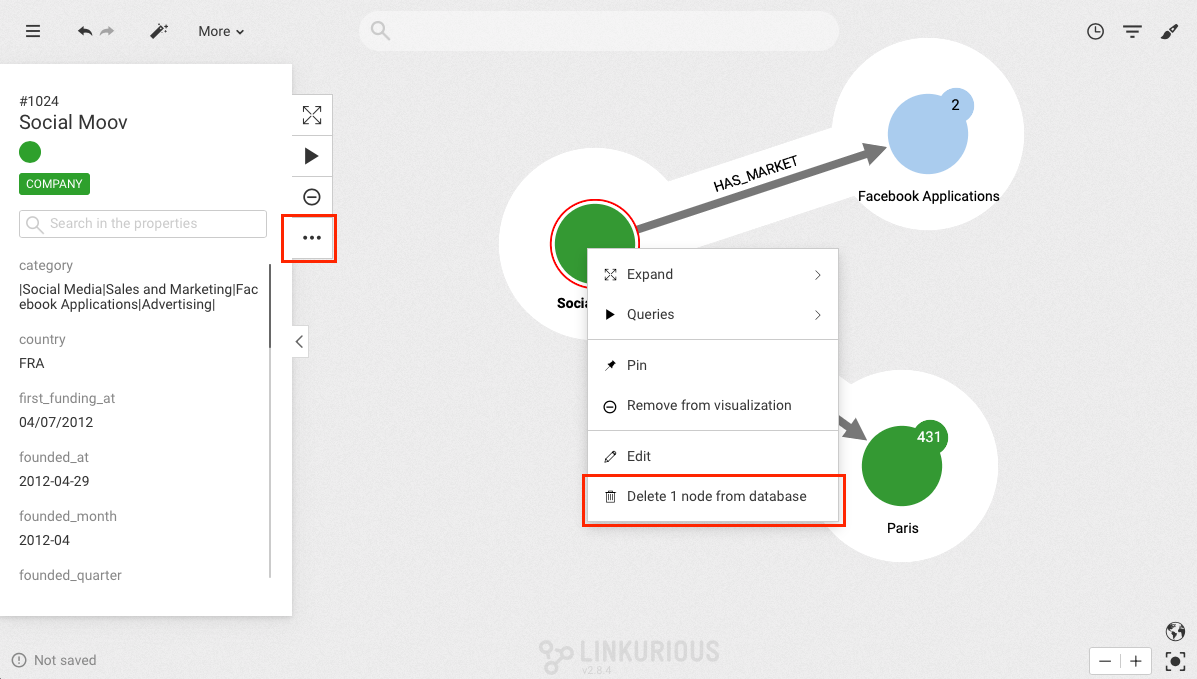
After clicking Delete x node(s) from database a confirmation modal will appear.
After clicking on Confirm, the node will be deleted from the database.
If we want to delete one or more edges from our database, we need to select the edges we
want to delete and right-click on one of them or on the Delete option in the selection panel.
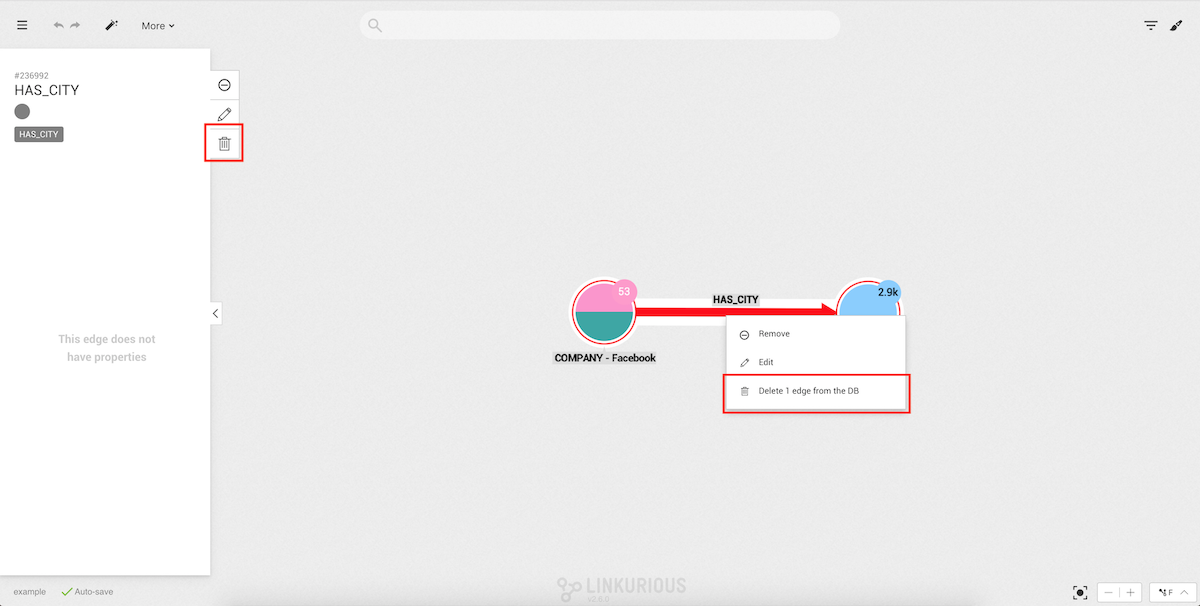
After clicking Delete x edge(s) from database a confirmation modal will appear.
After clicking on Confirm, the edge will be deleted from the database.
In this chapter, we will learn how to display graph data on a geographic map.
Nodes must contain geographic coordinates as properties. Latitude and longitude data must be expressed in decimal degrees (e.g. "38.8897,-77.0089") as available in many geographic information systems (GIS).
The Administrator should configure which property is the latitude property, and which property is the longitude property of the nodes of the data-source. Without configuration, Linkurious Enterprise will try to use properties called "latitude" or "lat", and "longitude", "long" or "lng".
When geographic coordinates exist in a node of the visualization, we can switch to the geo mode.
The Geo mode switch is available in the lower righthand corner of the Workspace. We can enable and disable the geo mode at will to switch between the standard "network" view and the geographic view.
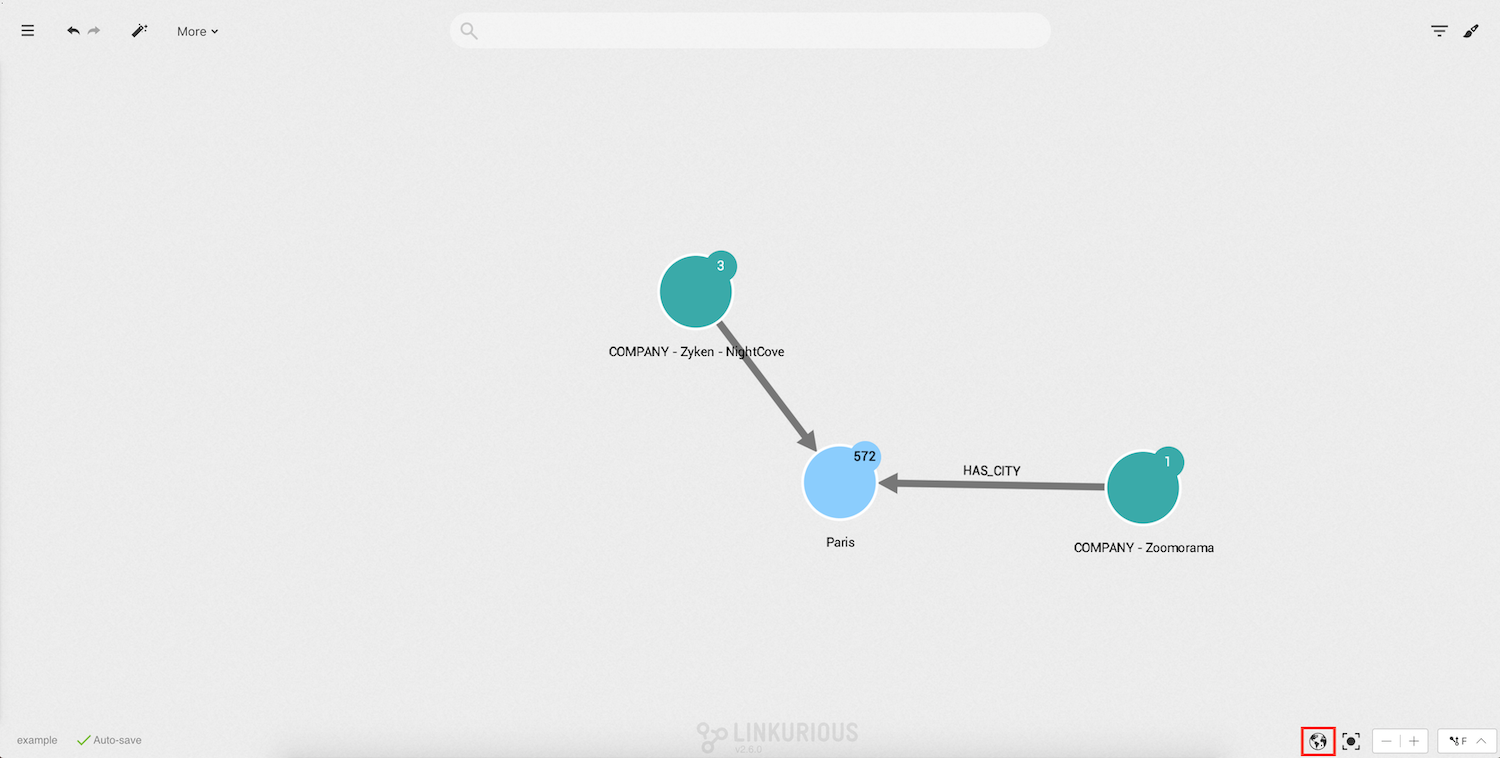
Click on it to display the geographical map. Nodes are positioned on the map according to their geographic coordinates. Other nodes present in the visualization can be hidden by the "geo coordinates" filter.
Linkurious Enterprise includes some different layers that can be selected by clicking on the layer button in the lower
righthand corner of the screen.
We can zoom in and out, drag nodes on the map to improve readability, select nodes and edges, etc. If we want to move the nodes to their original position we can always reset their coordinates by right-clicking on the background:
Finally, we can publish an interactive widget from Workspace menu > Publish with the geographical layers.
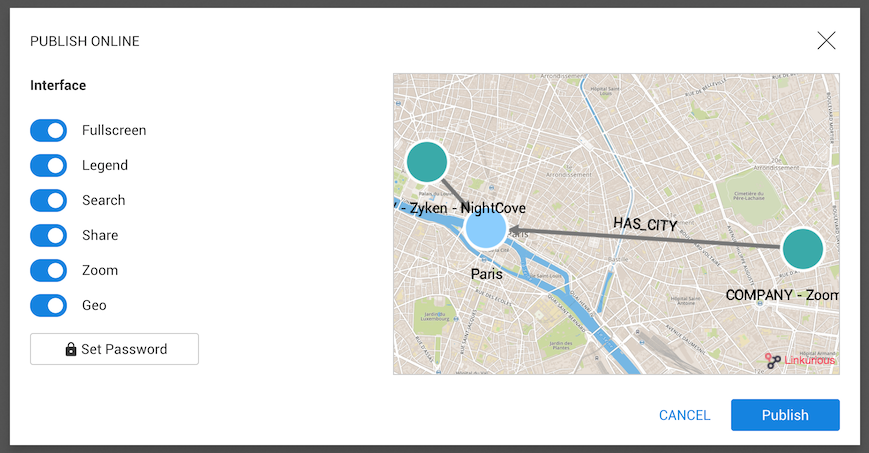
This chapter focuses on the lifecycle and workflow of alerts. Here, information on how to set up, edit and navigate alerts can be found. Moreover, a lexicon with useful terms around the feature can be accessed.
 Automated detection of patterns in the graph database
Automated detection of patterns in the graph database
The next section, is a step-by-step guide on how to create alerts.
In order to create an alert, navigate to the Alerts section from the top navigation menu and then click on the Alerts Dashboard button.
 The alerts dashboard, where you can manage the different alerts created.
The alerts dashboard, where you can manage the different alerts created.
When on the alerts' dashboard, simply click on the Create an alert button which will re-direct you to the alert creation form page.
 The alert creation form.
The alert creation form.
Only users with the right to create alerts can access the form.
Alerts have general settings that concern their frequency, sharing options and more. These settings are spread on the top and bottom of the creation page.
On the top of the page, users are asked to enter the alert's name and description. The alert name is a mandatory field. The alert description is optional and can be used to give context on the alert's usability and purpose. The description of the alert can be viewed on the Unified case list by hovering over the alert title or opening the case preview where analysts will be investigating their cases.
By default the alert, when enabled, will run every hour. It is possible though to adapt the frequency based on specific needs (for example the frequency of database updates).
We advise you to not go below the hourly frequency if your alert is too complex.
If the sharing options of an alert are not altered, it is only visible to its creators and Admin users. In order to make it visible to users,sharing options should be activated. This can be done by clicking on the Share alert toggle. Users are then asked to choose between sharing the alert with all users or one or more groups that have access to the datasource.
If an alert is shared via one of the above options, only users with "process alerts" or “create and process” rights will access it.
Finally, an alert will run only when activated. This can be achieved by clicking on the Enable alert toggle.
As creating an alert can be a complex process, users may have to test patterns and queries using the Linkurious Enterprise query system or consult investigators to ensure the consistency of the data returned. Therefore, there is the possibility to save an alert at any step during its creation.
Once the alert title is complete, the alert can be saved by clicking on the Save button (for your alert to run properly the target and at least one model should be correctly filled in). In case of pending errors within the alert (either on one of the models or on the attributes query), a window will exhibit the detected errors/warnings. There will exist the possibility to return to the alert creation page or continue with saving the alert.
In order for an alert to function properly, both for models and case attributes, the below criteria must be met:
When the alert is enabled in the setting, the alert can be saved and run by clicking the Save and Run button.
Running an alert can be a heavy process. Depending on the alerts' properties, users could notice the interface slowing down for a few minutes while an alert is running. We recommend scheduling the run of alerts in production outside of business hours to allow for a seamless experience.
Subsequently, many parameters can affect the performance of alerts. In order to optimise the performance of your alerts, we recommend taking into consideration the following points:
Models and preprocessing steps: The number and complexity of models or steps and the size of your dataset
The performance of an alert to run is directly related to the queries you will make on the database. Each data preprocessing step or model you configure for an alert will run directly on your entire dataset. Therefore, the more complex the query is (e.g. because it will have to cross the whole network) or the more results it will return, the longer your alert will take to run.
Please note that using the Neo4j GDS library in an alert's preprocessing steps can be costly in terms of system resources and impact Linkurious Enterprise performance depending on the complexity of the steps.
Case attributes: The number of columns configured and the complexity of the query that will calculate the custom attributes
The performance of the query that calculates the case attributes depends on the performance of the system the database is installed on. If the database is running on an undersized server, the computation will be slowed down.
System: The configuration of the system on which Linkurious Enterprise runs The performance of Linkurious Enterprise along with your database are directly related to the configuration of the system they are installed on. You can consult the Linkurious Enterprise installation requirements for more information.
Example: For an alert of 5 models with a case attribute query that will generate 10 columns, it takes 8 minutes to generate 5000 cases on a system with 5GB of RAM and 2 CPU.
Once the alert has run, its cases can be found on the Case List and the Unified case list.
In order for cases to be deduplicated properly, users have to set a target for their alert. The target is the entity used to deduplicate and group pattern occurences. The value of the target can be anything and it will have to be used in all the models that will be added to the alert.
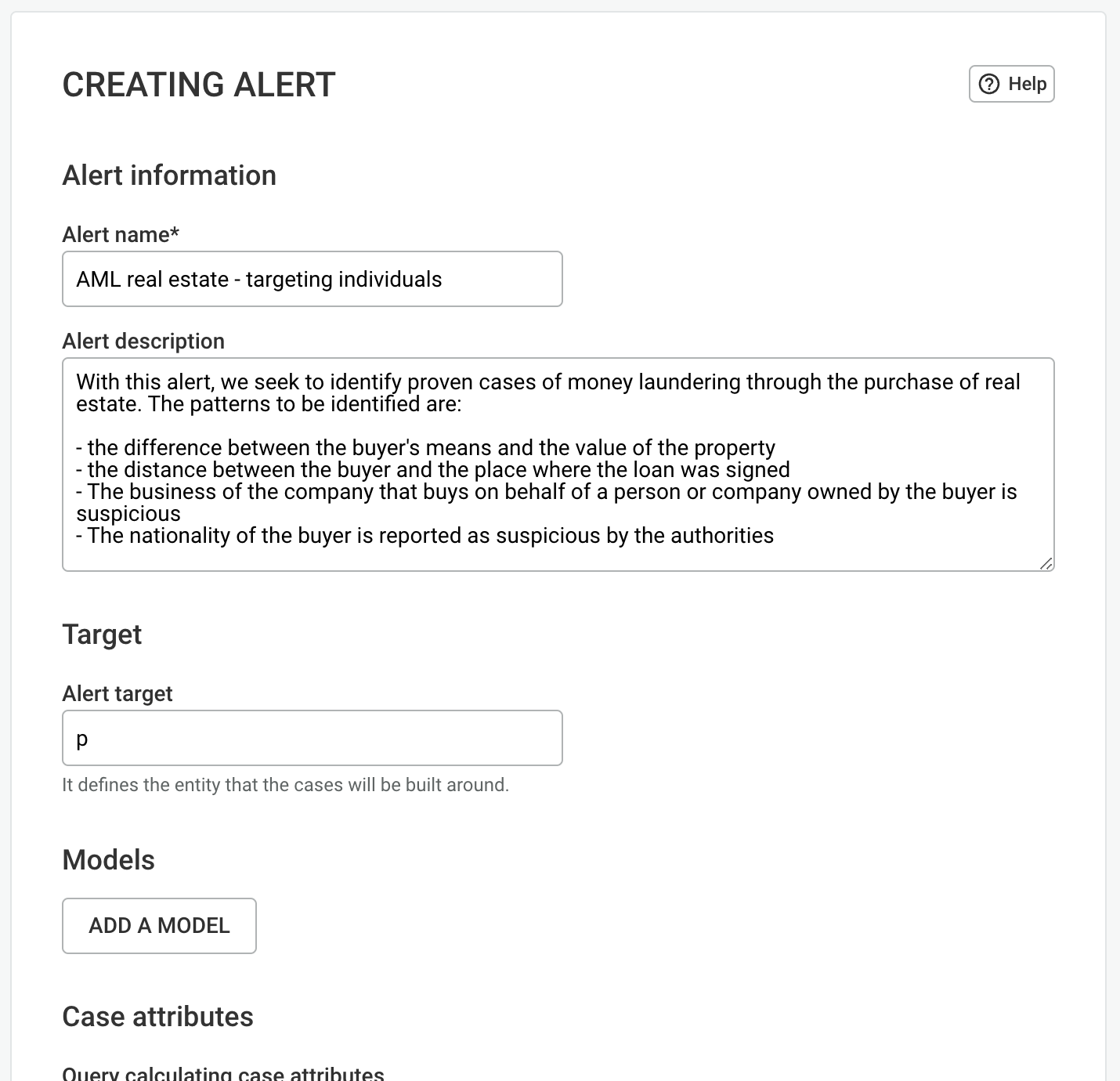
You can set as a target a node, an edge, multiple nodes, multiple edges or a subgraph but no scalar values or any type of data stored in entities.
The models of an alert are the detection patterns which users set. These patterns are called models. Each pattern has to be specified within a model using a query language (either Cypher or Gremlin, depending on your datasource). To create a model, click on the add a model button.
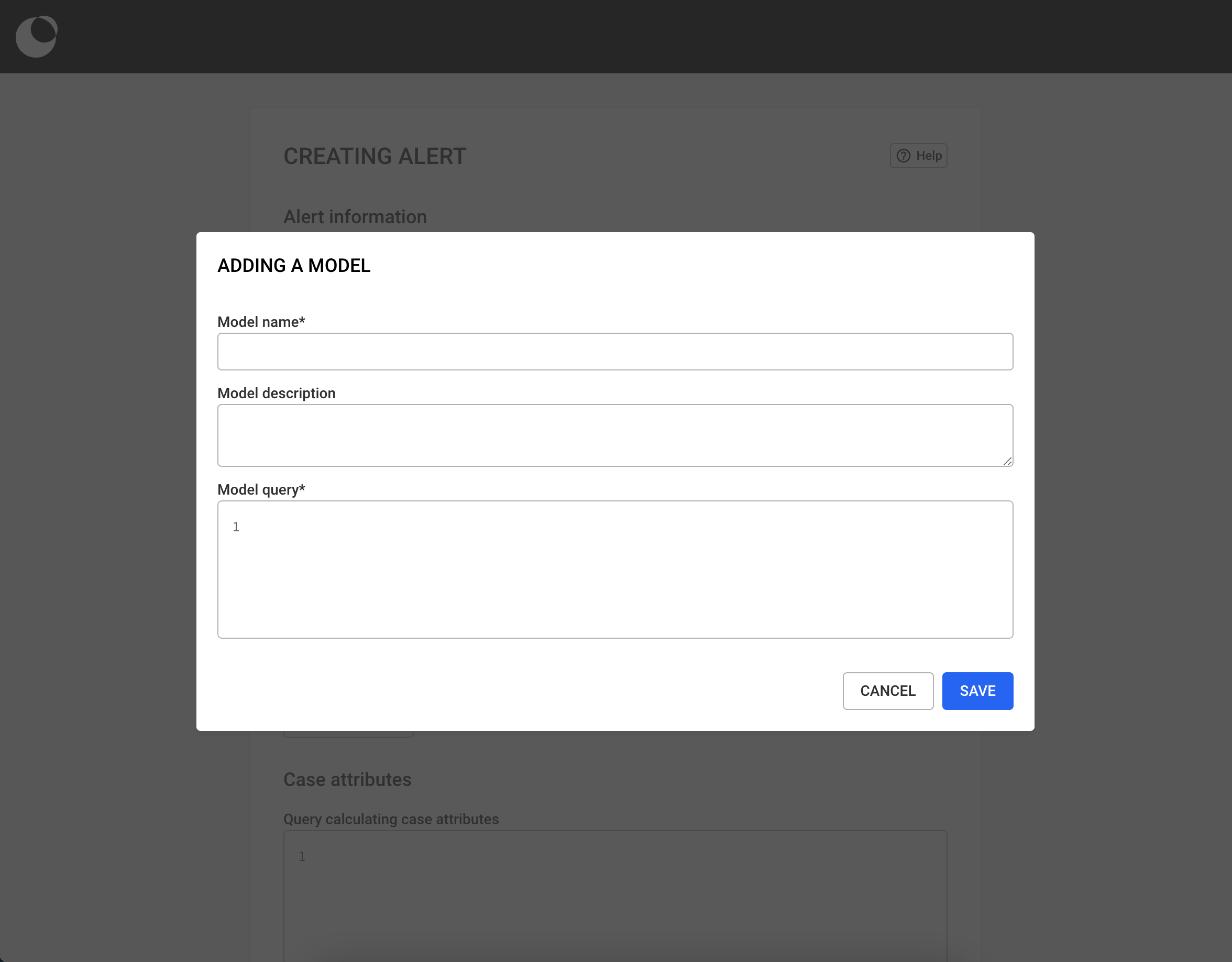 The model creation form.
The model creation form.
The model name and model query are mandatory fields and are needed in order to save a model. The model query should be a read query. In case the user writes a write query, saving the model will not be possible. Write queries can instead be input as data preprocessing steps (see below). Once the model is successfully saved, it will become visible on the list of models on the alert creation page. From there, if the model has any syntax errors or if the target is not found within the model, users will be able to see them. Consequently, users are able to edit and or delete models by clicking on the corresponding buttons.
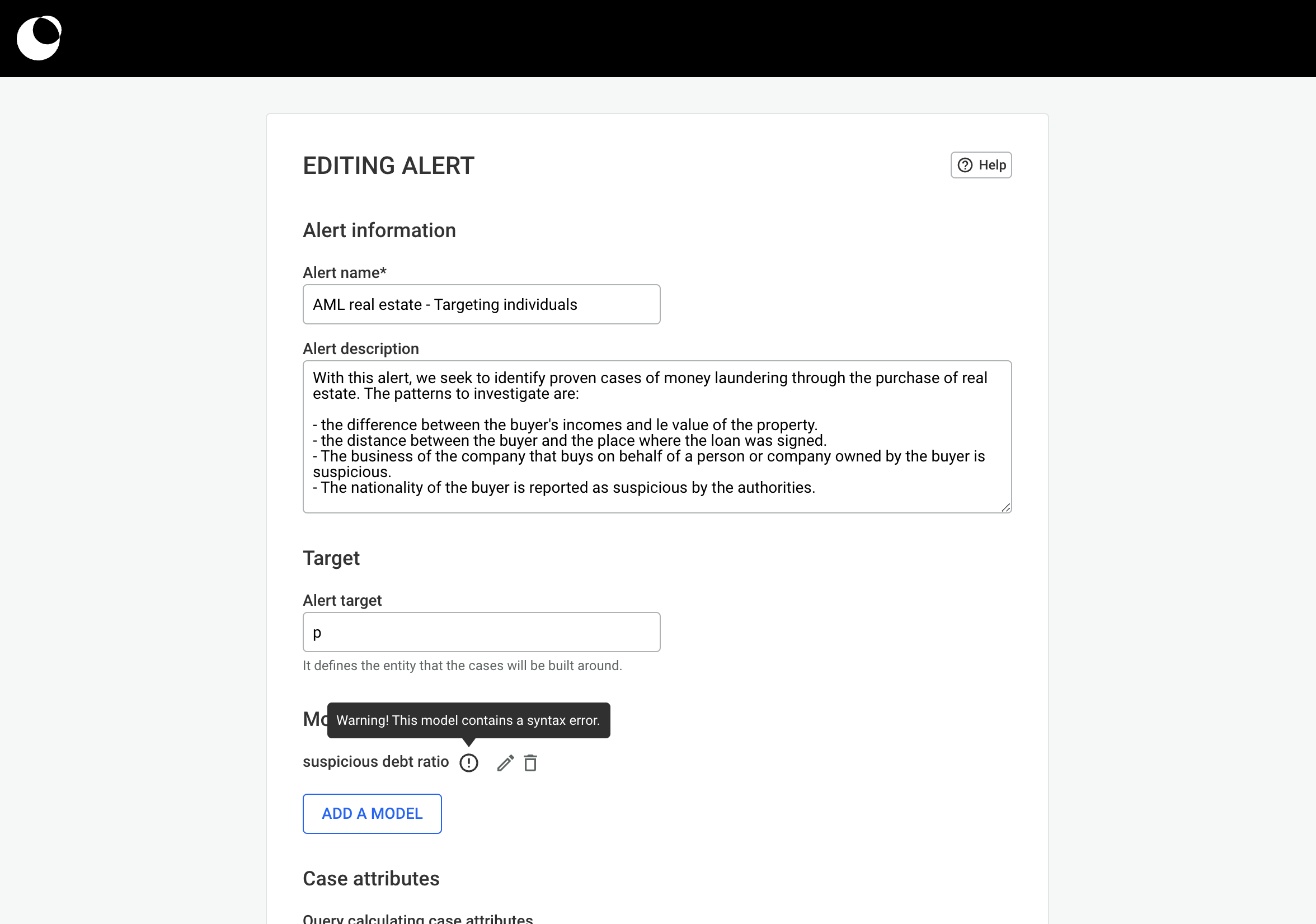 Incomplete models or models with errors are flagged in the alert creation page.
Incomplete models or models with errors are flagged in the alert creation page.
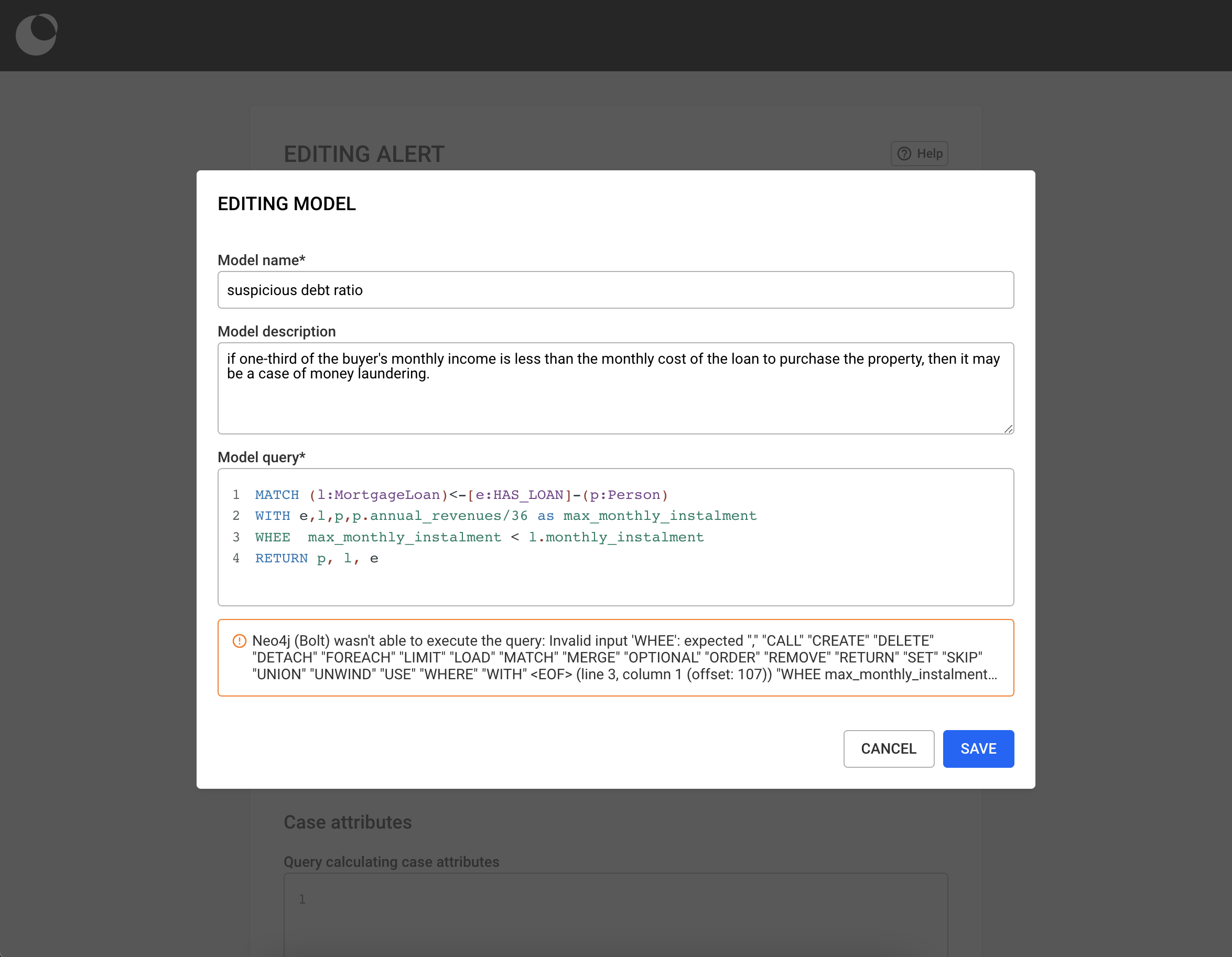 Complete model error in the template creation form.
Complete model error in the template creation form.
Data preprocessing steps are a series of queries used to write to the database in order to prepare data for the alert before models are run. Each query has to be written (using either Cypher or Gremlin, depending on your datasource), and it is considered a step and they are run sequentially before any models.
![]() Data preprocessing step creation form.
Data preprocessing step creation form.
Step name and query are mandatory. Only write queries may be used in preprocessing steps. Steps are run in alphabetical order, sequentially.
Data preprocessing can be used to enrich node and edge properties (see an example) and for more complex operations requiring multiple steps. Users can also use the Neo4j Graph Data Science Library to run graph algorithms such as computing global scores.
Common uses for GDS will usually require the user to create multiple steps and run estimations to prevent performance issues.
Once the models are created for an alert, cases will be returned once it has run. However, an analyst might need to access further information on cases in order to make informed decisions on their criticality.
To help prioritise and assign the most important cases to investigate, attributes can be created for each case. These attributes can be used to help prioritise cases (e.g. by calculating a "risk score"), to display information that makes it easy to assign cases to investigator (e.g. by displaying the type of fraud used), or to display important information about the target of the alert for quick decision making.
There are two types of syntax errors in the attribute creation query: the errors on the Linkurious Enterprise query template syntax and the errors related to the query language. These errors will be notified when saving the alert but are not blocking it.
In order to set up the case attributes, a query has to be written (using either Cypher or Gremlin, depending on your datasource). This query can either call directly or perform calculations on the data of a case. Once the query is written, columns that will appear in the lists of cases, need to be configured. In order for the above to be done, click on the add a column button and fill in the corresponding fields:
[Symbol] #,###.##: Currency symbol is displayed first, comma is used as thousands separator and dot as decimal separator.#.###,## [Symbol]: Currency symbol is displayed last, dot is used as thousands separator and comma as decimal separator.# ###,## [Symbol]: Currency symbol is displayed last, space is used as thousands separator and comma as decimal separator.In order for the columns to be properly displayed, the type of the case attribute fetched from the query has to match the one you choose as a type.
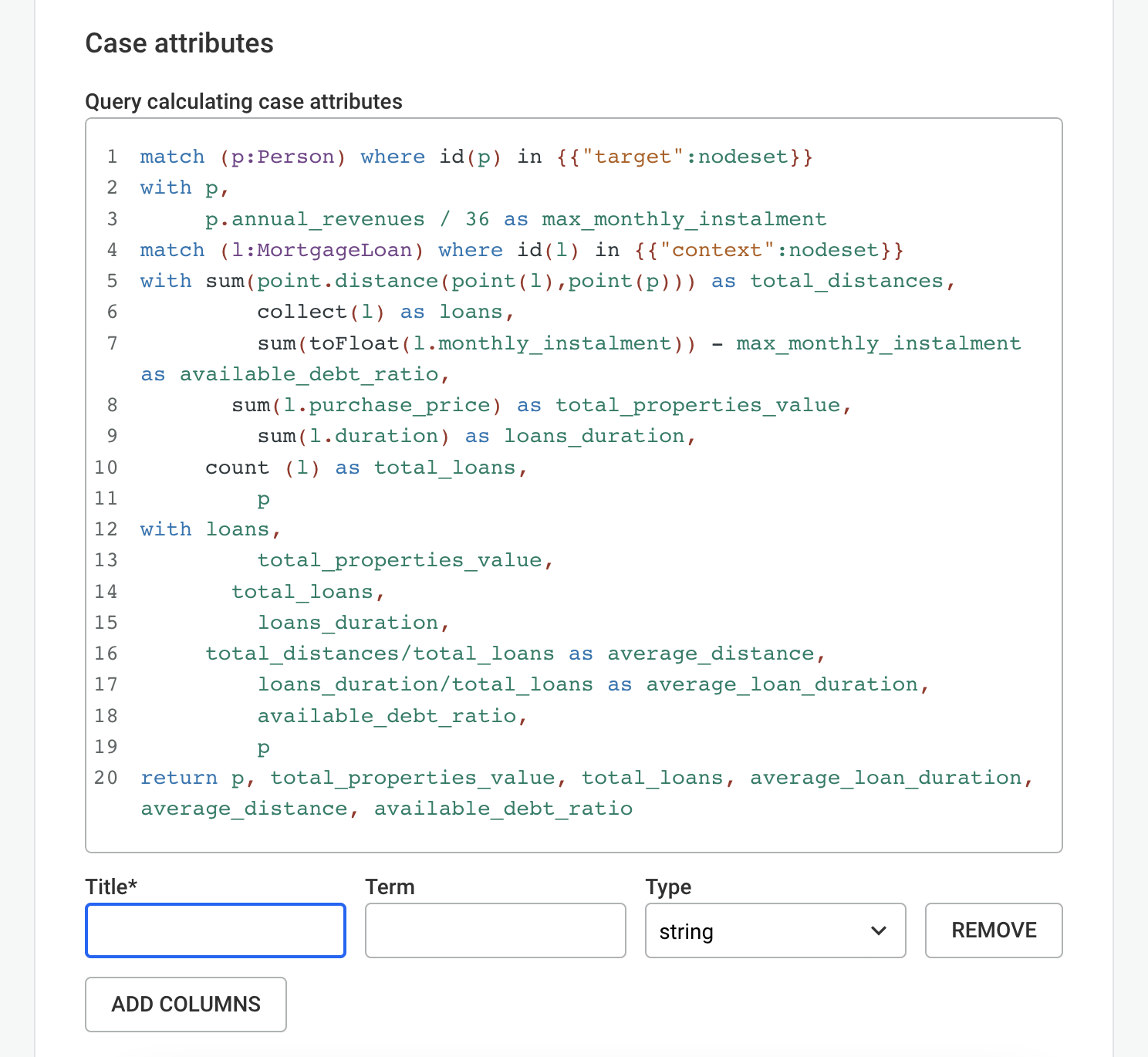 The title field is mandatory.
The title field is mandatory.
IMPORTANT
Please note that users of alerts who don’t have access to specific node categories and/or edge types can still access this information in the case attributes if the created queries return them. They will not see the nodes and/or edges in the visualization/case view but the data will still be displayed in the alert columns.
Go to the next section to follow a complete example of an alert setup.
In this chapter, we will learn how to use alerts to identify cases of fraud. With alerts, Linkurious Enterprise can regularly return new potential cases of fraud detected in your database. Once these cases are visible in the interface, they can be assigned to the investigators of your team, they can use the tools available in Linkurious Enterprise to ensure that the fraud case is genuine.
We will cover the use case of money laundering through the purchase of real estate to illustrate how to create Linkurious Enterprise Alerts.
Money laundering through the purchase of real estate (or real estate ML) consists of hiding the origin and injecting fraudulent funds into the legal economy by making a profitable investment. There are different ways to identify real estate fraud. Here are some of them:
As can be seen, there is a wide variety of different schemes for a fraud case. And a fraudster may use different schemes each time they try to launder funds in order to cover his tracks and hide his illicit activities. Linkurious Enterprise' alert system takes into account and aggregates these different schemes in order to detect and return all data related to one targeted entity.
Here we will create an alert in which we will target a person potentially guilty of laundering money through the purchase of real estate.
The target is the entity suspected for fraud. It is this entity that the investigator will inquiry during his investigation.
The target is left to the discretion of the alert creator but it will have to be used in each query describing a pattern in order for the system to work and for the alert to return cases.
In our example, the investigators will have to prove the responsibility of an individual in the potential fraud cases generated by the alert. This person will be our target. We will call him here "p" and we will make sure that each query will return a node of type person identified as "p".
In our example, we will be using the maximum monthly installment an individual can have as one of the element to detect fraudulent cases. Using a preprocessing step, we will calculate this amount and set it as a property on all Person nodes in the graph.
match (p:Person)
Set p.max_monthly_instalment = toFloat(p.annual_revenues/36)
Return p
In our example, the first pattern we want to detect is a discrepancy between the owner's income and property value, illustrated by the monthly instalment for the loan: if one-third of the buyer's monthly income is less than the monthly cost of the loan to purchase the property, then it may be a case of money laundering.
Here is how this pattern will be translated via the Cypher language:
match (l:MortgageLoan)<-[e:HAS_LOAN]-(p:Person)
where p.max_monthly_instalment < toFloat(l.monthly_instalment)
return l,p,e
As can be seen, we have identified the buyer (an entity of type Person in the given database) by the term p – our defined target – and returned it, along with the entities necessary for the investigation: the loan and the link between the two entities.
If you want to reproduce and test our example, here are all the queries used for each pattern:
A discrepancy between the usual income of the owner and the property value.
match (l:MortgageLoan)<-[e:HAS_LOAN]-(p:Person)
where p.max_monthly_instalment < toFloat(l.monthly_instalment)
return l,p,e
The indication by a country that there is a risk of money laundering by its citizen in another country.
match (p:Person)-[e:HAS_LOAN]->(l:MortgageLoan)
where p.nationality in ["Russia","North Korea", "China"]
return l,p,e
The location of the property (represented by location where the loan is done) is far away from the buyer location.
match (l:MortgageLoan)<-[e:HAS_LOAN]-(p:Person)
where point.distance(point(l),point(p))/1000 > 300
return l,p,e
The company or the type of company owned by the owner is among a list of sensitive fields.
// We distinguish two patterns here:
// - Company got the loan
match (l:MortgageLoan)<-[e:HAS_LOAN]-(c:Company)<-[:HAS_CONTROL]-(p:Person)
where c.industry in ["Military/Government/Technical","Oil/Gas Transmission"]
return l,c,p,e
// - Person got the loan
match (l:MortgageLoan)<-[e:HAS_LOAN]-(p:Person)-[:HAS_CONTROL]->(c:Company)
where c.industry in ["Military/Government/Technical","Oil/Gas Transmission"]
return l,c,p,e
We now want to set up some columns that will allow the investigator to quickly understand what type of scheme the fraudster is using to launder funds as well as information about the buyer:
Let's now take a look at the query that will help us add the above attributes.
match (p:Person) where id(p) in {{"target":nodeset}}
match (l:MortgageLoan) where id(l) in {{"context":nodeset}}
with p,p.max_monthly_instalment,
sum(point.distance(point(l),point(p))) as total_distances,
collect(l) as loans,
sum(toFloat(l.monthly_instalment)) as debt_ratio,
sum(l.purchase_price) as total_properties_value,
sum(l.duration) as loans_duration,
count (l) as total_loans
with p,
loans,
total_properties_value,
total_loans,
loans_duration,
total_distances/total_loans as average_distance,
loans_duration/total_loans as average_loan_duration,
p.max_monthly_instalment - debt_ratio as available_debt_ratio
return p, total_properties_value, total_loans, average_loan_duration, average_distance, available_debt_ratio
In the first line, we want to specifically look up the entity representing our target. To do so, we use the Linkurious Enterprise query templates syntax to specify what type of entity we are looking for. We can thus use 4 different variables to target distinct elements in the data of a case:
{{"target":nodeset}} will fetch the entities of type "node" in the alert target.{{"target":edgeset}} will fetch the entities of type "edge" in the alert target.{{"context":nodeset}} will fetch the entities of type "node" present in the case data.{{"context":edgeset}} will fetch the entities of type "edge" present in the case data.so, with these lines:
match (p:Person) where id(p) in {{"target":nodeset}}
we fetch the person node identified as our target, and return it.
In the same way, this line:
match (l:MortgageLoan) where id(l) in {{"context":nodeset}}
will return all entities of type node and category "MortgageLoan" contained in the data returned by the cases.
IMPORTANT If you are using Google Spanner as your data source, please review the Running queries with Spanner section for important limitations when using query templates.
Navigate to the next section where we dig deeper into the different ways alerts' cases can be processed.
Alerts' cases can be accessed in two pages. This section, guides you through these views and their features.
The Alerts Dashboard displays the alerts available to users.
It is always accessible to those who have the right to “Create & Process Alerts” (see Access Rights). However, users who have the right to “Process Alerts” can only access the dashboard if at least one alert exists.
From the Alerts Dashboard, we can:
When at least one folder exists, the file tree is displayed on the left.
The blue badge displayed above alerts and folders is there to inform users on cases requiring attention (cases with the status: open and assignee: unassigned).
Users clicking on 'Back to Cases' are navigated to the Unified case list.
The unified case list is where all the cases a user has access to can be displayed. It is accessible to all the users who can access and/or create alerts. The list of cases displayed can be adjusted using filters.
A "by default" filter is applied every time a user accesses the page, which shows the cases which have status Open or In progress and are assigned to the currently logged in user. This enables users to focus on the evolving cases which they are responsible for.
The unified case list is always sorted in descending order, meaning the newest case is always displayed first. Sorting can be modified according to the needs of the user by sorting the remaining columns of the unified case list. To go back to the initially sorted view, sort by the "created at" column in a descending order.
Users can navigate to the 'Alerts Dashboard', where they can also create alerts, when clicking on the 'Alerts Dashboard' button.

Different combinations of filters can be applied. Users can filter by one or many Alert folders, Alert names, Alert models, Case statuses and Assignees. Users can also filter by Created At and Updated At to add a chronological perspective to their results. When filters are cleared, by clicking on the clear button, all the cases a user has access to are displayed.
By default, the unified case list displays basic information common to all cases. The case ID, alert name, folder name (if any), the models that generated the case and their sum, case creation date and time, last updated at date and time, case status and the investigator assigned to it.
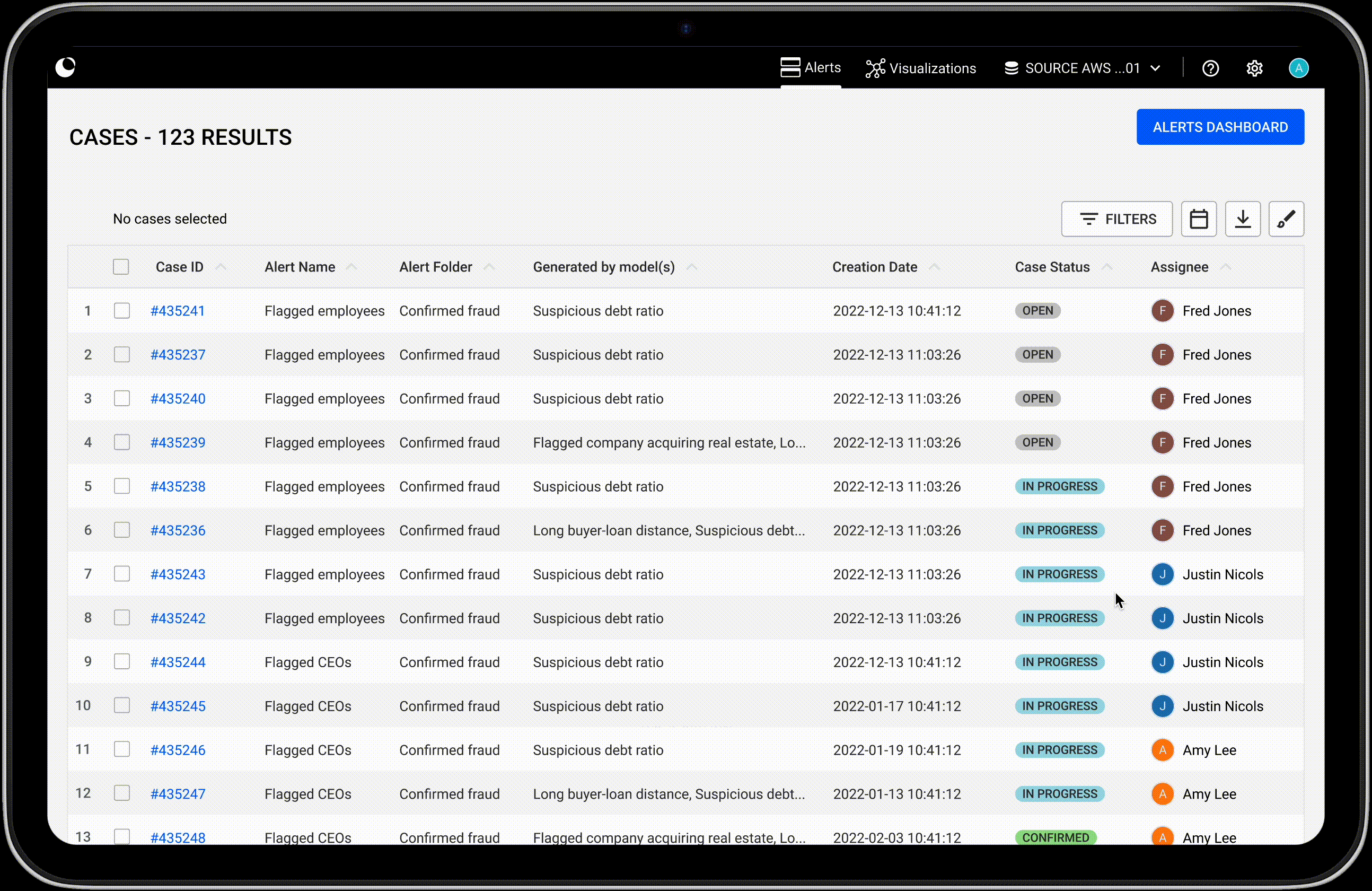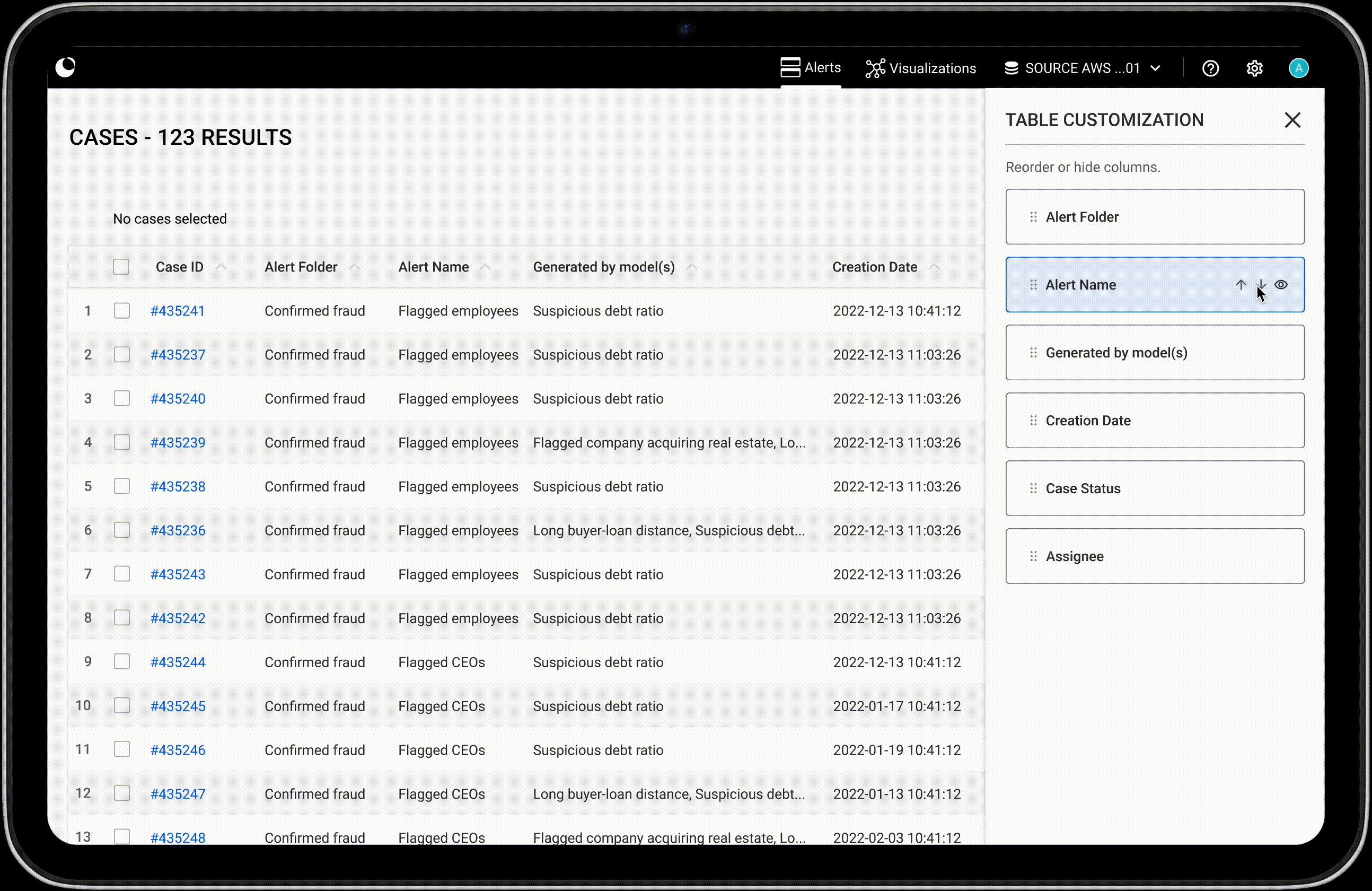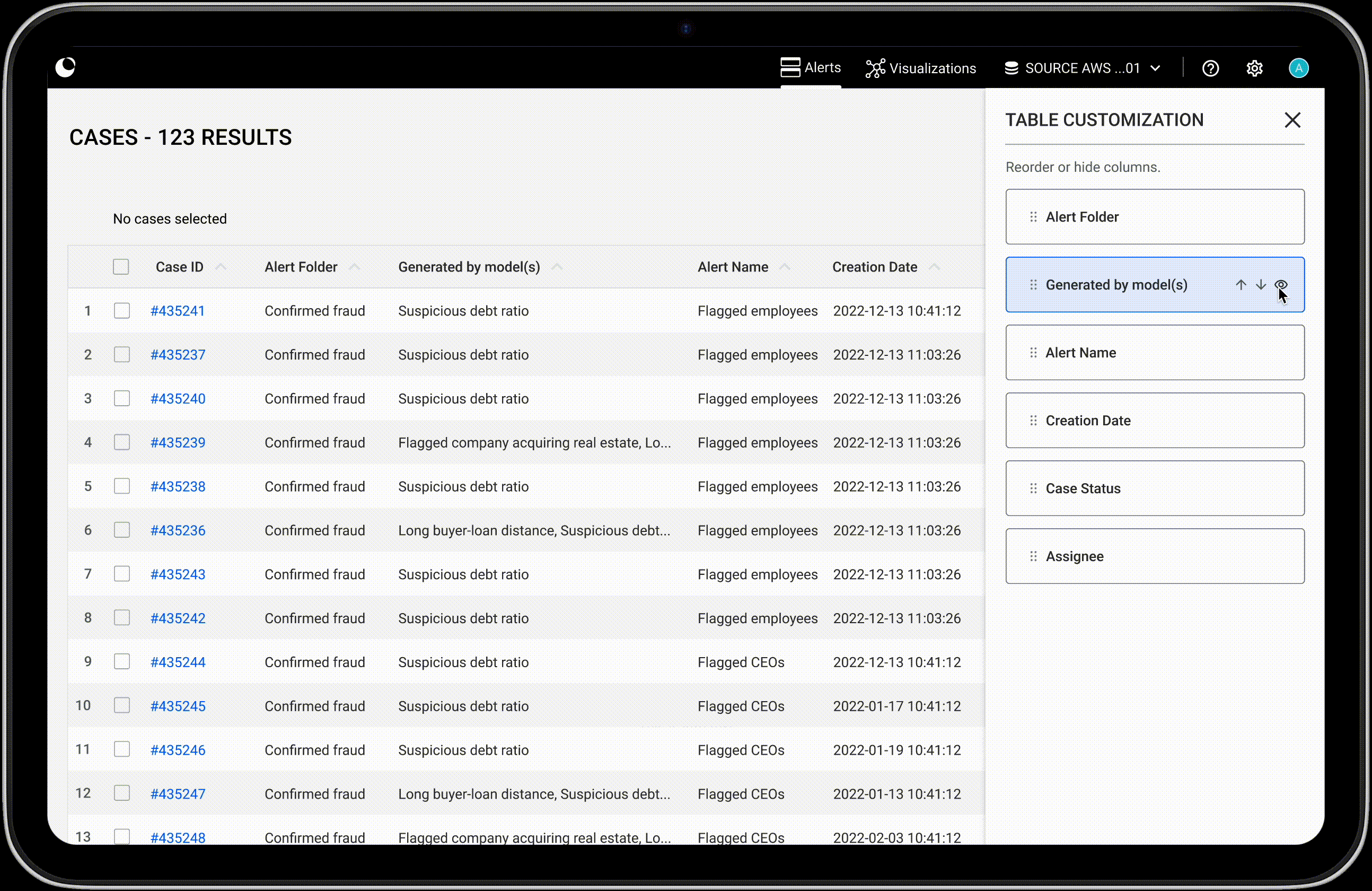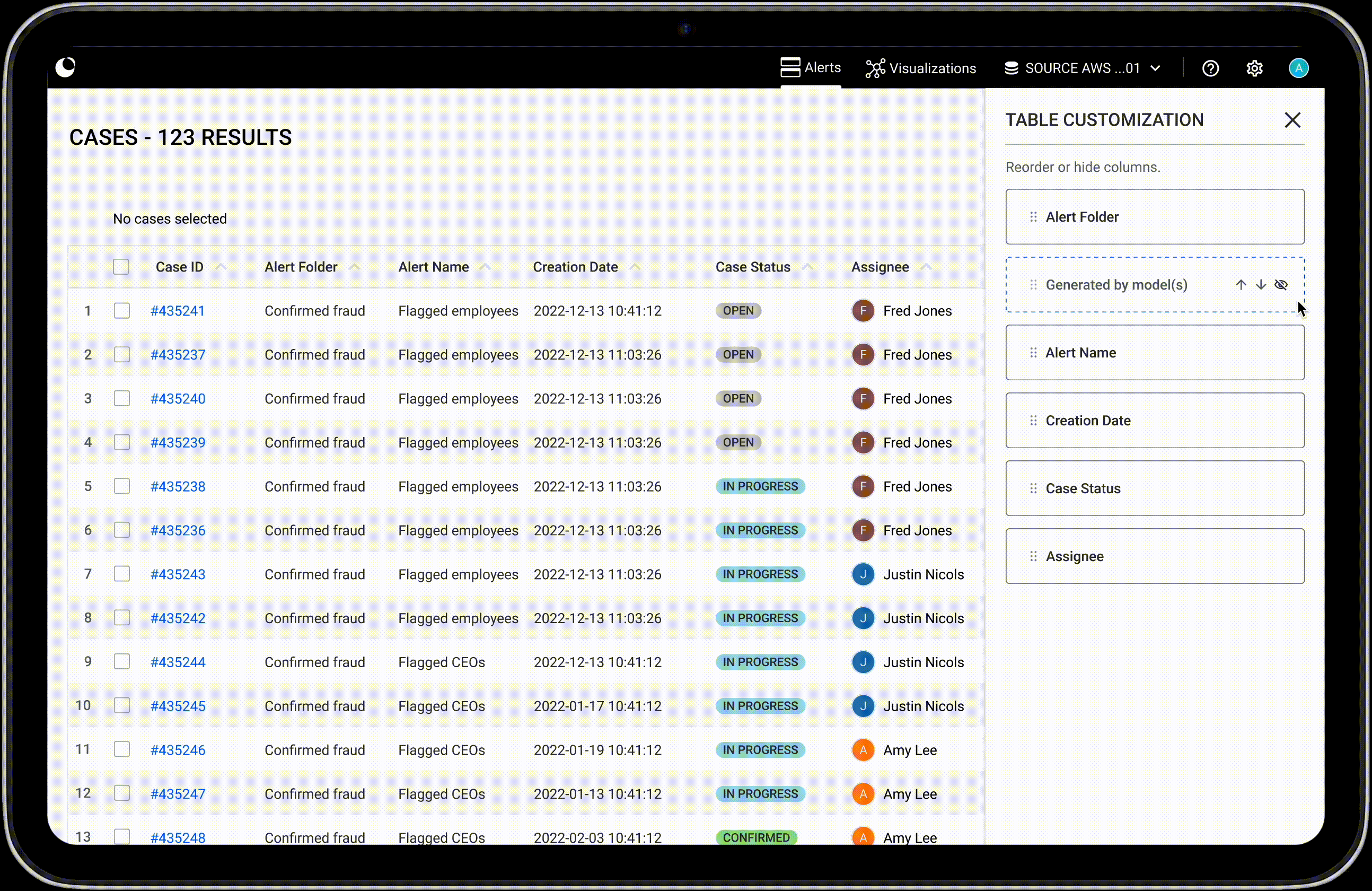
You can flexibly and efficiently manage your investigations by reordering and hiding columns to tailor the Unified Case List to your personal workflow. You can do so by clicking on the right-most button as shown above.
When filtering by one alert, all columns (case attributes) of that specific alert are displayed on the unified case list table. Moreover, they're also displayed on the filters panel where users can apply filters on them. The columns of the 'currency' type show the appropriate symbol and adhere to the currency format defined during the alert's creation.
Depending on the type of the columns' data users can filter on numerical, currency or text values.
 **
**
Filters and sorting are persisted to help users not lose the context of their work when navigating in the app.
Filtering monetary values is handled in the same manner as filtering columns of the 'number' type.
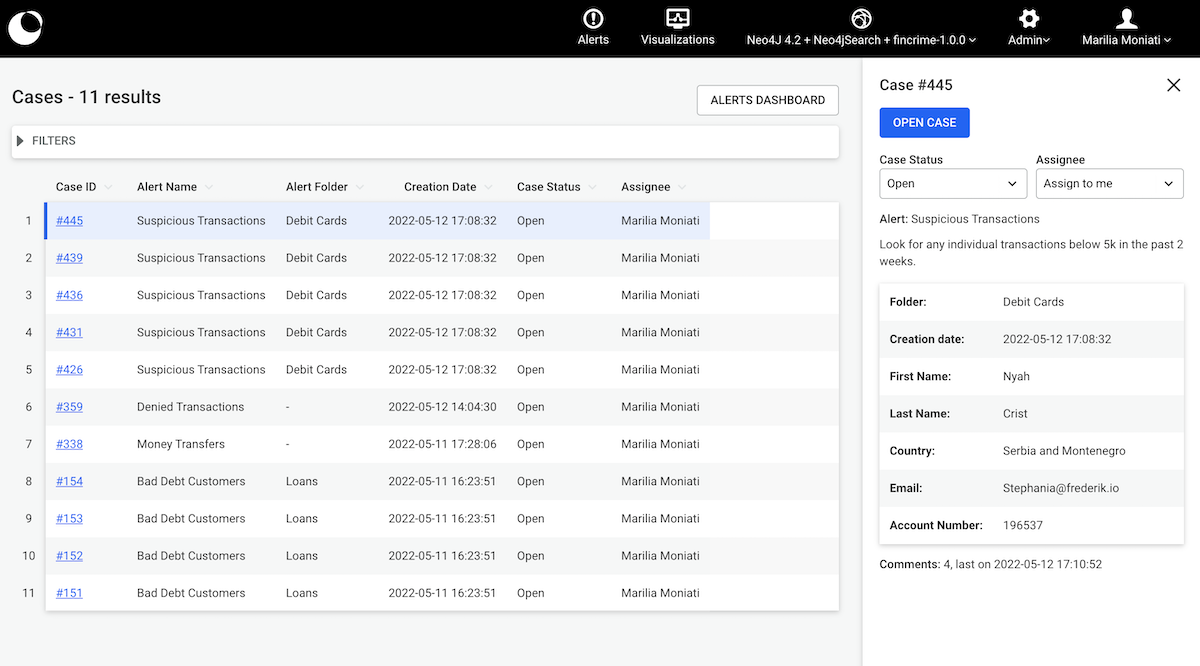
The case preview can be accessed by clicking on the case's ID. From the case preview the case view can be opened. Moreover, details on the information the case holds such as alert name, alert description, case attributes and number of comments as well as the timestamp of the latest comment are shown. Furthermore, users can change the status and assignee of a case, exactly in the same manner they do on the case view, from the case preview.
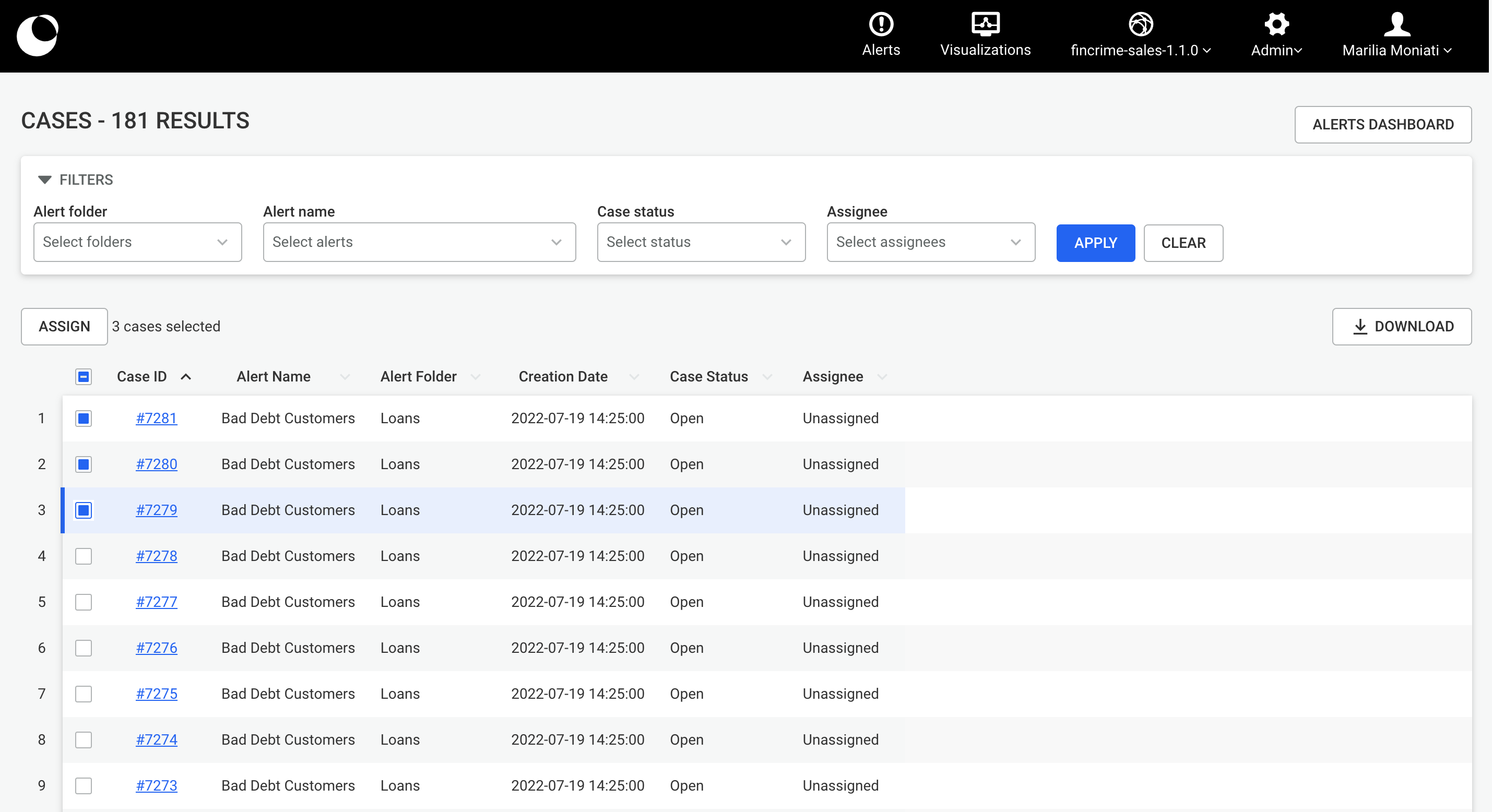
Users can assign one or multiple cases to another user or themselves in one go, from one or many alerts at a time. This is particularly useful for a team leader dispatching the workload among their team, especially in combination with the usage of filters.
To use this feature, the user needs to select one or many cases from the unified case list (clicking on checkboxes). The “ASSIGN” button will activate upon the first selection. Users can pick cases from the different pages of the list. The number of cases selected will show next to the “ASSIGN” button.
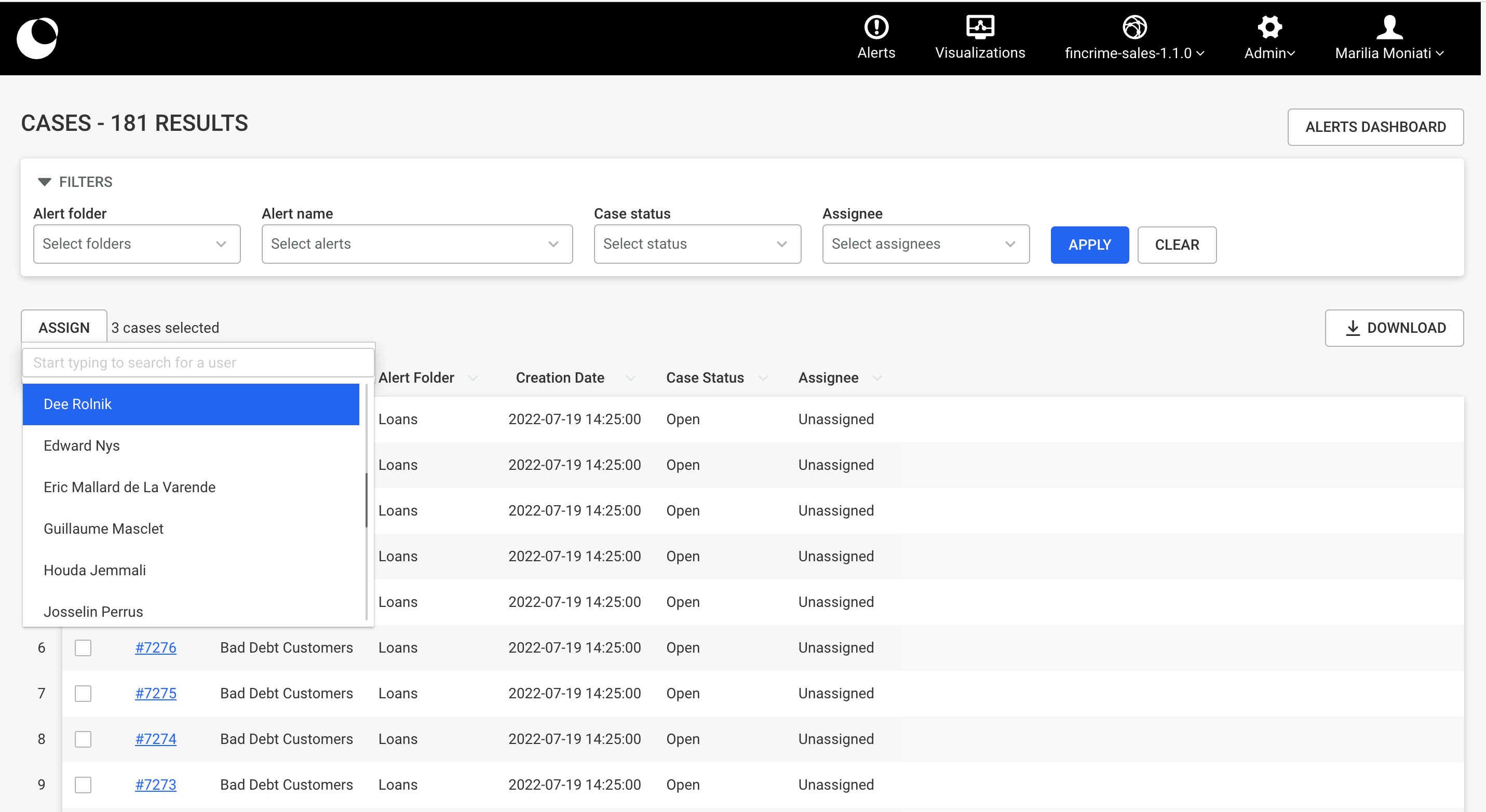
Once the user is done selecting cases, they will pick a user name from the dropdown list that opens upon clicking on the “ASSIGN” button. Only the users who have access to all the alerts to which the selected cases belong, will show on the list. If a user is lacking access to at least one of the cases’ alert, they won’t be displayed. Also, if new filters are applied or if filters are cleared, the current selection of cases is unselected.
From the unified case list, users can download an excel file containing all the cases which the applied filter returns. This file contains information which will enable analysts to monitor the team's activity and share it with fellow colleagues. and answer possible questions a they may have, such as:
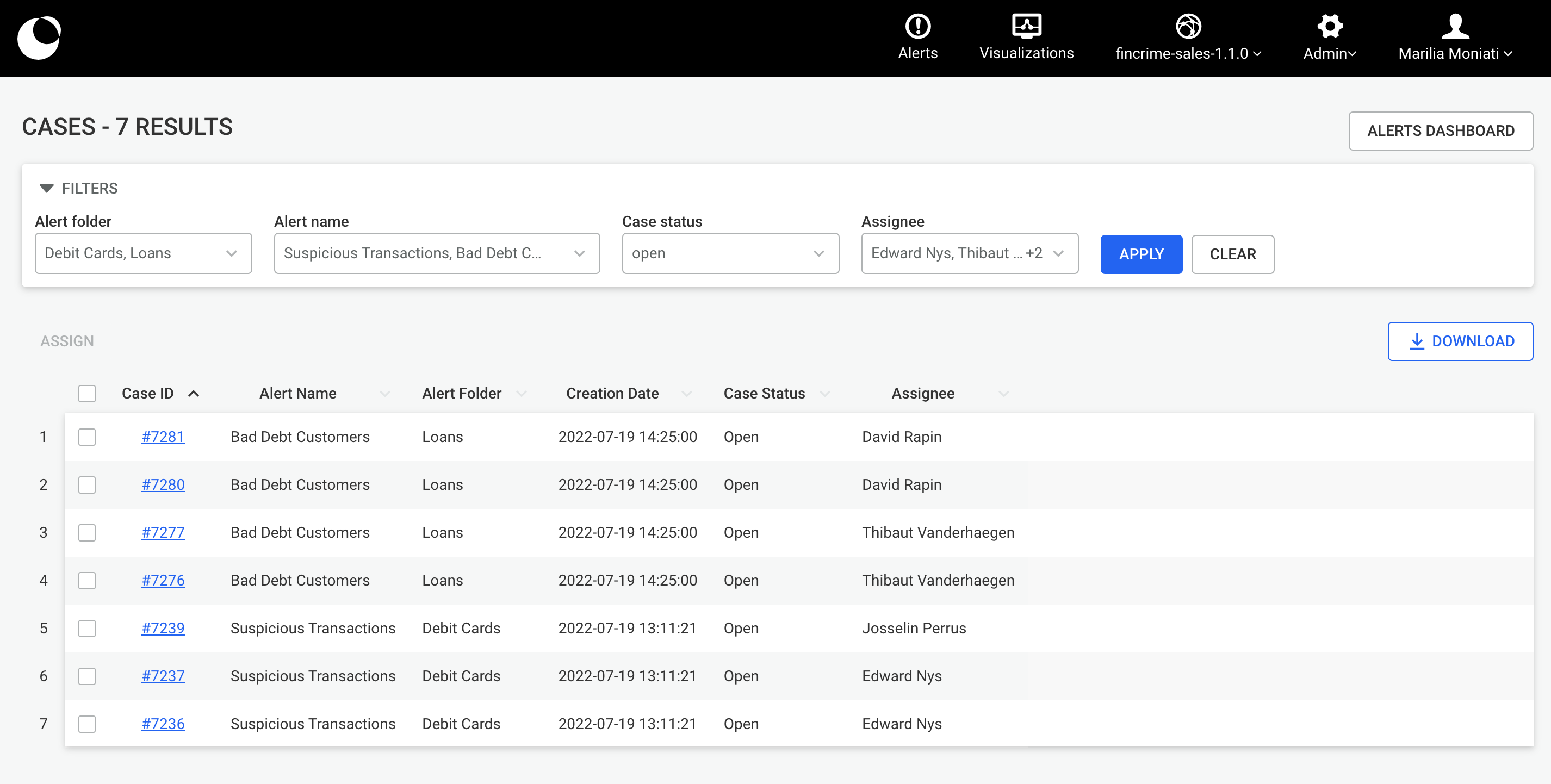
The file begins to download once the button is pressed. In the downloaded file, for each case, you will find its id, creation datetime, status, assignee username, assignee email, assigned datetime, dismissed or confirmed datetime, the alert name and folder name the case belongs to as well as the export datetime.
In case the applied filter returns more than 500k cases, download would not be possible.
The "Case List" shows a list of newly detected cases for each alert. Each row in the list is a case.
By default, cases are ordered by creation date.
You can change sorting order by using custom columns, if the alert creator has defined any.
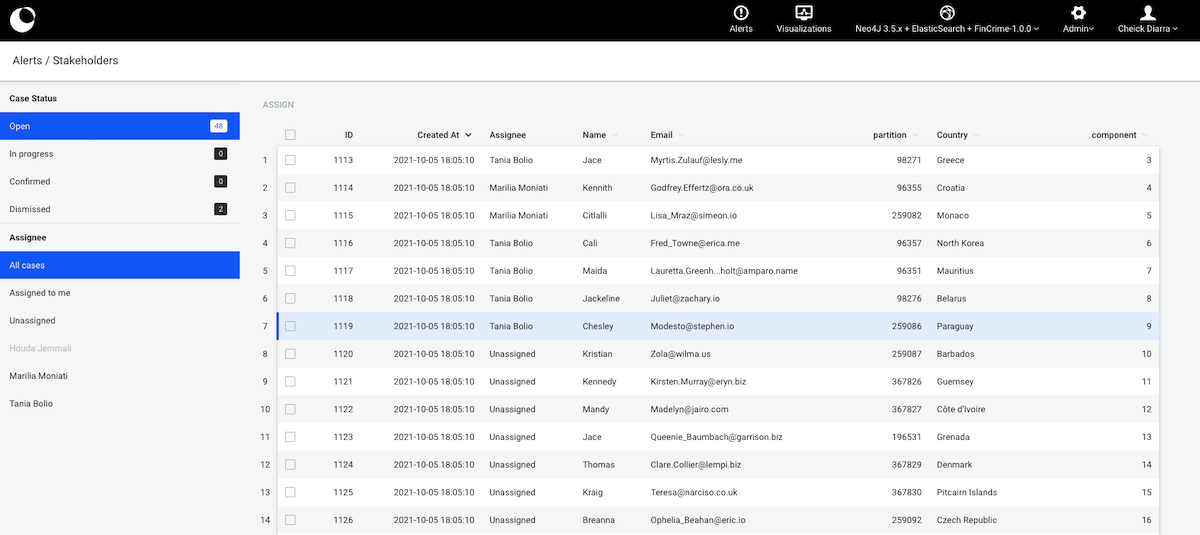
A case has a status that is either Open, In progress, Confirmed, or Dismissed.
New cases have the Open status by default.
The list of cases can be filtered by status.
For example, the image below shows the list of dismissed cases.
We can also see who has changed the status of those cases.
You can also filter the list of cases by assignee. In the example below, we can see all the cases opened and assigned to the current user.
If a user has no cases assigned to him, his name will appear greyed out in the list.
Within the list of cases, you can assign them to users that have the right to process the alert.
To do so, you can select cases from multiple pages by checking the checkbox on the left of every row.
You can also select all the cases within a page by clicking on the checkbox on top of the list of cases.
Once cases are selected, you can assign them to a single user by clicking on the button "Assign".
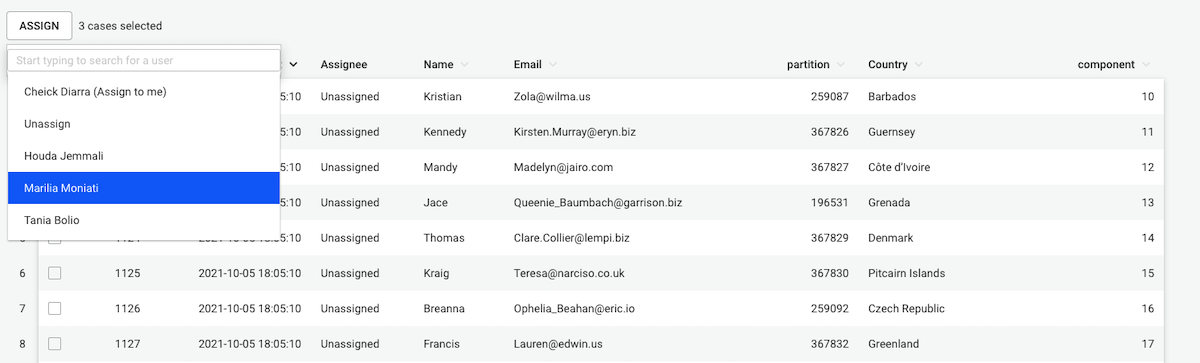
To take a decision, you must investigate on a case. Simply click on the ID of a case to open the case view.
From each alert's case list view, users can download an excel file containing all the cases of the alert. This file contains information which will enable analysts to monitor the team's activity, share it with fellow colleagues and answer possible questions a they may have, such as:
The file begins to download once the button is pressed. In the downloaded file, for each case, you will find its id, creation datetime, status, assignee username, assignee email, assigned datetime, dismissed or confirmed datetime, the alert name and folder name the case belongs to and the columns as well as the export datetime.
The next section focuses on case investigation and exploration best practises.
You can investigate a case by clicking on the case's id in the case list or the unified case list. By doing so, you will be redirected to the graph of said case where you can:
Features that are present in the visualization workspace such as, geomode, filtering, grouping, layouts and more are also present in this view in order to help you while investigating! Nodes' and edges' details can be accessed when clicking on them from the left panel. Moreover, the case can be exported.
From the activity panel, you can add comments and mention any user who has access to the datasource, by typing @. After typing @, a list of suggested users according to what you type will appear. Users can be searched for by their email and username. When you have found the user you would like to mention, you can click on them or press enter. Mentioned users will then be notified via email.
In order to receive notifications, confirm with your admin that your email notifications are correctly configured.
You can change the status of the case (from the top-right of the page).
When changing the status to either In progress, Confirmed or Dismissed, you will be prompted for an
optional note, to document the decision for future reference.
You can assign the case to someone directly through the information panel. To do so, you just need to click on "Assign" button next to the assignee username. You will find the history of assignement in the activity panel, with comments and status changes.
You can save the current state of the investigation by clicking on the "Save" button that
appears after you update the graph (e.g. by adding a node).

In this section, you can find useful definitions of commonly used vocabulary within the Alerts feature.
The Guest mode is a way to share graphs with people who do not have an account on Linkurious Enterprise.
Key characteristics:
The Guest mode is available once an Administrator has enabled it.
Standard user interface:
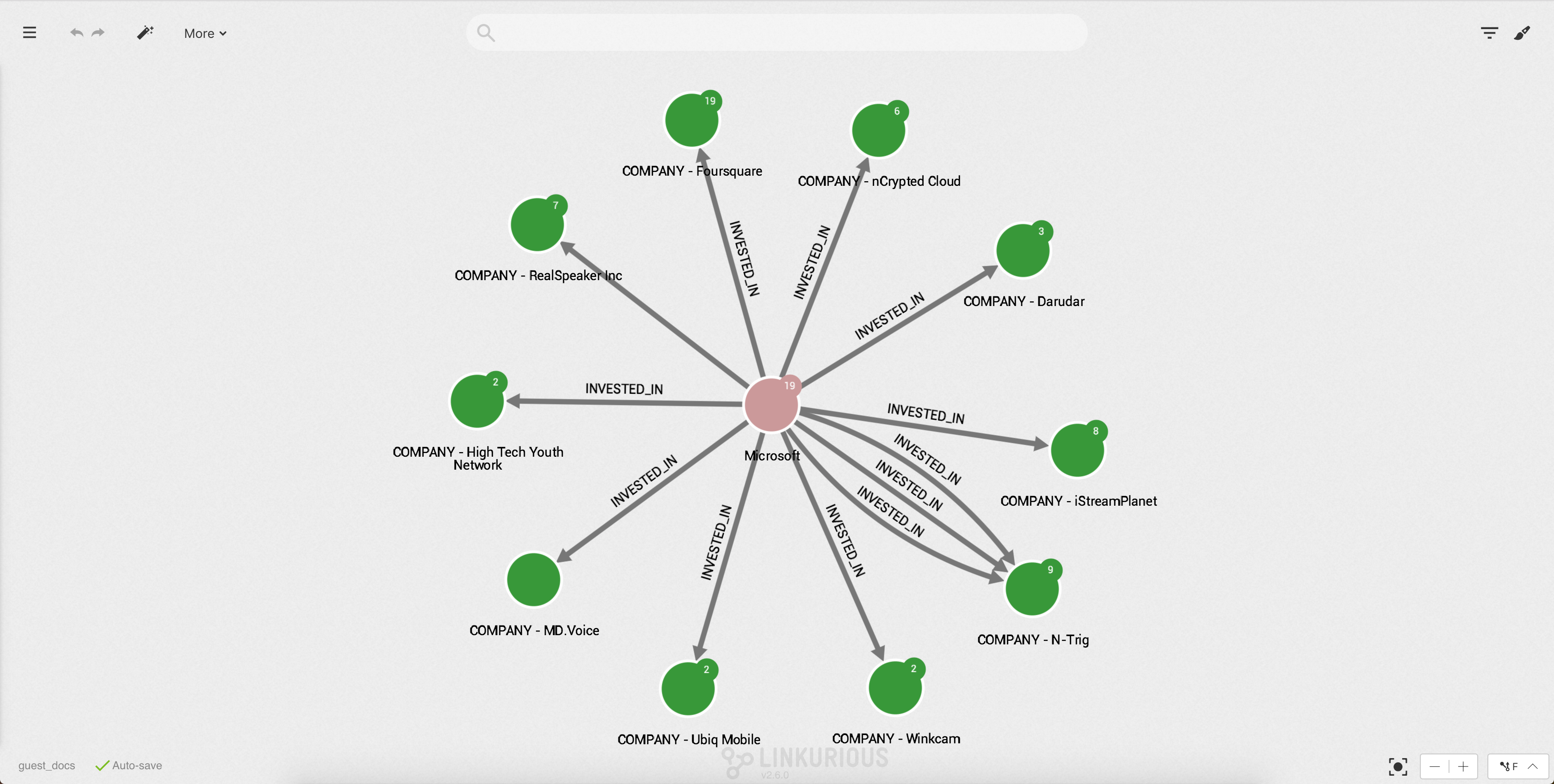
Guest mode user interface:
There are 2 options to share a visualization with the Guest mode:

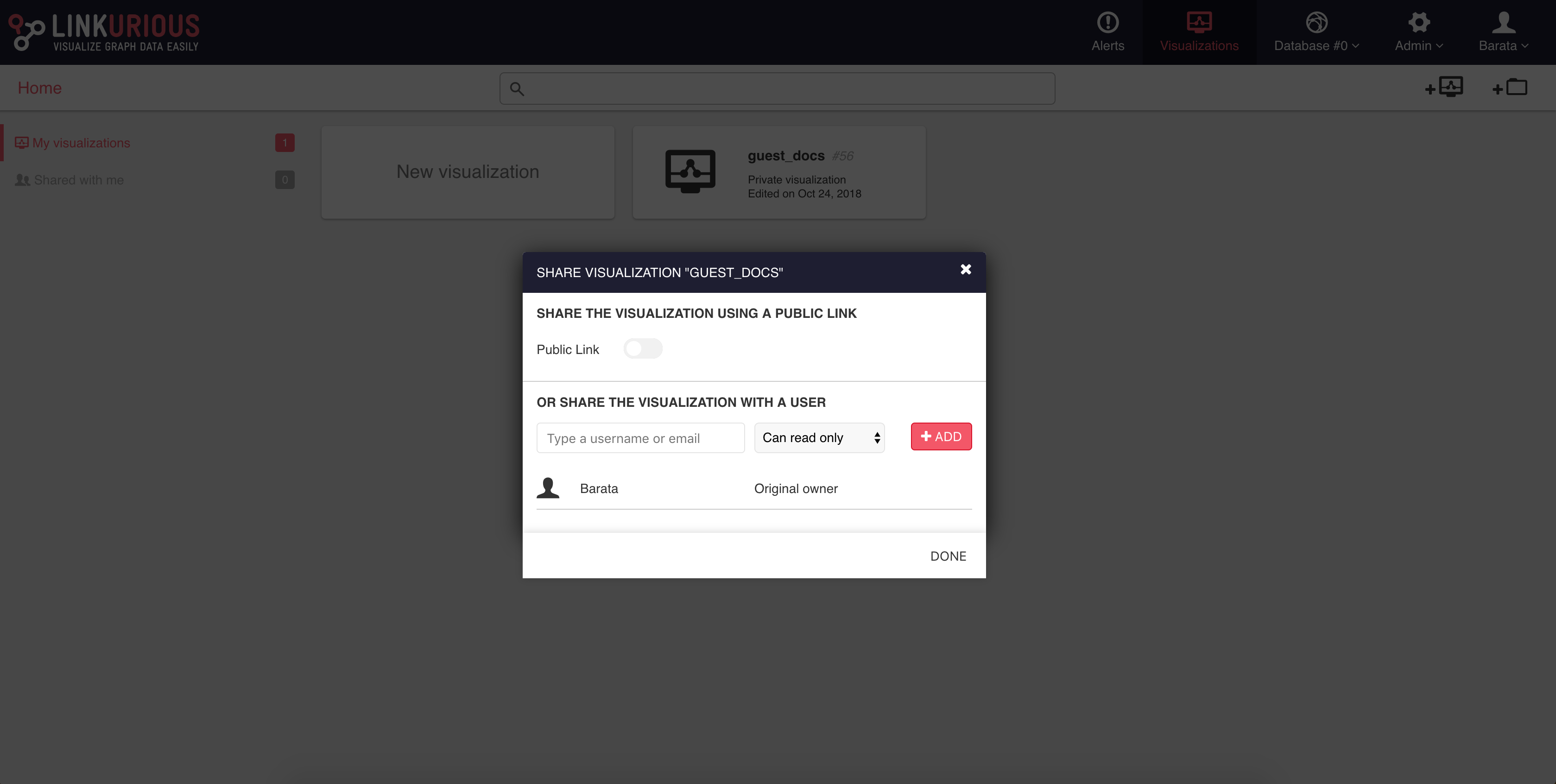
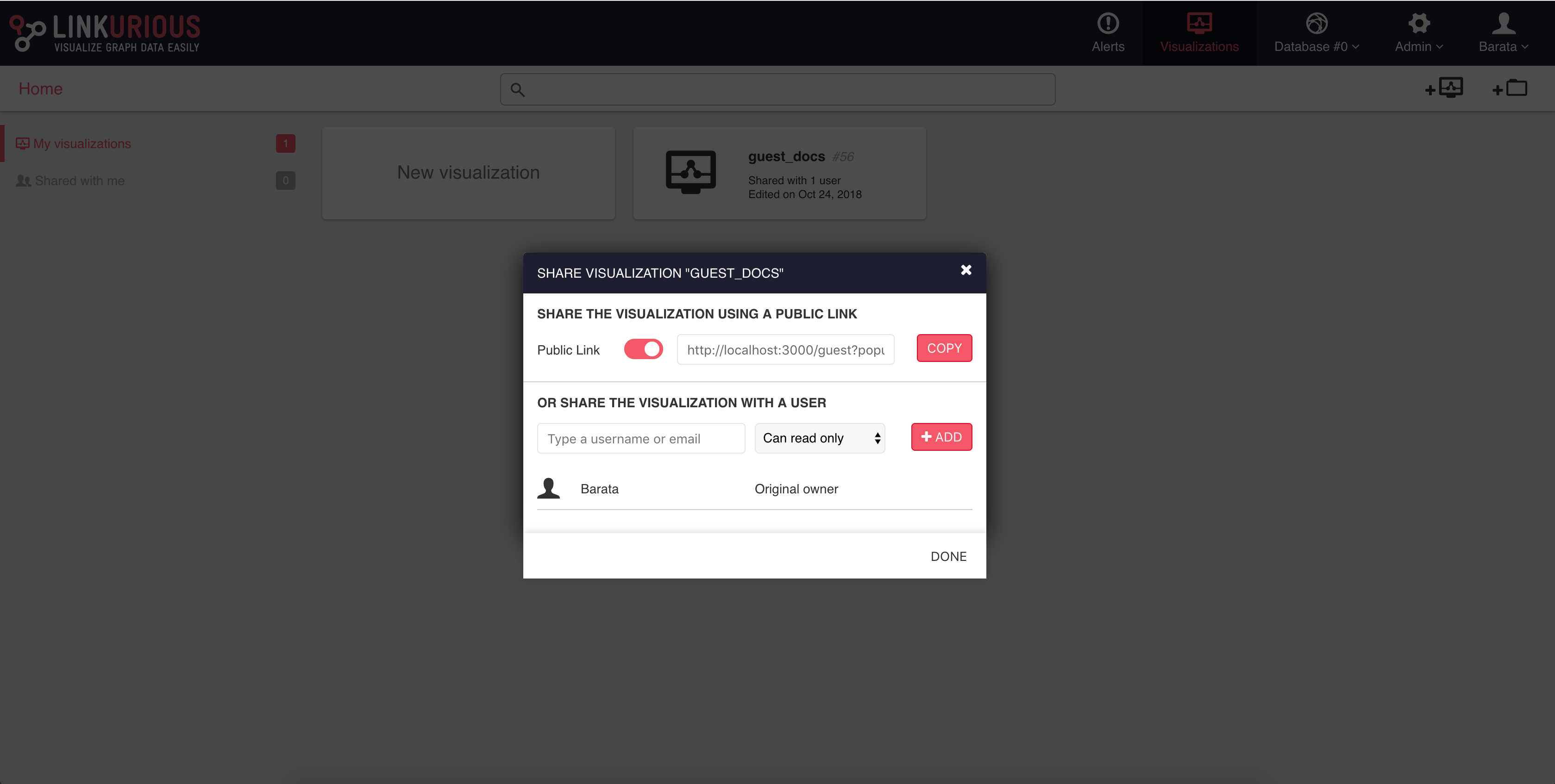
Users accessing visualizations through Guest Mode are considered regular users under the Linkurious Enterprise License. A valid license for these users is required to enable the use of Guest Mode.